이화여대 캡스톤 디자인 <포인트 체커 - 객체 인식과 OCR를 활용한 객관·단답식 시험 채점 AI 소프트웨어> 기술 블로그
Capstone Design Project

들어가며
이화여자대학교 캡스톤 디자인 프로젝트로 진행 중인 <포인트 체커 - 객체 인식과 OCR를 활용한 객관·단답식 시험 채점 AI 소프트웨어>를 만들기 위해 문항 인식, 잘린 문항 매칭, 객관식 선지 추출, 단답식 답안 추출 기능을 구현했으며, GPU 사용을 위해 AWS EC2, Flask, GitHub를 활용한 백엔드 서버 환경을 구축하고, 프론트엔드의 파일을 배포 파일로 변환했다.
당초엔 서술형 채점까지 구현하려고 했으나, 서술형 답안의 범위가 넓고 구할 수 있는 자료의 한계가 있어 서술형 채점은 구현에서 제외했다. 또한 사용한 자료의 다수가 '수능 시험지'였기 때문에 단답식 인식은 숫자 위주로만 가능하다는 점을 미리 알려 둔다.
ㅤ
ㅤ
ㅤ
사용한 AI 유형 소개
Object Detection
객체 인식은 컴퓨터 비전의 하위 분야로, 딥러닝을 사용해 객체를 탐지하고 인식하는 기술을 말한다. 해당 프로젝트에서 객체 인식은 Yolov8을 사용해 진행했다.
Yolov8은 ultralytics에서 제공하는 오픈 소스 라이브러리다, Yolov8을 사용해 문항 인식, 잘린 문항 매칭, 객관식 문항의 선지 인식을 구현했다.
Yolov8 라이브러리: https://github.com/ultralytics/ultralytics
Yolov8 사용법
라이브러리 설치
pip install ultralyticsultralytics에서 배포하는 파이썬 라이브러리를 다운 받는다.
모델 불러오기 및 추론
from ultralytics import YOLO
model = YOLO(model_path)
results = model(source=images, save=False, save_crop=False)
names = model.namesmodel_path는 .pt 형태로 가중치가 저장된 경로를 입력한다.
ex.) model_path = path + "/model/weights/best.pt"
source에 이미지, 혹은 이미지가 저장된 폴더 경로를 입력한다.
save와 save_crop으로 결과 저장 여부를 정할 수 있다.
names에는 모델의 라벨 이름이 리스트 형태로 저장되어 있다.
ex.) {0: 'num', 1: 'check1', 2: 'check2', 3: 'check3', 4: 'check4', 5: 'check5'}
추론 결과 사용
for result in results:
boxes = result.boxes.xyxy.tolist()
clss = result.boxes.cls.cpu().tolist()
if boxes is not None:
for box, cls in zip(boxes, clss):
if (names[int(cls)=="num"):
passboxes에는 이미지 한 장에서 탐지된 객체의 (복수의) 영역들이 들어 있다.
clss에는 이미지 한 장에서 탐지된 객체의 (복수의) 라벨 클래스들이 들어 있다.
box와 cls 페어를 묶어서 루프 문을 구성하고, names[int(cls)]로 라벨 이름을 색출해 원하는 작업을 할 수 있다.
ㅤ
ㅤ
OCR
OCR은 텍스트 이미지에서 텍스트를 추출해 기계가 읽을 수 있는 텍스트 포맷으로 변환하는 기술을 말한다.
해당 프로젝트에서 OCR은 EasyOCR과 OCR Tamil을 사용해 진행했다.
EasyOCR은 JaidedAI에서 제공하는 오픈 소스 라이브러리로 문항 번호 인식에 사용했다.
OCR Tamil은 gnana70에서 제공하는 오픈 소스 라이브러리로 단답식 답안 인식에 사용했다.
EasyOCR 라이브러리: https://github.com/JaidedAI/EasyOCR
OCR Tamil 라이브러리: https://github.com/gnana70/tamil_ocr
EasyOCR 사용법
라이브러리 설치
pip install easyocrJaidedAI에서 배포하는 파이썬 라이브러리를 다운 받는다.
모델 불러오기 및 추론
import easyocr
reader = easyocr.Reader(['ko', 'en'])
ocr_text = reader.readtext(img, detail=0)reader에는 OCR 리더기의 정보를 저장한다. 리스트에 읽을 언어를 약어로 지정할 수 있다.
ocr_text에는 readtext 함수를 통해 입력 이미지의 글자를 추출할 수 있다. detail을 0으로 지정해서 세부 정보 없이 추출한 텍스트만 리스트 형태로 뽑아낼 수 있다.
추론 결과 사용
text = ocr_text[0]ocr 결과는 항상 리스트로 반환되기 때문에, 띄어쓰기 없는 단어만 추출했다고 해도 인덱싱으로 추출을 해야 한다.
ㅤ
OCR Tamil 사용법
라이브러리 설치
OCR Tamil은 파이썬 라이브러리로 배포되어 있지 않기 때문에, git clone이나 git submodule 형태로 다운 받아야 사용이 가능하다.
git clone
git clone https://github.com/gnana70/tamil_ocr.gitgit clone은 서버 환경 구축할 때 사용한다. GitHub clone을 마치고, 사용하고자 하는 경로에서 git clone 코드를 실행한다. GitHub clone에 대한 내용은 아래에 있으니 참고하길 바란다.
git submodule add
git submodule add https://github.com/gnana70/tamil_ocr.git Backend/models/tamil_ocrgit submodule add는 OCR Tamil을 프로젝트 배포 GitHub에 포함할 수 있게 한다.
git submodule 사용 시 GitHub 프로젝트 루트 경로에 .gitmodules가 생성된다.
ex.) .gitmodules
[submodule "Backend/models/tamil-ocr"]
path = Backend/models/tamil-ocr
url = https://github.com/gnana70/tamil_ocr.git
submodule로 포함시켰는데, tamil_ocr @ 5f1662a 폴더를 누르면 원래의 리포지토리의 tree branch로 이동한다.
모델 불러오기 및 추론
import os
import sys
sys.path.append(os.path.dirname(os.getcwd() + "/models/tamil_ocr/ocr_tamil"))
from ocr_tamil.ocr import OCR
ocr_text = OCR().predict(img)OCR Tamil을 import 하는 과정은 조금 복잡하다. 디렉토리 구조가 조금 복잡하기 때문에 os와 sys 라이브러리를 사용해서 sys.path.append()를 수행하는 것을 강력하게 추천한다. sys.path.append()로 sys.path에 끼울 경로는 tamil_ocr 밑의 ocr_tamil이라는 폴더의 경로다. ocr_tamil을 루트로 import 할 수 있어야 오류가 나지 않는다.
tamil ocr은 영어와 타밀어만을 인식한다. 따라서 별도의 리더기 언어 지정이 필요하지 않다.
ocr_text에는 predict 함수를 통해 입력 이미지의 글자를 추출할 수 있다. tamil ocr의 리더기는 별도의 세부 정보 없이 추출한 텍스트만 리스트 형태로 반환한다.
추론 결과 사용
text = ""
for txt in ocr_text:
for t in txt:
if (t.isdigit()):
text += t
elif (t == 'l' or t == 'i' or t == 'I' or t == '|' or t == '/'):
text += '1'
elif (t == 'q'):
text += '9'ocr_text는 리스트이기 때문에 순회해야 하는데, txt를 또 순회하는 이유는 숫자를 타밀어로 인식했을 가능성이 있기 때문이다. 이때 인식한 글자가 l이거나 i거나 I거나 |라면 1로 인식하도록 세부 조정을 했고, 인식한 글자가 q라면 9로 인식하도록 세부 조정을 했다. 이는 단답식 답안이 숫자만으로 구성되어 있다는 전제가 있을 때 필요한 세부 조정이다.
ㅤ
ㅤ
ㅤ
AI 모델 훈련
라벨링은 labelimg로 진행하였으며, 라벨링한 작업물들은 전부 Yolov8 성능 개선에 사용했다. OCR은 이미 있는 오픈 소스 라이브러리로 충분하다는 판단 하, 별도의 성능 개선 작업을 진행하지 않았다.
labelimg 소개 링크: https://pypi.org/project/labelImg/#labelimg
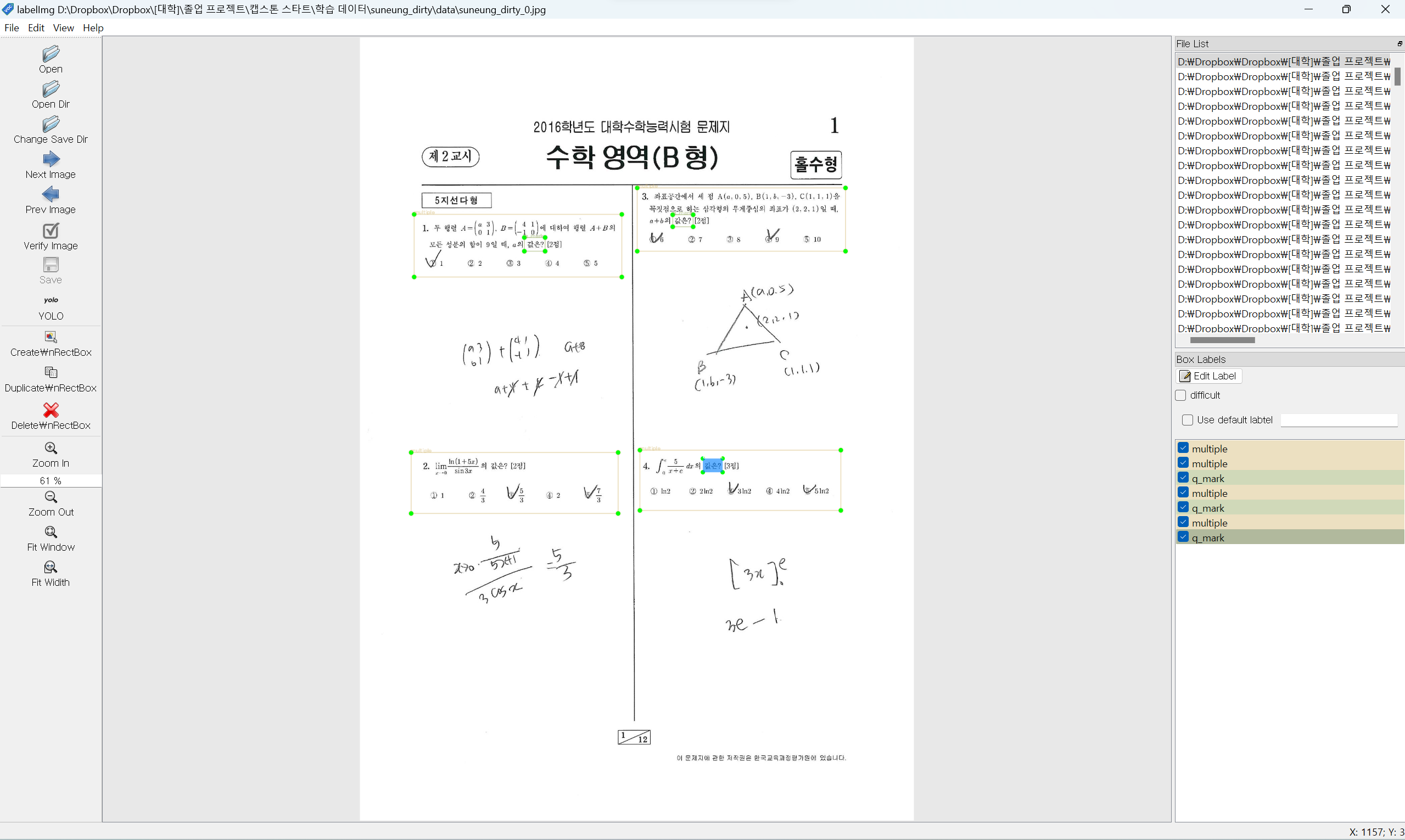
문항 인식
입력 이미지


라벨링
라벨 목록
multiple: 객관식 문항 영역
multiple_cropped: 잘린 객관식 문항 영역
subjective: 단답식 문항 영역
subjective_cropped: 잘린 단답식 문항 영역
q_mark: 물음표로 끝나는 어절 (객관식 표지)
q_period: 마침표로 끝나는 어절 (객관식 표지)
s_period: 마침표로 끝나는 어절 (단답식 표지)
라벨링 사진

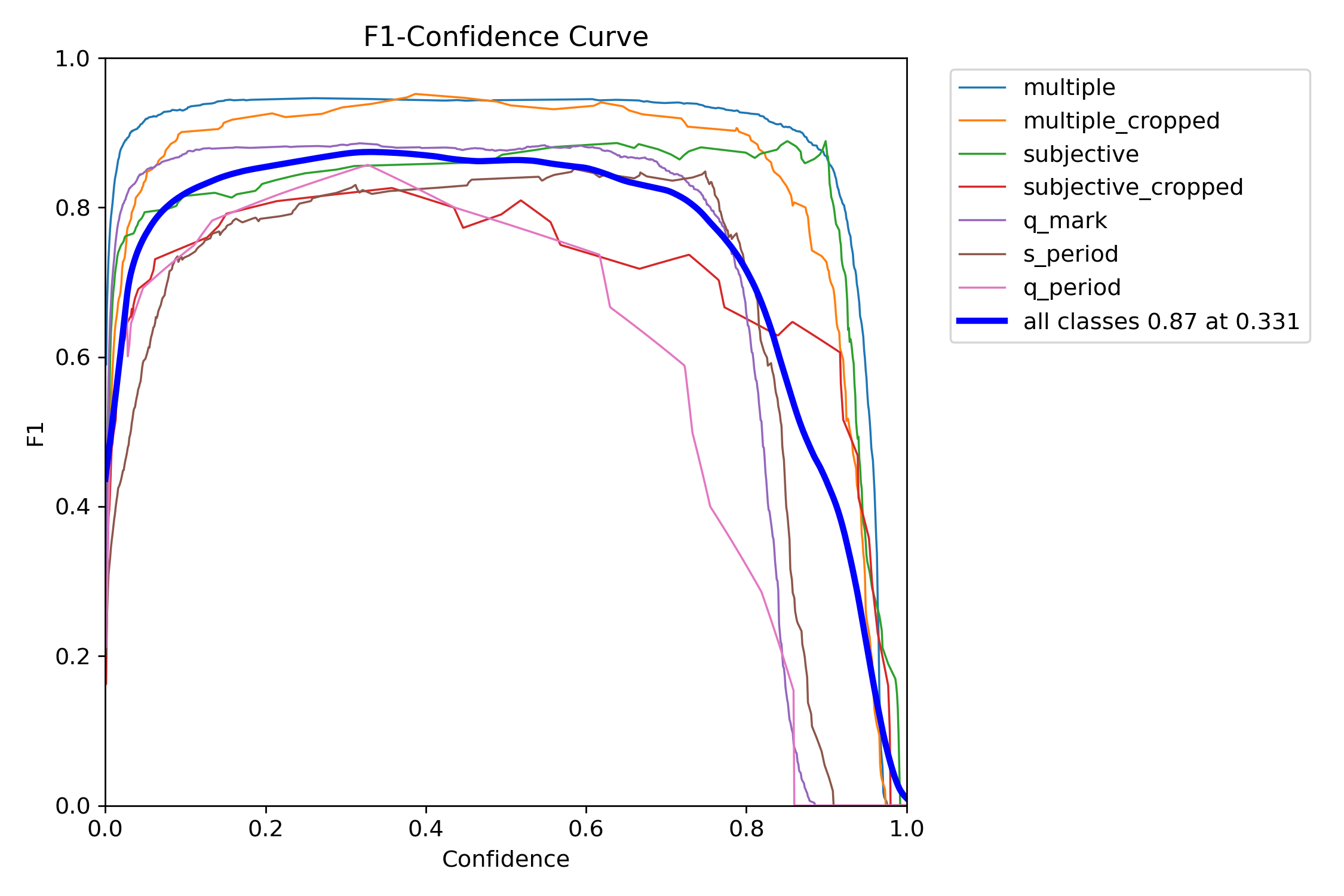
그래프
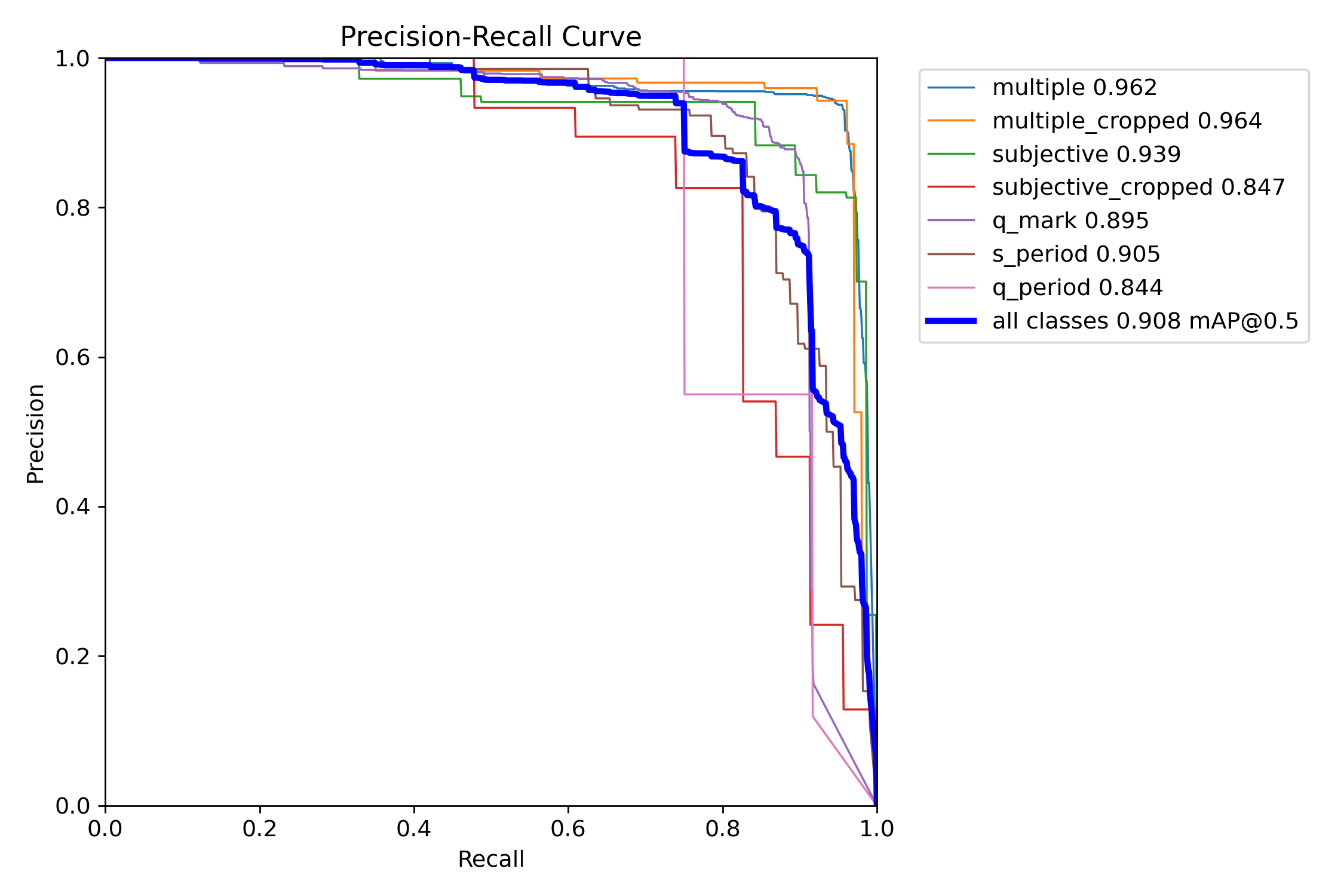
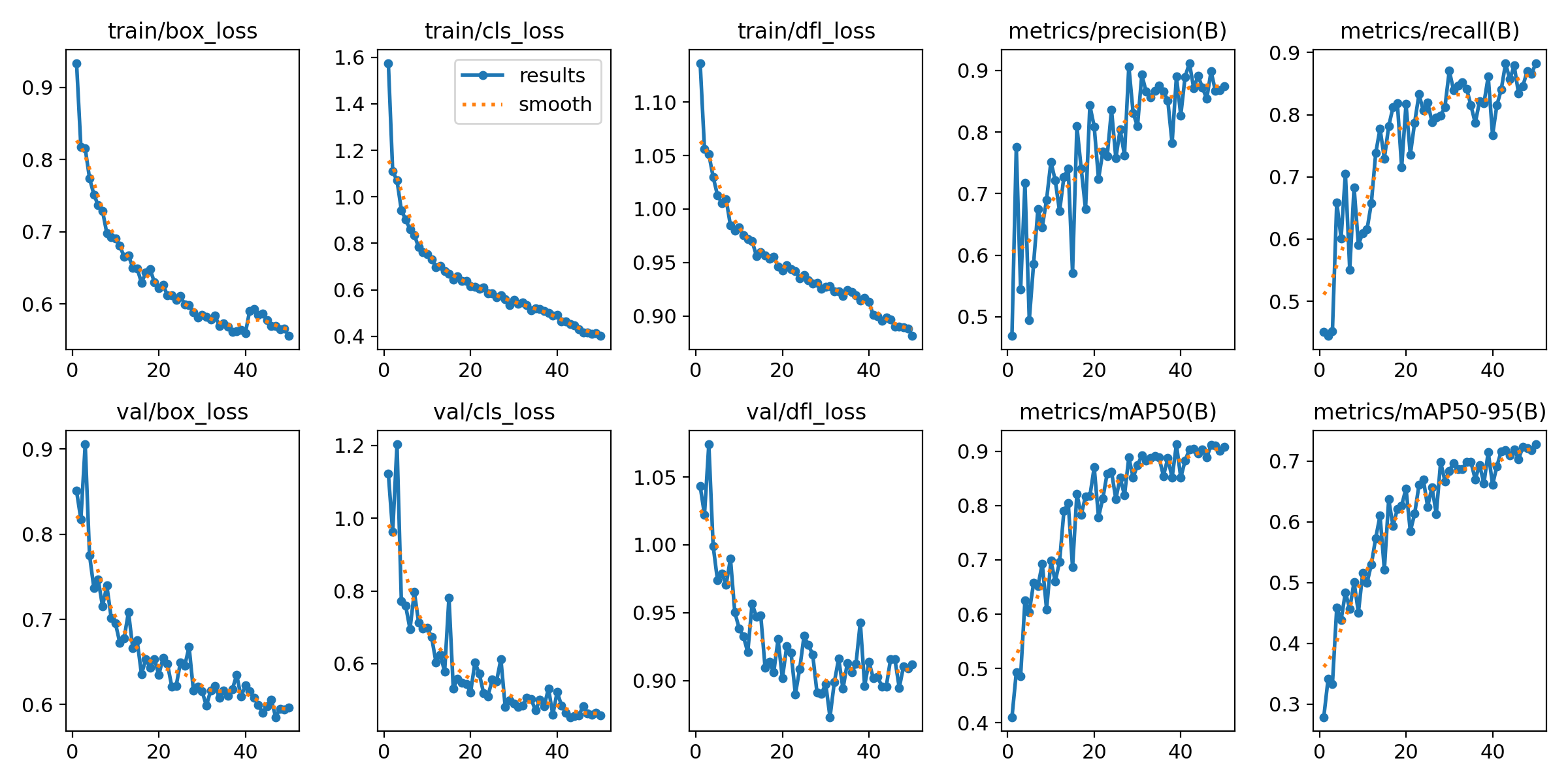
결과

multiple: mAP50 0.908, mAP50-95 0.907
multiple_cropped: mAP50 0.964, mAP50-95 0.863
subjective: mAP50 0.939, mAP50-95 0.862
subjective_cropped: mAP50 0.847, mAP50-95 0.764
q_mark: mAP50 0.895, mAP50-95 0.562
q_period: mAP50 0.844, mAP50-95 0.553
s_period: mAP50 0.905, mAP50-95 0.57
all: mAP50 0.908, mAP50-95 0.726
ㅤ
잘린 문항 매칭
수능 데이터 기준으로 만들었기 때문에, 잘린 객관식 문항만이 매칭 가능하다.
