쿼리에 간접적으로 영향을 줄 수 있는 인덱스와 제약조건constraint 기능에 대해 알아보자.
인덱스 Index
비개발자라도 인덱스는 다들 들어봤을 것이다. 색인 같은 것을 생각했다면 그게 맞다.
MySQL은 기본적으로 데이터를 검색할 때 첫 번째 필드부터 차례대로 훑으면서 내려간다. 즉, 내가 쿼리를 쓰면 그 쿼리의 결과값을 보여주기 위해 1개 이상의 테이블을 처음부터 끝까지 다 훑는다는거다. 내가 지금까지 썼던 쿼리들은 테이블의 행이 적기 때문에 금방금방 돌아갔는데, 테이블에 3,000,000개의 행이 있다고 생각해보면... 🤦🏾♀️ 괴로워진다.
인덱스의 사용목적은 테이블 내의 데이터를 빠르게 찾기 위해서다. 사람이 인덱스를 이용해서 빠르게 책의 원하는 곳으로 가는것처럼, 데이터베이스 서버는 인덱스를 사용해 빠르게 테이블의 행을 찾는다.
인덱스 생성
책 + 구글링해보니 2가지 방법이 있는 것으로 보인다.
CREATE INDEX 인덱스이름
ON 테이블이름 (열이름) ; 혹은,
ALTER TABLE 테이블이름
ADD INDEX 인덱스이름 (열이름) ; SHOW 명령어로 인덱스를 조회할 수도 있다.
SHOW INDEX FROM 테이블이름 ; 기본적으로 서버는
PRIMARY KEY의 인덱스는 자동 생성하고,PRIMARY라는 이름을 부여한다.
고유 인덱스 Unique Index
데이터베이스를 설계할 때는 중복 데이터를 포함할 수 있는 열과 그렇지 않은 열을 고려하는게 중요하다.
- 고유인덱스는 인덱스열에 중복값을 허용하지 않는다.
- 행이 삽입되거나, 인덱스 열이 수정될 때마다 서버는 고유인덱스를 확인하여 테이블의 다른 행에 값이 이미 있는지를 확인한다.
