2차시 - 이미지 분류 파이프라인
파이프라인은 한 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 형태로 연결된 구조이다.
1. Nearest Neighbor
트레이닝 셋에서 "가장 가까운 샘플"을 찾아내는 방식이다.

위 사진은 CIFAR-10 의 데이터를 사용해서 가장 가까운 샘플 순으로 정렬한 것이다.
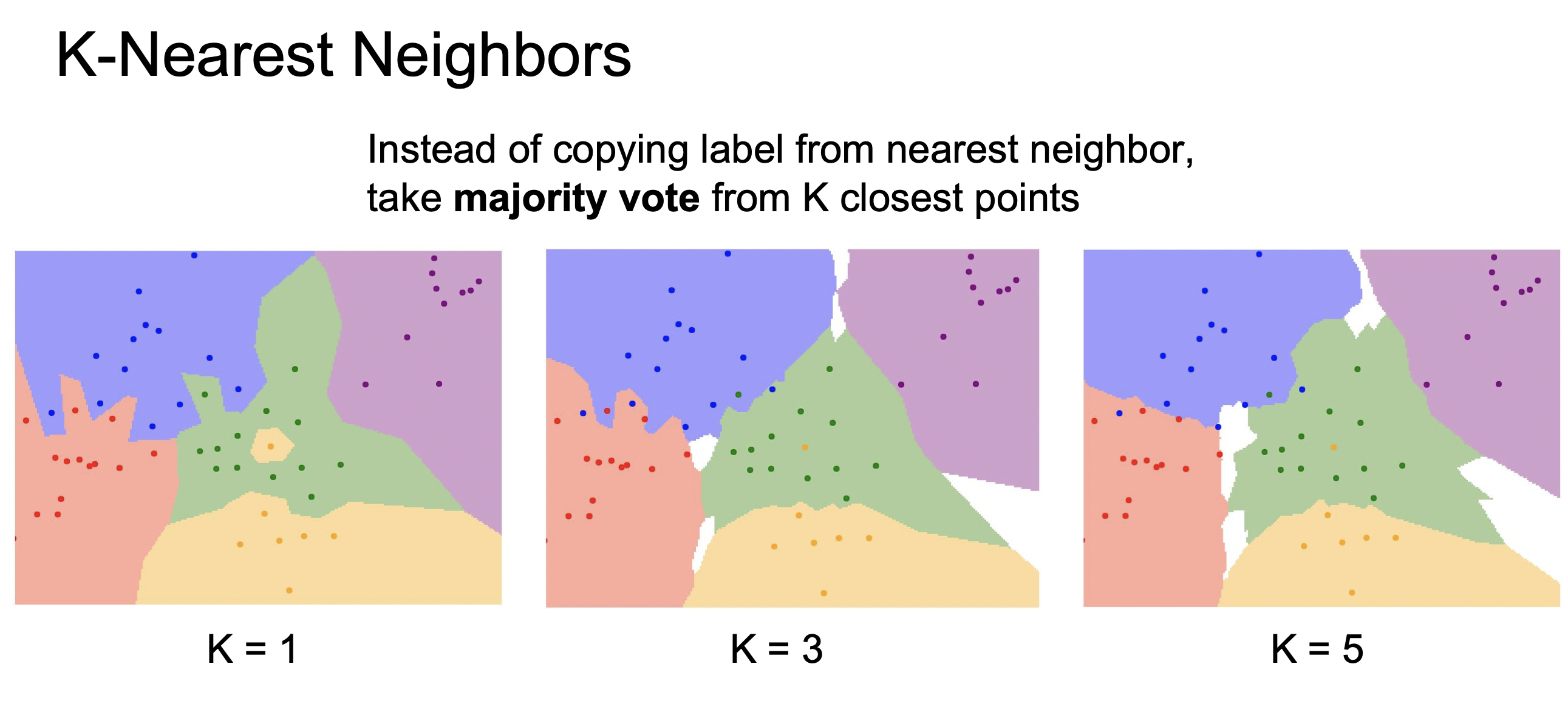
KNN은 가장 가까운 이웃 K개를 측정해서 가장 많은 데이터가 속한 곳으로 분류하는 방식이다.
이웃을 하나만 뽑은 가장 왼쪽의 그림을 보면 녹색 영역 가운데 노란색 으로 잘 분류된 영역이나, 파란색과 녹색 영역 경계의 한 데이터가 잘못 분류 된 것을 알 수 있다. 이처럼 잡음의 문제를 해결하기 위해 1개가 아닌 K개를 측정하는 방식을 따른다.