잘린 문항의 유형을 분류하고, 맞는 유형끼리 이어붙여 잘리지 않은 객관식 문항 형태로 반환한다.
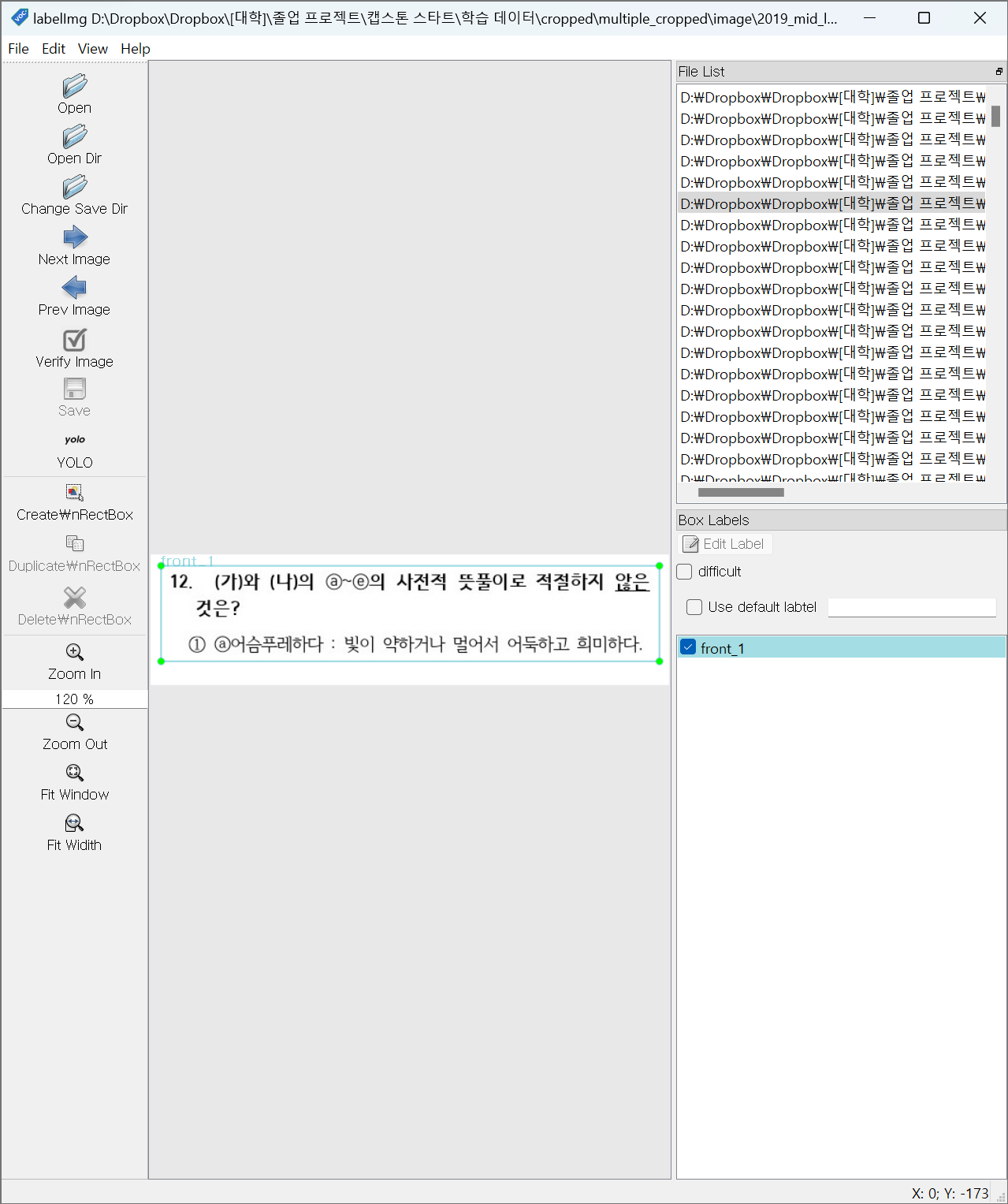
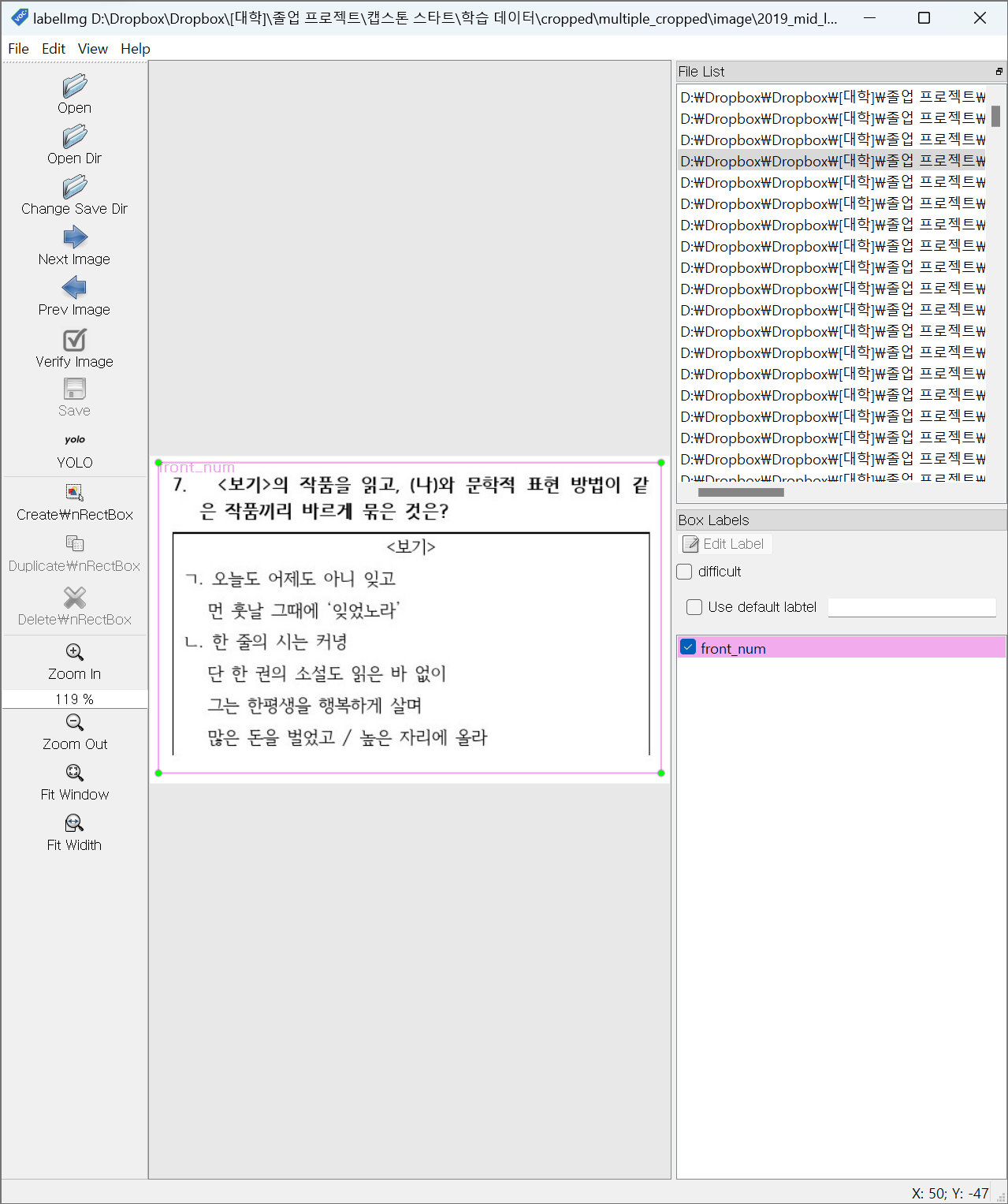
입력 이미지


라벨링
라벨 목록
front_num: 문항 번호와 문제까지 포함하고 앞에서 잘린 유형
front_1: 문항 번호와 문제와 1번 선지까지 포함하고 앞에서 잘린 유형
front_2: 문항 번호와 문제와 2번 선지까지 포함하고 앞에서 잘린 유형
front_3: 문항 번호와 문제와 3번 선지까지 포함하고 앞에서 잘린 유형
front_4: 문항 번호와 문제와 4번 선지까지 포함하고 앞에서 잘린 유형
front_5: 문항 번호와 문제와 5번 선지까지 포함하고 앞에서 잘린 유형, 사실상 잘리지 않은 문항인데 잘렸다고 잘못 분류된 유형이다.
back_num: 문항 번호와 문제까지 포함하지 않고 뒤에서 잘린 유형
back_1: 문항 번호와 문제와 1번 선지까지 포함하지 않고 뒤에서 잘린 유형
back_2: 문항 번호와 문제와 2번 선지까지 포함하지 않고 뒤에서 잘린 유형
back_3: 문항 번호와 문제와 3번 선지까지 포함하지 않고 뒤에서 잘린 유형
back_4: 문항 번호와 문제와 4번 선지까지 포함하지 않고 뒤에서 잘린 유형
back_5: 문항 번호와 문제와 5번 선지까지 포함하지 않고 뒤에서 잘린 유형, 매칭 필요 없이 버려도 되는 유형이다.
etc: 위 유형 중 어느 것에도 속하지 않은 기타 유형
front_num과 back_num은 서로 맞는 유형이다.
front_1과 back_1은 서로 맞는 유형이다.
front_2와 back_2는 서로 맞는 유형이다.
front_3과 back_3은 서로 맞는 유형이다.
front_4와 back_4는 서로 맞는 유형이다.
라벨링 사진


그래프

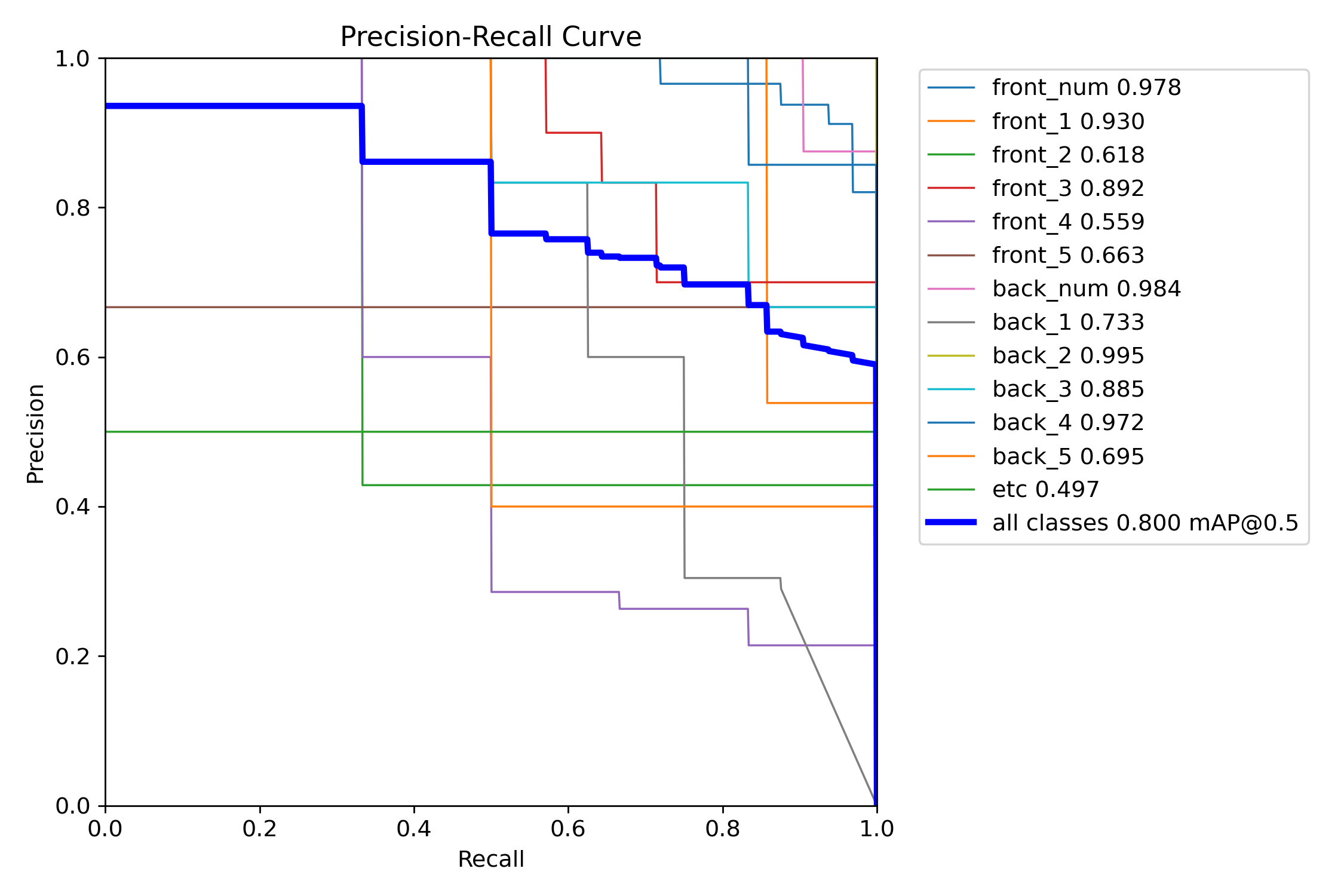
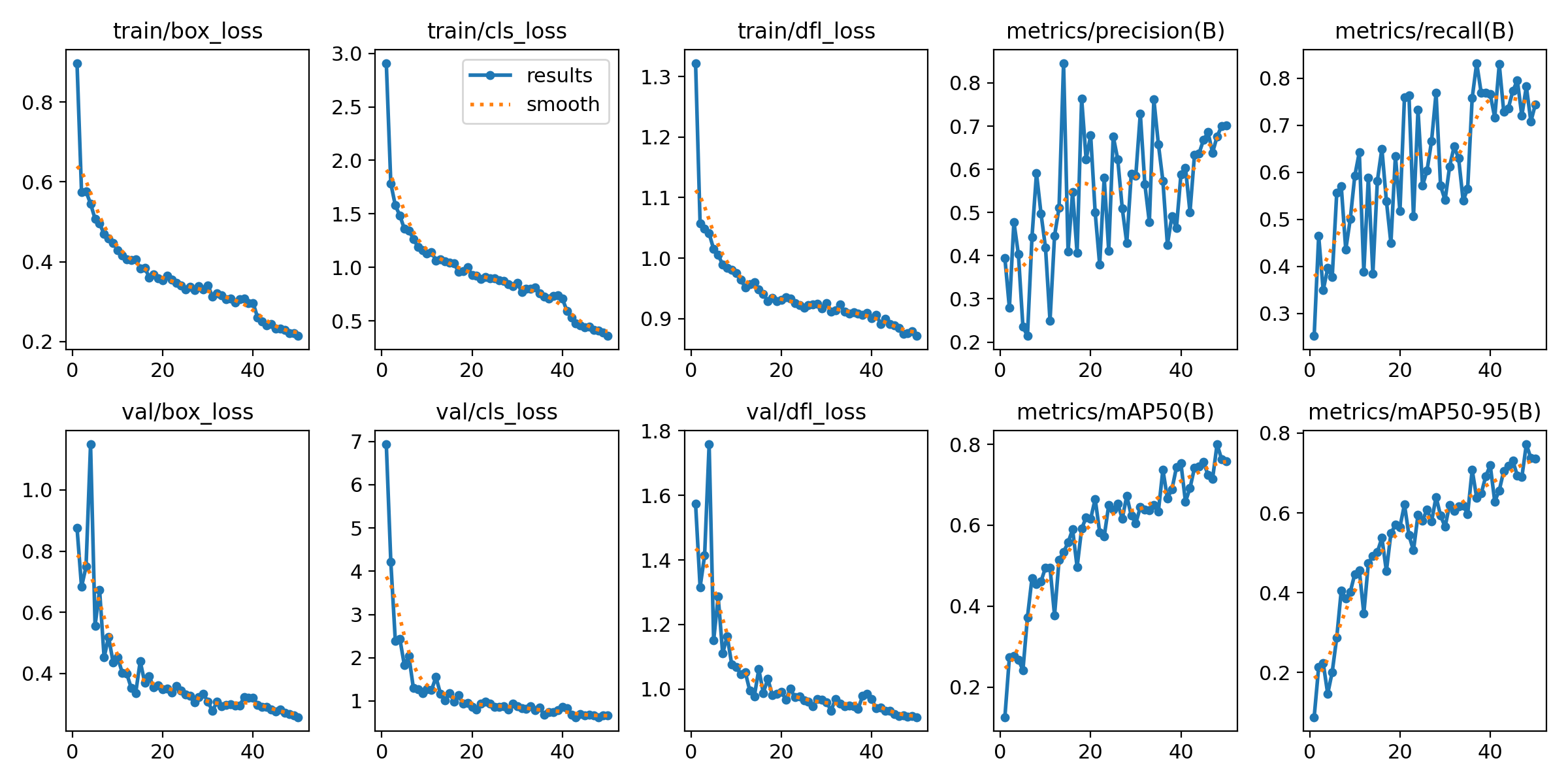
결과

front_num: mAP50 0.978, mAP50-95 0.934
front_1: mAP50 0.93, mAP50-95 0.864
front_2: mAP50 0.618, mAP50-95 0.576
front_3: mAP50 0.892, mAP50-95 0.892
front_4: mAP50 0.559, mAP50-95 0.559
front_5: mAP50 0.663, mAP50-95 0.663
back_num: mAP50 0.984, mAP50-95 0.962
