오늘은 우선순위 큐 & Heap을 알아보자.
Ch.09 우선순위 큐와 힙
09-1
우선순위 큐도 그냥 큐처럼 핵심 기능은 두개다.
- Enqueue : queue에 데이터 삽입
- Dequeue : queue에서 데이터 꺼냄
근데 여기서, 그냥 Queue와 우선순위 큐와의 차이는 연산 결과에 있다.
그냥 큐는, 선입선출의 개념이였다. 먼저 들어간 친구가 먼저 나오는 대기줄과 같은 느낌.
그런데, 우선순위 큐는 들어간 순서와 상관 없이, 우선순위가 높은 데이터가 먼저 나온다.
그러니까 만약, Queue에 차례대로 데이터 "5, 3, 4, 1" , 즉 정수형 데이터 네개를 삽입했다고 가정하자. 그런데, 이 큐에서 우선순위를 따지는 기준은 "숫자가 작을수록 우선순위가 높다이다. 그러면, 정렬이 1, 3, 4, 5가 되며, Dequeue를 했을때에도 차례대로 1, 3, 4, 5가 나오게 된다.
이 "우선순위를 따지는 기준"은 사용자가 지정할 수 있다. 뭐 정수를 오름차순 / 내림차순으로 정렬한다던가, 영단어를 여러개 삽입했을때 맨 앞에 있는 글자를 알파벳 순으로 정렬한다던가. 이런.
그러면, 이 우선순위 큐에 대한 기본 개념은 알았으니. 구현하는 방법을 알아보자.
이 우선순위 큐도 앞서 봤던 많은 자료구조들과 마찬가지로 구현하는 방법이 하나가 아니다.
1. 배열 기반 구현
2. 연결 리스트 기반 구현
3. Heap을 이용한 구현
이렇게 세가지로 나뉜다.
물론 1번과 2번이 쉽기는 하지만, 단점이 몇개 있다.
우선, "데이터를 삽입 / 삭제할 때, 데이터를 전부 한 칸씩 밀거나 당겨야 한다." 그러면 데이터가 10개 있을 때, 한개를 삭제한다고 가정하면 뒤에 있는 9개를 다 앞으로 한칸씩 당겨야 하는데, 연산량 소모가 좀 있다..
