자료구조는 윤성우의 열혈 자료구조 교재를 통해 학습할거다.
1장, 자료구조와 알고리즘의 이해
1장이니만큼 정말 기본적인 내용만을 학습했다.
01-1
우선, 자료구조란 무엇인가.
"데이터의 저장"을 담당하는 것 이다. 뭐 예로들면, 문자를 저장하기 위해 char형 변수를 선언한다거나, 구조체를 정의한다거나. 배열을 선언한다거나. 이런게 다 자료구조의 일종이다. 뭐 선형구조, 비선형구조, 뭐시기 뭐시기 등.. 엄청 다양하게 있는데, 이런건 이후에 책을 통해 학습하다보면 접하게 되겠지.
그러면, "알고리즘"은?
알고리즘은, 표현이나 저장된 데이터를 대상으로 "문제의 해결 방법" 을 뜻한다.
만약
int arr[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};이라고 int형 배열을 선언해줬다면, 이 배열 선언 자체는 "자료구조적 측면"의 코드일 것이다. 데이터의 저장을 담당하고 있는 명령문이니까.
for (i=0 ; i<10 ; i++) {
sum += arr[i];
}이렇게 써준다면, 배열에 저장된 값의 합을 구하는 알고리즘이다. 그러면 "알고리즘적 측면"의 코드겠지. 배열에 저장된 0번째 data부터 9번째 data까지 전부 합산해주는 풀이를 보여주고 있는 코드니깐.
근데 이런 sum을 구해주는 코드는 배열이니까 이렇게 썼지, 만약에 배열이 아닌 다른 무언가였다면 for문과 다른 접근방법을 쓰지 않았을까?
이렇게 생각하는걸 알고리즘 측면에서 이해하면
자료구조에 따라서 알고리즘은 달라진다
라고 생각해야한다.
01-2
그러면, 알고리즘이 일련의 "문제 해결 방법" 을 뜻한다고 했는데, 백준에서 흔히들 문제를 풀때 무슨 무슨~~ 알고리즘을 활용해서 문제를 풀었다. 이렇게 velog나 naver blog에 본인이 공부한걸 기록하는 사람들이 있다. 그런데 문제를 풀더라도 코드는 시간이 덜 걸리면 좋다~ 메모리를 덜 먹으면 좋다~ 이렇게 "얼마나 잘 풀었는가"에 대해 판단하지 않는가. 이번엔 이런
"알고리즘의 성능분석 방법"
에 대해 알아볼거다.
일단, 알고리즘을 평가하는 요소는 크게 두가지가 있다..
-
시간 복잡도(Time complexity) : 어떠한 상황에서 어떤 알고리즘이 더 빠르고 느리냐.
-
공간 복잡도(Space complexity) : 어떤 알고리즘이 어떤 상황에서 메모리를 더 적게 or 더 많이 쓰냐?
당연히 이상적인 코드는 "시간이 덜 걸리고 메모리를 적게 먹는" 코드가 최적의 알고리즘일거다.
그런데, 일반적인 평가 기준은 "실행속도"가 초점이라고 한다.
그러면 뭐, 속도에 초점을 두고 얼마나 좋은지 평가해봐야지.
그러면 이 평가하는 방법은 이렇다.
연산의 횟수를 센 후에,
처리해야할 데이터 수 n에 대한 연산횟수의 함수 T(n)을 구성한다.
만약 이렇다면, 데이터 수가 많아진다고 해도 연산횟수가 크게 늘지 않아야 좋은 코드 아닐까?
예를 보자.