back_1: mAP50 0.733, mAP50-95 0.678
back_2: mAP50 0.995, mAP50-95 0.966
back_3: mAP50 0.885, mAP50-95 0.876
back_4: mAP50 0.972, mAP50-95 0.96
back_5: mAP50 0.695, mAP50-95 0.607
etc: mAP50 0.497, mAP50-95 0.497
all: mAP50 0.8, mAP50-95 0.772
ㅤ
객관식 선지 추출
입력 이미지


라벨링
라벨 목록
num: 문항 번호
check1: 체크된 1번 선지
check2: 체크된 2번 선지
check3: 체크된 3번 선지
check4: 체크된 4번 선지
check5: 체크된 5번 선지
라벨링 사진

그래프
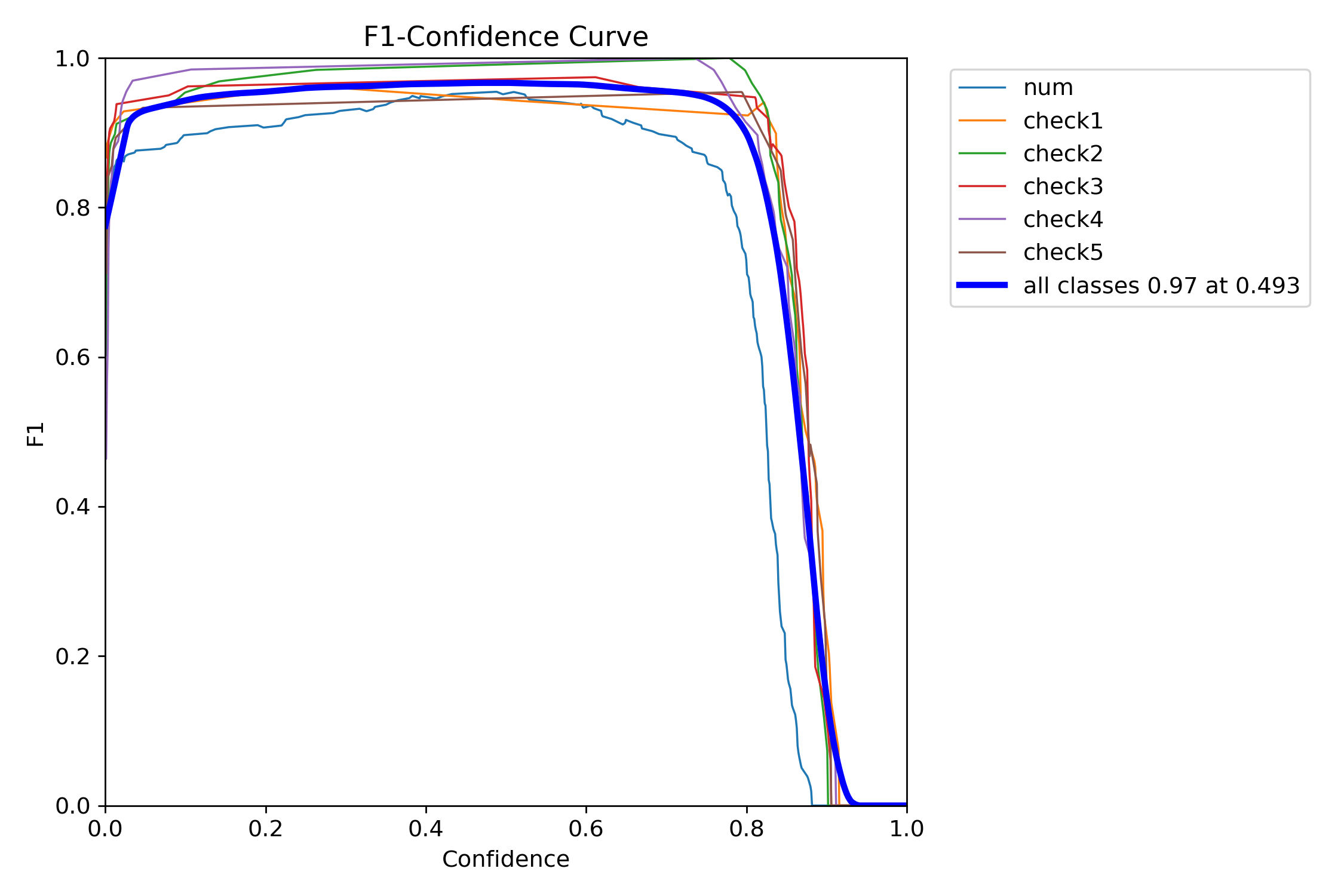
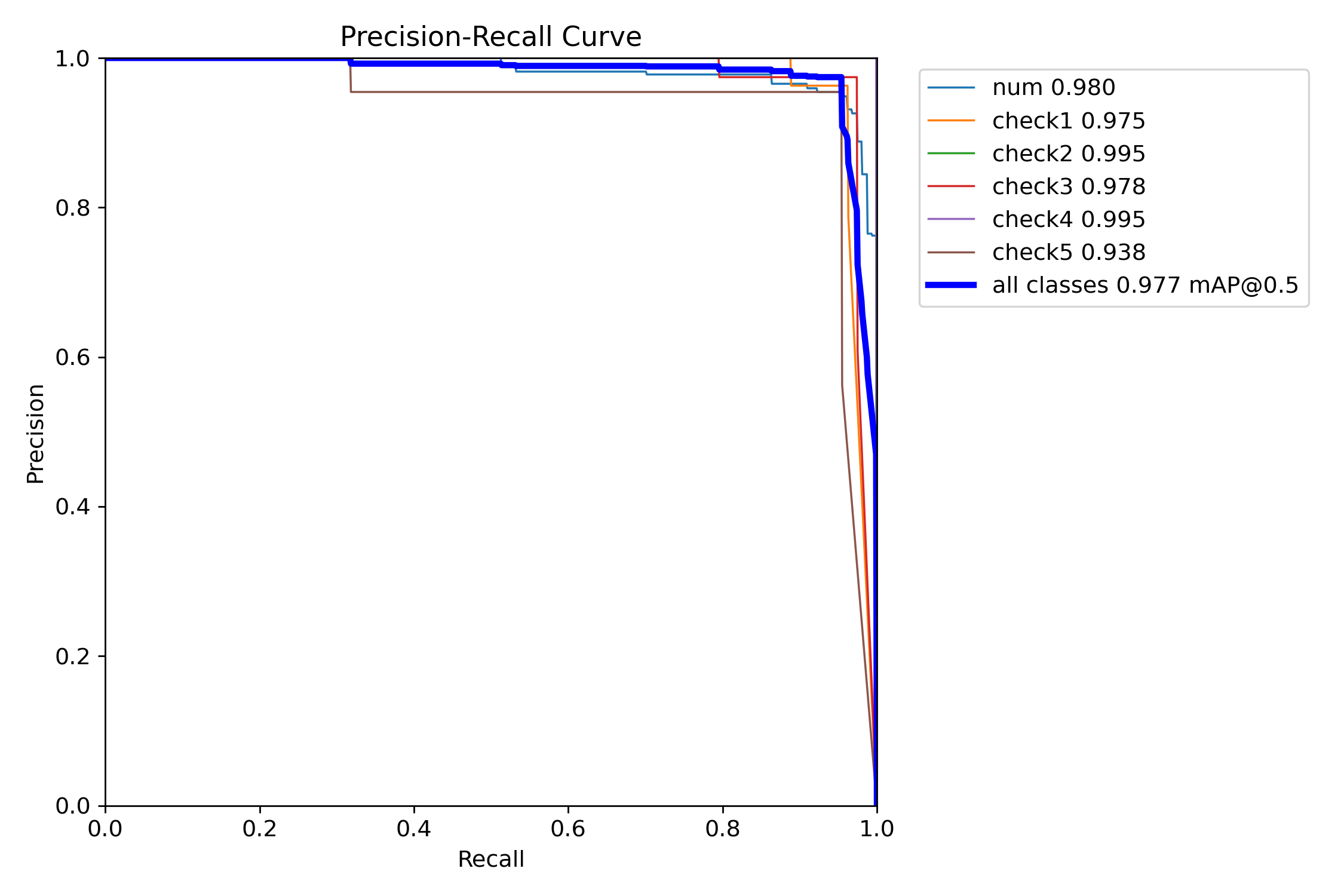

결과
num: mAP50 0.98, mAP50-95 0.659
check1: mAP50 0.975, mAP50-95 0.644
check2: mAP50 0.995, mAP50-95 0.738
check3: mAP50 0.978, mAP50-95 0.664
check4: mAP50 0.995, mAP50-95 0.721
check5: mAP50 0.938, mAP50-95 0.704
all: mAP50 0.977, mAP50-95 0.688
ㅤ
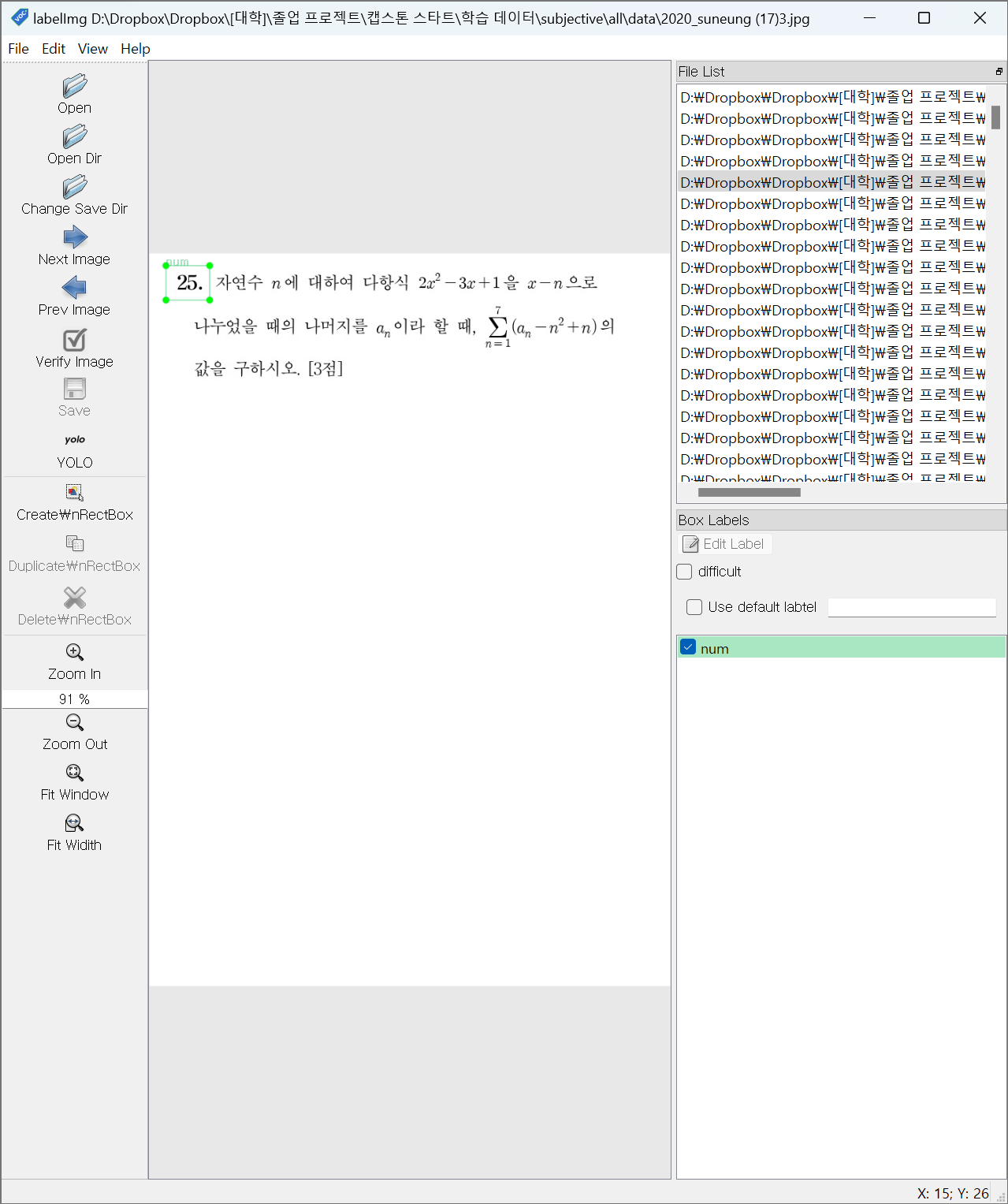
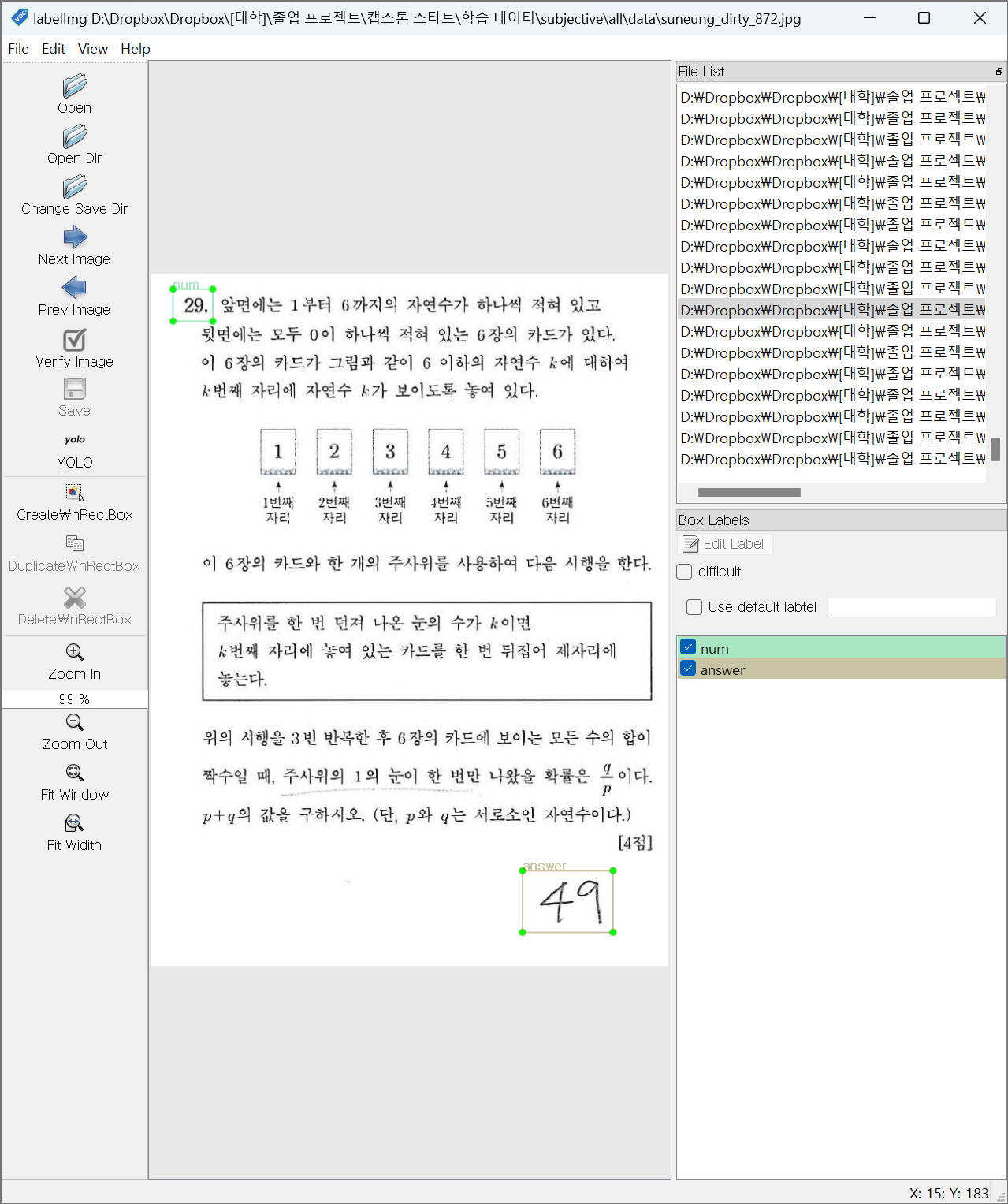
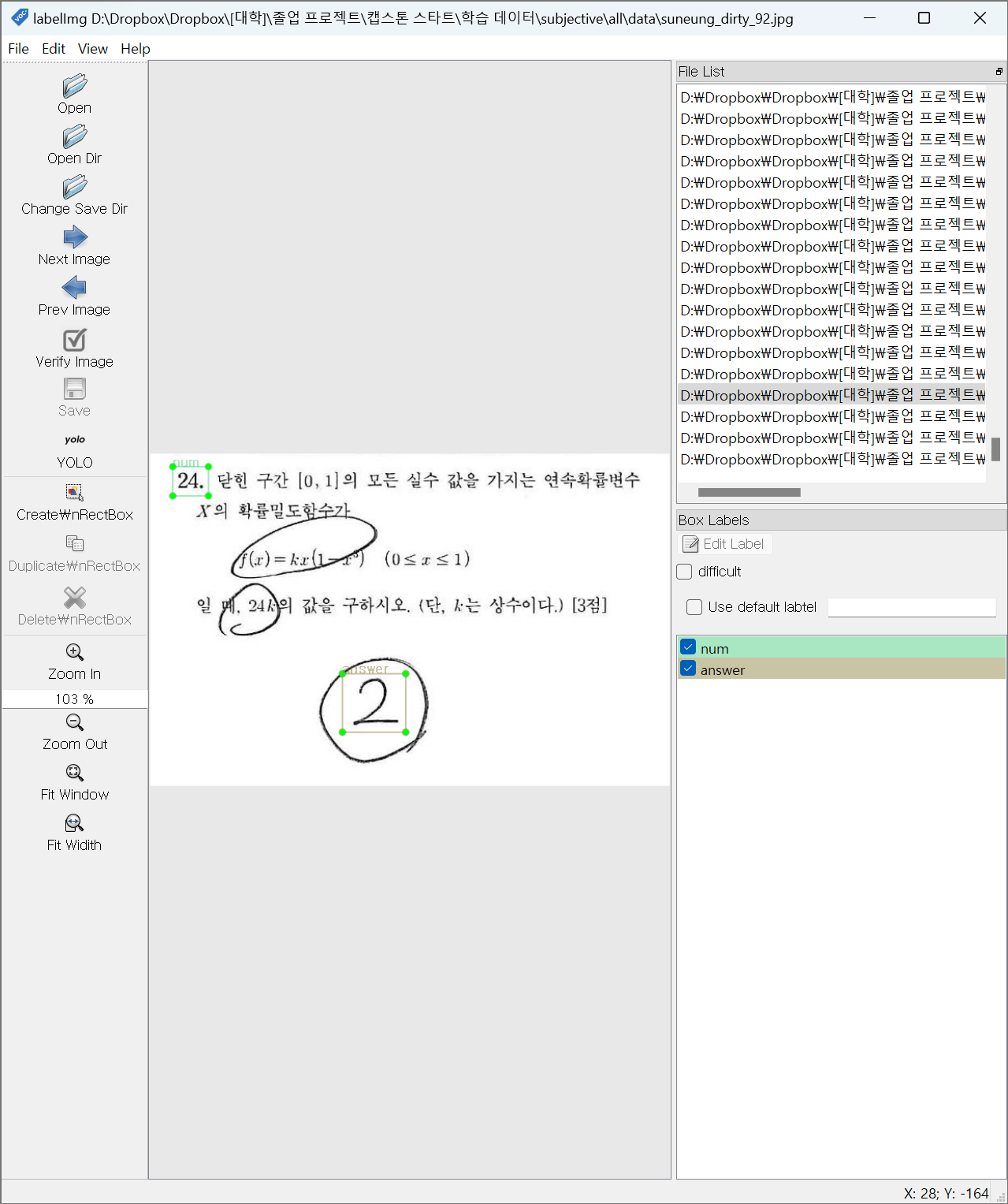
단답식 답안 추출
입력 이미지


라벨링
라벨 목록
num: 문항 번호
answer: 답안 영역
라벨링 사진
그래프
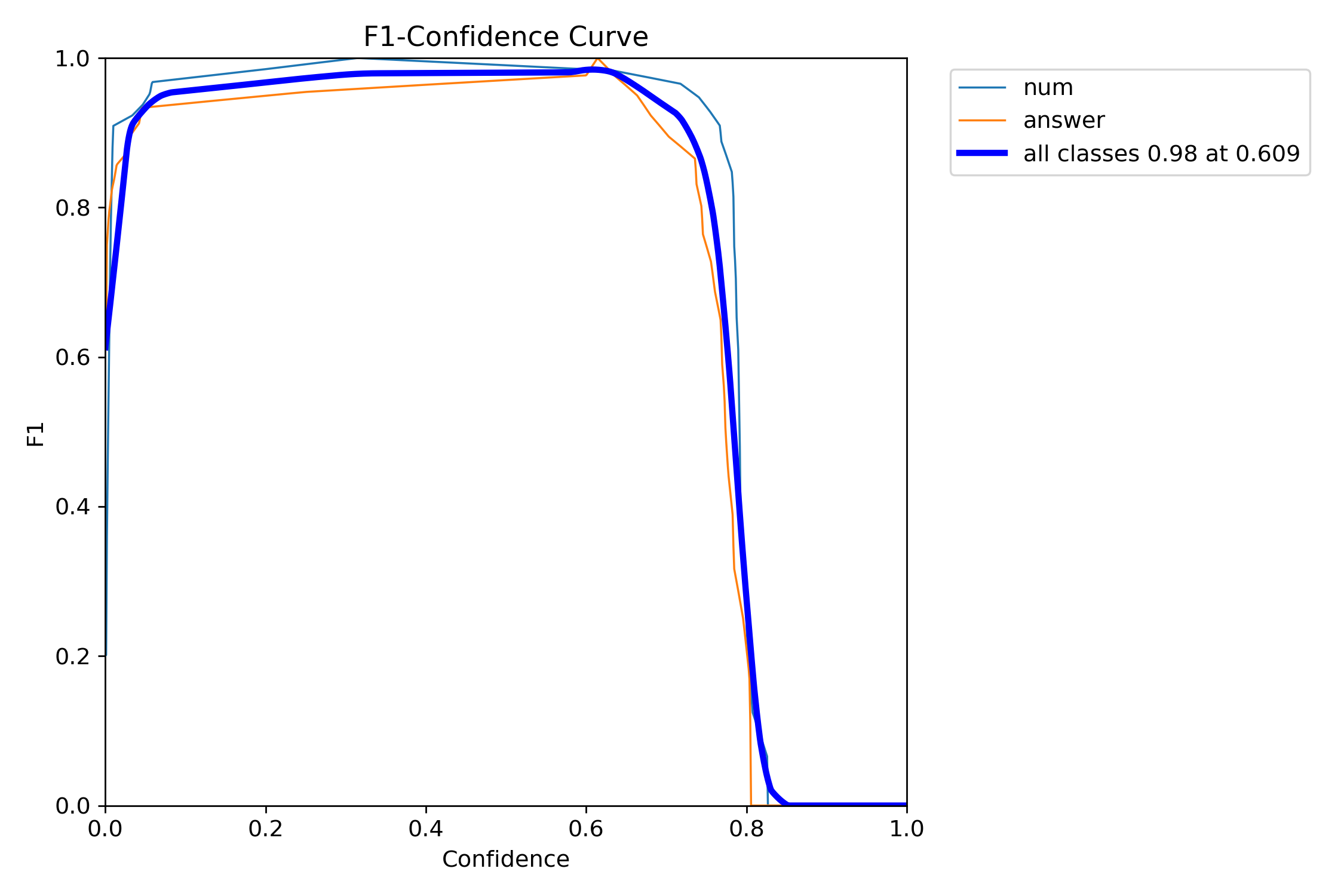
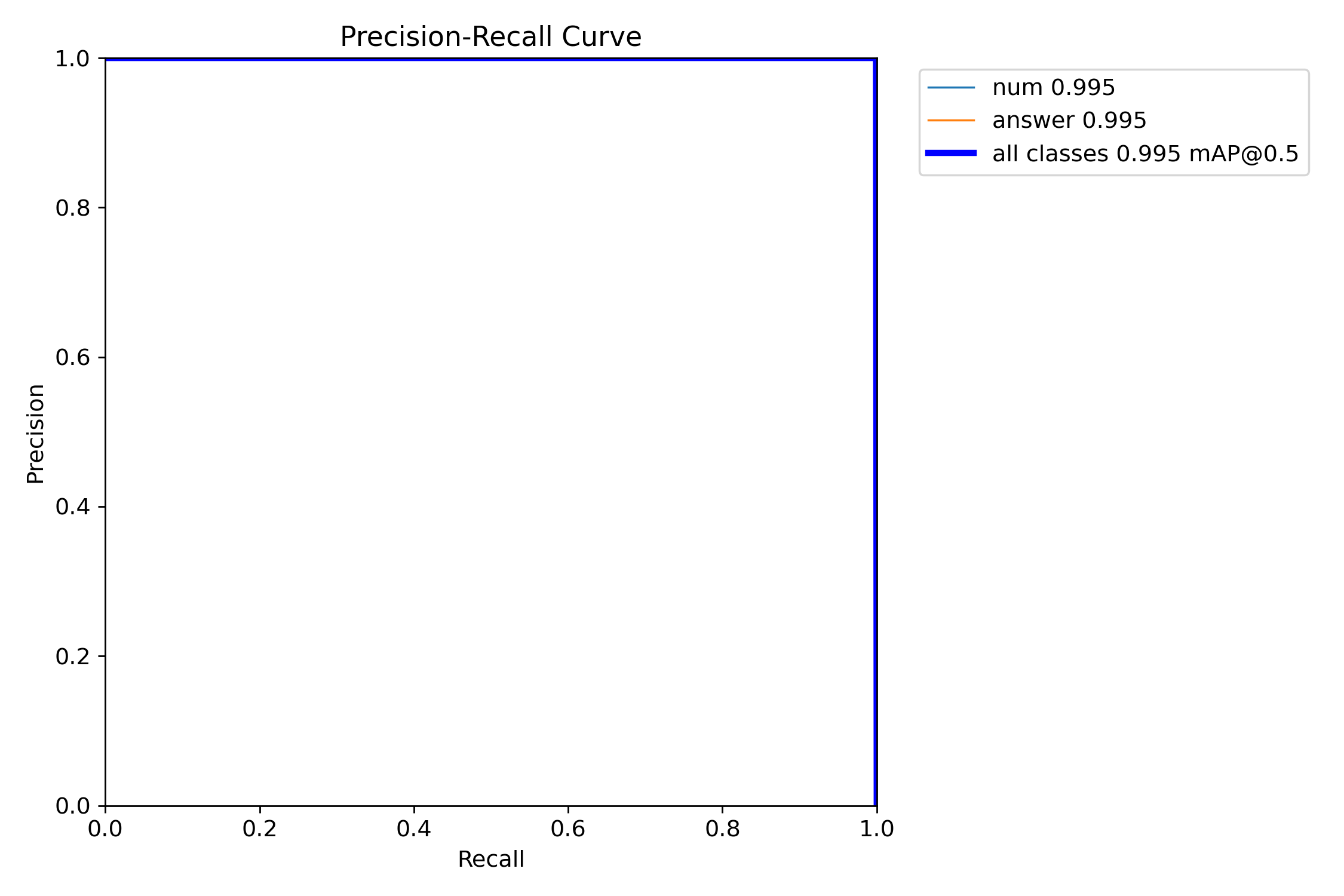
결과
num: mAP50 0.995, mAP50-95 0.641
answer: mAP50 0.995, mAP50-95 0.701
all: mAP50 0.995, mAP50-95 0.671
ㅤ
ㅤ
ㅤ
백엔드 서버 구축
AWS EC2
해당 프로젝트는 Yolov8, EasyOCR, OCR Tamil을 사용하기 때문에 평범한 cpu 사양의 노트북에서 돌릴 경우 사용자의 로컬 cpu 자원을 독점하는 문제가 발생한다. 따라서 사용자의 원활한 컴퓨터 사용을 위해, 서버를 따로 두어 서버의 cpu/gpu를 사용하도록 AWS EC2를 활용한 가상환경을 구축했다.