그리고, "삽입 위치를 찾기 위해 첫 노드부터 마지막 노드까지 전부 우선순위 비교 연산을 해야할 수도 있다." 이것도 큰 문제다. 데이터가 10개일 때 1개를 우선순위를 따져서 정렬 후 추가하려면, 경우에 따라 비교연산을 10번 진행해야할 수도 있다. 10번이라 그라나 다행이지, 데이터가 132000개면.. 132000번.. 아찔하다.
이러한 단점들을 보완하기 위해, "Heap"이라는 자료구조를 이용해서 우선순위 큐를 구현할 수 있다.
Heap.
이진트리이되 "완전 이진 트리"인 구조이며, 모든 Node에 저장된 값은 자식 노드에 저장된 값보다 크거나 같아야 한다.
Heap의 정의이다. 그리고 "자식 노드에 저장된 값"이란, 그냥 단순히 정수 데이터 값 이런게 아니라 "우선순위"가 될 수도 있다. 즉, 자식 노드보다 우선순위가 높은 경우도 위의 정의에 부합하다고 볼 수 있다.
이 Heap에는 두 종류가 있다.
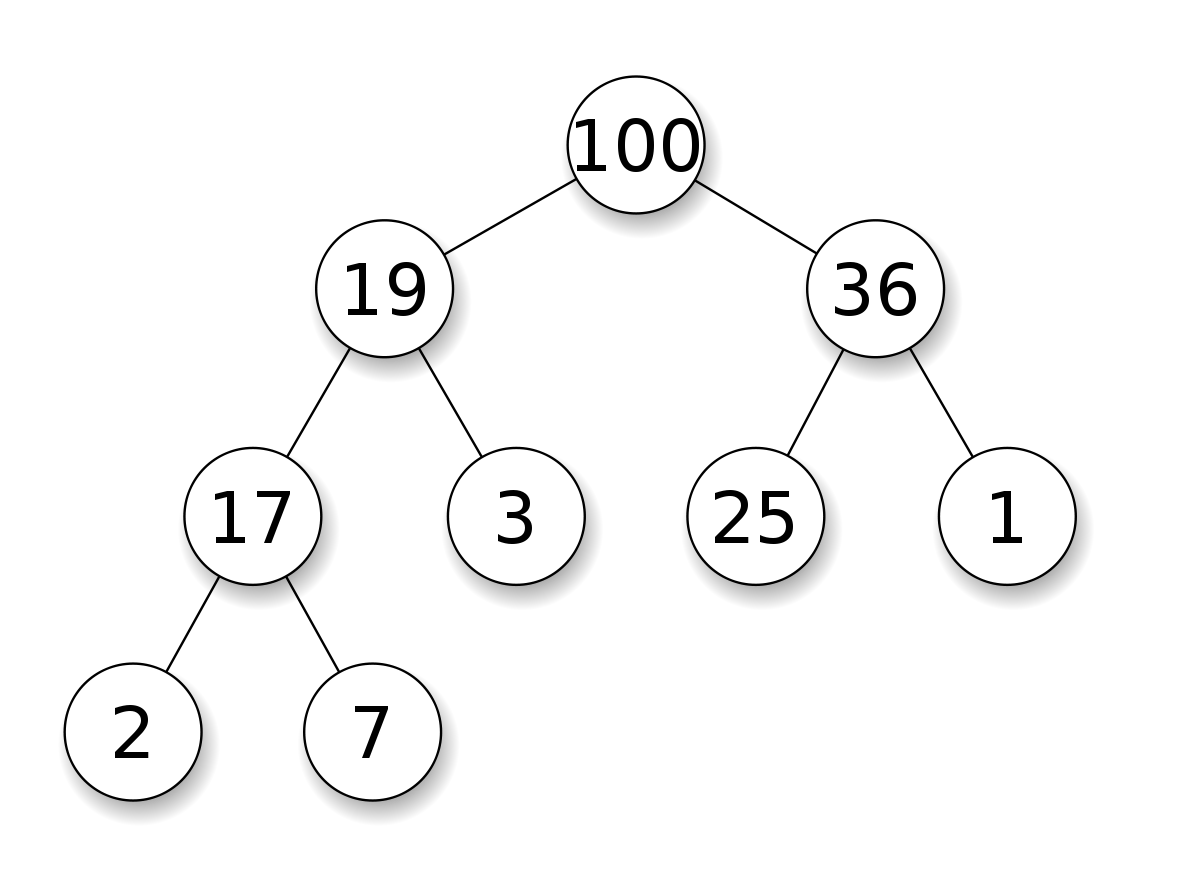
1. 최대 힙(max heap).
위로 올라갈수록 저장된 값이 커지는 구조다.
{kind=link}
이렇게.
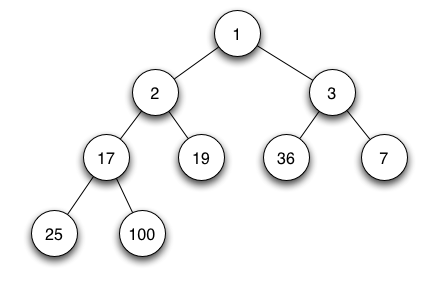
2. 최소 힙(min heap).
1번 반대다.
{kind=link}
그러면, 이런 heap들을 구현하러 가보자.
09-2
오늘의 목적은 우선순위 큐의 이해 + 구현이 main이다.
그 전에, 우선순위 큐를 만들려면 heap이 필요하니까.
heap 부터 한번 구현해보자.
데이터 저장 in heap
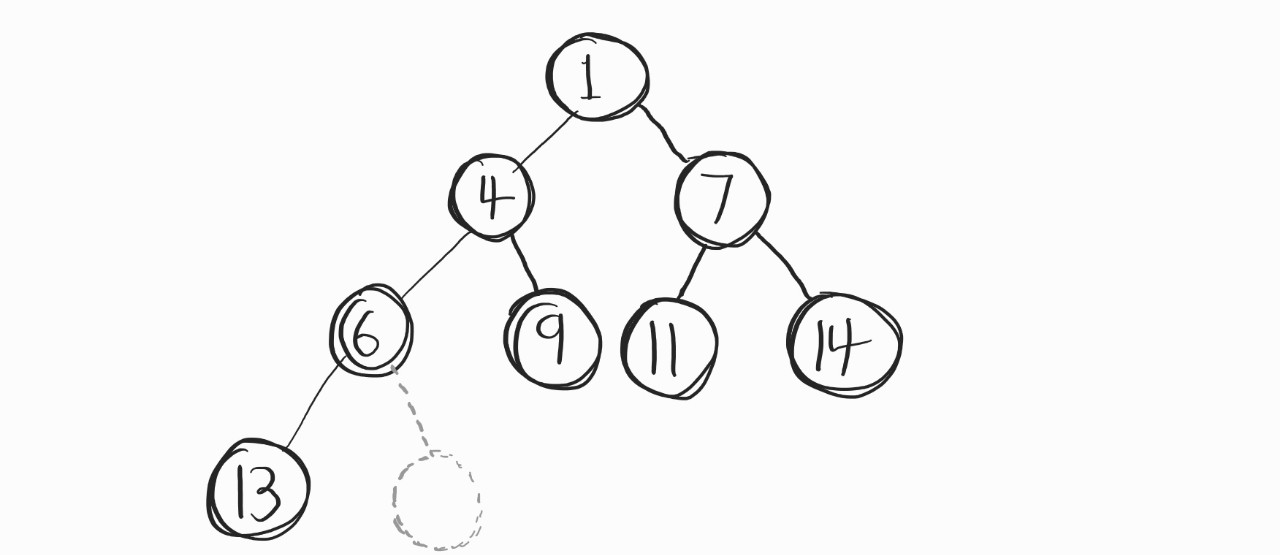
위 그림을 예로 들겠다. 보다시피, 최소 heap이다. 완전 이진트리 구조를 가졌고, 위로 갈수록 data가 작아진다. 회색 점선 부분은 공집합노드라고 생각하면 된다.
