{kind=link}
여러 데이터셋을 결합할 수 있는 union , intersect , except 집합 연산자를 사용하는 방법을 알아보자.
집합이론 (기초)
중1에 처음 배웠던 듯 한.... 집합에 대해 짚고 넘어가자.
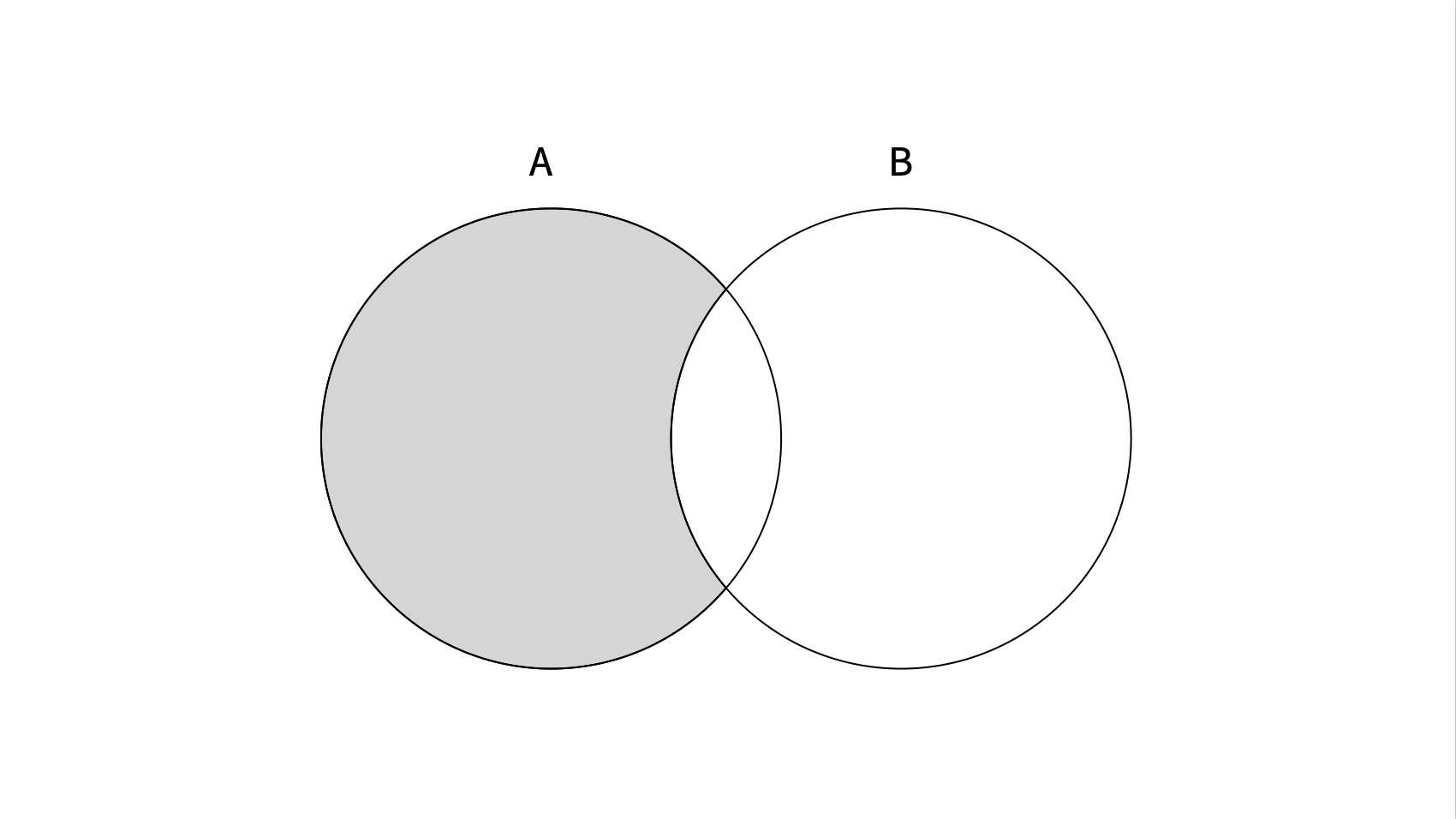
합집합 : union 연산
색이 칠해진 부분 = A union B
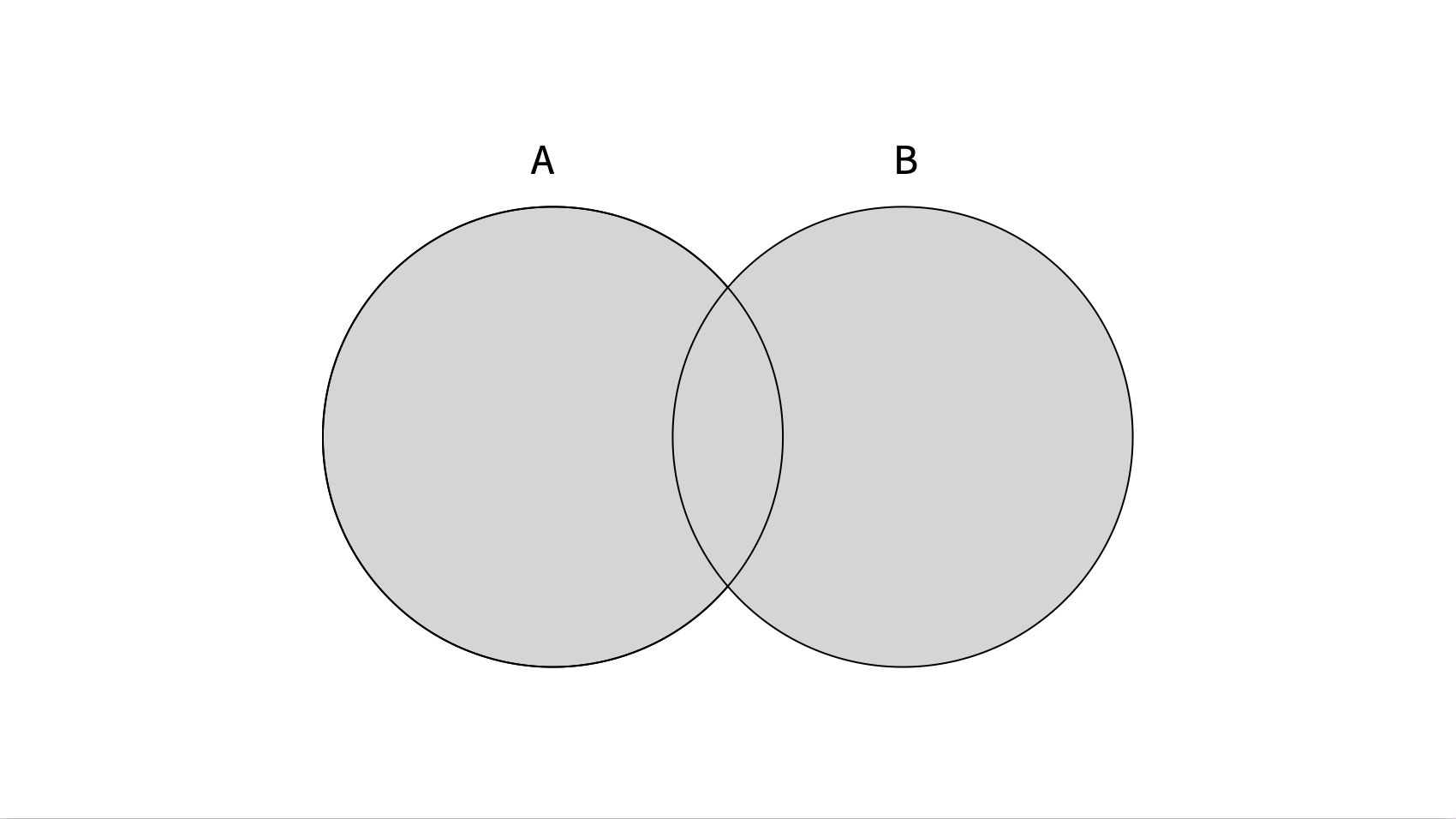
교집합 : intersect 연산
색이 칠해진 부분 = A intersect B
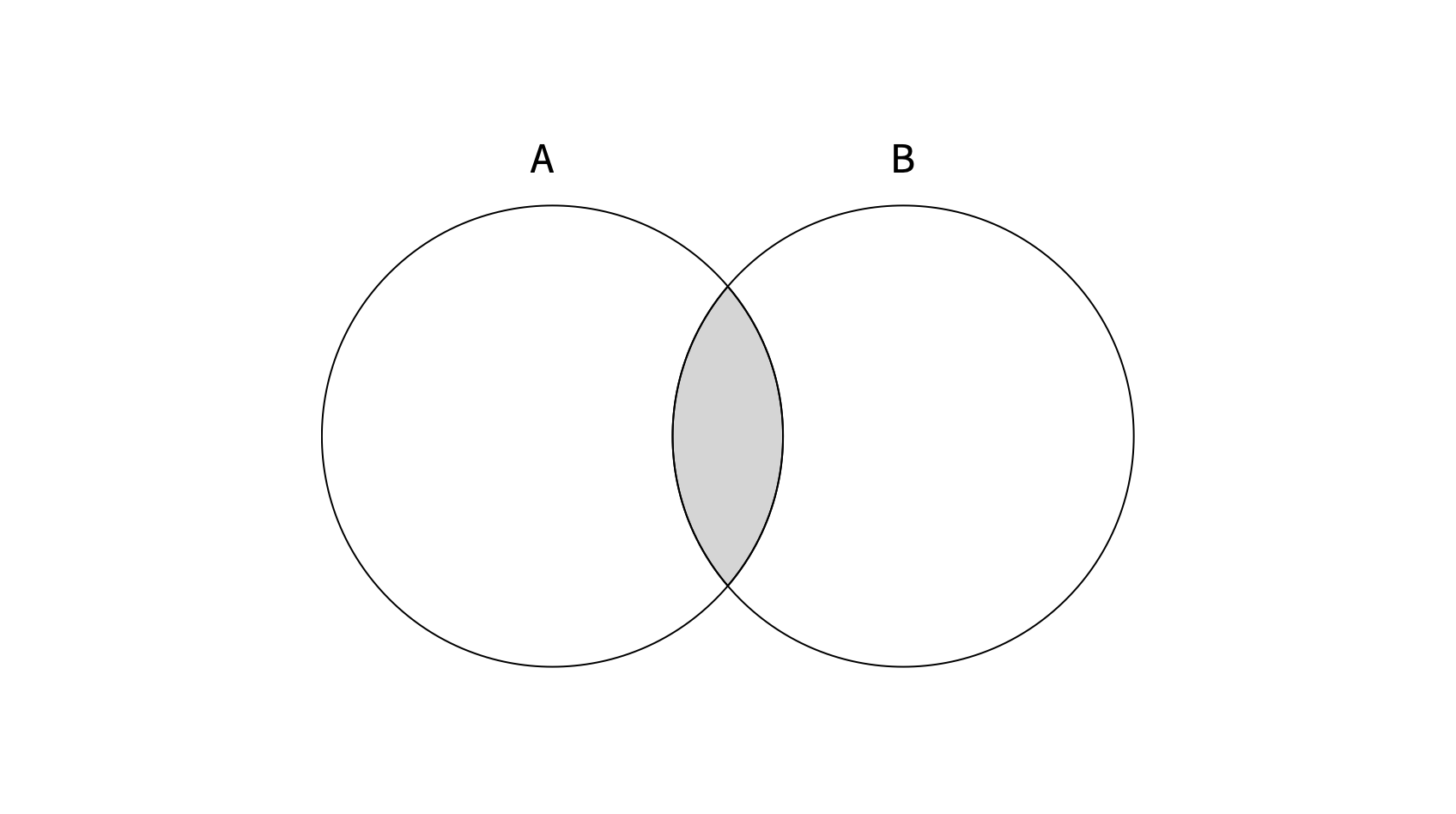
차집합 : except 연산
색이 칠해진 부분 = A except B