리전 선택
EC2 홈 화면 링크: https://console.aws.amazon.com/ec2/home
먼저 루트 사용자로 (회원가입 후) 로그인한 후, ec2 홈 화면에서 리전을 선택한다. 리전의 디폴트 값은 '미국 동부 (버지니아 북부)'인데, 해당 프로젝트의 경우 리전을 '아시아 태평양 (서울)'을 바꿔 설정했다.
ㅤ
인스턴스 시작
EC2 인스턴스 화면 링크: https://console.aws.amazon.com/ec2/home#Instances
인스턴스 화면에 들어가서 '인스턴스 시작' 버튼을 누른다.ㅤ
ㅤ
인스턴스 생성
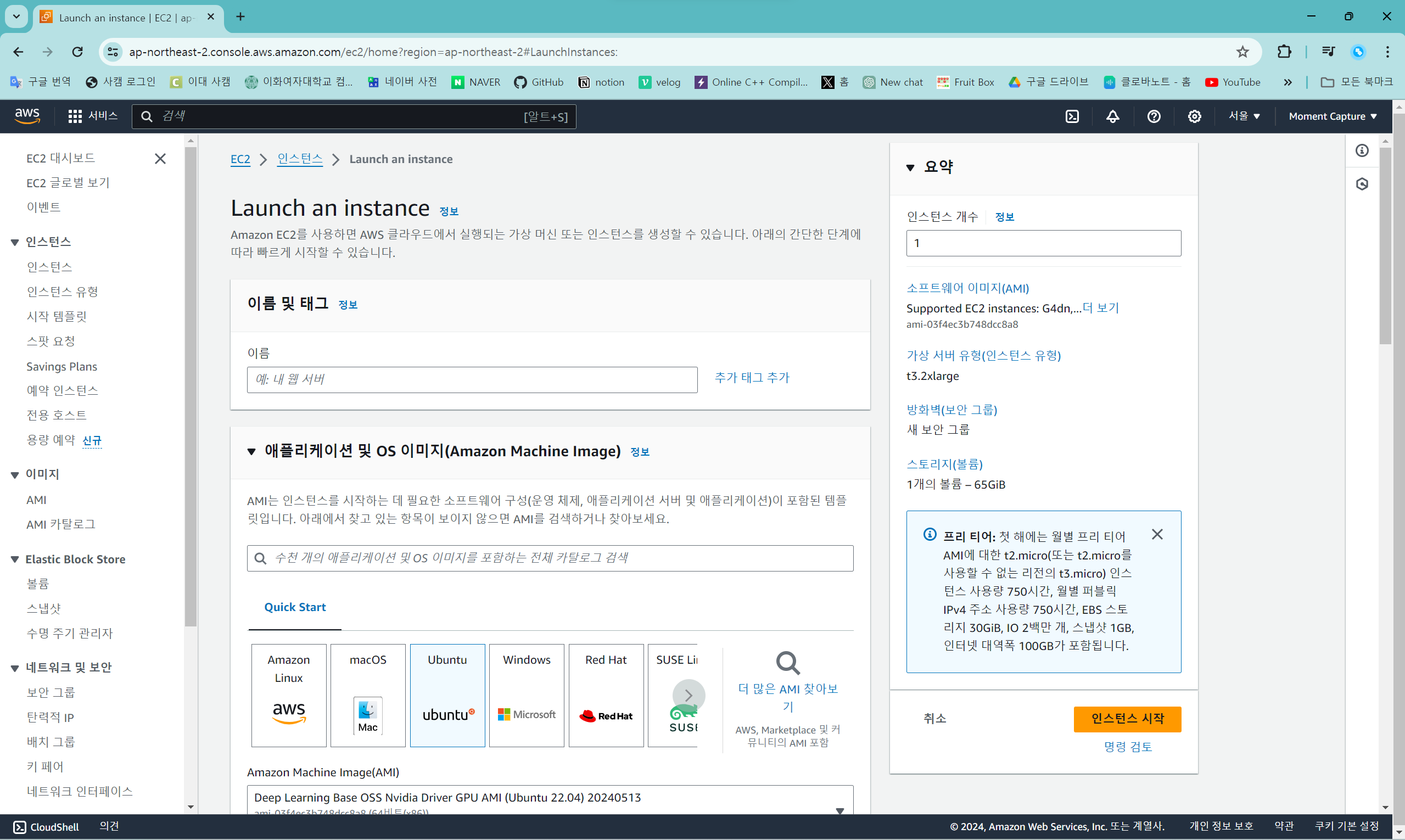
인스턴스 시작 화면의 구성은 이렇다.
이름 및 태그
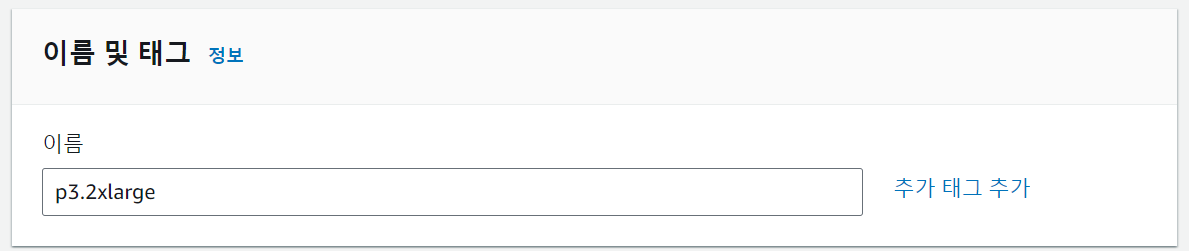
이름은 자율적으로 설정한다.
해당 프로젝트에서는 사용할 인스턴스 유형을 이름으로 설정했다.
애플리케이션 및 OS 이미지
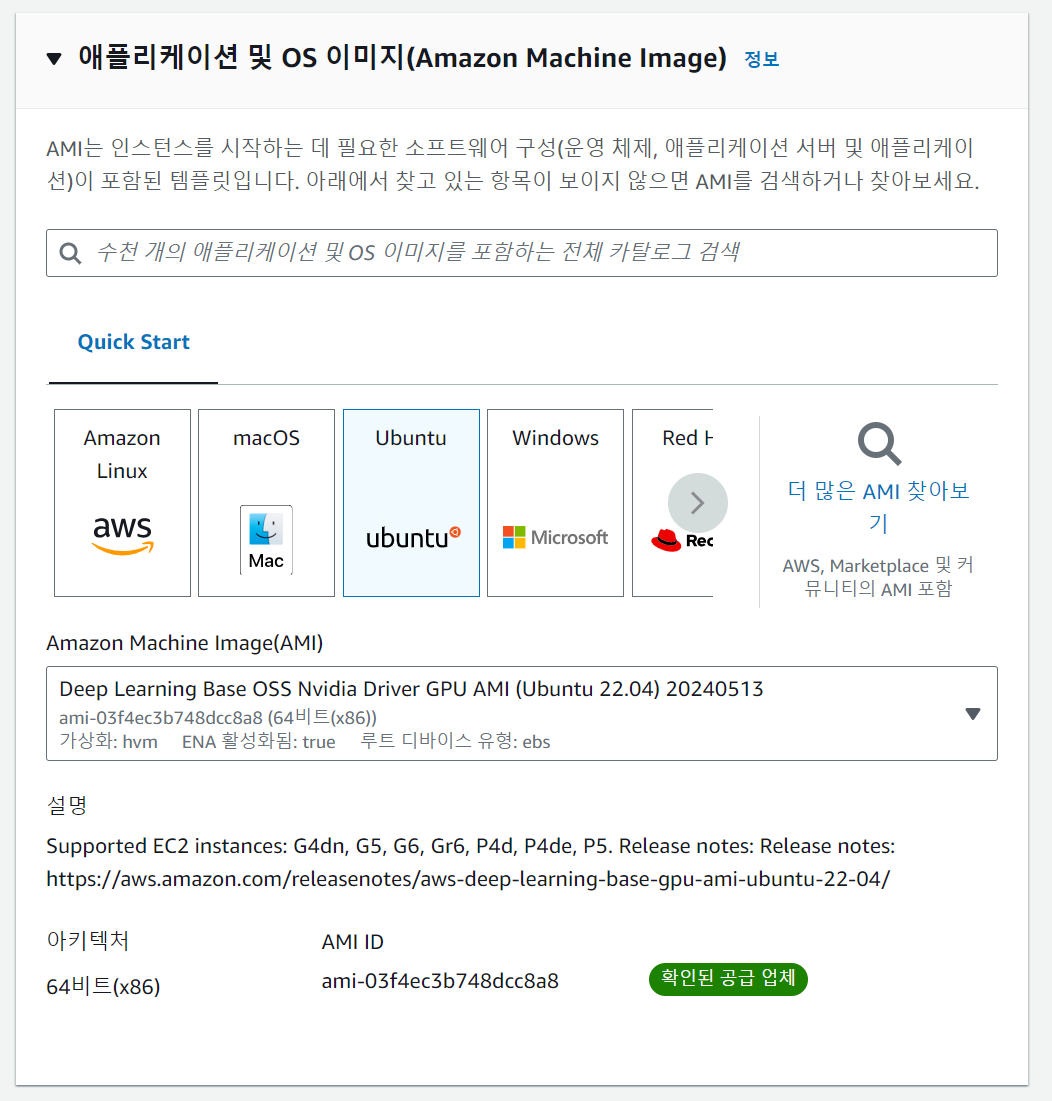
AMI는 'Ubuntu' 기반의, 'Deep Learning Base OSS Nvidia Driver GPU AMI (Ubuntu 22.04) 20240513'을 선택하도록 한다.
딥러닝 모델을 훈련시키거나 가동할 때는 리눅스/우분투 계열의 OS를 사용하는 게 일반적이다. 다른 OS의 경우 딥러닝 특화 AMI를 제공하지 않는다는 점을 유의해야 한다. AMI의 경우 전체 카탈로그 창에 'Deep Learning'을 검색했을 때 가장 위에 나오는 것을 골랐는데, 이는 가장 최신의 GPU AMI를 의미한다.
인스턴스 유형
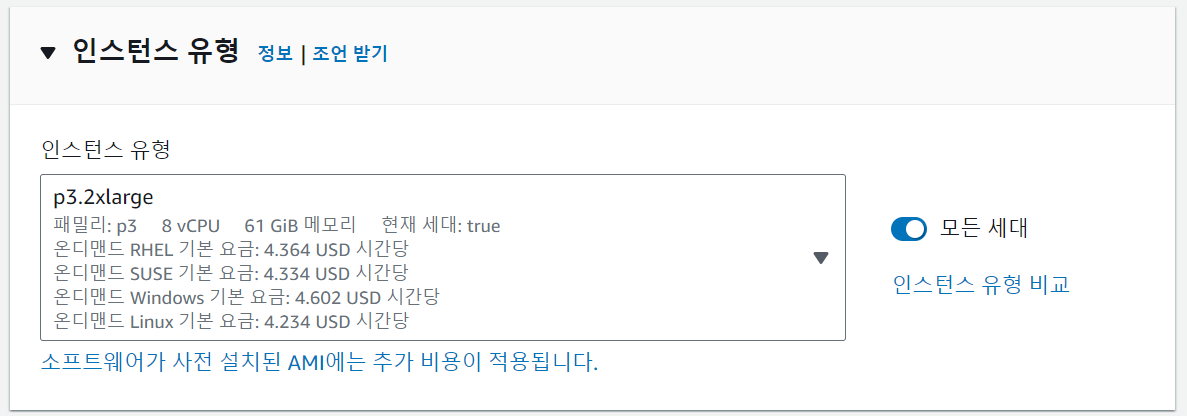
인스턴스 유형은 p3.2xlarge로 설정한다. 이때, p3 vCPU 기본 할당량이 0이기 때문에 따로 vCPU 할당량 요청을 해야 한다. "할당량 요청"은 아래에서 따로 다룬다.
인스턴스 유형을 고르는 기준은 다양한데, 할당량 증가 요청이 용이하며 학생 수준에서 부담이 가능한 비용을 청구하는 유형으로 P3를 골랐다.
키 페어
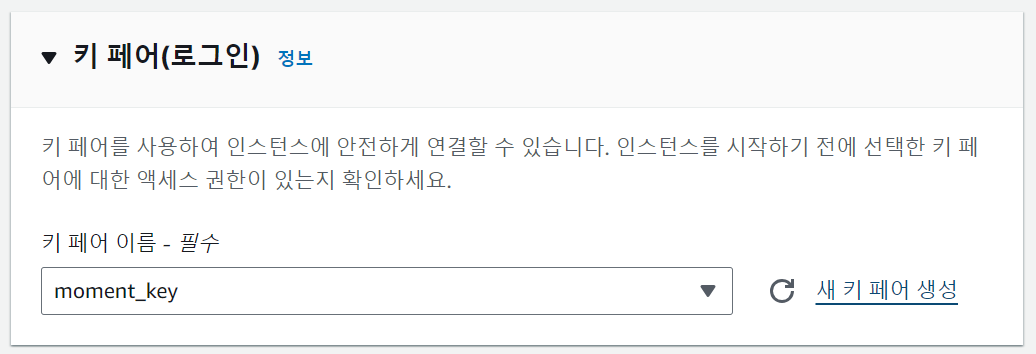
인스턴스를 연결할 때 필요한 키 페어를 설정한다. 이미 생성한 키 페어가 있다면 해당 키 페어를 고를 수 있고, 없다면 새 키 페어를 생성할 수 있다.
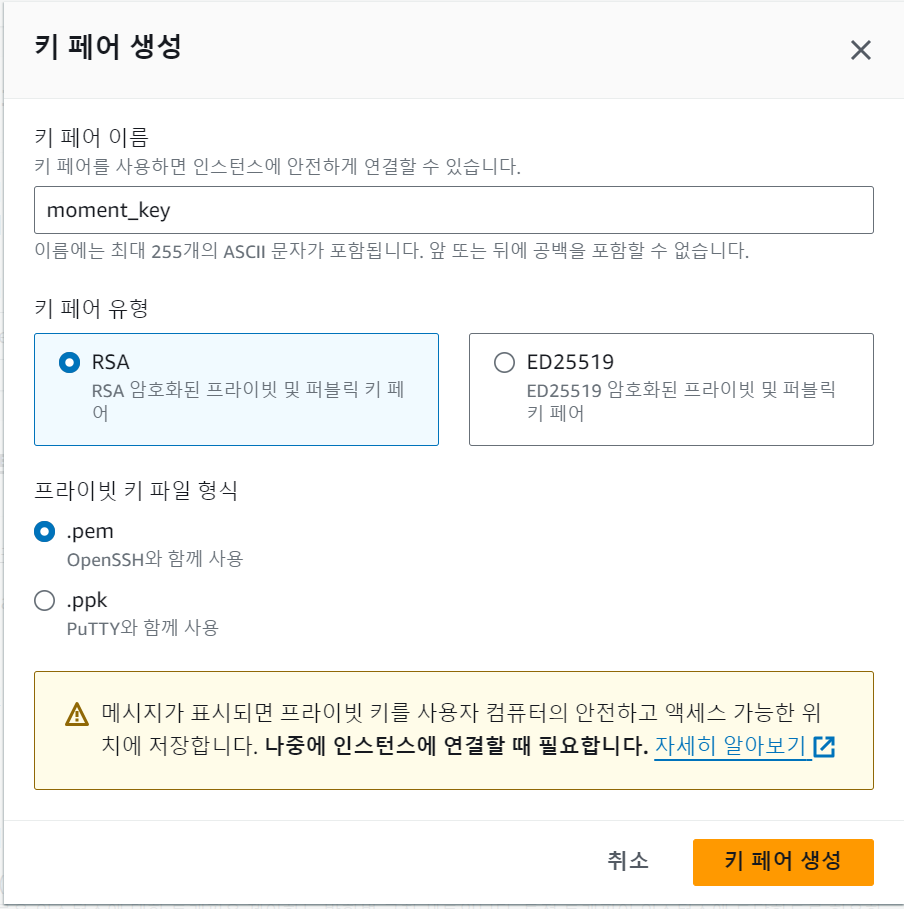
키 페어를 생성할 때 이름과 유형과 프라이빗 키 파일 형식으로 골라야 한다. 이름에 공백이 포함된다면 하이픈(-)이나 언더바(_)를 사용해 설정하도록 한다. 키 페어 유형은 RSA를 사용했으며, 프라이빗 키 파일 형식은 .pem으로 골랐다.
'키 페어 생성'을 누르면 프라이빗 키를 저장하는 창이 열린다. 필요한 곳에 저장을 하고 나중에 인스턴스 연결을 할 때 프라이빗 키를 접속에 사용하면 된다.