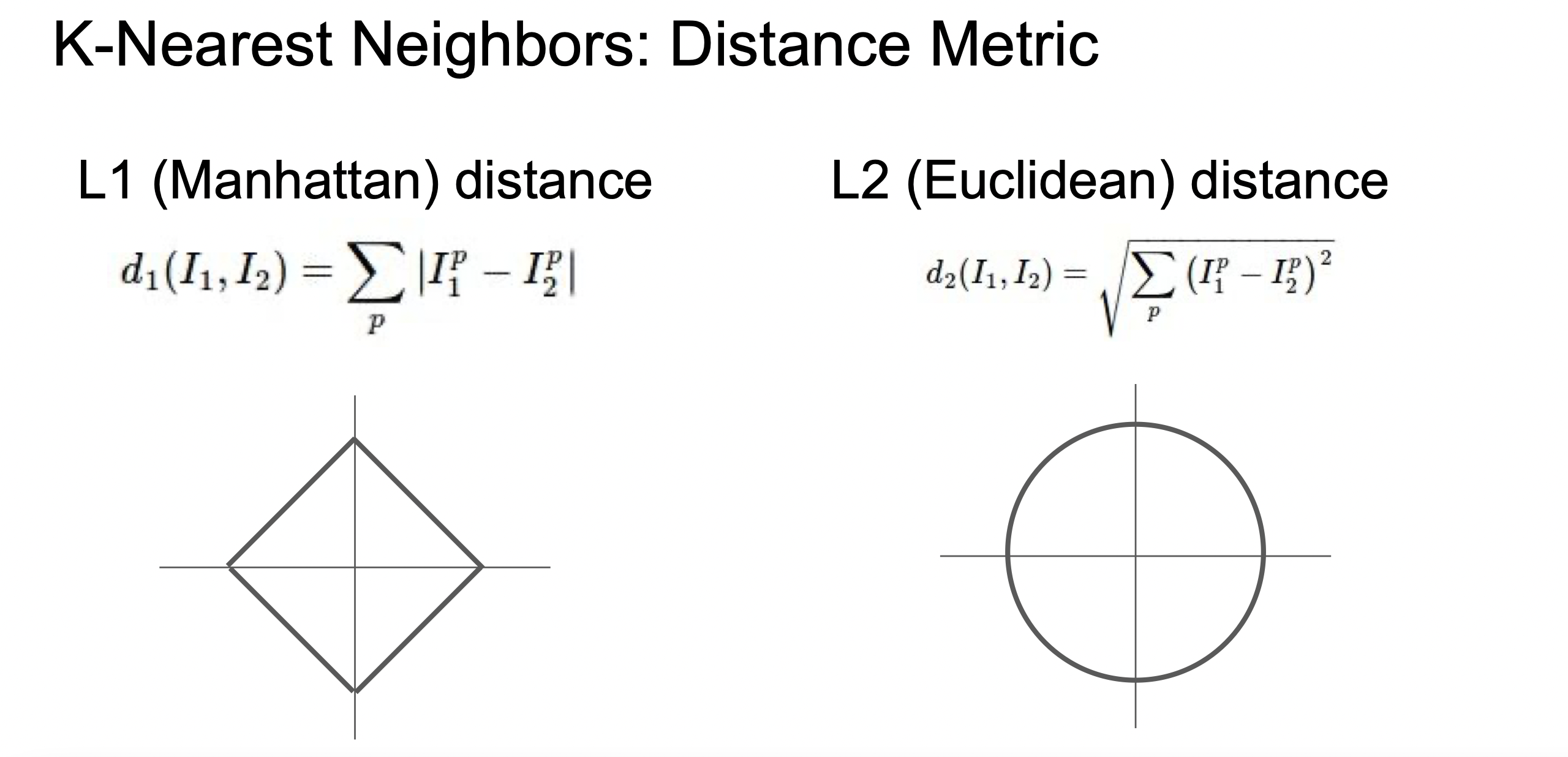
거리를 측정하는 방식은 두 가지 이다.
1) L1 distance : 각 픽셀의 차이의 절댓값
2) L2 distance : 각 픽셀의 차이의 제곱의 합의 제곱근
L1은 좌표계에 영향을 받기 때문에 키, 몸무게 같이 각각 요소들이 개별적인 의미를 가지고 있는 경우 사용하면 좋다.