집합 A에서 집합 B와 겹치는 부분을 뺀 결과를 보여준다.
그렇다면 아래와 같은 대칭차집합은 어떻게 만들 수 있을까?
위의 3가지 연산을 사용하거나, 서로 다른 연산을 결합해 만들 수 있다.
방법은 여러개가 있겠지만...
A와 B를 모두 포함하는 합집합에서 교집합 부분만 제거할 수도 있다.
(A Union B) except (A intersect B)또는 A에서 B를 뺀 차집합과, B에서 A를 뺀 차집합의 합으로 구할 수도 있다.
(A except B) union (B except A)집합 연산을 사용할 때 주의할 점
실제 데이터를 다룰 때는, 결합할 데이터 집합의 구성을 살펴봐야한다.
예를 들면 문자가 포함된 숫자열 <-> 날짜가 포함된 숫자열 처럼, 서로 다른 열의 쌍을 결합하는 방법이 명확하지 않으면 안된다.
따라서 결합하려는 데이터셋 사이에는 반드시 공통점이 있어야 한다.
다음 규칙을 적용하자.
- 두 데이터셋 모두 같은 수의 열을 가져야 한다.
- 두 데이터셋의 각 열의 자료형은 서로 동일해야 한다. (또는 서버가 서로 변환할 수 있어야 한다)
집합 연산자
3가지 집합 연산자 (union, intersect, except)는 각각 2가지로 나뉜다.
- 중복을 포함하는 버전
- 중복을 제거하는 버전
❶ union 연산자
- 중복을 포함하는 버전 :
UNION ALL - 중복을 제거하는 버전 :
UNION
예를 들어, customer 테이블과 actor 테이블에서 이니셜이 JD 인 사람 전체를 뽑고 싶다고 하자.