위와 같이 생긴 heap이 있을 때, 새로운 데이터인 3을 저장한다고 가정하자.
저장하는 과정이 어떻게 될까?
"우선순위가 제일 낮다는 가정하에," 마지막 위치에 저장. -> 부모 노드와 우선순위 비교 -> IF 위치를 바꿔야하면 바꿔줌 -> 부모노드와 우선순위 비교 후 변경하는 과정 반복.. -> 부모노드보다 우선순위가 낮아지면, 그 자리가 제대로 된 위치다.
이게 전체적인 과정이다. 그러면 그림과 함께 한 순서씩 보겠다.
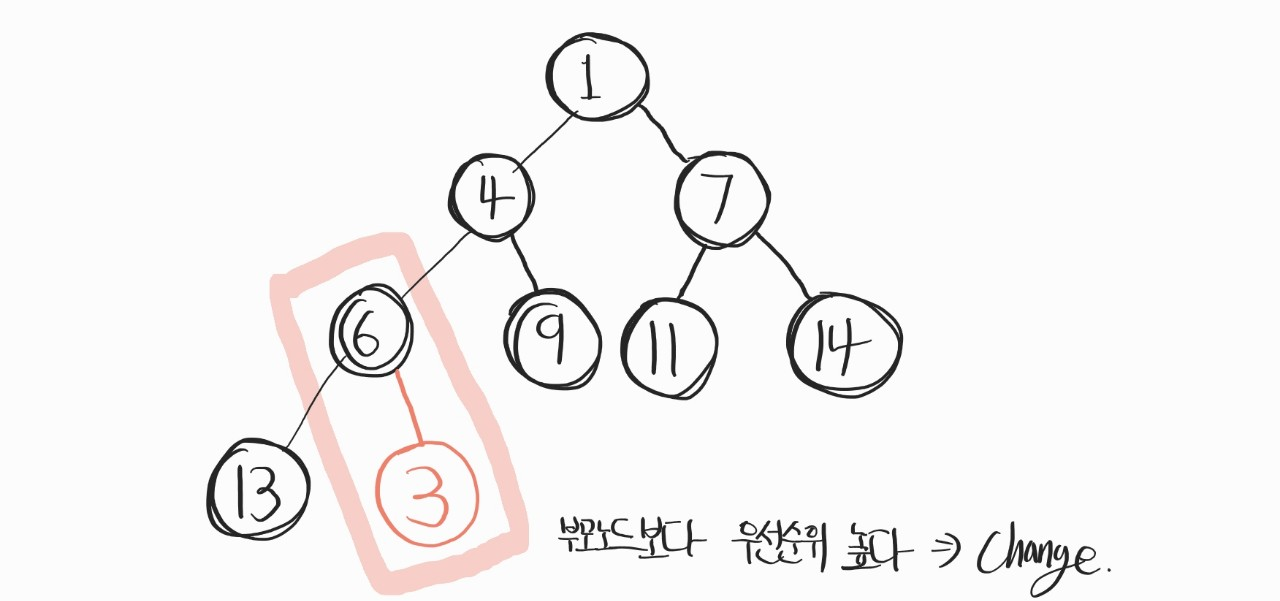
우선, 맨 첫번째 "우선순위가 제일 낮다는 가정하에," 마지막 위치에 저장. 여기서 말하는 마지막 위치란, "가장 밑의 가장 오른쪽"이라고 생각하자.
그리고, 부모 노드와 우선순위를 비교했는데, 최소 heap이니까 3이 6보다 우선순위가 높다. 그러니, 위치를 바꿔주자.
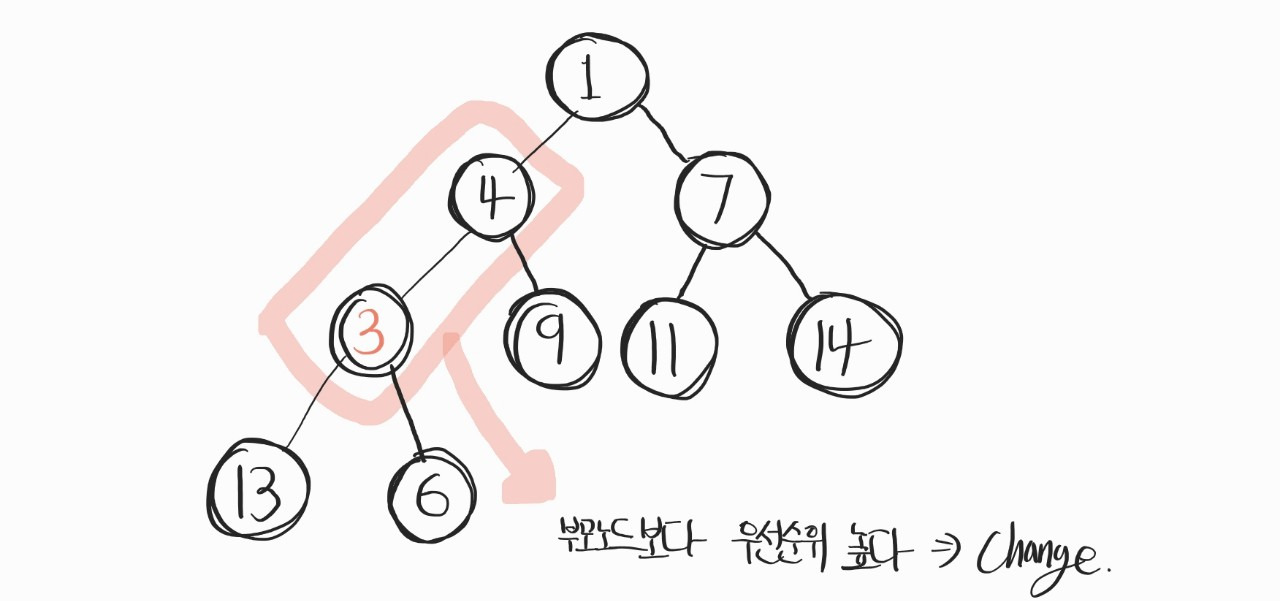
또 바뀌니까, 또 바꿔주자.
