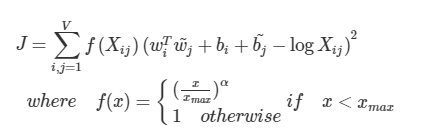📙 Bag of word
📘 정의
Bag of Word란 단어들의 순서를 고려하지 않고 단어들의 출현 빈도에만 집중하는 텍스트 데이터의 수치화 표현 방법.
분석이나 활용시 단어 사전을 만들어 놓은 후 문서를 벡터로 바꿔준다.
📗 문서-단어 행렬(Document-Term matrix)
어떤 문서에서 등장하는 단어들의 빈ㄷ를 나타낸 행렬.
BoW(Bag of words)를 활용하기 위한 행렬 형식
ex)
- 단어사전 : [“가지”, “감자”, “고구마”, “당근”, “무”, “미역”, “양파”, “피망”]
- 문서 : "감자 감자 감자 감자 감자 당근 미역 미역 미역 피망 피망"
-문서-단어 : {"가지":0, "감자":5, "고구마":0, "당근":1, "무":0, "미역":3, "양파":0, "피망":2}
한계
1. 저장공간의 낭비
희소 벡터 또는 희소 행렬로 표현되기 때문에 많은 양의 저장 공간과 높은 계산 복잡도 요구.
-> 전처리를 통한 단어의 정규화와 단어 집합의 크기 감소 필요
2. 단순 빈도 수 기반 접근
불용어 같은 경우 모든 문서에서 동일하게 빈도수가 높다. 즉 유사한 문서라고 판단할 수 있다는 것이다.
-> 각 단어에 가중치를 주어서 해결 할 수 있다(TF-IDF)
📘 과정
- 각 단어에 고유한 정수 인덱스 부여 #단어 집합(사전) 생성
- 입력된 문서에 대하여 단어 집합을 만들어 각 단어에 정수 인덱스 할당
- 각 인덱스에 위치한 단어 토큰의 등장 횟수 기록(문서-단어 행렬 생성)
- 각 단어에 대한 one-hot vector 생성
- 각각의 one-hot vector를 더하여 BoW를 생성
📙Word Embedding
📘정의
자연어 처리의 필수적 개념으로, Word를 R차원의 vector로 매핑시켜주는 것을 말한다.
각 단어를 인공 신경망 학습을 통해 벡터화 하는 것.
📘Word2Vec
📗정의
- 단어를 벡터로 표현하여 유사도 계산에 유리하다.
ex) 'Cat'과 'Kitty'는 유사한 표현이다. 따라서 비슷한 벡터를 가진다 -> Short distance- 저차원 벡터를 통해 다차원 공간에 벡터화해서 유사성을 표현할 수 있다.
- 2개의 히든 레이어를 가지고 있는 뉴럴 테느워크 모델이다.
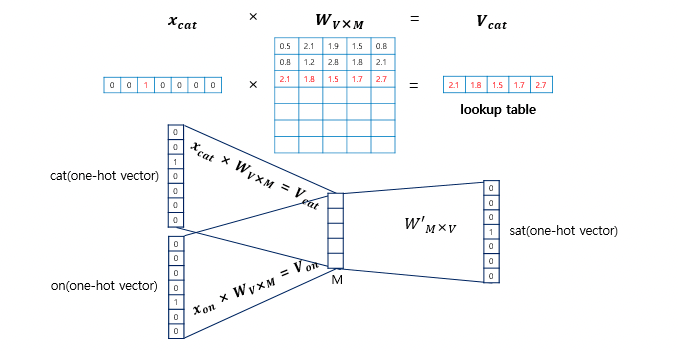
📗학습방법(Cotinuous Bag of Word)
주변에 있는 단어들의 입력으로 중간에 있는 단어들을 예측하는 방법
-
용어정리
- Window : 앞 뒤로 몇개의 단어를 볼 것인가.
- Center word : 예측해야 하는 중심단어
- Context word : 주변 단어
- Sliding Window : 데이터 셋을 만드는 방법
-
방법
- 윈도우 크기가 정해지면 윈도우를 옆으로 움직이며 슬리아딩 윈도우 방법을 통해 학습하며 데이터 셋을 만든다
- 입력충의 입력으로 윈도우 크기의 주변 단어들의 원-핫 벡터가 들어가고 출력층에서 중간단어의 원-핫 벡터가 필요하다
- 투사층 벡터를 통과아여 출력층 벡터가 나온다
📘GloVe
📗정의
카운트 기반과 예측 기반을 모두 사용하는 방법론.
카운트 기반의 LSA와 예측 기반의 Word2Ve의 단점을 보완한다는 목적으로 나왔다.
하지만 단정적으로 Word2Ve와 GolVe중 어떤 것이 더 뛰어나다고 말할 수 없다.임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시 등장 확률이 되도록 만드는 것
📗용어 정리
-
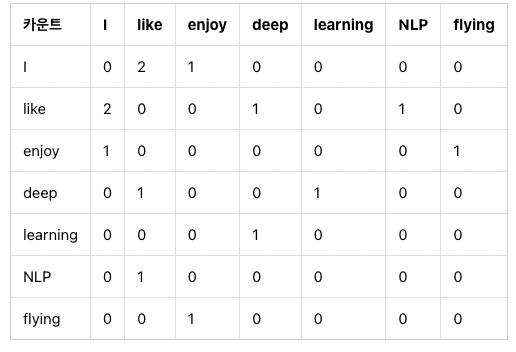
윈도우 기반 동시 등장 행렬
전체 단어 집합의 단어들로 구성되고 i단어의 윈도우 크기 내에서 k단어가 등장한 횟수를 기재한 행렬.
ex)
윈도우 크기 = 1, k,n = 7
입력 문장 :
I like deep learning
I like NLP
I enjoy flying
-
동시 등장 확률
동시 등장 확률은 동시 등장 행렬로부터 특정 단어 i의 전체 등장 횟수를 카운트하고, 특정 단어 i가 등장했을 때 어떤 단어 k가 등장한 횟수를 카운트하여 계산한 조건부 확률입니다.
-
손실 함수(Loss function)
예측값과 실제값의 차이를 구하는 기준을 의미한다.
성능을 증면하는 지표중 하나이다. 즉 손실함수의 값을 최소화하는 방향으로 학습을 진행한다.
ex) MSE, RMSE, MAE, Binart Crossentropy, Categorical Crossentropy

- Glove의 손실함수