SELECT
c.first_name
, c.last_name
FROM customer c
WHERE c.first_name LIKE 'J%'
AND c.last_name LIKE 'D%'
UNION ALL
SELECT
a.first_name
, a.last_name
FROM actor a
WHERE a.first_name LIKE 'J%'
AND a.last_name LIKE 'D%' ;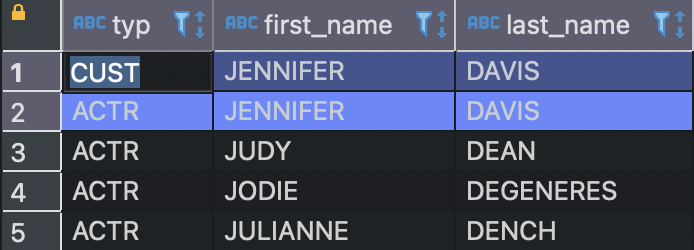
UNION ALL 연산자를 사용했기 때문에 JENNIFER DAVIS가 중복되었더라도 그대로 결과셋에 반환된다. (어느 테이블의 값인지를 표시해주고 싶어서 typ이라는 별칭으로 각각 'CUST', 'ACTR'를 붙여주었다)
만약 중복행을 제외하고 싶다면, 아래와 같이 UNION 연산자를 사용한다.
SELECT
c.first_name
, c.last_name
FROM customer c
WHERE c.first_name LIKE 'J%'
AND c.last_name LIKE 'D%'
UNION
SELECT
a.first_name
, a.last_name
FROM actor a
WHERE a.first_name LIKE 'J%'