네트워크 설정
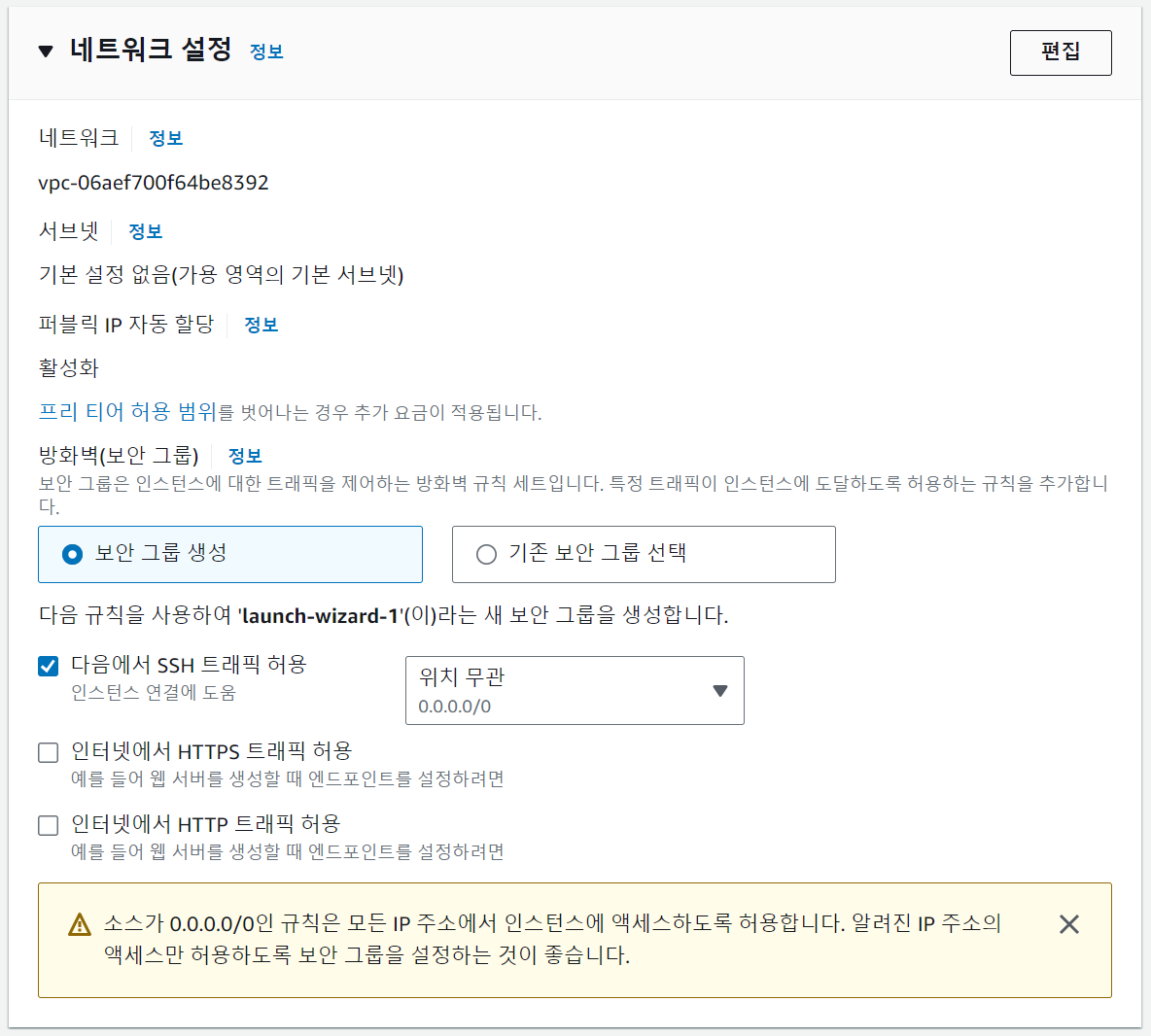
네트워크를 설정할 때 보안 설정을 같이 한다. 이미 생성한 보안 그룹이 있다면 기존 보안 그룹을 선택할 수 있고, 없다면 새 보안 그룹을 생성할 수 있다. 우측 상단의 '편집' 버튼을 누르면 새로 생성하는 보안 그룹의 인바운드 보안 그룹 규칙을 세부적으로 설정할 수 있다.
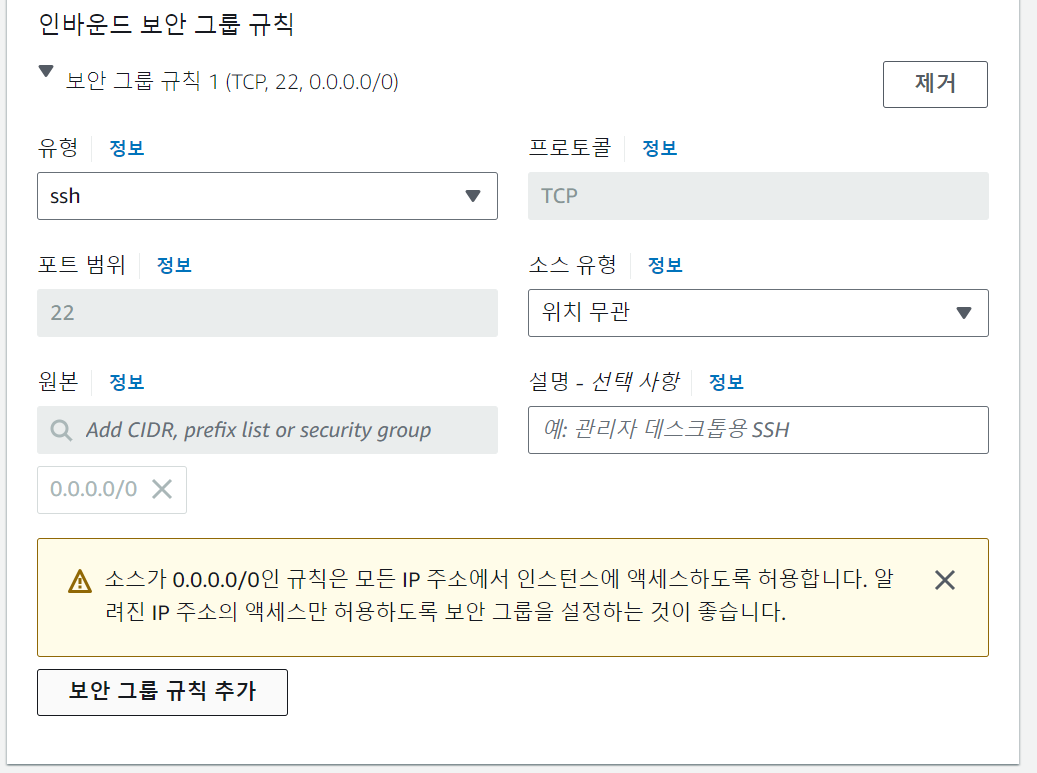
'보안 그룹 규칙 추가'를 눌러 필요한 규칙들을 추가한다.
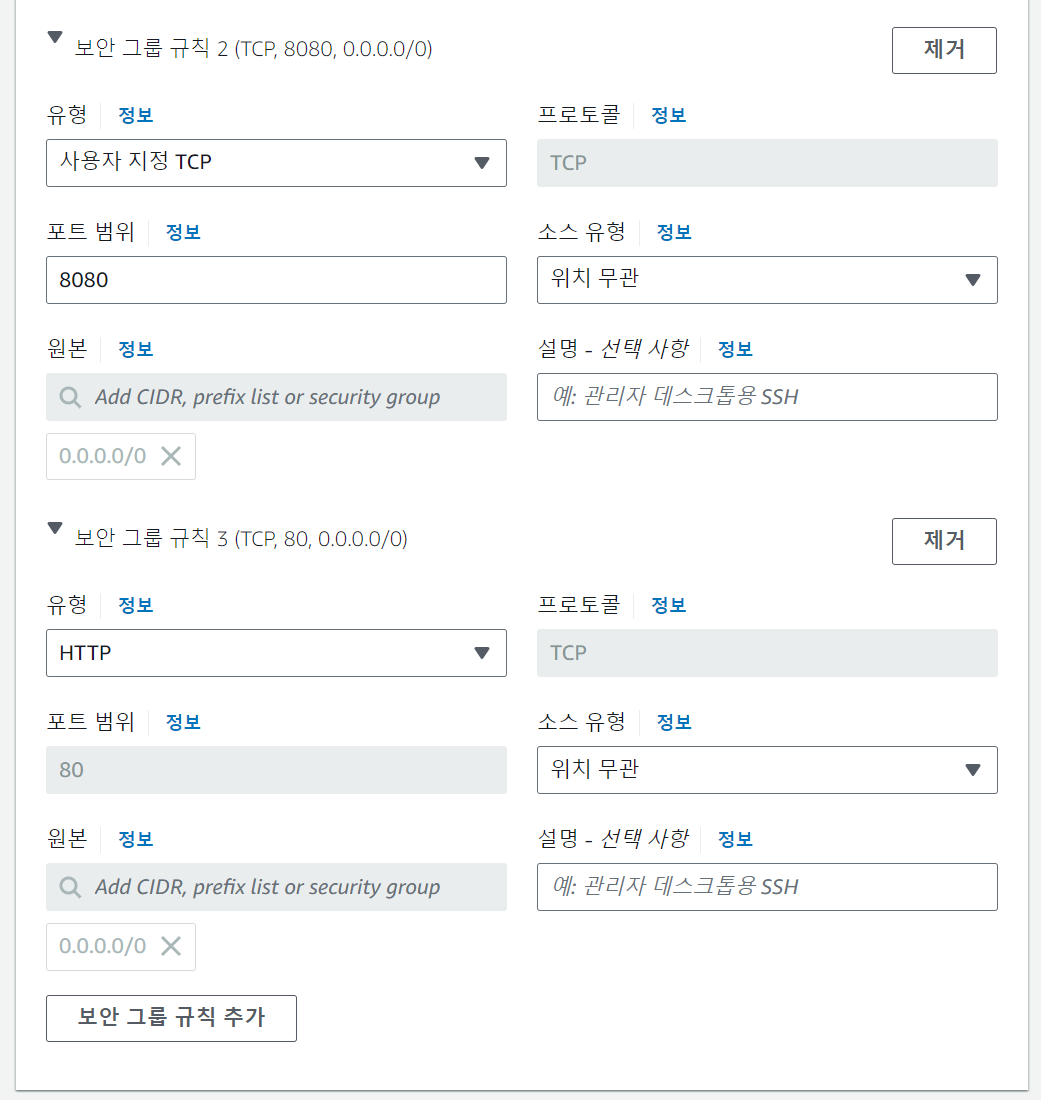
'보안 그룹 규칙 2'는 사용자 지정 TCP의 8080 포트를 열어 Flask를 통한 접속을 허용한다. 해당 설정을 추가하지 않으면 규칙이 없기 때문에 막혀 버리고 만다.
'보안 그룹 규칙 3'은 HTTP의 80 포트를 열어 두는 건데, 혹시 몰라 추가해 뒀다.
이론적으로는 8080 포트만 열어 둬도 접속이 가능해야 한다.
스토리지 구성
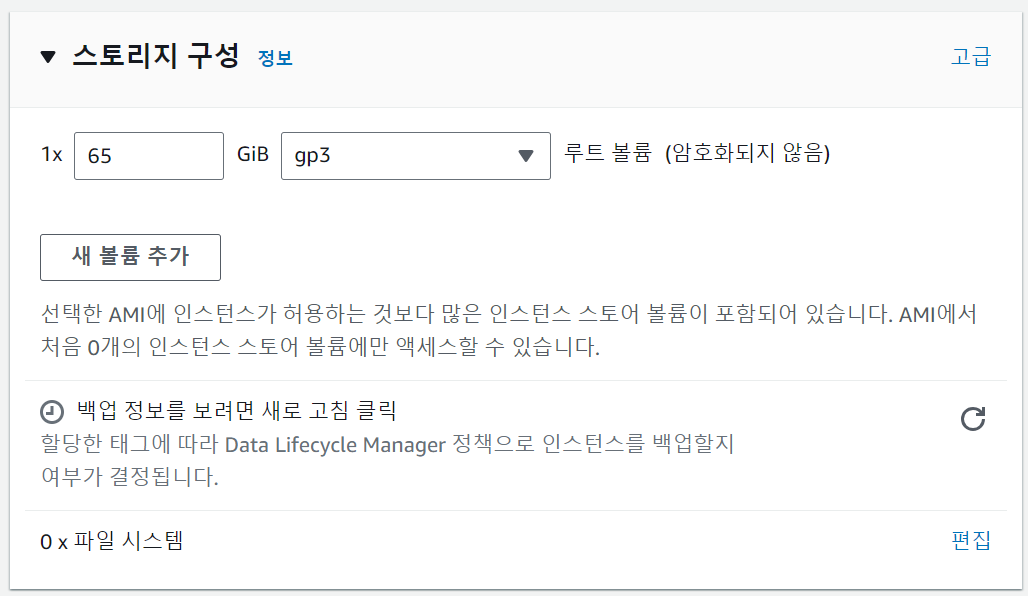
필요한 만큼 스토리지 볼륨을 설정한다. 다다익선이니 넉넉하게 설정하는 게 좋을 것이다.
요약
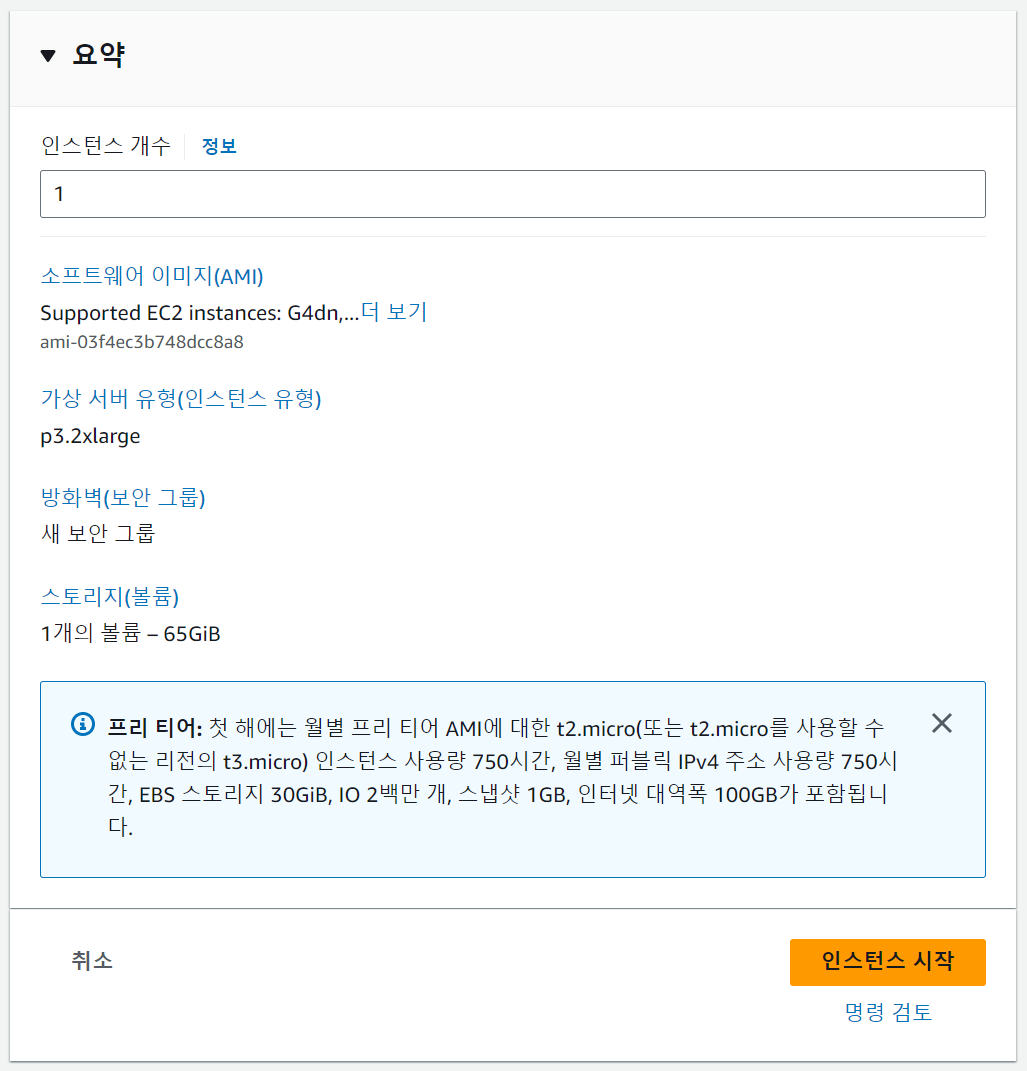
인스턴스 개수를 설정할 수 있다. 하나만 필요해서 1로 설정했다. 인스턴스 시작을 누르면 인스턴스 생성이 완료된다.
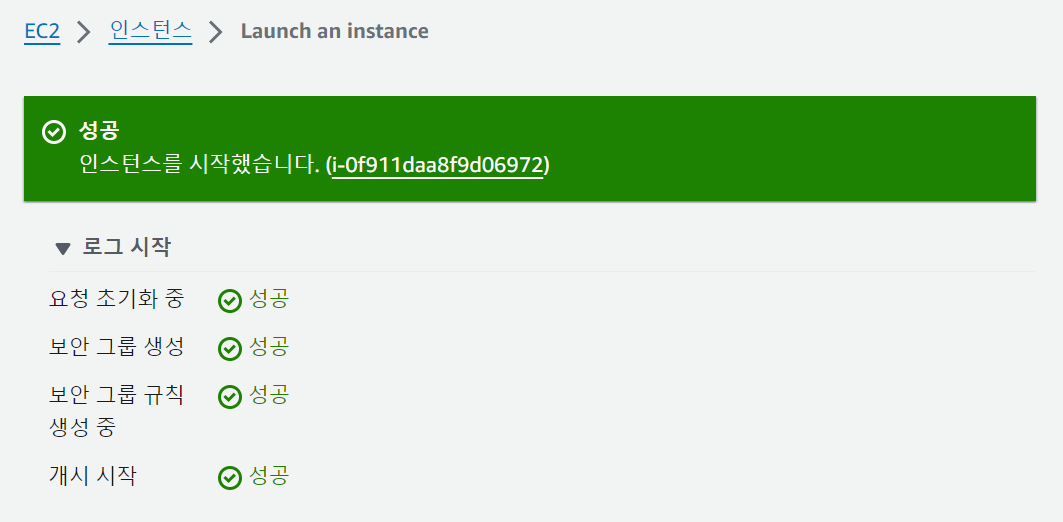 ㅤ
ㅤ
ㅤ
인스턴스 연결
인스턴스 연결에는 크게 두 방법이 있다. EC2 화면에서 바로 연결하는 방법과, SSH 클라이언트를 사용해서 연결하는 방법이다.
1. EC2 인스턴스 연결
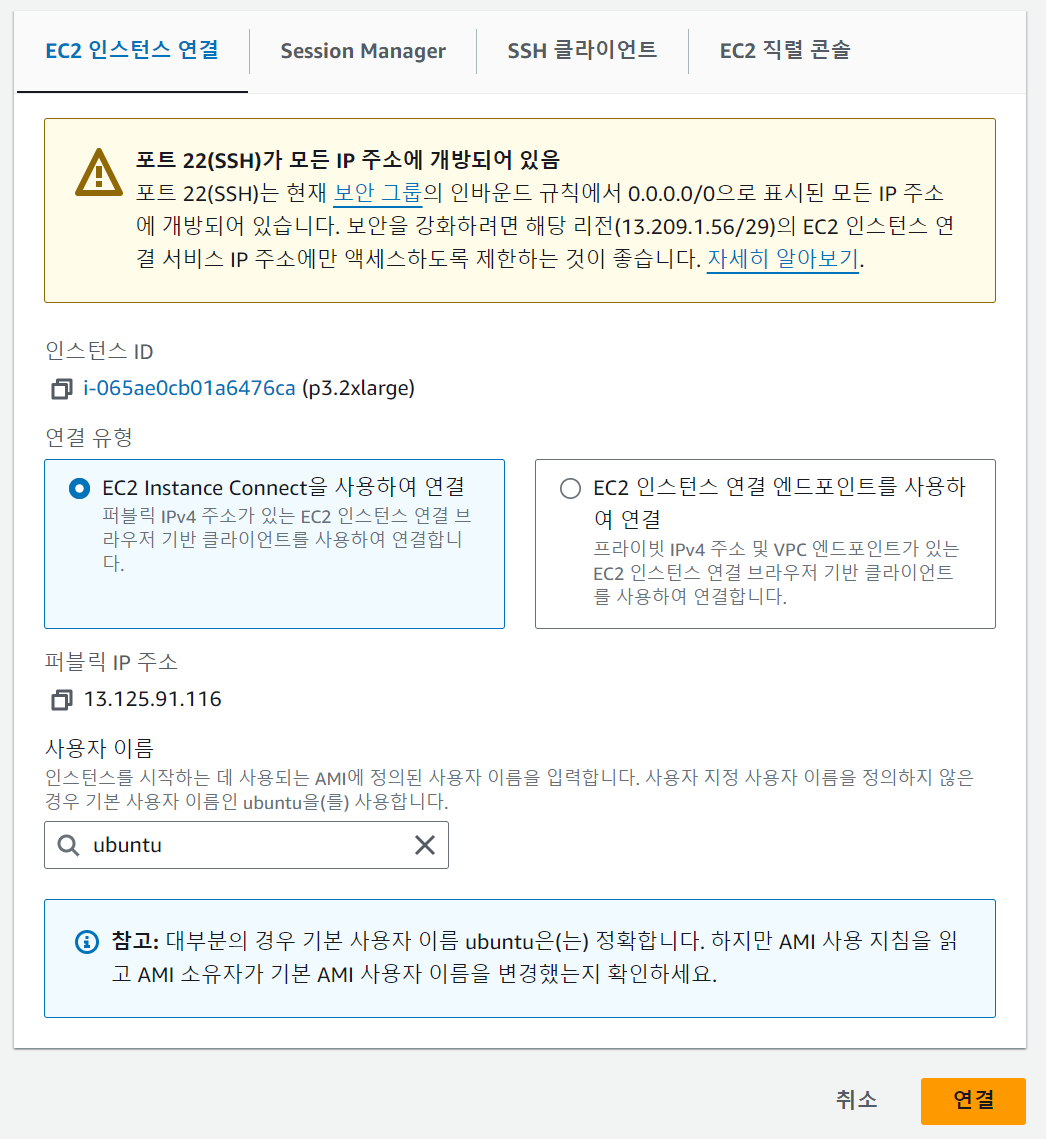
연결 버튼을 누르면 아래 화면이 새 탭에 나타난다.