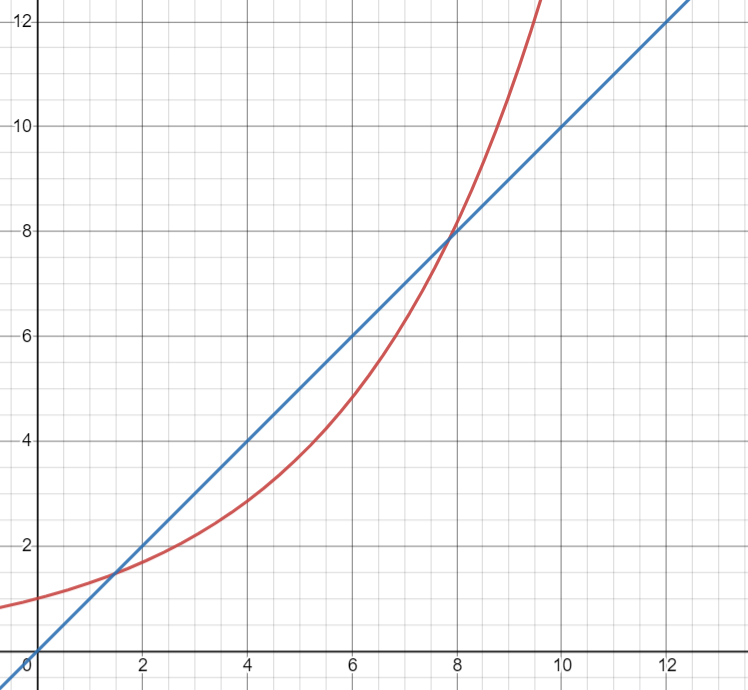
x축이 데이터 수, y축이 연산횟수라고 가정한다.
빨간색 그래프와 파란색 그래프를 보면, 대략 x축이 8일때 쯔음부터 빨간 그래프가 데이터 수 대비 연산 횟수가 계속 많아진다. 그러면 대충 x가 1.7~8에선 빨간색그래프가 더 좋고, 8 이후로는 파란색그래프가 더 좋을까?
뭐, 틀린말은 아닌데, 데이터 수가 적을때 속도 차가 나봤자 얼마나 나겠나. x축 8 이후로 데이터 수가 9천만개까지 있다고 치면 무조건 파란색 그래프의 코드를 쓰는게 좋지 않을까?
그렇다는거다.
여기에서 저자는 순차 탐색 알고리즘 (Linear Search Algorithm)을 설명해준다.
흔히 사용하는 방식인데, 만약 배열에 숫자가 10개가 있다고 가정하면, 원하는 숫자를 찾을 때 맨 앞에서부터 하나 하나 뒤져보는거다.
for (i=0 ; i<len ; i++) {
if (arr[i] == target) {
return i;
}
}이런 식이다. 여기서 객관적인 근거인 " == " 연산이 적게 수행하는 알고리즘이 시간 복잡도가 낮은, 좋은 알고리즘이라고 생각할 수 있다. == 연산 횟수가 많아지면 <연산, ++연산이 자동적으로 같이 늘어나기 때문에 이렇게 판단할 수 있다.
그리고, 알고리즘은 "최악의 경우"가 몇번인지를 따져서, 이 알고리즘이 얼마나 좋은 알고리즘인지 알 수 있다.
물론, 평균적인 경우를 따질 수도 있는데.. 조금 복잡해진다.
최악의 경우인 1번에 시간 복잡도를 계산하는 방법은,
데이터 수가 n개일 때, 최악의 경우에 해당하는 연산횟수는 n이다. 즉, 최악의 경우를 대상으로 정의한 함수 T(n) = n이다.
뭐, 당연한 말이다. int형 배열에 1~10 숫자 10개가 저장되어 있는데, 10을 찾으려면 1부터 10까지 돌려야 하니까 데이터 수 10개, T(10) = 10이다.
그러면, 평균적인 경우를 통해 계산하면..?
이건 좀 시간이 걸리고, 귀찮다.
가정 1 ) 탐색 대상이 배열에 존재하지 않을 확률이 50%
가정 2 ) 배열의 첫 요소 ~ 마지막 요소 전부 탐색 대상이 존재할 확률은 동일.
그리고 마찬가지로 데이터 수가 n개일 때, 탐색대상이 존재하지 않는 경우의 수 는 n, 존재하는 경우의 횟수는 n/2. 거기에 가정 1에 의해 각 경우에 n/2를 곱하여
n x 1/2 + n/2 x 1/2 = 3/4 x n.