- 따라서 고유인덱스가 이미 존재하는 값인데 새 행으로 추가하려고 하면 오류가 발생한다.
다중 열 인덱스
두 열을 사용해서 인덱스를 만들 수 있다. 예를 들면 회원이 많을 경우에는 이름만 아는 것보다, 이름과 생년월일을 동시에 검색하게 하면 더 신속하게 원하는 결과를 찾을 수 있을 것이다.
단, 다중 열 인덱스는 단일 열 인덱스보다 더 비효율적으로
INSERT,UPDATE,DELETE를 수행하기 때문에 신중하게 사용하자. 가급적 업데이트가 안되는 값을 사용하는게 좋다.
인덱스 유형
B-Tree Index
MySQL, 오라클, SQL 서버는 디폴트로 B-Tree Index를 사용한다. B-Tree 인덱스는 잎 노드leaf node와 하나 이상의 가지 노드branch node 레벨이 있는 트리tree로 구성된다.
- 가지 노드 : 트리 탐색에 사용됨
- 잎 노드 : 실제 값과 위치 정보를 가짐
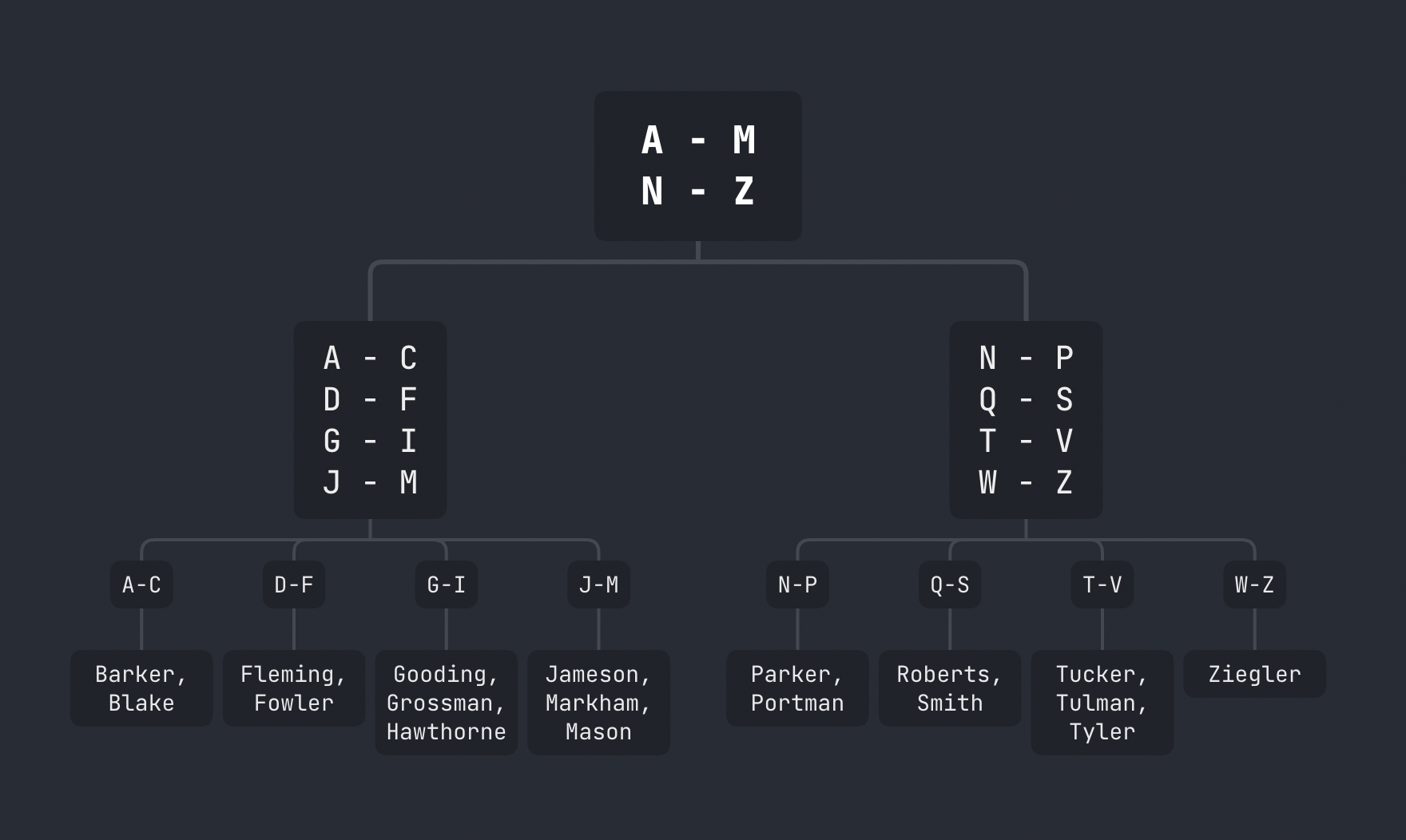
예를 들어 customer.last_name 열에 생성된 B-Tree 인덱스는 위 그림과 같을 것이다. 만약 성이 G로 시작하는 모든 고객을 검색하는 쿼리를 실행한다면 서버는,
- 최상위 가지 노드(루트 노드 root node)를 살펴본다
- A-M의 가지 노드를 따라간다
- G-I의 가지 노드를 따라간다
- G로 시작하지 않는 값을 만날때까지 잎 노드의 값을 읽는다 (
Hawthorne)
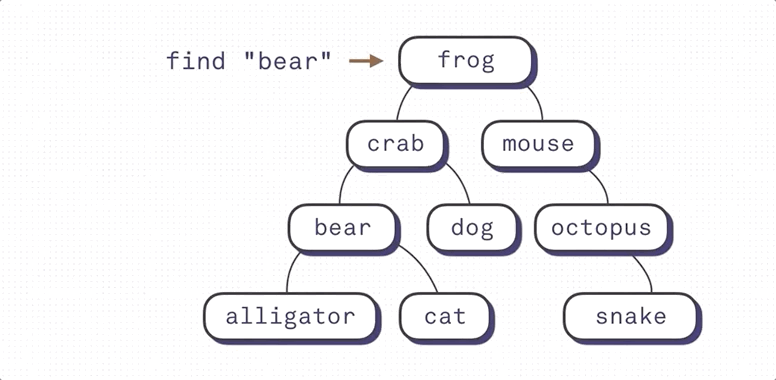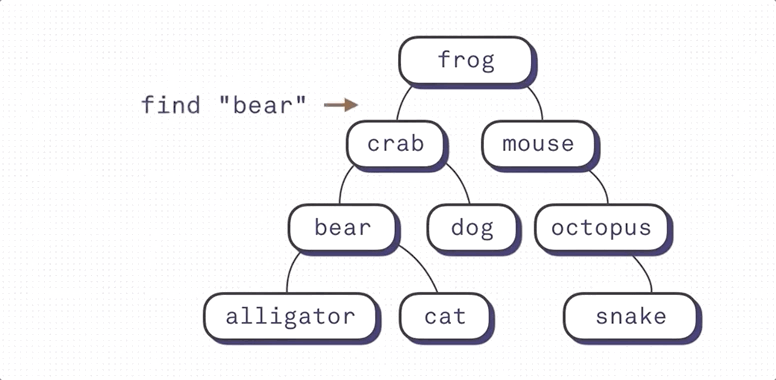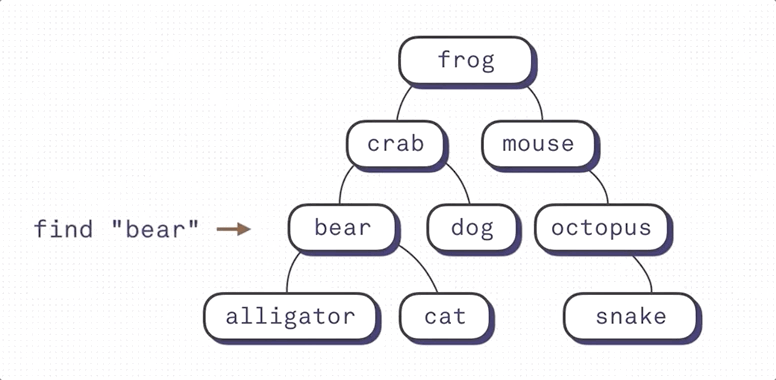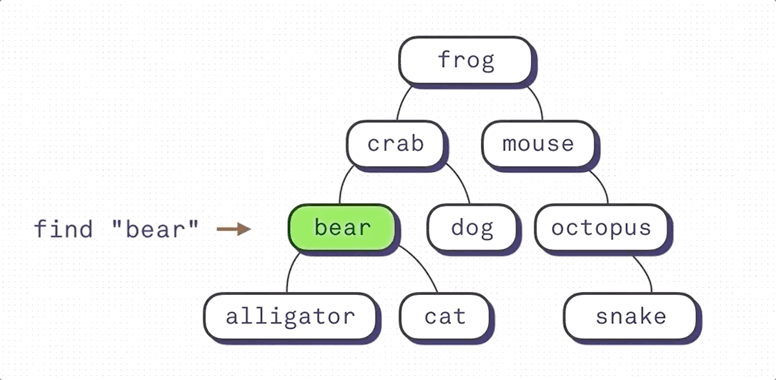