AND a.last_name LIKE 'D%' ;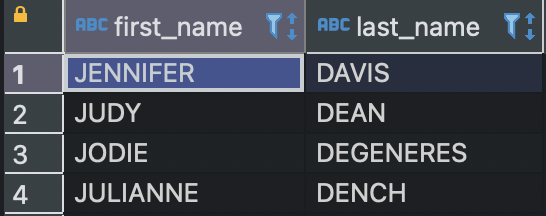
중복을 제외한 4개의 고유한 이름만 결과값에 포함되는걸 알 수 있다.
❷ intersect 연산자
MySQL 버전 8.0은 INTERSECT 연산자를 지원하지 않는다. (ANSI SQL 사양에서 지원) 오라클 또는 SQL 서버 2008을 사용할 경우에는 intersect 연산자를 사용할 수 있다.
예를 들어, customer 테이블과 actor 테이블에서 동일하게 이니셜이 JD인 교집합을 뽑고 싶다고 하자.
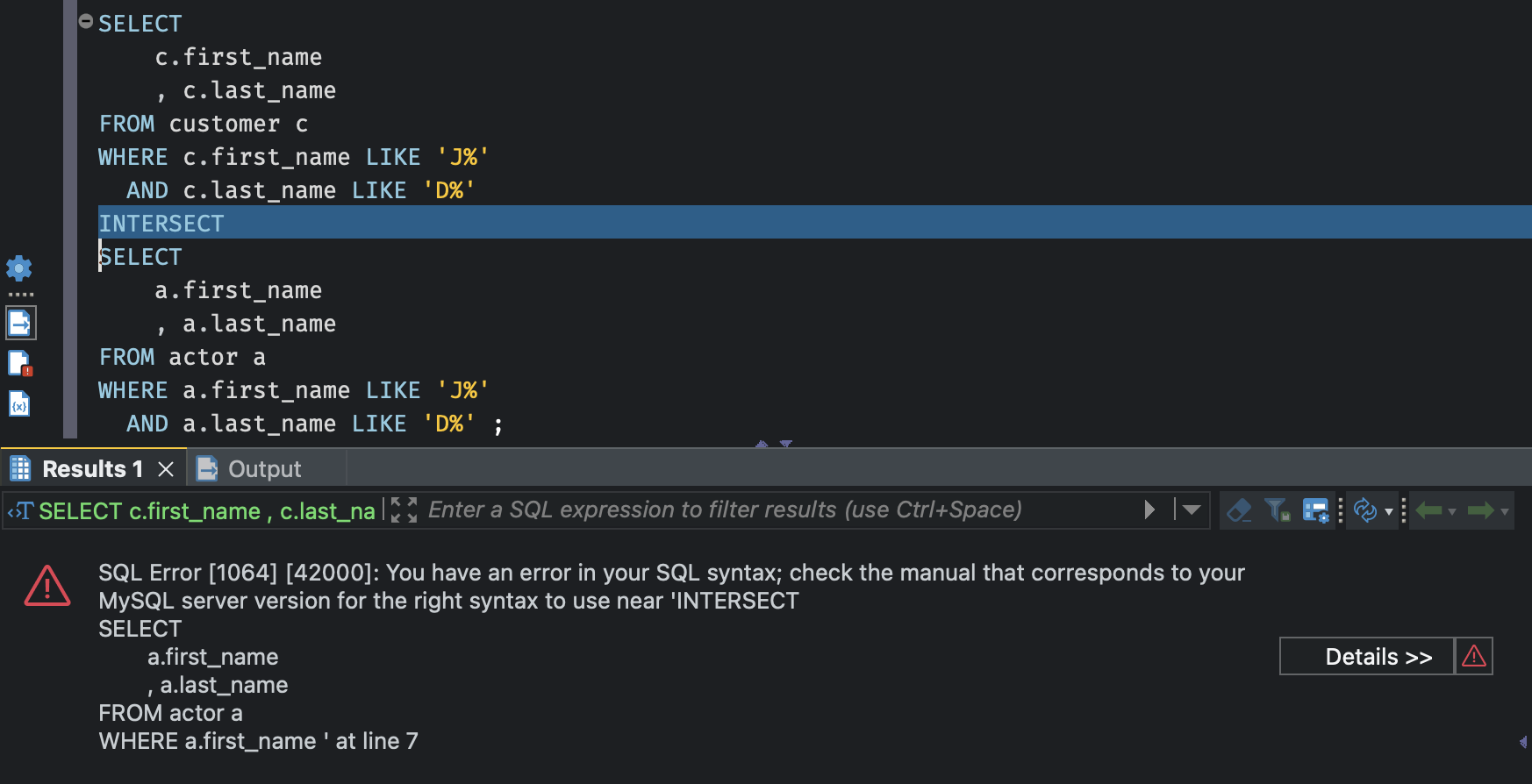
INTERSECT 연산자 때문에 에러가 발생한다.
이 경우에는 INNER JOIN으로 같은 결과를 뽑아낼 수 있다는 글을 보았다...
SELECT
c.first_name
, c.last_name
FROM customer c
INNER JOIN actor a
ON c.first_name = a.first_name
AND c.last_name = a.last_name ;
1개의 결과값이 반환된다.
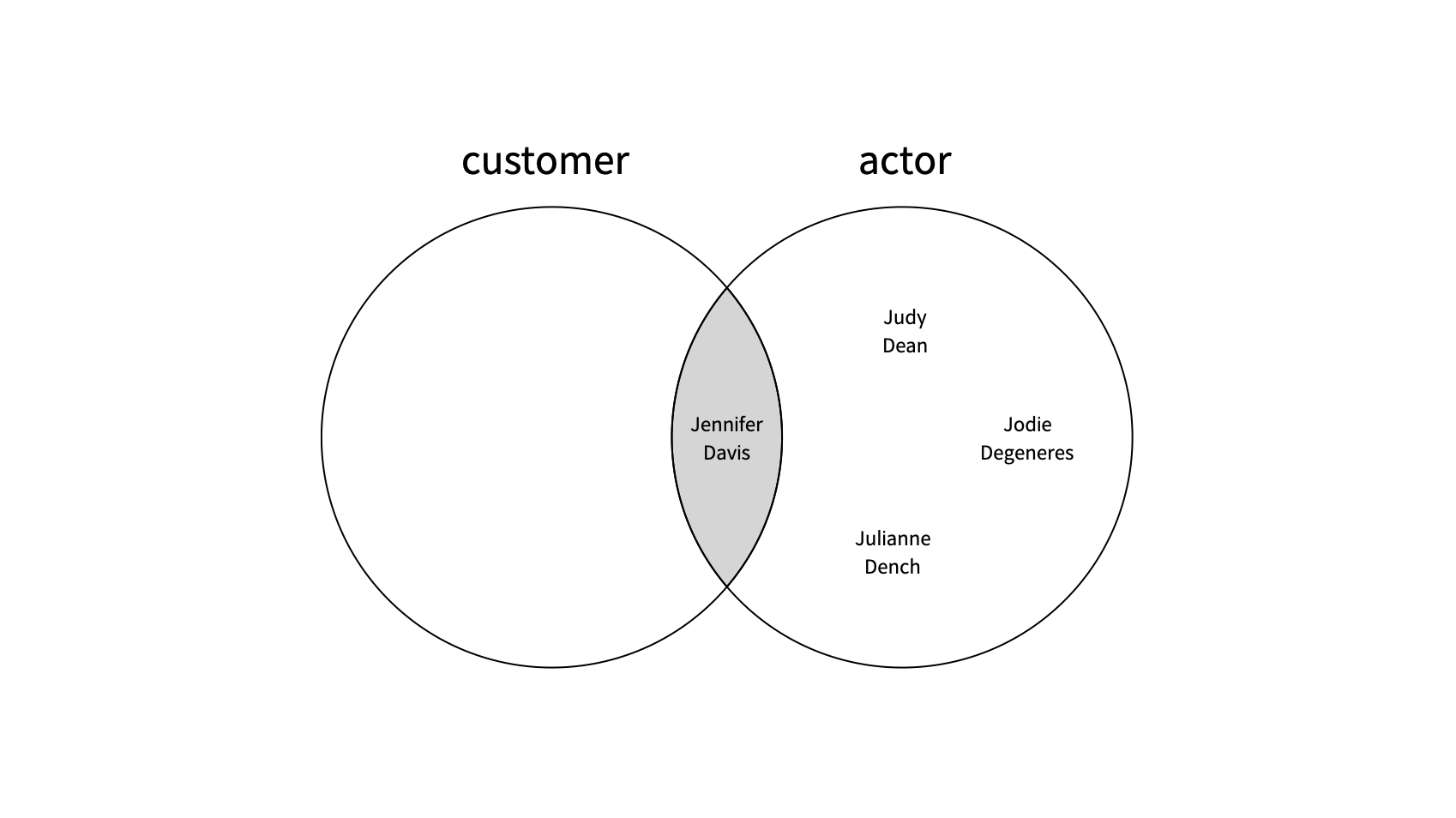
❸ except 연산자
EXCEPT 연산자도 MySQL 버전 8.0에서 지원되지 않는다.