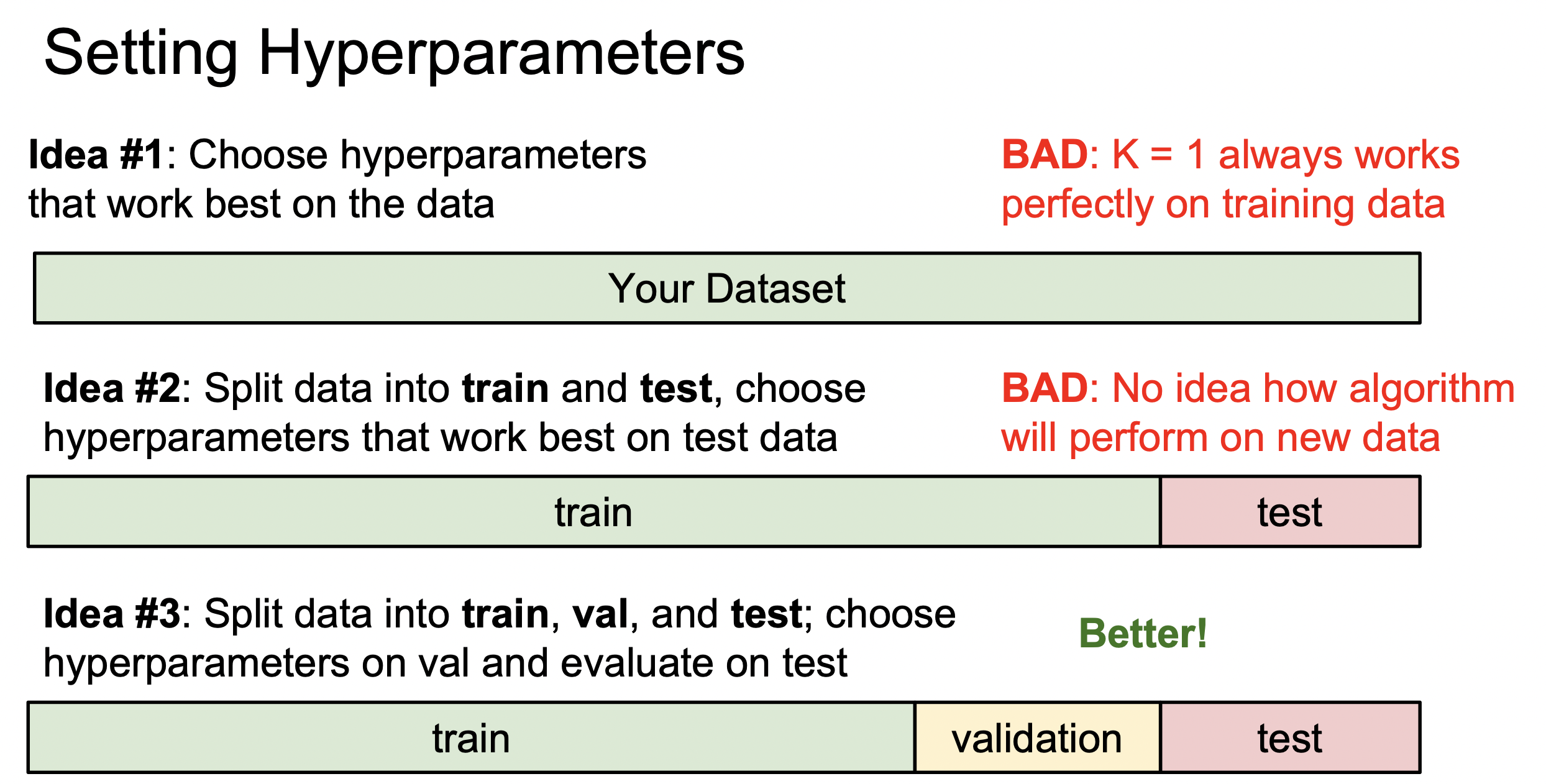
하이퍼파라미터 - KNN은 하이퍼파라미터를 설정해야하는데, k의 값(k개의 이웃)과, 거리를 측정하는 방식(L1 or L2)을 정해야 한다.
또한, 목표는 새로운 데이터를 잘 분류하는 것이기 때문에 기존의 훈련 데이터만 잘 분류하는 것은 의미가 없기 때문에 검증 데이터, 테스트 데이터로 나눈다.