Binary Search Index의 작동방식에 대해 잘 설명한 그림이다. (출처: https://shrtm.nu/F5Qi) B-Tree Index는 Binary Search Index의 한계를 극복한 자료구조다.
B-Tree 인덱스가 균형 트리 인덱스balanced-tree index로도 불리는 이유는 서버가 테이블에 행이 삽입, 업데이트, 삭제 됨에 따라 값을 균등하게 재분배해 트리의 균형을 유지하려 하기 때문이다.
비트맵 인덱스
비트맵 인덱스는 MySQL에서는 지원하지 않는다.
만약 활성화고객은 1, 비활성화고객은 0으로 나타낸 인덱스가 있다고 하자. 정상적인 서비스라면 활성화고객 수가 훨씬 많을 것이기 때문에 0보다 1의 갯수가 훨씬 많아질꺼고, 균형을 유지하기 어렵다.
따라서 많은 양의 데이터가 상대적으로 적은 값을 포함하는 열의 경우 다른 종류의 인덱스가 필요하다. 이때 사용하는게 비트맵 인덱스이다. (예: 영업 분기, 지역, 제품코드 등)
텍스트 인덱스
DB에 문서가 저장된 경우, 해당 문서에서 특정 단어나 구문을 검색하도록 지원해야 할 수 있다. MySQL에서는 풀텍스트 인덱스full-text index라는게 있다.
인덱스 사용
MySQL 서버 옵티마이저가 쿼리 실행을 결정하는 방법을 EXPLAIN 명령어로 확인해보자.
SELECT
customer_id
, first_name
, last_name
FROM customer
WHERE first_name LIKE 'S%'
AND last_name LIKE 'P%' ;위의 쿼리의 경우 서버는 다음 전략 중 1가지를 사용할 수 있다.