오라클 데이터베이스를 사용할 경우, ANSI와 호환되지 않는
minus연산자를 사용해야 한다.
예를 들어, customer 테이블과 actor 테이블에서 이니셜이 JD인 사람들의 차집합을 뽑고 싶다고 하자. (기준: actor 테이블)
즉, actor 테이블에는 있지만, customer 테이블에는 없는 이니셜인 JD인 사람들을 뽑아내고 싶은거다.
이 경우에는 LEFT OUTER JOIN(또는 RIGHT OUTER JOIN)을 이용하여 같은 결과를 뽑아낼 수 있다.
단,
MINUS집합 연산은 항상DISTINCT하게 중복 레코드를 제거하고 리턴하기 때문에SELECT의 최종 결과에DISTINCT를 붙혀 줘야 다른 DBMS의MINUS와 동일한 결과를 얻을 수 있다.
SELECT
a.first_name
, a.last_name
FROM customer c
RIGHT JOIN actor a
ON c.last_name = a.last_name
AND c.first_name = a.first_name
WHERE c.customer_id IS NULL
AND a.first_name LIKE 'J%'
AND a.last_name LIKE 'D%' ;3개의 결과값이 반환된다.
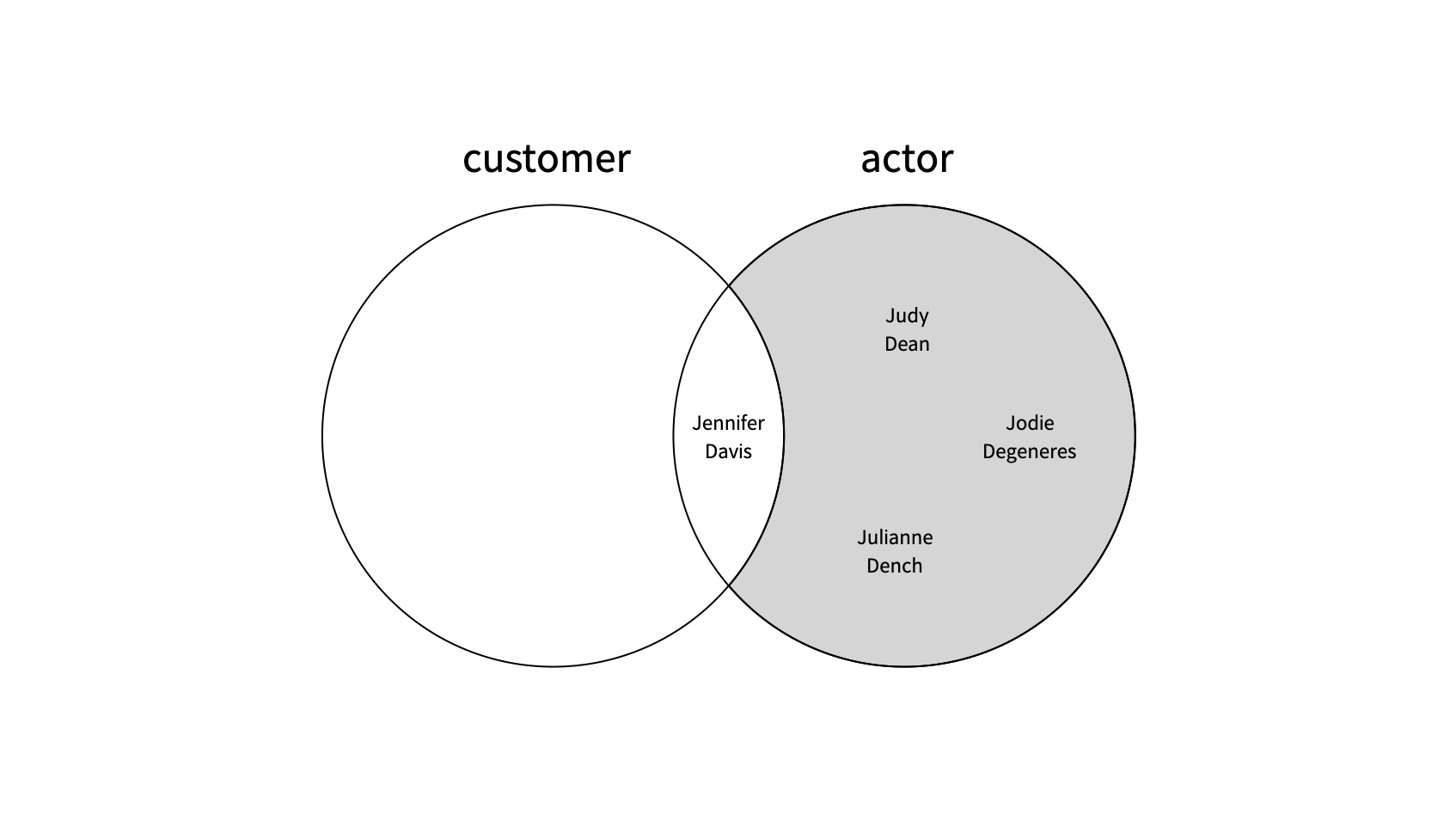
참고 포스팅
RIGHT JOIN 할 때 원하는 교집합의 결과가 나오지 않아 애를 많이 먹었다.