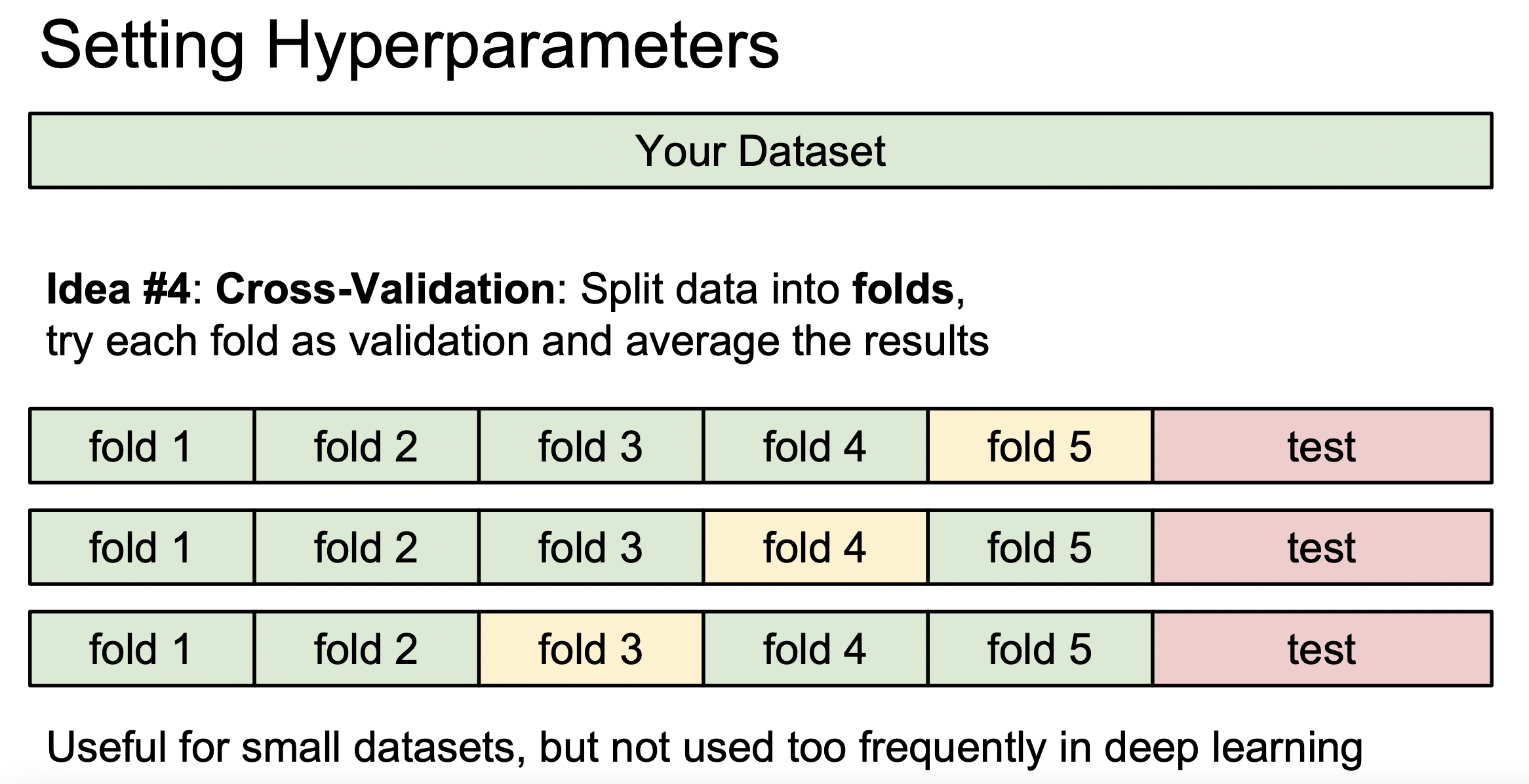
데이터가 적은 경우에는 교차 검증을 사용하기도 한다.
KNN은 이미지에서 절대 사용하지 않는다. 이유는 다음과 같다.
1. 엄청 느리고, "지각적 유사도"를 측정하기에 적합 하지 않다.
2. 차원의 저주 : 차원이 늘어날때마다 기하급수적으로 공간을 채울 데이터들이 필요해지는데, 현실적으로 충분한 양의 학습 데이터를 가지고 있기가 어렵다.