- Customer 테이블의 모든 행을 스캔한다.
last_name열의 인덱스를 사용해 성이 P로 시작하는 모든 고객을 찾는다. → Customer 테이블의 각 행을 읽어서 이름이 S로 시작하는 행만 찾는다.last_name과first_name열의 인덱스를 사용해 성이 P로 시작하고, 이름이 S로 시작하는 모든 고객을 찾는다.
3번이 가장 합당해보인다. 실제로 MySQL 서버 옵티마이저의 쿼리 실행 계획을 확인해보자.
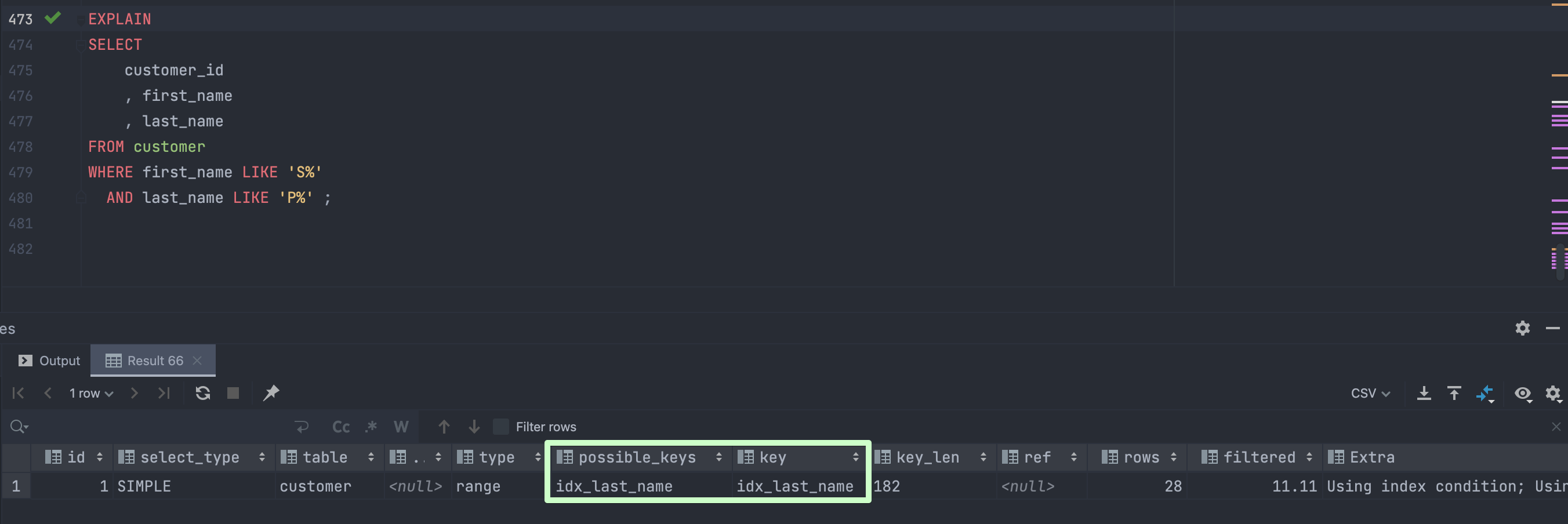
key열에서 last_name 인덱스를 통해 쿼리가 실행될 것임을 알 수 있다. 또 type 열을 보면 range라고 나와있다. 범위 스캔이 사용될 것이라는 뜻이다. 즉, 데이터베이스 서버는 하나의 행을 검색하는 대신 인덱스에서 값의 범위를 찾는다.
인덱스의 단점
더 많은 인덱스가 반드시 좋은 것은 아니다. 모든 인덱스는 결국 특수한 유형의 테이블이기 때문이다. 즉, 테이블에서 행을 추가하거나 삭제할 때마다 해당 테이블의 모든 인덱스도 수정해야 한다. 따라서 인덱스가 많을수록 서버가 모든 스키마를 최신 상태로 유지하기 위해 더 많은 작업을 수행해야 하므로 속도가 느려진다.
좋은 전략
- 모든 Primary Key 열에 인덱스가 만들어져 있는지 확인한다.
- 다중 열 PK의 경우에는 PK 열의 서브셋 or 모든 PK 열에 대해 PK 제약조건 정의와 다른 순서로 추가 인덱스를 생성하는 걸 고려해볼 수 있다.