T(n) = 3/4 x n.
확실히 최악의 경우를 고려하는 것보다는 많이 귀찮다. 그나마 쉬운 코드를 예로 들어서 이정도 계산으로 끝났지, 어마무시한 코드였으면 어마무시한 계산을 했을 거다.
그래서, 알고리즘 시간 복잡도의 기준으로는 최악의 경우를 기준으로 삼는다고 한다.
그 다음은 이진 탐색 알고리즘 (Binary Search Algorithm)이다.
이진?? 이진법도 아니고, 뭘 원하는 걸까.
일단, 이 이진 탐색 알고리즘을 적용하려면 하나의 전제 조건이 있어야한다.
"배열에 저장된 데이터는 정렬되어 있어야 한다."
정렬된 데이터가 아니면 적용이 불가능 하다. 뭐 오름차순 내림차순 이런 식으로 정렬이 되어야 한다는 거겠지?
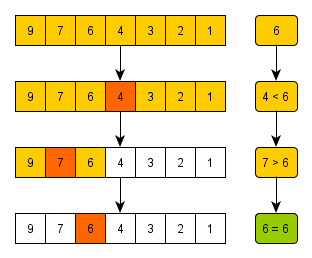
위 그림은 arr[] = {9, 7, 6, 4, 3, 2, 1}일 때 "6" (target) 을 찾는 과정이다.
우선 4를 중간값(mid)로 잡고, target이 mid보다 큰가 작은가를 판별한다. 그러면 target이 mid보다 크니까, 정렬이 내림차순인걸 고려해서 mid값 이하 (mid도 포함)을 싹 다 날려버린다.
그러면 6, 7, 9가 남겠지. 여기서 다시 mid를 정하는데, 그러면 7이다. target이 mid보다 작으니까 mid값 이상을 싹 다 날린다.
그러면 6만 남고, target == mid(현재 숫자 6)가 되니깐 성공!
이게 이진 탐색 알고리즘이다.
만약 1을 찾는다 생각했으면, 순차 탐색 알고리즘은 끝까지 다 가봤을텐데 (7번), 이진 탐색 알고리즘은 3번이면 끝난다! 얼마나 편한가.
그러면, 이 이진 탐색 알고리즘의 시간 복잡도는 어떻게 계산할까?
여기서 앞에서 순차 탐색 알고리즘을 학습할 때 "데이터 수가 n개일 때, 최악의 경우에 해당하는 연산횟수는 n이다." 라는 내용이 있었는데. 그러면 데이터 수가 n개 일때, 최악의 경우 연산횟수는 몇번일까?
.. 바로 답할 수 없다. 저 이진 탐색 알고리즘이 바로 머리에서 슥 삭 소로록 계산이 되는게 아니라면.
그러면 이건 어떻게 계산해야할까..?
그러면 대충 세어보자.
- 처음에 데이터 수가 n개일때 탐색과정 1회
- 데이터 수 n/2, 탐색과정 1회
- 데이터 수 n/4, 탐색 과정 1회
.
.
. - 데이터수가 1개일 때, 탐색 과정 1회
뭐 어떻게 쉽게 답을 할 수가 없다.
그러면 위의 예시를 보고 (6 찾기) 생각해보자.
- 6이 1이 되기 까지 3번 나눈다. 즉 비교연산 3회
- 데이터가 1개 남았을 때, 이 값이 target과 같은지 비교 연산 1회.
이걸 일반화 해보자.
- n이 1이 되기 까지 k번 나눈다. 즉 비교연산 k회
- 데이터가 1개 남았을 때, 이 값이 target과 같은지 비교 연산 1회.
=> T(n) = k + 1.
맞지 않는가.
.. 근데 그러면 k는 어떻게 구하나.
n x (1/2)^k = 1.
n을 1이 되기까지 (1/2)를 k번 나누니까. 위와같은 식이 된다.
그러면
n x 2^(-k) = 1.
n = 2^k.
k = log2n이다. 밑이 2, 지수가 n.
그러면 T(n) = log2n
.. ?
T(n) = k + 1인데요? +1 어디????