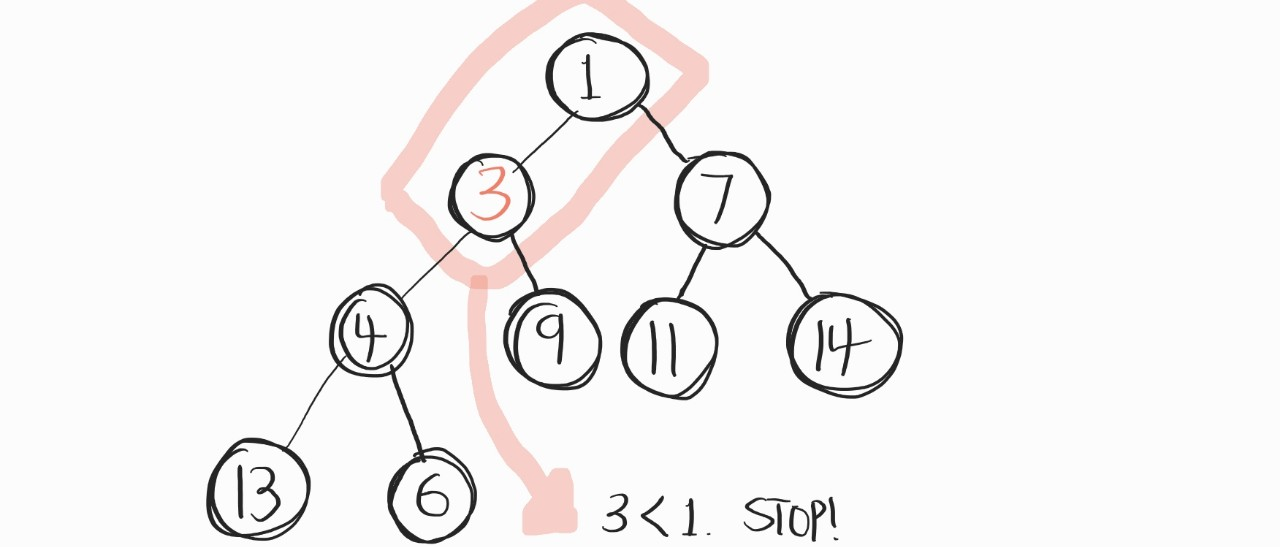
어? 이제 3이 부모노드인 1보다 우선순위가 낮다.
3이 제자리를 찾았다! 그러니, 이제 비교연산 stop. 이게 데이터를 추가하는 과정이다.
데이터 삭제 in heap
얘는 위에 데이터 추가 삽입의 결과를 가져다 쓰겠다. 지울 데이터는 "1"이다. 왜? heap은 우선순위가 가장 높은 데이터를 빼니까. 고로 루트노드가 빠진다.
"마지막 노드"를 루트 노드로 옮김 -> 자식 노드와 비교 -> IF 자식노드가 우선순위가 더 높다면, 위치 바꿔줌 -> 자식 노드와 비교후 자리 바꿔주는 과정 반복 -> 자식노드보다 우선순위가 높아지면, 그게 제자리다.
엥? "마지막 노드를 루트노드로 옮긴다?" 왜 그럴까.
또 그림으로 이해해보자.