- FK 제약조건에서 참조되는 모든 열에 대해 인덱스를 작성한다.
- 서버는 부모 행이 삭제될 때 자식 행이 없는지 확인해야 한다.
- 열에 인덱스가 없다면 전체 테이블을 스캔해야 한다.
- 데이터 검색에 자주 사용되는 열을 인덱싱한다.
- 단순 보고서 작성을 위한 것이라면, 업무 시간 전에 인덱스를 생성하고 업무시간 이후에는 데이터 로드에 문제가 되지 않도록 인덱스를 삭제한다.
제약조건
제약이란 테이블의 하나 이상의 열에 적용되는 제한사항이다.
제약조건은 데이터베이스가 일관성을 가질 수 있게 해준다. 예를 들어 rental 테이블에서 동일한 고객ID를 변경하지 않고, customer 테이블에서만 고객ID를 변경할 수 있도록 허용한다면(=제약조건이 없다면), 유효하지 않은 고객ID의 대여 데이터가 생길꺼다. 즉, 고아 행orphan row이 생긴다.
- PK 제약조건 : 테이블 내에서 고유성을 보장하는 열을 식별
- FK 제약조건 : 다른 테이블의 PK 열에 있는 값만 포함되도록, 하나 이상의 열을 제한
- 고유 제약조건 : 테이블 내에서 고유한 값을 포함하도록 하나 이상의 열을 제한 (PK 제약조건은 특별한 유형의 고유 제약조건)
- 체크 제약조건 : 열에 허용되는 값 제한
제약조건 생성
제약조건은 보통 CREATE TABLE 문을 통해 테이블과 동시에 생성된다.
시리즈 거의 첫 부분에서 Table 만들기 를 했었는데 이때 테이블을 만드는 과정은 이랬다.
- 설계 : 테이블에 들어갈 정보들을 항목화한다.
- 정제 : 정규화한다. (DB설계에 중복 또는 복합 열이 없는지를 확인한다)
- 스키마문 활용 : 테이블을 만든다.
아래와 같은 스키마를 생성한다고 가정했을 때, 제약조건은 3가지가 포함된다.
CREATE TABLE customer (
customer_id SMALLINT UNSIGNED AUTO_INCREMENT NOT NULL
, store_id TINYINT UNSIGNED NOT NULL
, first_name VARCHAR(45) NOT NULL
, last_name VARCHAR(45) NOT NULL
, email VARCHAR(50) DEFAULT NULL
, address_id SMALLINT UNSIGNED NOT NULL
, active BOOLEAN NOT NULL DEFAULT TRUE
, create_date DATETIME NOT NULL
, last_update TIMESTAMP DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP
, PRIMARY KEY (customer_id)