위의 예시에서 WHERE c.customer_id IS NULL 를 써주지 않으면 교집합 부분이 제외되지 않은 결과값이 보여진다. 이때 조건문에는 반드시 PK를 써줘야 한다.
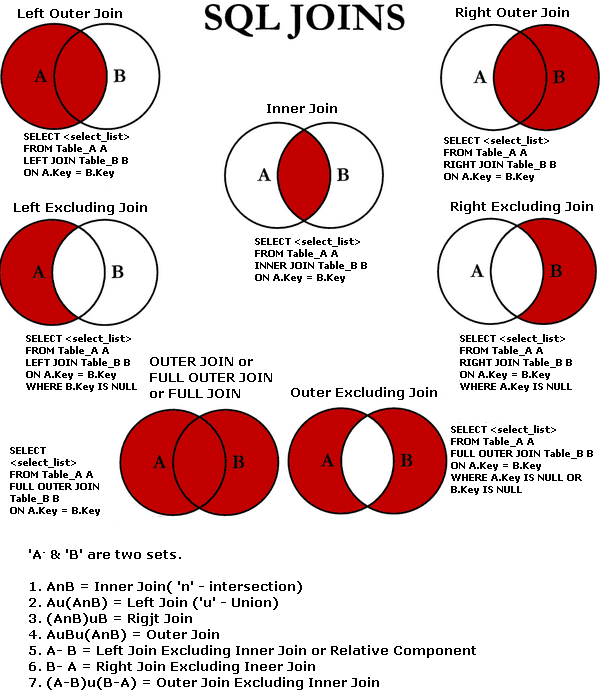
집합 연산 규칙
복합 쿼리로 작업할 때 따라야 하는 몇 가지 규칙을 살펴보자.
여기서 복합쿼리(compound query)란 여러 개의 독립적인 쿼리로 구성된 쿼리를 말한다.
복합 쿼리의 결과 정렬
order by 절을 쿼리 마지막에 추가한다. 이때 열 이름을 정의할 때 복합 쿼리의 첫 번째 쿼리에 있는 열의 이름을 선택해야 한다.
예시:
SELECT
a.first_name AS fname
, a.last_name AS lname
FROM actor a
WHERE a.first_name LIKE 'J%'
AND a.last_name LIKE 'D%'
UNION ALL
SELECT
c.first_name
, c.last_name
FROM customer c
WHERE c.first_name LIKE 'J%'
AND c.last_name LIKE 'D%'
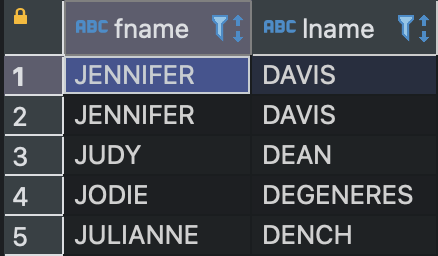
ORDER BY lname, fname ;처음 SELECT문에서 별칭으로 지정한 fname과 lname 기준으로 정렬해야지 오류가 나지 않는다.
lname 기준으로 먼저 정렬되고, 그다음 fname 기준으로 정렬된 결과값을 볼 수 있다.