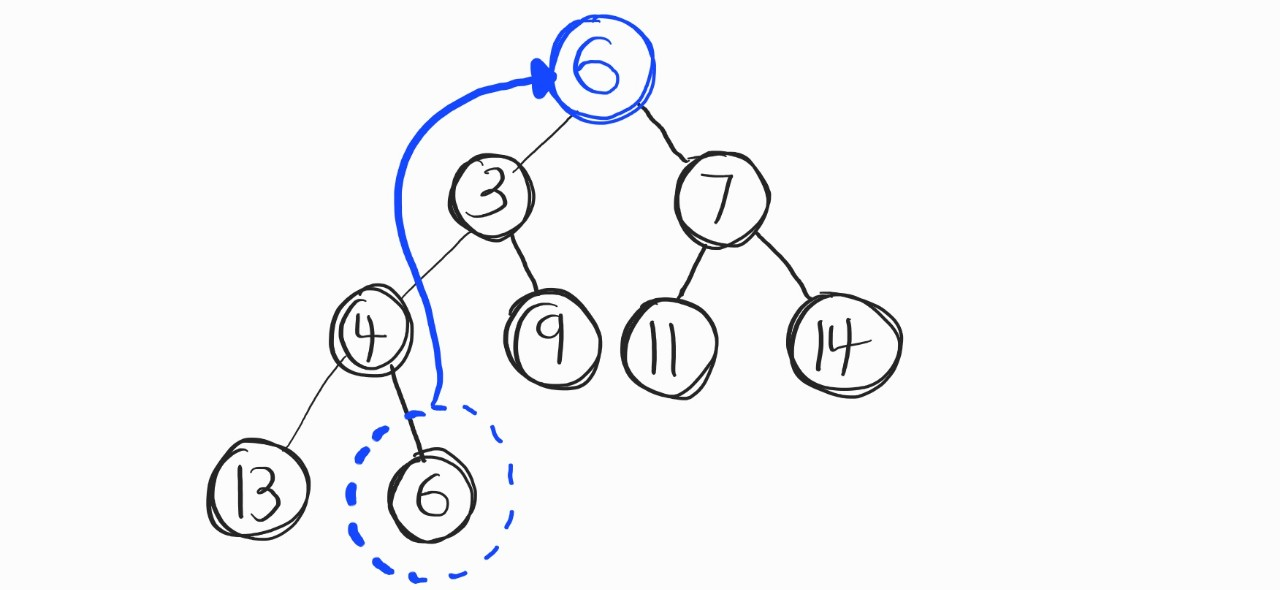
우선, 마지막 노드를 루트 노드로 옮겼다. 이후, 자식 노드와 비교연산을 진행한다.
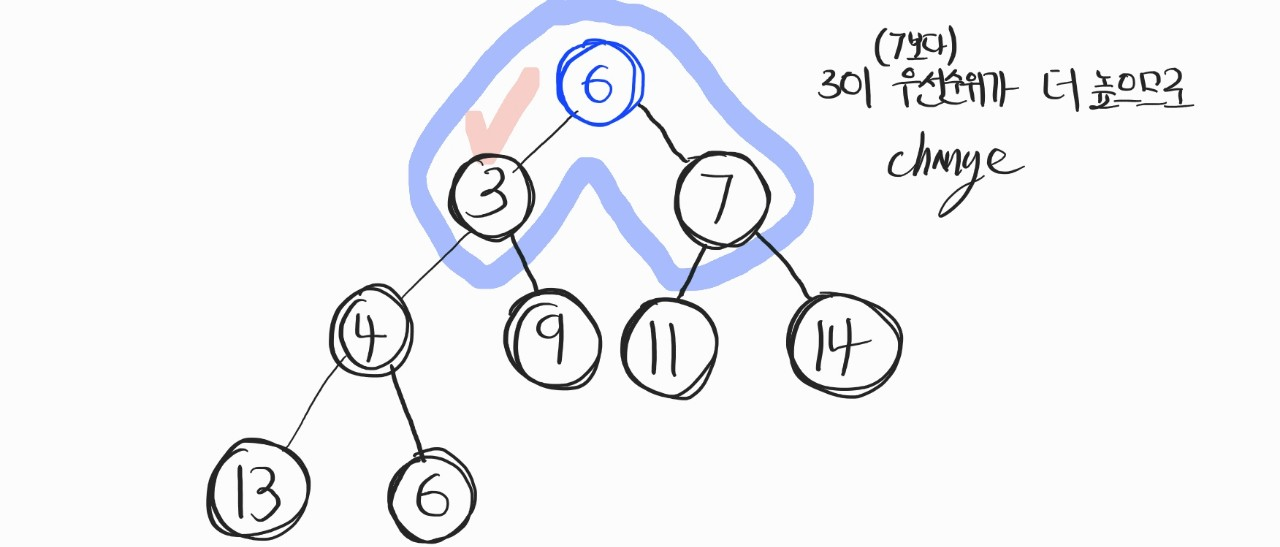
왼쪽 자식 노드와 부모 노드 / 오른쪽 자식 노드와 부모 노드 비교를 진행해서, 더 우선순위가 높은 자식노드와 부모노드를 서로 바꿔준다. 여기선 애초에 7보다 6이 우선순위가 높기에, 3이 WIN! 고로 3과 6을 바꿔준다.
(그리고 위 그림에 실수가 있는데, 마지막 노드에 있는 6은 지워야 한다. root 노드로 옮겨갔으니까.)
즉, 3이 root 노드가 된다.