, KEY idx_fk_store_id (store_id)
, KEY idx_fk_address_id (address_id)
, KEY idx_fk_last_name (last_name)
, CONSTRAINT fk_customer_address FOREIGN KEY (address_id)
REFERENCES address (address_id) ON DELETE RESTRICT ON UPDATE CASCADE
, CONSTRAINT fk_customer_store FOREIGN KEY (store_id)
REFERENCES store (store_id) ON DELETE RESTRICT ON UPDATE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;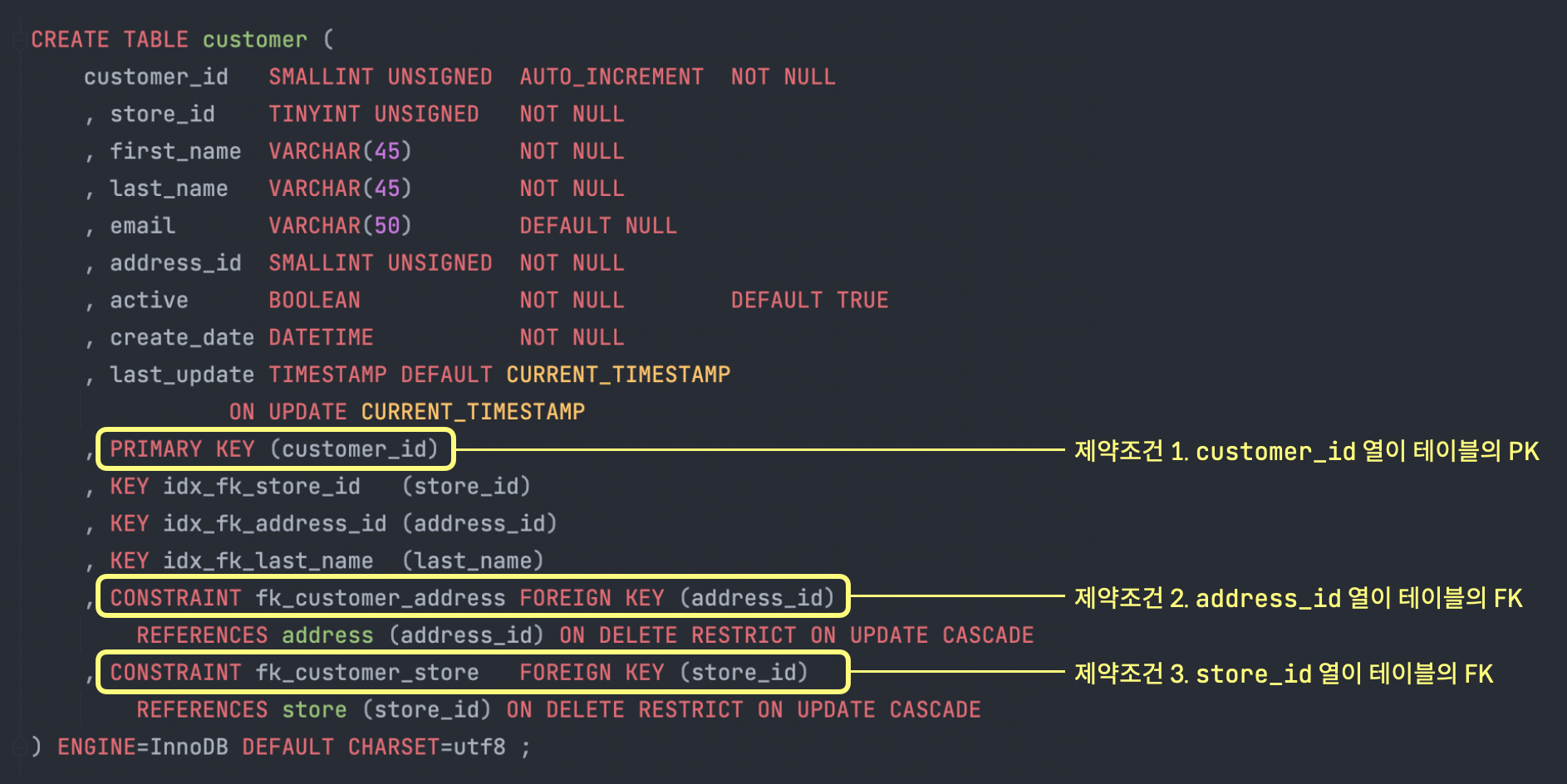
FK 제약조건의 경우, CREATE TABLE문으로도 설정할 수 있고, 일단 테이블 생성 후 ALTER TABLE문으로 추가할수도 있다.
ALTER TABLE customer
ADD CONSTRAINT fk_customer_address FOREIGN KEY (address_id)
REFERENCES address (address_id) ON DELETE RESTRICT ON UPDATE CASCADE ;
ALTER TABLE customer
ADD CONSTRAINT fk_customer_store FOREIGN KEY (store_id)
REFERENCES store (store_id) ON DELETE RESTRICT ON UPDATE CASCADE ; 이 때 여러개의 ON 절이 포함되어 있는데 의미는 이렇다.

위의 쿼리예제에서는, 자식테이블은 customer가 되고 부모테이블은 address 또는 store가 된다.
ON DELETE RESTRICT절은 부모테이블에서 행이 삭제될 때 고아 행이 발생하는 것을 막아준다.ON UPDATE CASCADE절은 부모테이블에서 PK값이 수정될 때, 자동으로 자식테이블을 업데이트함으로써 고아 행이 발생하는 것을 막아준다.
외래키가 포함된 테이블을 자식 테이블이라고 하고 외래키 값을 제공하는 테이블을 부모 테이블이라한다.
Foreign Key 제약조건을 정의할 때 선택옵션
ON DELETE RESTRICTON DELETE CASCADEON DELETE SET NULLON UPDATE RESTRICTON UPDATE CASCADEON UPDATE SET NULL
선택사항이며 ON DELETE에서 0개 또는 1개 + ON UPDATE에서 0개 또는 1개를 각각 선택할 수 있다.