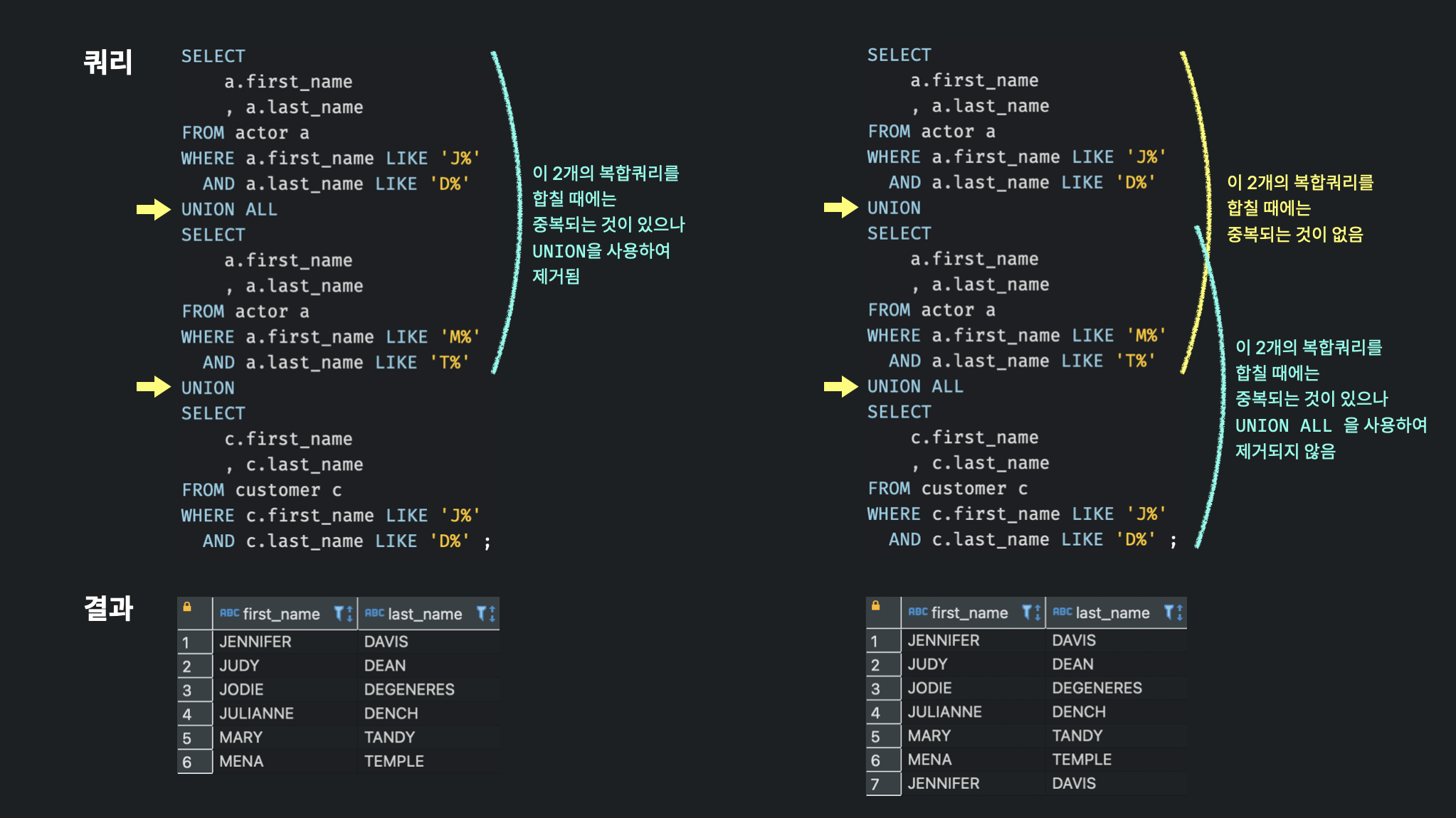
집합 연산의 순서
복합쿼리에서 서로 다른 집합 연산자를 사용하는 2개 이상의 쿼리를 쓸 경우, 순서를 고려해야한다. 연산자가 놓이는 위치에 따라 결과가 달라진다.
UNION과 UNION ALL의 순서를 다르게 쓰면 어떻게 결과가 달라지는지 아래 예시로 확인해볼 수 있다.