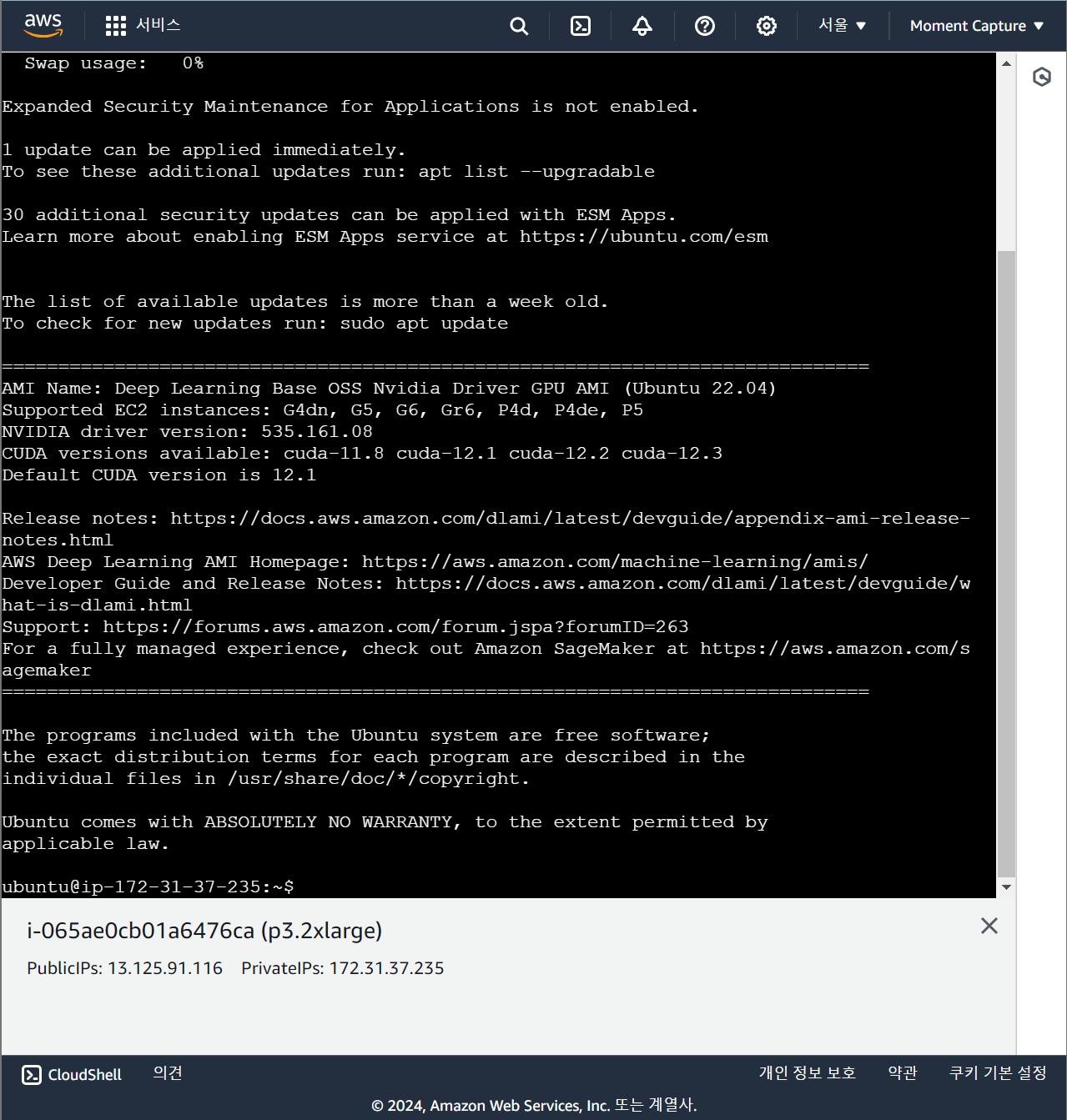
별도의 터미널을 사용하지 않고, EC2에서 제공하는 연결 화면 상에서 서버 작업을 완료할 수 있다.
단, vim을 통한 문서 작업은 화살표로 이동할 때마다 위 문장이 사라지는 등 매우 불편하므로 터미널 상 간단한 작업만 수행하는 것을 추천한다. 문서 작업을 한다면 SSH 클라이언트를 통해 cmd 창을 열어 작업하는 편이 훨씬 편하다.
2. SSH 클라이언트
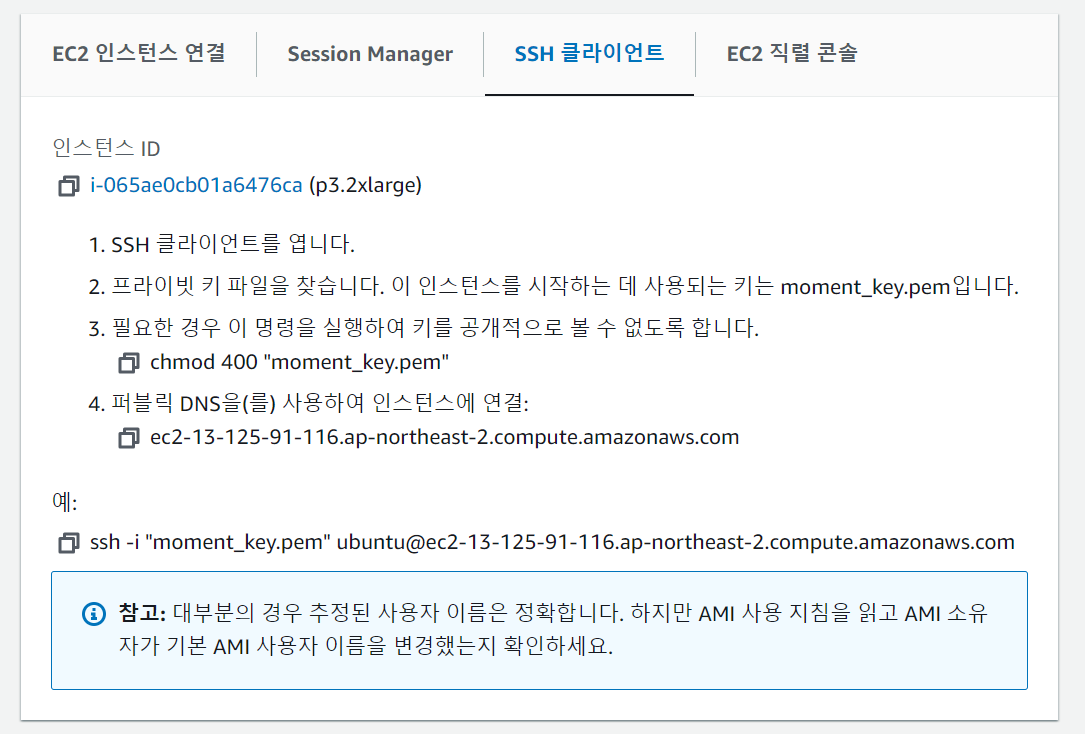
우분투나 맥 환경에서 작업 중이라면 화면에 적힌 대로 작업을 수행해 주면 된다. 하지만 chmod 명령어가 없는 윈도우 상에서는 별도의 권한 설정을 따로 해 줘야 한다. 로컬 컴퓨터의 환경이 윈도우 OS를 사용하기 때문에 아래의 절차를 따라야 했다.
ㅤ
- chmod 400
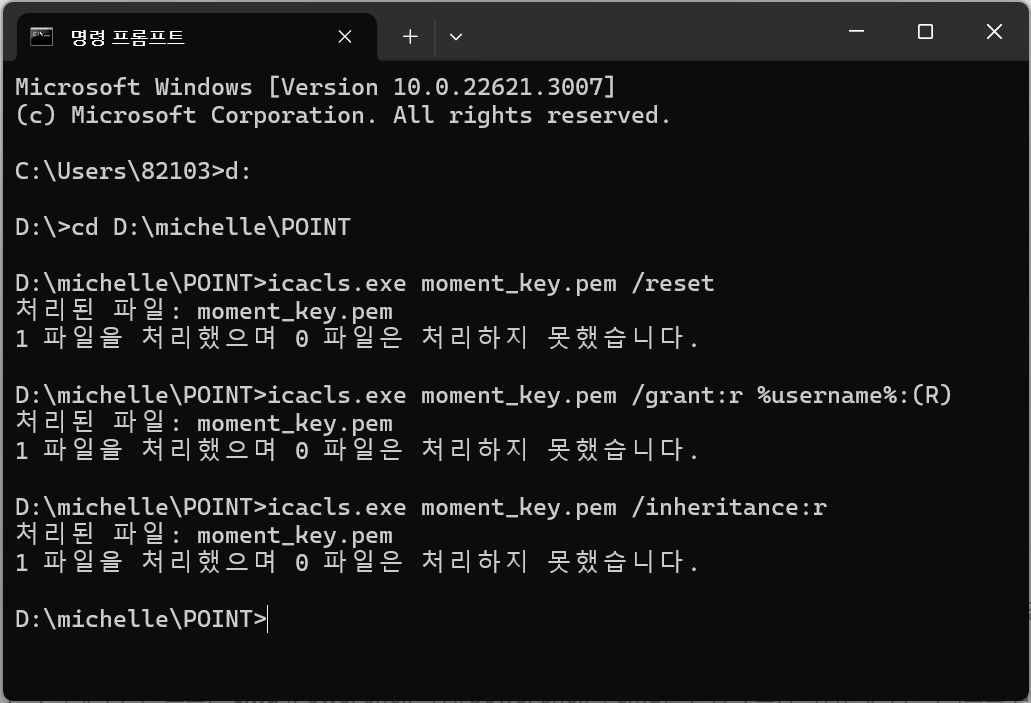
icacls.exe moment_key.pem /reset
icacls.exe moment_key.pem /grant:r %username%:(R)
icacls.exe moment_key.pem /inheritance:r.pem 파일이 존재하는 경로로 이동해서, 위 코드를 cmd 창에 입력하면 파일 권한이 400(-r--------)으로 맞춰진다. 즉, 소유자만 읽을 수 있는 파일로의 설정이 완료된다. cmd 창이 아닌 Powershell을 사용하면 작동하지 않으니 꼭 cmd 창을 사용하도록 유의해야 한다.
"moment_key.pem" 부분만 바꿔서 사용하면 된다. %username%은 건드리지 않아도 된다.
ㅤ
- ssh 접속

ssh -i "moment_key.pem" ubuntu@ec2-13-125-91-116.ap-northeast-2.compute.amazonaws.com위 코드를 입력하면 연결을 진행하겠느냐는 질문이 나오는데, 여기에 yes를 입력하면 연결에 성공한다.
ㅤ
- 가상 환경 접속

해당 화면은 가상 환경 접속 완료 시 cmd 창에 나타날 화면이다. cmd 창에서 원격으로 접속해 서버 구축 작업을 진행할 수 있다. 해당 프로젝트를 만들 때 GitHub를 사용해서 작업하고, 서버에서 pull 하는 형태로 구축 작업을 진행했다. GitHub를 사용해서 진행한 작업은 아래에서 따로 분리해 설명하겠다.
ㅤ
할당량 요청
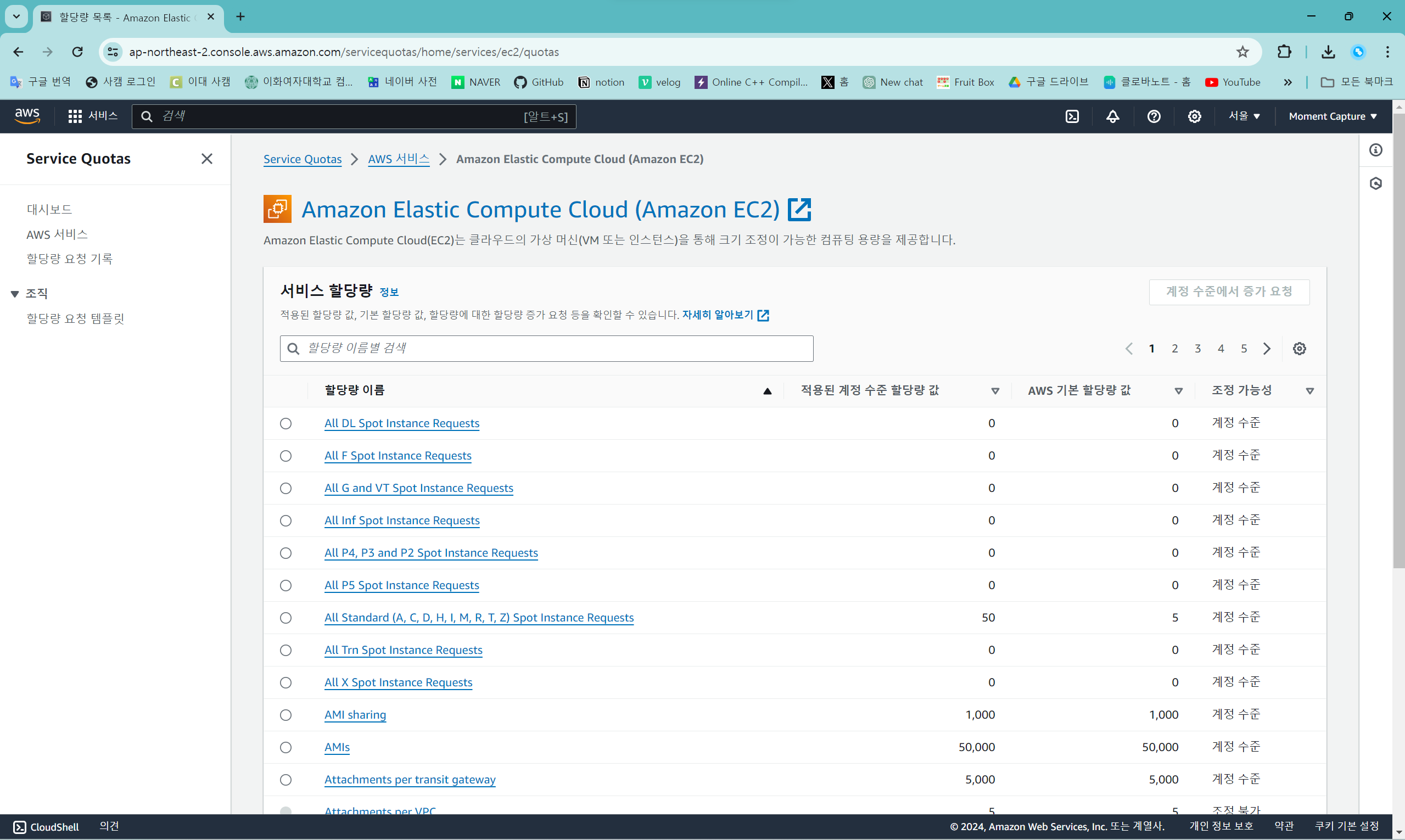
할당량 요청 화면: https://console.aws.amazon.com/servicequotas/home/services/ec2/quotas
할당량 요청 화면에 들어가면 여러 선택지가 나오는데, 각 인스턴스 유형에 맞는 자원을 검색해서 받아야 인스턴스 생성이 가능할 것이다.
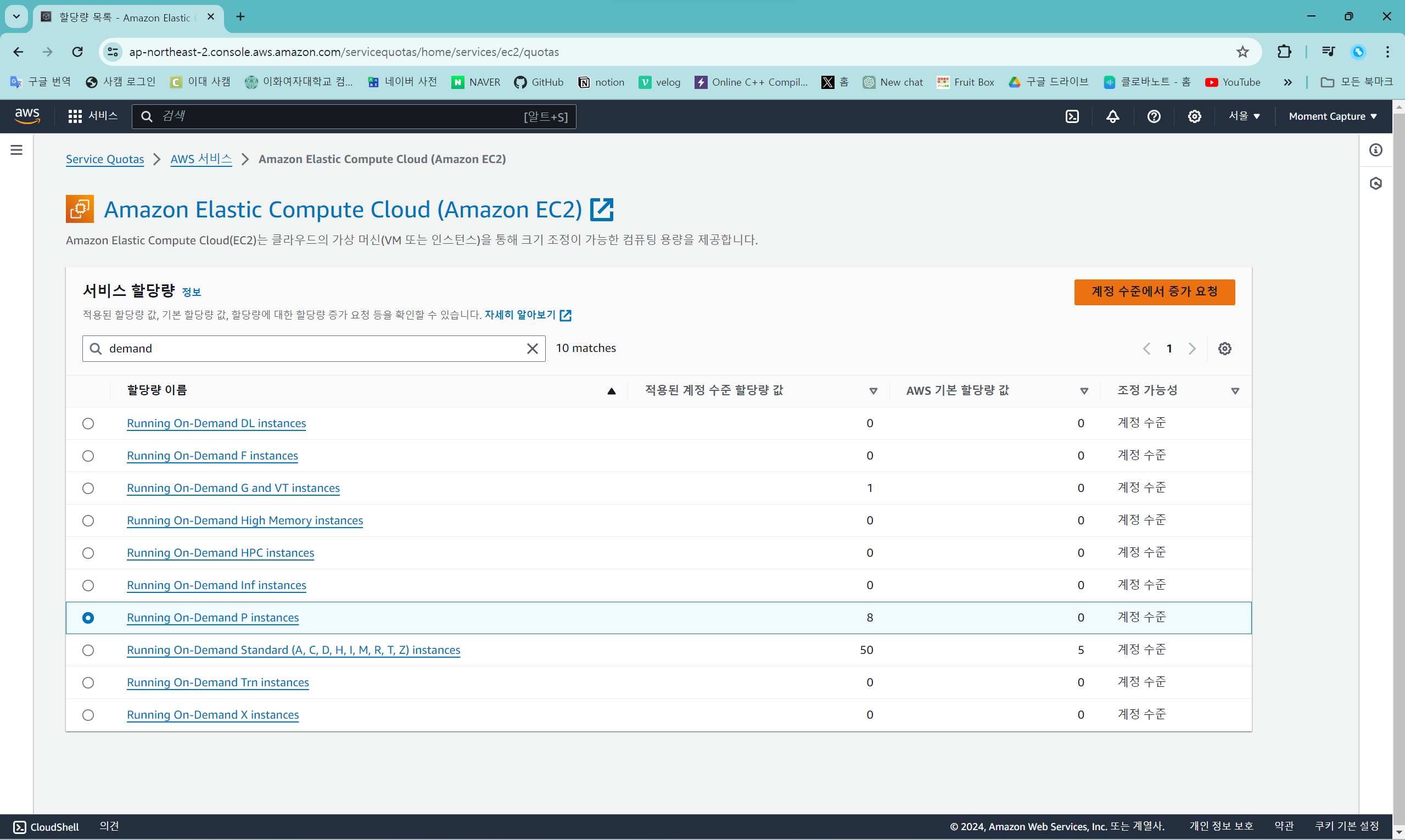
검색 창에 "demand"를 검색하면 해당하는 할당량 리스트가 보이는데, 여기에서 "Running On-Demand P instances"를 선택하고 "계정 수준에서 증가 요청" 버튼을 누른다.
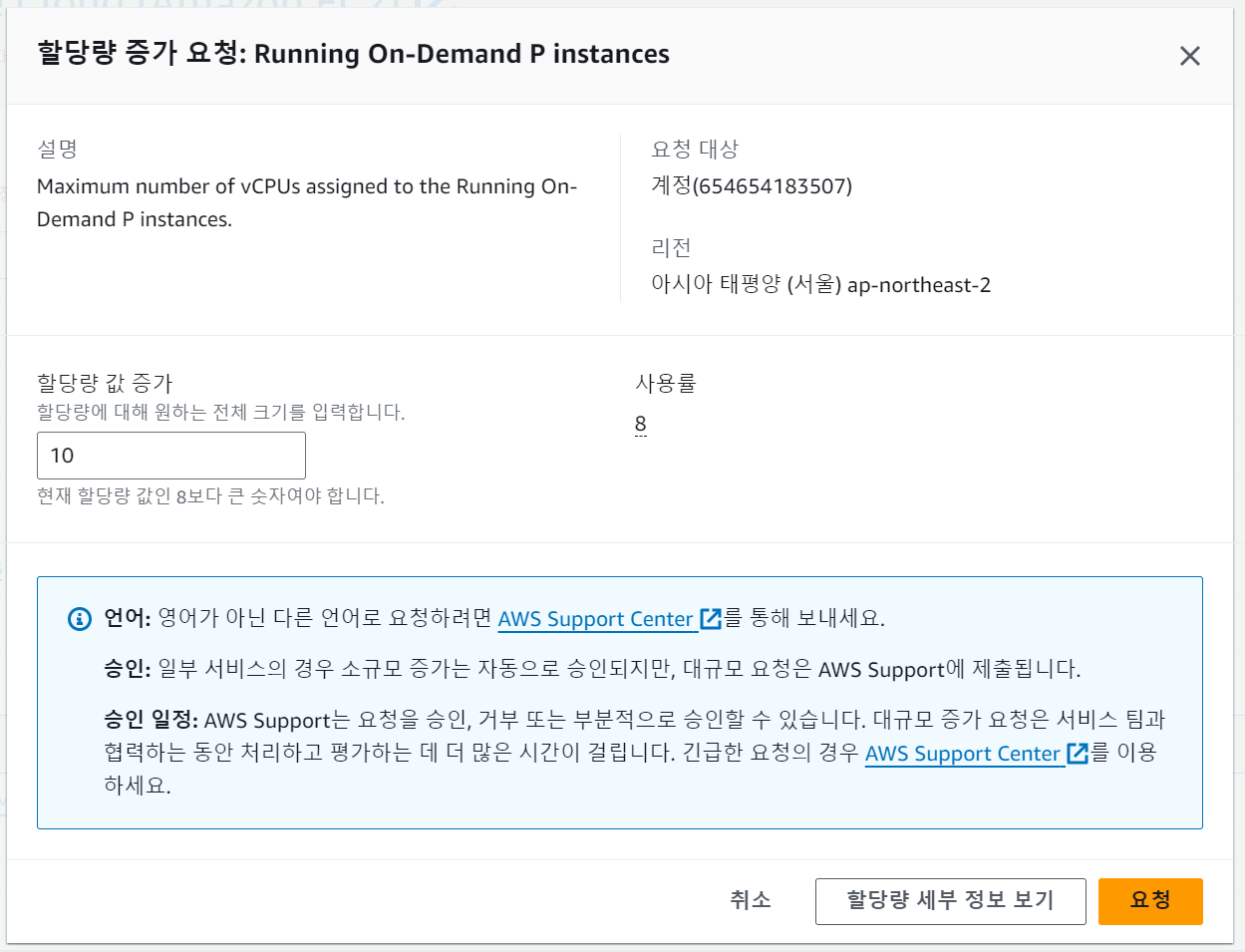
원하는 전체 할당량 크기를 "할당량 값 증가"에 적으면 요청한 만큼 크기를 늘려 준다. 요청 버튼을 누르면 할당량 증거 요청이 접수된다.