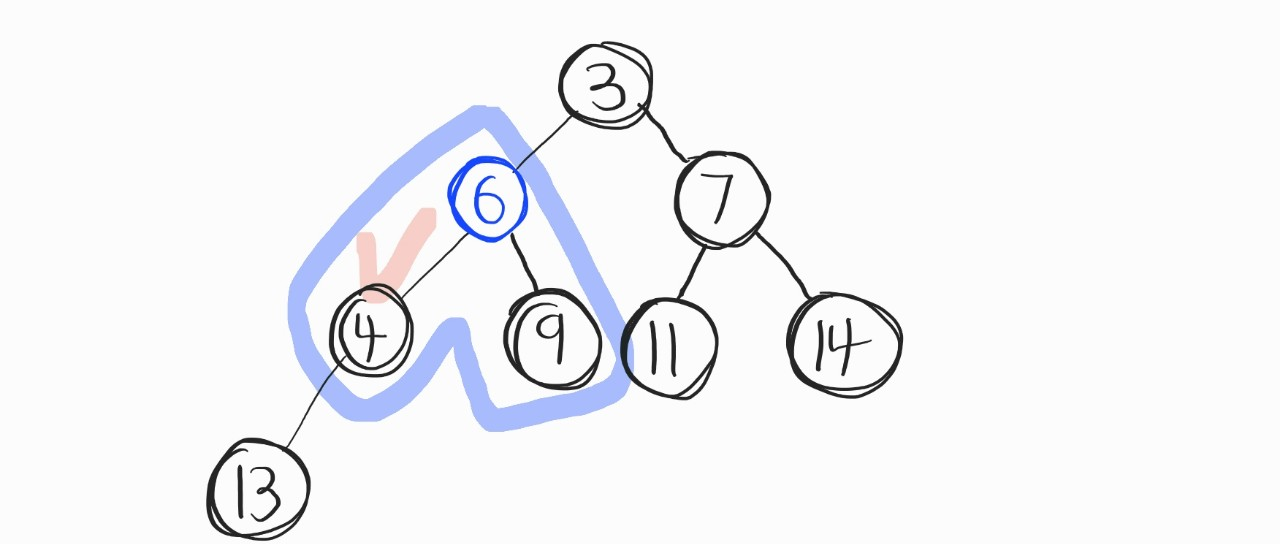
그리고, 다시 위와 같은 비교연산 반복. 4와 서로 위치를 바꿔준다.
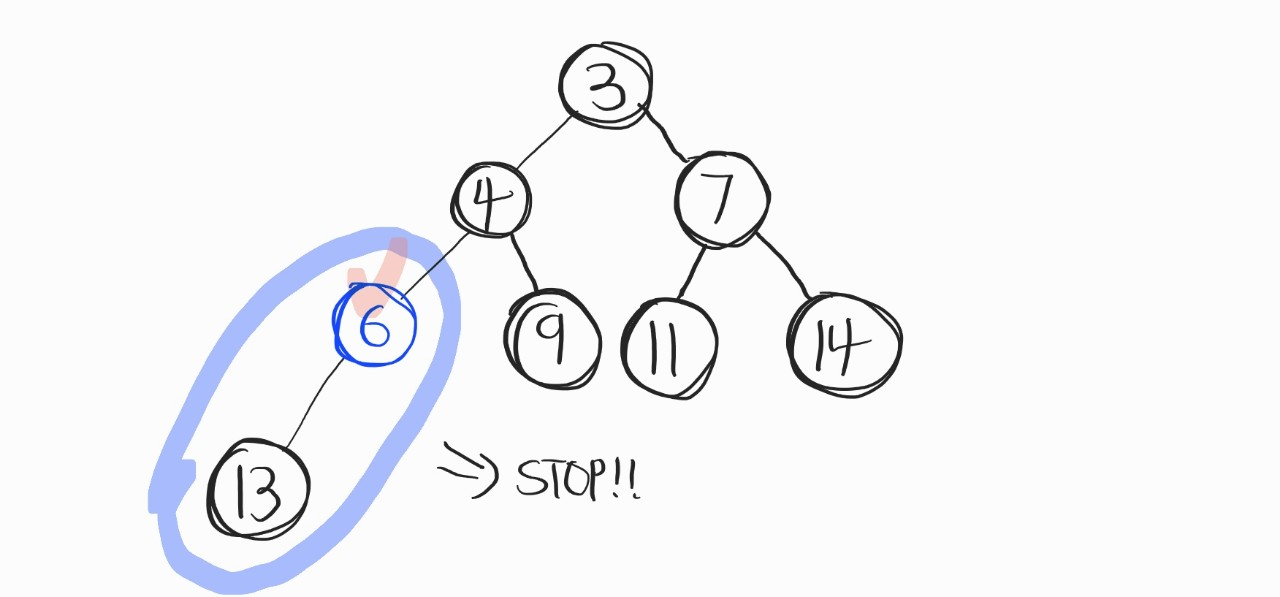
다시 비교연산을 반복.. 했으나, 이제 6이 자식노드보다 우선순위가 높다! 그럼 이제 비교연산 종료. 위 그림이 데이터를 삭제한 후 최종 결과다.
이제 Heap의 핵심 연산에 대해, 이론적 설명이 끝났다.
그런데 이 Heap 기반 우선순위 큐가 단순 배열 / 연결 리스트 기반보다 더 사용하기에 효율적이고 적합하단건, 어떻게 알 수 있을까?
Ch.1인가 2에서 학습했던 Big-Oh 연산법을 다시 보자.
시간 복잡도에 대해서 다뤄본다는 말이다!