여기서 기억해둬야할게 하나 있다. 시간복잡도에 대한 함수 T(n)은
"데이터 수의 증가에 따른 연산횟수의 변화 정도를 판단할 수 있다".
즉, "연산횟수의 변화 정도", 변화 "추이"가 궁금하다는 거지, 구체적인 값을 알고싶다는게 아니다. 그래서 미미한 +1정도는 치워줘도 된다는거다.
이런 이론과 일맥상통하는 게 또 있는데,
빅-오 표기법 (Big-Og Notation)
만약 T(n) = n^2 + 2n + 1이다.
그러면 앞에 k+1에서 +1을 날린걸 생각했을 때, 여기서 뭘 날려야 할지 직감적으로 감이 오나? 아마 나같은 뉴비들은 아닐거다.
이런 나같은 사람들이 어마무시하게 많아서, 시간복잡도에 대해서 빅-오 표기법이 있다.
쉽게 말하면, 대충 T(n)을 간략하게 표현하기 위해 근사치 식을 구성하는거다.
그러면 위의 예시에선 2n + 1을 날려버리고 T(n) = n^2이라 생각하는 거다. 이걸 빅-오 표기법에선
O(n^2) => 이렇게 표기한다.
빅-오 오브 n^2이라고 읽고.
그리고 만약 n^2의 계수가 5여서 5n^2이여도, 5는 날리고 n^2만 살린다.
왜냐고? "변화 추이"만 알면 되지, 정확하게 어떻게 어떻게 변화한다는 몰라도 된다.
만약
"데이터 수가 2, 3, 4로 늘 때 연산횟수는 4, 8, 16이야"
"데이터 수가 2, 3, 4로 늘 때 연산횟수는 300, 600, 1200이야".
연산횟수 차이는 어마무시하지만, 늘어나는 걸 보면 n = (n-1) x 2로 똑같다.
그래서, 그냥 계수를 날려버린다.
이런 대표적인 빅-오는 뭐 여러개 있는데,
- 상수형 O(I)
- 로그형 O(log n)
- 선형 O(n)
- 선형로그형 O(nlog n)
- 제곱형 O(n^2).. 등이 있다.
이러한 빅-오가 이렇게 무식하게 하는 방법만 있느냐? 그건 아니다. 수학적 접근도 가능하다고 한다.
두 개의 함수 f(n)과 g(n)이 주어졌을 때, 모든 n >= k에 대하여
f(n)<=C*g(n)을 만족하는 두 개의 상수 C, K가 존재하면,
f(n)의 빅-오는 O(g(n))이다.
무슨 소린지 모르겠지. 책에 있는 문제를 풀어보자.
T(n) = 3n+2 일 때, O(n)임을 증명하시오
자. f(n) = 3n+2, g(n) = n이라고 가정하겠다.
여기서 K값은 무식하게 크게 잡아도 되는데, n>=k 라는 조건의 존재 이유는 "n이 계속 커지다 어느 순간부터 f(n) <= C*g(n)을 항상 만족시키기만 하면 된다." 라는 이유에서다.
C값은, 아무리 g(n)의 C가 날고 긴다고 해도 연산횟수 증가율의 패턴이 빅-오를 넘지 못해서, 무식하게 잡아도 되는 것이다. 즉, "~의 증가율 패턴을 넘지 못한다"를 증명하기 위해 C가 큰 수식을 만들어 주는 것이다.
이 때, 대충 K는 10이라고 생각하겠다.
그러면 f(10) = 32, g(10) = 10.
즉 32 <= C * 10을 만족시켜야 한다.
엥? 대충 C에 4만 집어 넣어도 맞는 식이 되네?
그러면, 식이 성립하니, O(g(n)) = O(n), 아까 언급한 선형 빅-오가 되는것이다. 대충 알겠찌?
이 수학적 증명에 따라 빅-오를 설명한다면,
"Big - Oh 는 데이터 수의 증가에 따른 연산횟수 증가율의 상한선을 표현한 것"
이 된다.
뭐, 요로코롬. 1장이 끝났다.