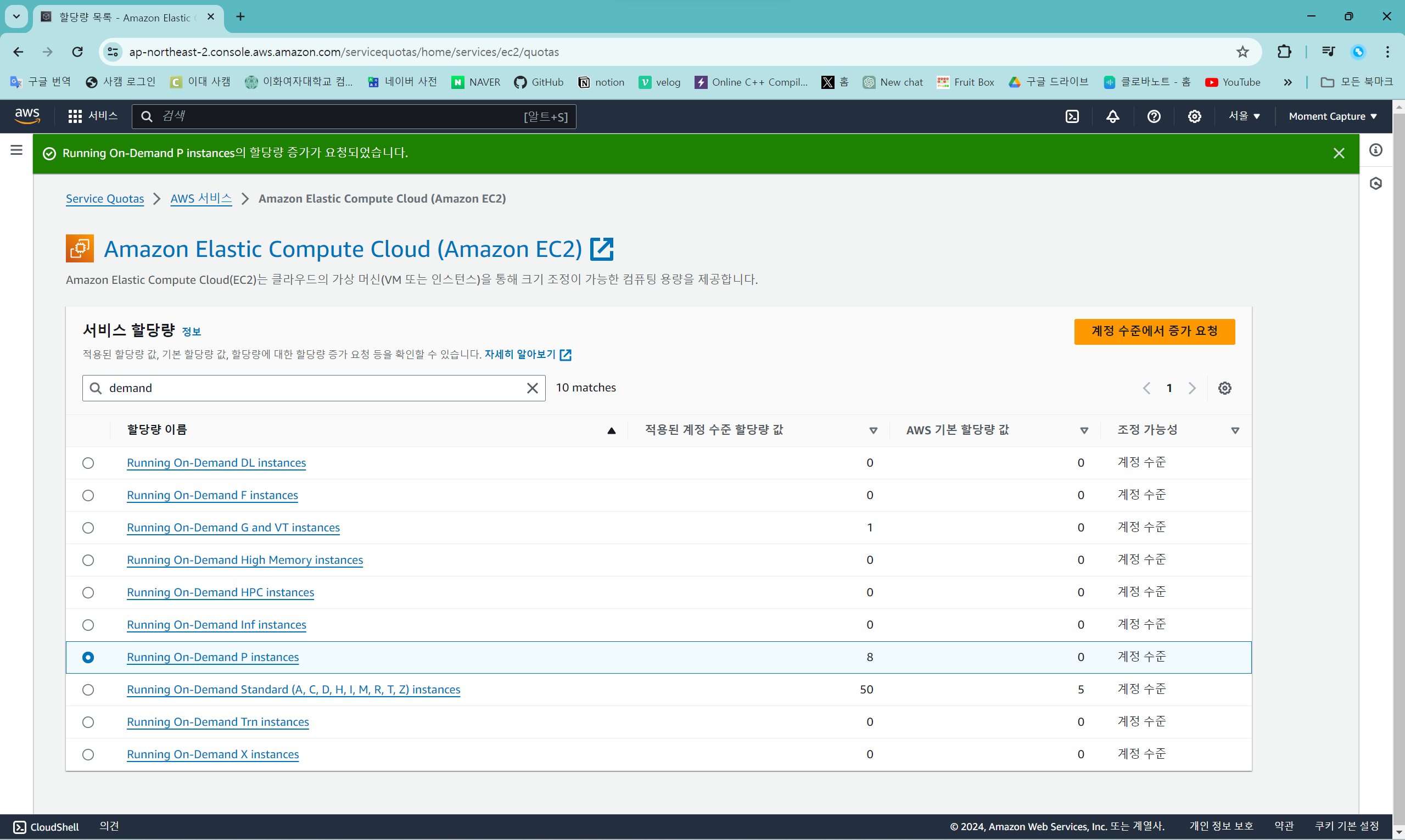
Standard (A, C, D, H, I, M, R, T, Z) 인스턴스는 증가 요청이 빠르게 접수되고 빠르게 반영된다.
하지만 P나 G and VT 인스턴스는 바로 반영이 되지 않고 시간이 하루 정도 소요된다.
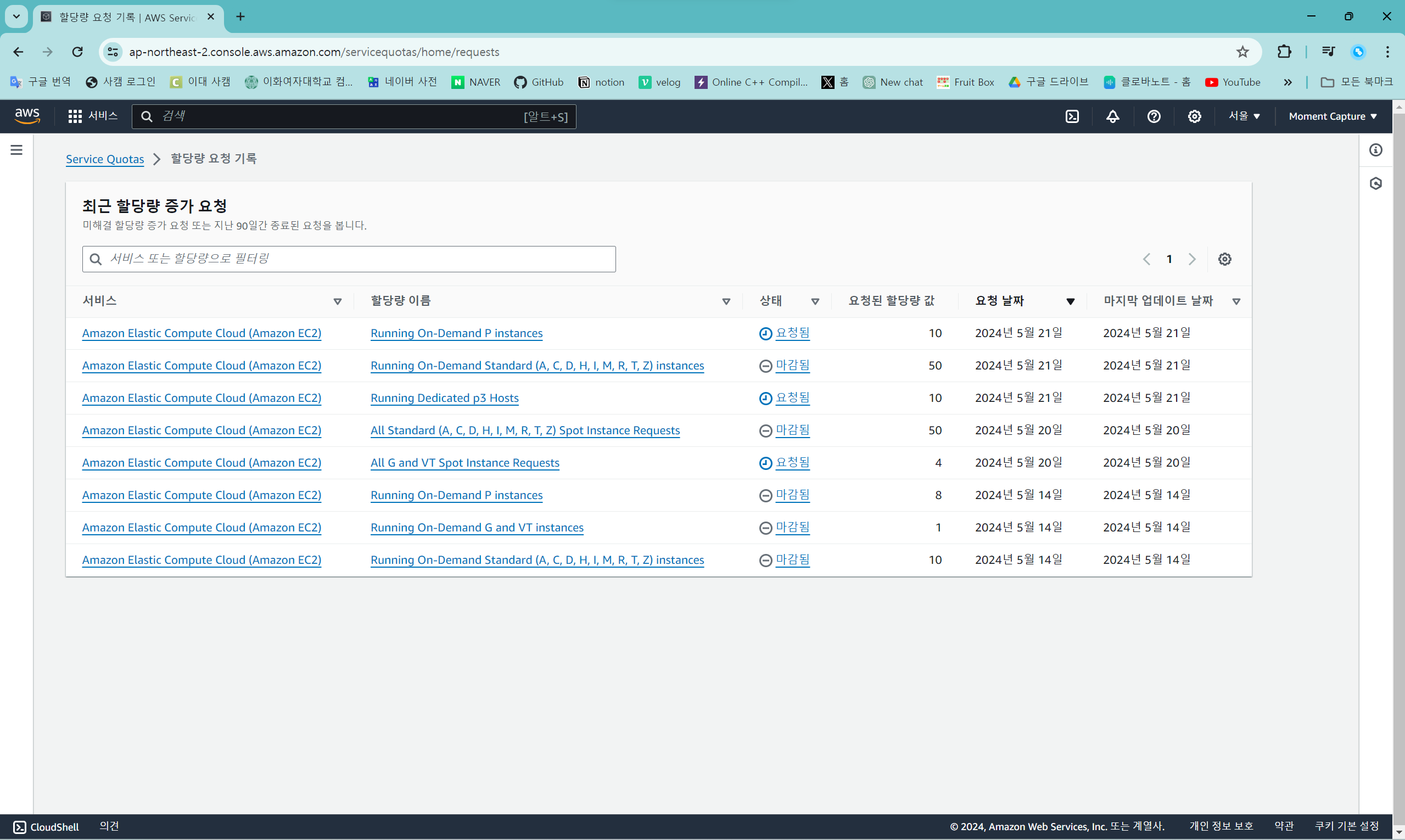
할당량 요청 기록 화면: https://console.aws.amazon.com/servicequotas/home/requests
할당량 증가 요청 목록을 보고 싶으면 "할당량 요청 기록"에서 확인하면 된다.
ㅤ
ㅤ
GitHub
작업을 로컬 컴퓨터로 하고, GitHub에 작업 파일을 올려 서버에서는 git clone을 통해 파일을 받는 방식으로 서버 환경을 운영한다. 이때, 해당 프로젝트는 private repository이기 때문에 키를 발급하고 해당 키를 통해 리포지토리에 접근하는 일련의 과정이 필요했다. 이때 배포 키를 사용해서 접근했는데, 배포 키 사용 방법은 GitHub에서 제공하는 "배포 키 관리" 설명을 참고로 했다.
배포 키 관리 문서: https://docs.github.com/ko/authentication/connecting-to-github-with-ssh/managing-deploy-keys#deploy-keys
ssh 키 발급
"새 SSH 키 생성 및 ssh-agent에 추가" 설명을 참고로 했다.
새 SSH 키 생성 및 ssh-agent에 추가 문서: https://docs.github.com/ko/authentication/connecting-to-github-with-ssh/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent#generating-a-new-ssh-key
ssh 키 생성
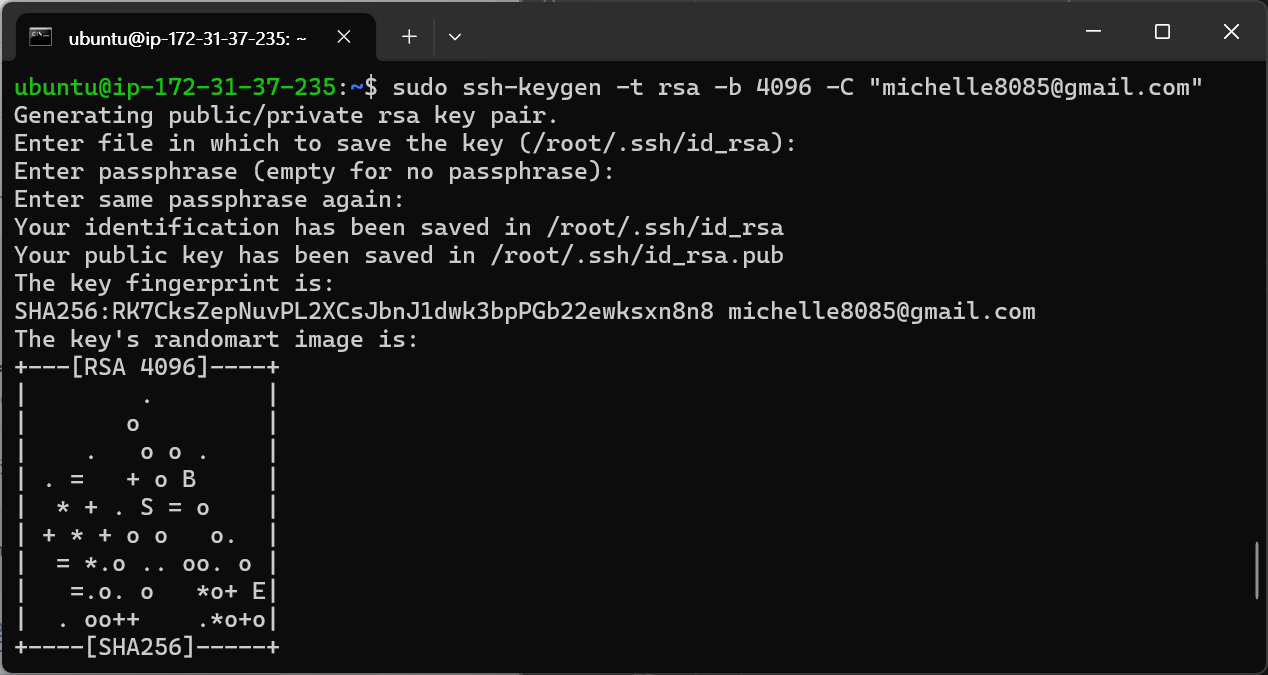
sudo ssh-keygen -t rsa -b 4096 -C "michelle8085@gmail.com"위 코드를 통해 ssh 키를 만든다. rsa 방식을 사용했다. "" 안에 본인의 GitHub 가입 메일을 적으면 된다.
코드를 입력하면 ssh 키 저장 장소에 대한 확인을 요구하는데 엔터를 누르면 되고, 키 접근을 위한 비밀번호 설정을 요구하는데 비밀번호를 입력하면 된다.
현재 ssh 키는 /root/.ssh 디렉터리에 저장되어 있고, 같은 디렉터리에 퍼블릭 키도 함께 저장되어 있다.
퍼블릭 키 복사
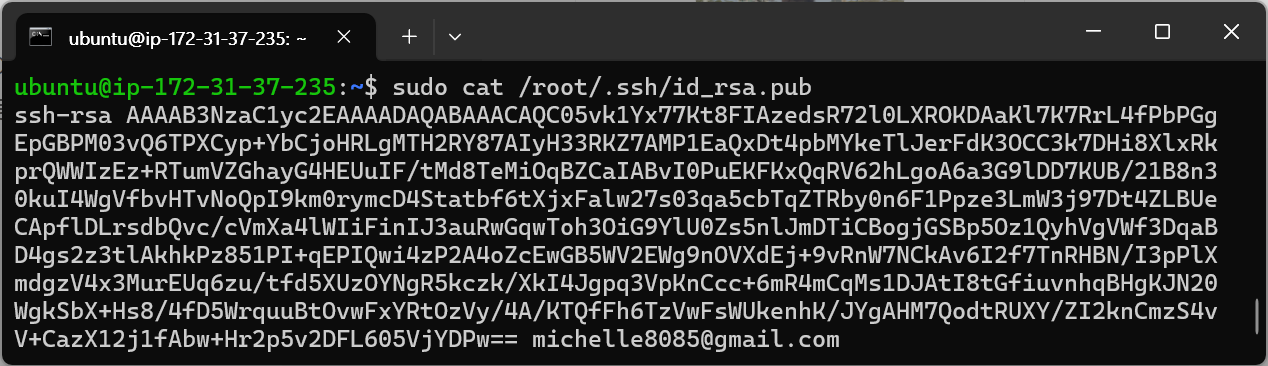
sudo cat /root/.ssh/id_rsa.pub퍼블릭 키가 /root/.ssh/id_rsa.pub에 저장되어 있음이 위에서 확인됐기 때문에, 위 코드를 통해 퍼블릭 키를 반환 받아 복사하면 된다.
배포 키 추가
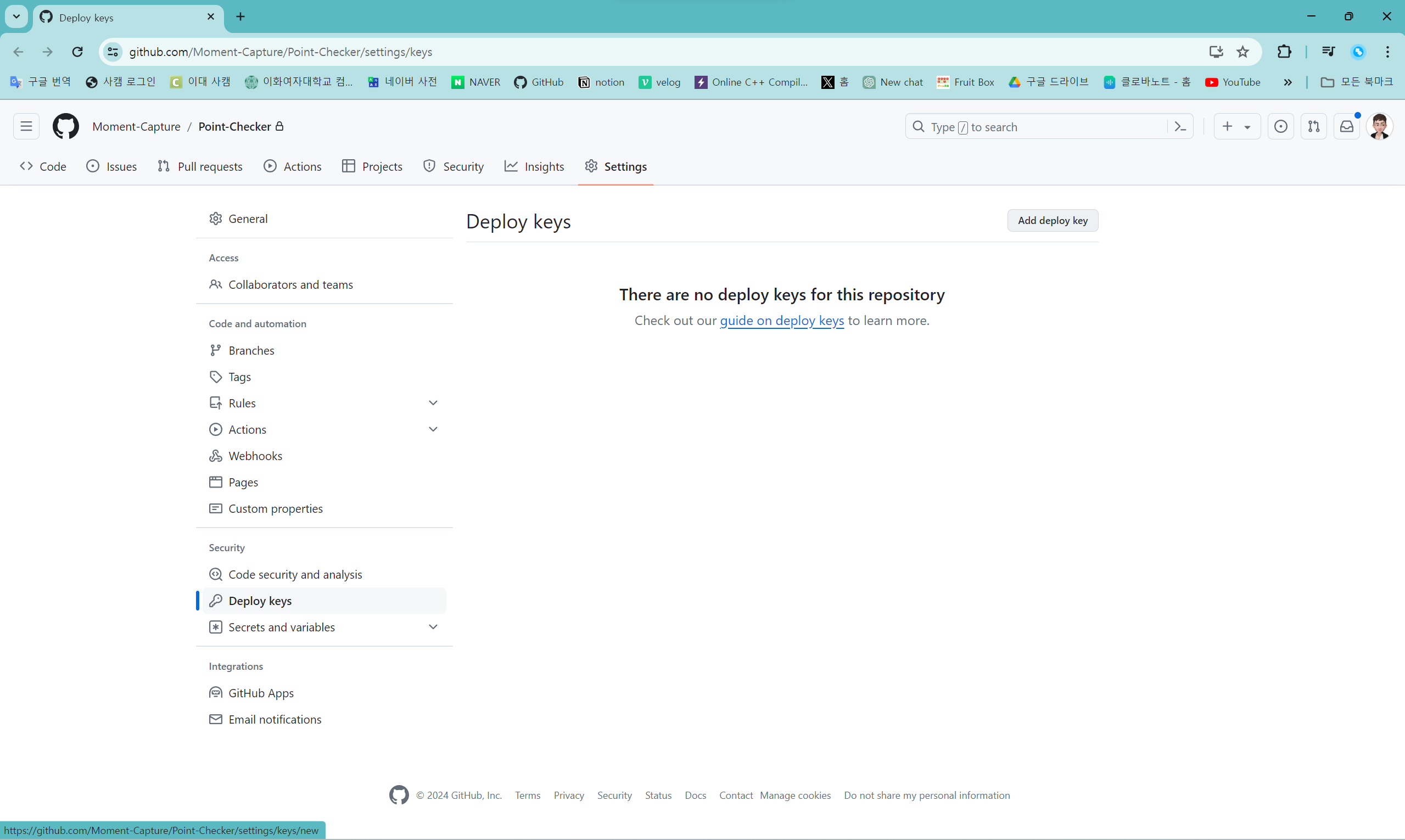
GitHub의 private repository의 "Settings"에서 "Deploy keys"를 선택하면 위와 같은 화면이 나온다. "Add deploy key" 버튼을 눌러 배포 키를 등록한다.
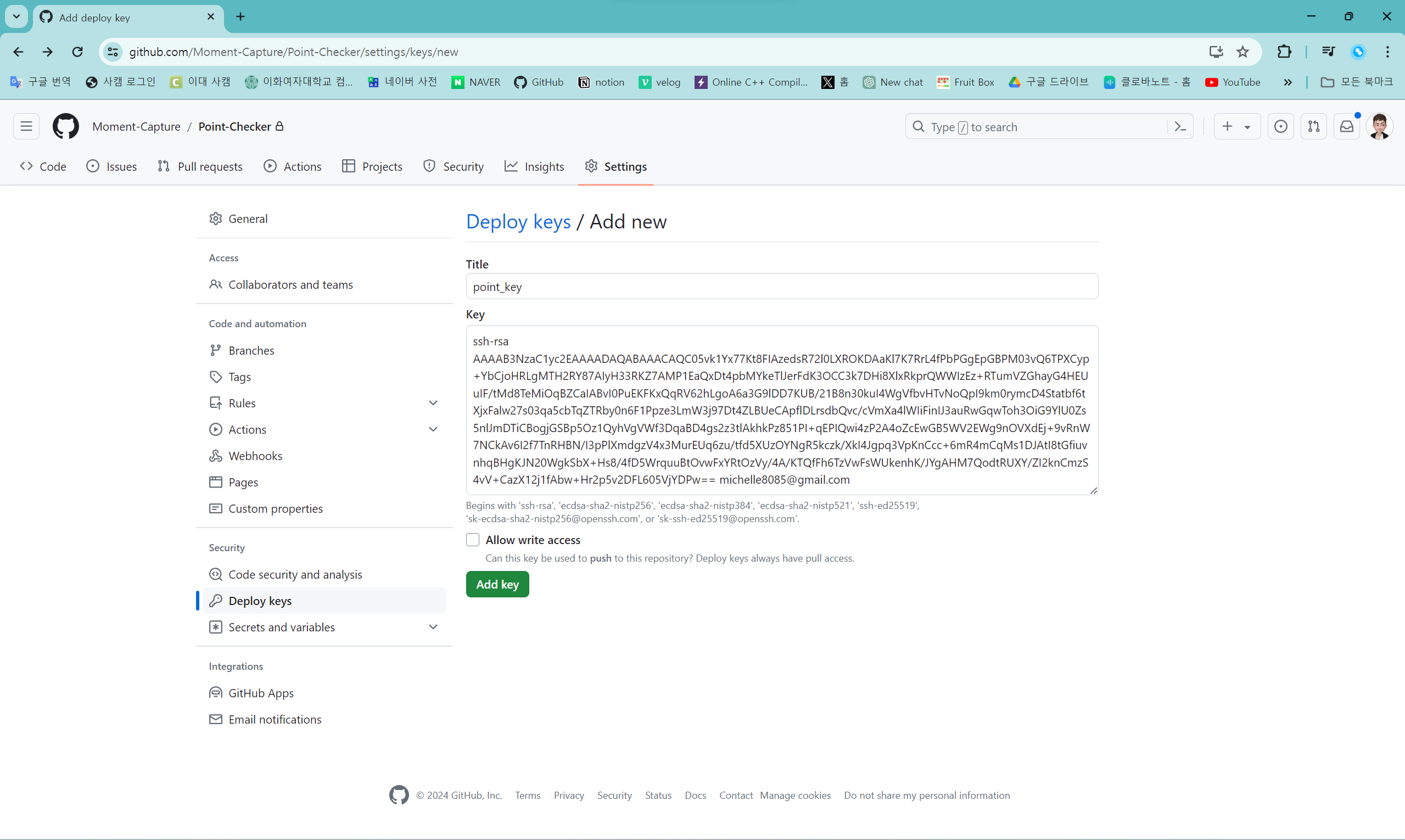
배포 키 등록 화면이다. Key에 복사한 퍼블릭 rsa 키를 붙여 넣는다.