배열 기반 데이터 저장 및 삭제의 시간 복잡도는 O(n)이다. 배열에 저장된 모든 데이터와 우선 순위 비교 과정을 가지게 되기 때문이다. 그리고 연결 리스트 기반도 애초에 똑같으므로, 얘도 시간 복잡도는 O(n)이다.
그런데, Heap을 보면, "트리 높이가 하나 늘어날 때마다 비교 연산 횟수가 1회 증가한다." 위의 데이터 저장 과정과 삭제 과정을 보면, 아마 무슨 말인지 알 수 있을 것이다.
그리고, 트리 높이가 하나 늘어날 때마다 데이터의 갯수는 2배씩 늘어난다. "이진 트리"이므로. 0층에선 1개 (root node), 1층에선 2개, 2층에선 4개.. 이렇게 늘어날 것이다.
그러면 트리 높이가 하나 늘어날 때마다 비교 연산 횟수 1회 증가 = 데이터가 2배 늘어날 때마다 비교 연산 횟수 1회 증가. 같은 말이 된다.
그러면, 시간복잡도는?
O(log2n)일 것이다.
고로, O(n) vs. O(log2n). 누가 우승일까?
그래프만 대충 떠올려 봐도, 후자가 우승이다. 그래서, "Heap 기반 우선순위 큐가 배열 / 연결 리스트 기반 우선순위 큐보다 더 뛰어난 효율성을 가진다"고 생각해도 된다.
이제 왜 Heap을 기반으로 우선순위 큐를 쓰는지도 알았다.
그런데, Heap을 구현해야, 우선순위 큐를 쓸 수 있지 않을까..? Heap도 트리니까, 이를 구현하는 방법도 알아야지..
Heap은 "새 노드를 힙의 마지막 위치에 추가하는 과정" 때문에, 배열 기반으로 구현하면 된다.
다시 배열 기반 이진 트리를 대충 떠올려 보면, idx가 0인 위치의 요소는 사용하지 않고, 1인 위치부터 루트노드를 하나씩 속 속 집어 넣었었다.
그리고, Heap을 짜려면 양쪽 자식 노드의 인덱스 값도 얻을 줄 알아야 할 것이다.
? 양쪽 자식 노드 인덱스 값은 또 어케 구하는데요
어렵지 않다.
- 왼쪽 자식 노드 : 부모 노드 인덱스 값 x2
- 우측 자식 노드 : 부모 노드 인덱스 값 x2 +1
- 부모 노드 : 자식 노드 인덱스 값 /2 (정수형 나누기다! 나머지 소수점은 날림)
예를 들어 볼까?
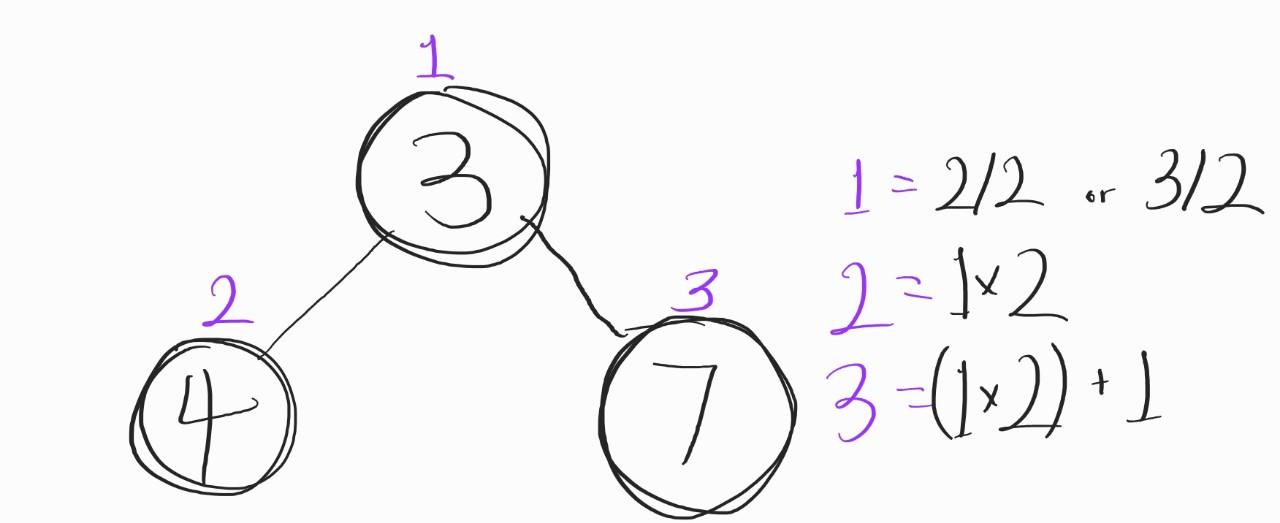
그렇다.
그러면 이제, Heap부터 한번 구현해보자. 우선, 헤더파일.