2. Linear Classification
KNN에서는 모든 트레이닝 셋을 테스트할 때 사용한다. 하지만, Linear Classification(선형분류)에서는 Parametric Approach를 사용한다.
Parrametrict Approach에서는 트레이닝 데이터의 정보를 요약한다.
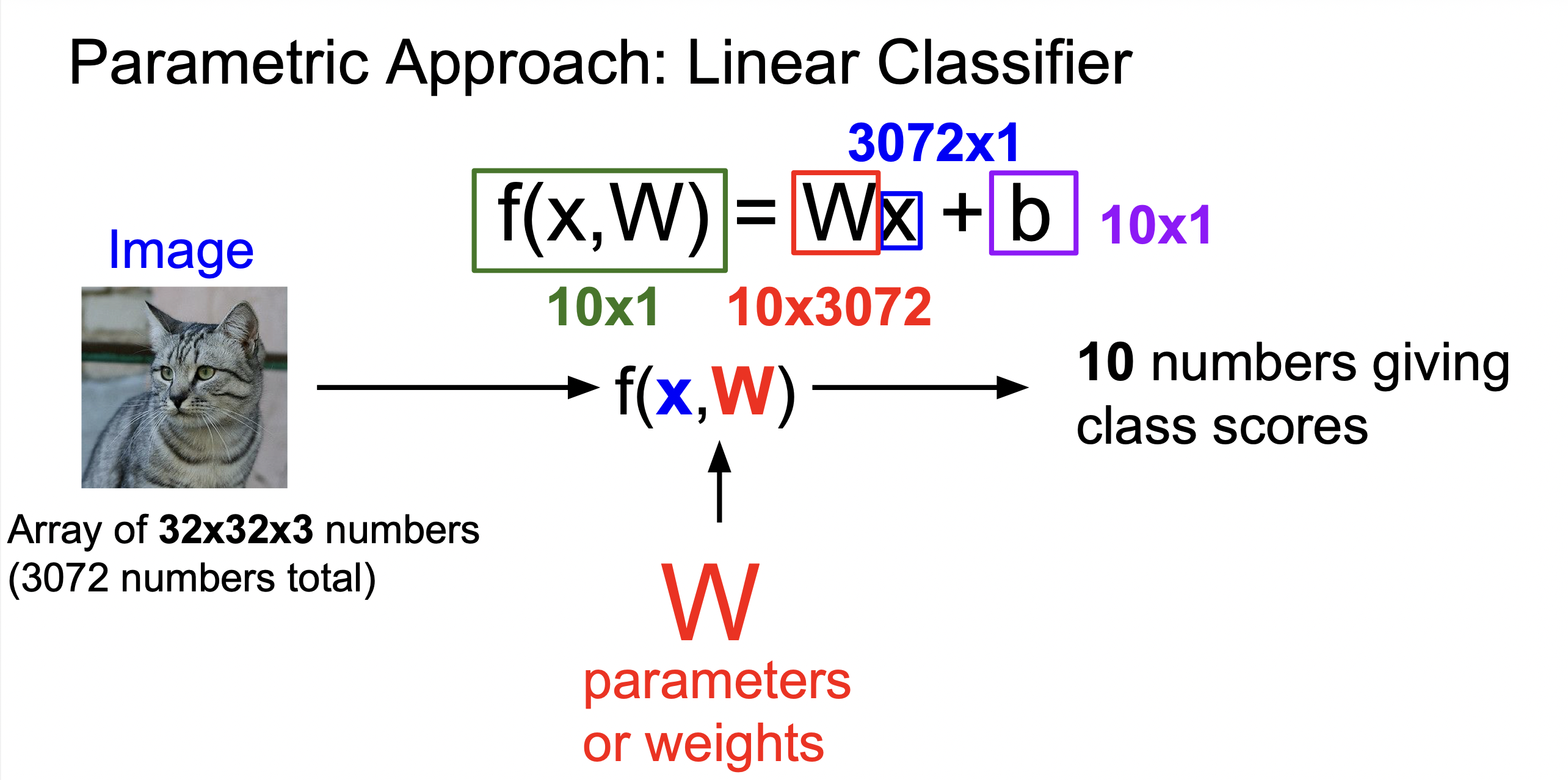
고양이의 픽셀의 수가 통틀어 3072개이고, 개, 고양이, 배 등등 10가지의 다른 라벨로 분류한다고 한다면, 위의 그림처럼 계산을 해준다. b는 bias(편향)인데, 만약에 고양이 사진이 적고 개 사진이 많다면, 개로 분류할 가능성이 높기 때문에 개보다 고양이에 더 큰 점수를 부여하는 것이 b의 역할이다.