/* SimpleHeap.h */
#ifndef __SIMPLE_HEAP_H__
#define __SIMPLE_HEAP_H__
#define TRUE 1
#define FALSE 0
#define HEAP_LEN 100
typedef char HData; // 각 노드에 'A','B'같은 알파벳을 데이터로 넣겠따
typedef int Priority;
typedef struct _heapElem { // 힙에 저장될 데이터의 모델
Priority pr; // 우선순위
HData data; // 저장될 데이터
} HeapElem;
typedef struct _heap { // heap 구조체
int numOfData; // heap에 저장된 데이터 개수
HeapElem heapArr[HEAP_LEN]; // heap에 저장된 각 데이터들
} Heap;
void HeapInit (Heap *ph);
int HIsEmpty(Heap *ph);
void HInsert(Heap *ph, HData data, Priority pr);
HData HDelete(Heap *ph);
#endif그렇다.
어? 근데 우선순위를 굳이 내가 집어넣어야하나? 그럼 너무 귀찮은거 아닌가요? 컴퓨터가 알아서 해주는줄..
일단 Heap 자체를 구현하고 이해하기 위해 코드를 이렇게 짰는데, 이제 코드에서 우선순위를 알아서 매겨주는 구조는 저자가 이 코드를 다 짜본 후에 알려주겠다고 했다. 기다리자.
그럼, 위의 헤더파일을 소스파일로 짜보자. 설명은 주석에 달려있다.
/* SimpleHeap.c */
#include "SimpleHeap.h"
void HeapInit (Heap *ph) {
ph->numOfData = 0;
}
int HIsEmpty(Heap *ph) {
if (ph->numOfData == 0) {
return TRUE;
} else return FALSE;
}
int GetParentIDX (int idx) { // 부모 노드 idx 반환
return idx / 2;
}
int GetLChildIDX (int idx) { // 좌측 자식노드 idx 반환
return idx*2;
}
int GetRChildIDX (int idx) { // 우측 자식노드 idx 반환
return GetLChildIDX(idx)+1;
}
int GetHIChildIDX (Heap *ph, int idx) { // 우선순위가 높은 자식노드의 idx 반환
if (GetLChildIDX(idx) > ph->numOfData) { // 자식 노드가 없다면
return 0;
} else if (GetLChildIDX(idx) == ph->numOfData) { // 자식 노드 하나가 마지막 노드라면
return GetLChildIDX(idx);
} else { // 자식 노드 두개가 온전히 있으면
if (ph->heapArr[GetLChildIDX(idx)] > ph->heapArr[GetRChildIDX(idx)]) {
// R이 L보다 우선순위 높다면
return GetRChildIDX(idx);
} else { // L이 R보다 우선순위 높다면
return GetLChildIDX(idx);
}
}
}
void HInsert(Heap *ph, HData data, Priority pr) { // 데이터 삽입
int idx = ph->numOfData+1; // 마지막 노드 idx 저장
HeapElem nelem = {pr, data}; // 추가된 노드의 pr, data
while(idx != 1) {
if(pr < ph->heapArr[GetParentIDX(idx)].pr) {
// 부모 노드보다 추가된 노드가 우선순위가 높다면
ph->heapArr[idx] = ph->heapArr[GetParentIDX(idx)];
idx = GetParentIDX(idx) // 추가된 노드가 한계단 올라감
} else { // 추가된 노드보다 부모 노드가 우선순위가 높다면
break; // 여기가 내자리야
}
}
ph->heapArr[idx] = nelem; // 추가된 노드의 데이터를 확정된 자리에 저장
ph->numOfData += 1; // 데이터 하나 늘어남
}
HData HDelete(Heap *ph) {
HData rdata = (ph->heapArr[1]).data; // 지울 데이터인 root node
HeapElem lastElem = ph->heapArr[ph->numOfData];
// Delete의 핵심인 마지막 노드. 써먹을꺼니까.
// parentIdx에는 마지막 노드가 저장될 idx값이 담긴다.
int parentIdx = 1; // 부모 노드 idx값
int childIdx;
while(childIdx = GetHIChildIDX(ph, parentIdx)) {
// 루트 노드 기준, 우선순위가 높은 자식 노드를 시작으로 반복문 start
if (lastElem.pr < ph->heapArr[childIdx].pr) {
break;
} // 만약 마지막 노드보다 자식 노드가 우선순위가 낮다면 break
//자식 노드가 마지막 노드보다 우선순위가 높다면
//비교대상 노드의 위치를 한 계단 내리고
ph->heapArr[parentIdx] = ph->heapArr[childIdx];
parentIdx = childIdx;
// 마지막 노드가 저장될 위치 정보를 한 계단 올린다.
}
ph->heapArr[parentIdx] = lastElem;
// 마지막 노드의 정보를 최종 확정된 자리로 옮긴다
ph->numOfData -= 1;
return rdata;
}코드가 길다..
여기서, HDelete 함수에서 조금 의아할수도있다.
? 위에서 설명한 그림대로면 마지막 노드가 루트노드로 옮겨가서, 하나씩 점점 내려가는 과정 아닌가요? 왜 한 곳에 머물러 있다가 자리가 확정 나면 그때만 옮겨가는거죠?
질문에 답이 있다.
굳이 한번에 옮겨갈 수 있는데, 괜히 root node로 신나서 먼저 갔다가 한자리씩 한자리씩 귀찮게 내려갈 필요가 있는가?
그렇다. 이걸 실행할 수 있는 main함수는, 뭐 대충 넘기겠다. 자세한건 GitHub를 참고하자.
여기까지.