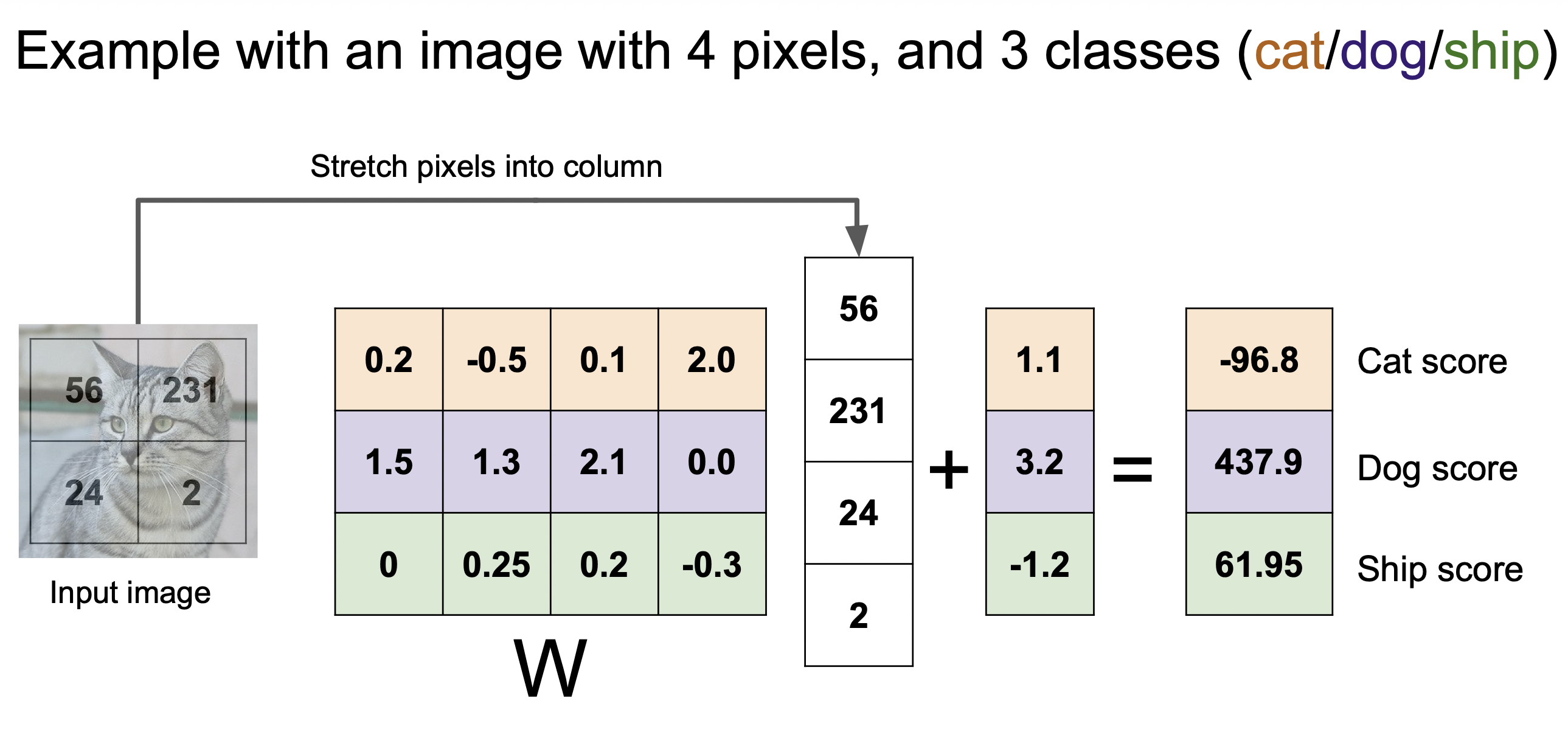
4개의 픽셀을 가진 이미지를 3개 클래스로 분류하는 예시이다.

각 훈련된 가중치들을 보면 어렴풋이 라벨의 모습을 하고 있음을 알 수 있다.
키워드 : KNN, L1, L2, 하이퍼파라미터, 교차검증, Linear Classification(선형분류), 가중치