"Allow write access"를 체크하면 push 권한을 얻게 되는데, 현재는 우선 pull만 할 것이기 때문에 체크는 안 하기로 한다.
설정이 끝나면 "Add key" 버튼을 눌러 등록을 마친다.
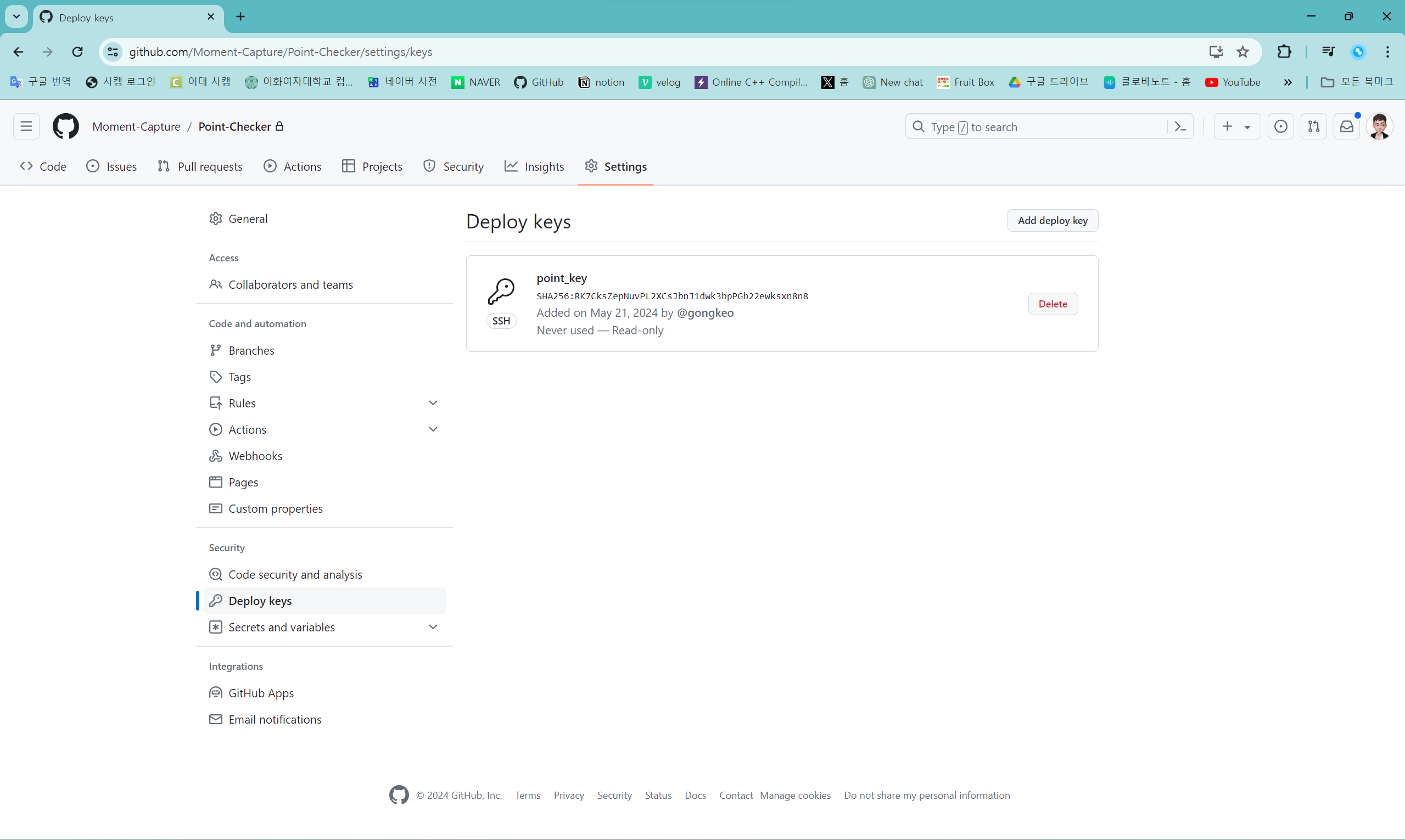
등록이 끝나면 등록한 배포 키를 "Deploy keys"에서 확인할 수 있다.
config 생성
sudo vi /root/.ssh/config.ssh 디렉터리 밑에 config를 만들어야 한다.
위 코드를 실행하면 아래와 같은 문서 창이 열린다.
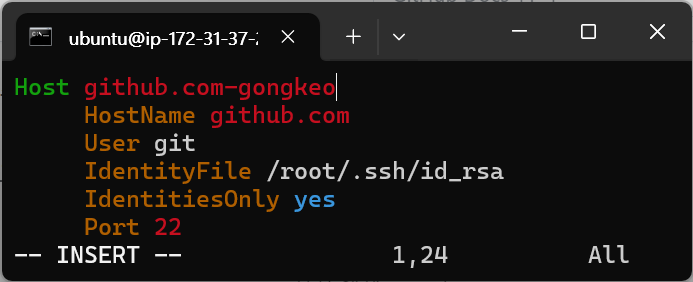
Host github.com-gongkeo
HostName github.com
User git
IdentityFile /root/.ssh/id_rsa
IdentitiesOnly yes
Port 22위의 내용을 복사해서 붙여 넣으면 된다.
"Host"는 자율로 설정해도 된다. 이 프로젝트에서는 github.com-gongkeo로 설정했다.
"IdentityFile"은 프라이빗 키 경로를 입력하면 된다. 이 프로젝트에서는 /root/.ssh/id_rsa로 설정했다.
ㅤ
git clone
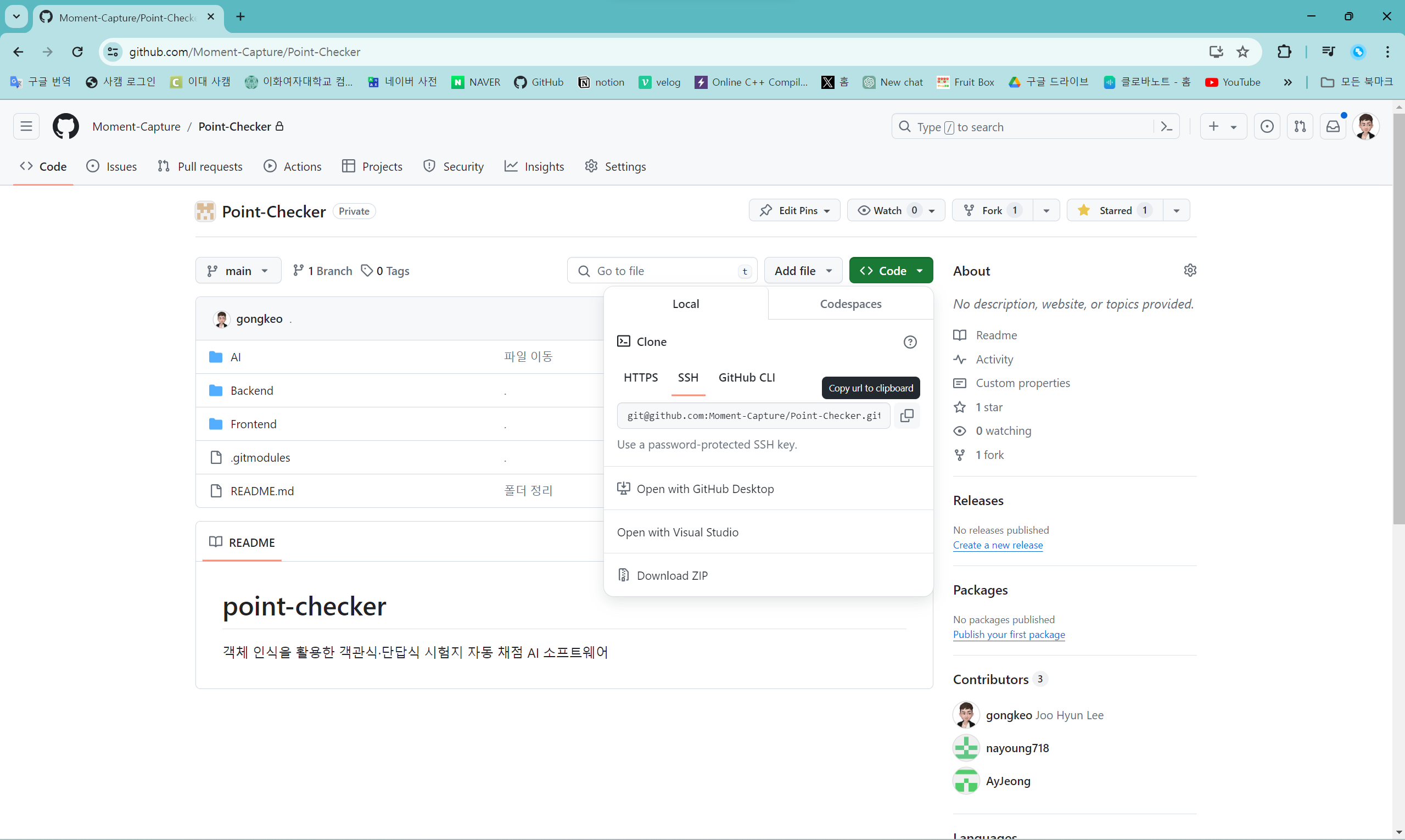
"<>Code"를 열면 나오는 창에서 "SSH"를 선택하고, 코드를 복사하면 된다. 이때, config 설정에 맞춰 복사한 코드의 변용이 필요한다.
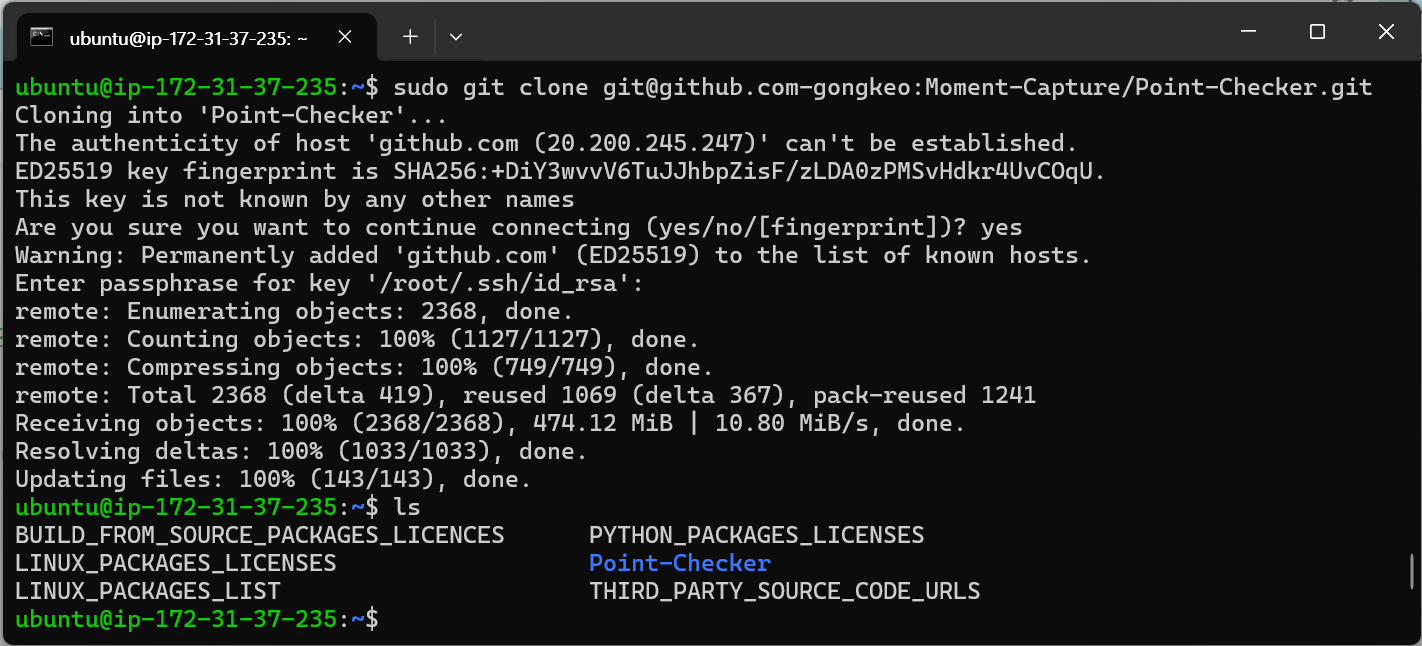
sudo git clone git@github.com-gongkeo:Moment-Capture/Point-Checker.gitsudo git clone git@<Host 이름>:<단체 이름>/<Repository 이름>.git
ssh 키 접근을 sudo 권한으로 할 수 있기 때문에, clone을 할 때 sudo 명령어를 사용해야 한다. 여기서는 "Host"를 github.com-gongkeo로 설정했으므로, <Host 이름>에 github.com-gongkeo를 입력한다.
연결을 계속하겠냐는 질문에는 yes를 입력하면 된다. 그리고 프라이빗 키 접근할 때 비밀번호를 설정했기 때문에, 비밀번호를 입력하면 접근이 완료된다. 프라이빗 리포지토리가 무사히 clone 된 것을 확인할 수 있다.
ㅤ
git pull
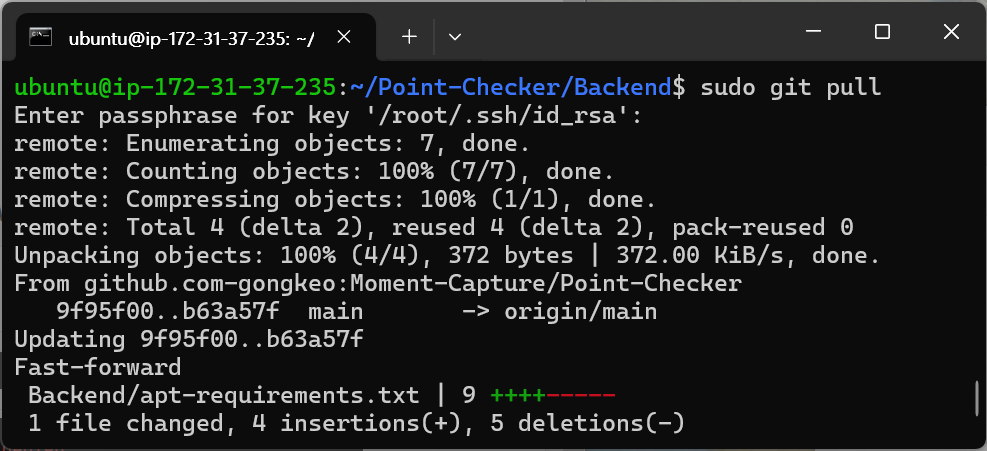
cd ~/Point-Checker/Backend
sudo git pullssh 키 접근을 sudo 권한으로 할 수 있기 때문에, pull을 할 때에도 sudo 명령어를 사용해야 한다. 또한, pull을 하며 프라이빗 키에 접근하기 때문에 설정한 프라이빗 키 비밀번호를 입력해야 해당 단계가 진행된다.
git pull이 잘 되는 것을 다 확인했다면, 위의 OCR Tamil을 /Backend/models 아래에 clone 받는 작업도 잊지 않아야 한다. OCR Tamil을 따로 clone을 해야 프로그램이 무리없이 돌아간다.
ㅤ
ㅤ
Flask
Flask 가이드: https://flask-docs-kr.readthedocs.io/ko/latest/
라이브러리 설치
sudo apt-get install python
sudo apt-get install python-pip
pip install flask
pip install requests서버에 접속해 Flask 파이썬 라이브러리를 다운 받는다.
requests 라이브러리 역시 다운 받는다.
ㅤ
클라이언트 파일 작성
import json
import requests
def server_connect(pdf_path, answer_path, test_name, copy_num, total_qna_num, testee_num, test_category):
url = "http://13.125.91.116:8080/upload"
data = {
'test_name':test_name,
'copy_num':copy_num,
'total_qna_num':total_qna_num,
'testee_num':testee_num,
'test_category':test_category
}
files = {
'pdf':open(pdf_path, "rb"),
'answer':open(answer_path, "rb"),
'data':(None, json.dumps(data), 'application/json')
}
global df
response = requests.post(url, files=files)
json_data = json.loads(response.text)
print(json_data)
df = pd.json_normalize(data)
df.drop(columns=["file"], inplace=True)
df.set_index(["testee_id", "num"], inplace=True)
print(df)
서버로 연결하는 함수를 불러 서버에 연결하고, 응답 결과를 받아 온다.
서버 연결 파트
import json
import requests
url = "http://13.125.91.116:8080/upload"
data = {
'test_name':test_name,
'copy_num':copy_num,
'total_qna_num':total_qna_num,
'testee_num':testee_num,
'test_category':test_category
}
files = {
'pdf':open(pdf_path, "rb"),
'answer':open(answer_path, "rb"),
'data':(None, json.dumps(data), 'application/json')
}
requests.post(url, files=files)url에는 EC2에서 할당받은 인스턴스의 "퍼블릭 ip 주소:포트 번호" 기반의 url 주소를 저장한다. 여기에서 P3 인스턴스의 퍼블릭 ip 주소는 13.125.91.116이고, 포트 번호는 8080이며, 업로드를 처리할 주소는 /upload이므로 http://13.125.91.116:8080/upload 형태의 주소를 저장한다.
data에는 변수 등 단순한 정보를 딕셔너리 형태로 담았다. 또한 files에는 전달된 경로에서 읽어들인 파일의 바이너리 정보와 data를 딕셔너리 형태로 담았다.
data를 file 안에 담을 때에는 헤더 정보와 함께 json으로 data를 변환한 형태로 담아야 서버 쪽에서 files와 data 구분이 가능하다.
requests.post(url, files=files) 함수를 통해 files를 지정한 주소로 post한다.
응답 결과 수신 파트
import json
import requests
import pandas as pd
response = requests.post(url, files=files)
json_data = json.loads(response.text)
df = pd.json_normalize(json_data)response에는 클라이언트에서 post하고 받은 서버 측의 응답 결과를 저장한다.
json_data에 json 형태로 로드된 response 텍스트를 저장한다.
df에 판다스의 json_normalize 함수를 이용해 json 데이터를 데이터프레임 형태로 바꿔 저장한다.
ㅤ
서버 파일 작성
from flask import Flask, request, redirect, url_for
app = Flask(__name__)
@app.route("/upload", methods=["POST"])
def upload_files():
if request.method == "POST":
files = request.files
pdf = files["pdf"]
answer = files["answer"]
datas = request.form
data = datas.get("data")
data = json.loads(data)
test_name = data["test_name"]
copy_num = data["copy_num"]
total_qna_num = data["total_qna_num"]
testee_num = data["testee_num"]
test_category = data["test_category"]
return redirect(url_for("plural_check",
id=id,
test_name=test_name,
copy_num=copy_num,
total_qna_num=total_qna_num,
testee_num=testee_num,
test_category=test_category))
@app.route("/plural", methods=["GET"])
def plural_check():
id = request.args.get("id", type=str)
test_name = request.args.get("test_name", type=int)
copy_num = request.args.get("copy_num", type=int)
total_qna_num = request.args.get("total_qna_num", type=int)
testee_num = request.args.get("testee_num", type=int)
test_category = request.args.getlist("test_category")
id_path = UPLOAD_FOLDER + "/" + id
df = pd.DataFrame()
df = pointchecker(id_path, test_name, copy_num, total_qna_num, testee_num, test_category)
if len(df) == 0:
return "Error Occured", 200
json_data = df.to_json(orient="records")
return json_data, 200
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080)
서버의 app.py에서 클라이언트의 파일을 처리하고 결과를 내보내는데, 크게 수신 파트와 처리 파트로 나눠져 있다.
클라이언트 수신 파트
from flask import Flask, request, redirect, url_for
app = Flask(__name__)
@app.route("/upload", methods=["POST"])
def upload_files():
if request.method == "POST":
files = request.files
pdf = files["pdf"]
answer = files["answer"]
datas = request.form
data = datas.get("data")
data = json.loads(data)
test_name = data["test_name"]
copy_num = data["copy_num"]
total_qna_num = data["total_qna_num"]
testee_num = data["testee_num"]
test_category = data["test_category"]
return redirect(url_for("plural_check",
id=id,
test_name=test_name,
copy_num=copy_num,
total_qna_num=total_qna_num,
testee_num=testee_num,
test_category=test_category))
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080)
기본적으로 코드는 app = Flask(__name__)으로 시작하고, app.run(host="0.0.0.0", port=8080)으로 끝난다. run 함수로 host의 브로드캐스트 주소를 설정해 모든 호스트의 접속을 허용하고, 포트 번호는 8080으로 지정한다. 이는 위의 EC2 인스턴스의 보안 인바운드 규칙 설정과 연관된다. 허용하는 호스트의 범위와 포트 번호가 바뀌면, 인스턴스의 인바운드 규칙도 바꿔야 한다.
@app.route("/upload", methods=["POST"])으로 업로드 url을 지정하는데, 클라이언트에서 접속하는 http://13.125.91.116:8080/upload 주소가 바로 이 함수에서 지정된다. 접속 형태가 POST일 때만 반응하도록 methods에는 POST만 리스트에 추가해 둔다.
지정한 주소 밑에는 꼭 주소에서 불러올 함수를 설정해야 하는데, 이 경우에는 upload_files()이다. 함수 이름은 중복될 수 없다.
클라이언트에서 전송한 모든 정보는 "request" 안에 저장된다.
request.method는 클라이언트의 전송 형식을 담고 있다.
request.files는 클라이언트의 읽은 파일을 담고 있는데, 위에서 requests.post(url, files=files)로 보냈을 때 "files" 담긴 파일 정보를 말한다. files 딕셔너리로 "pdf", "answer" 등 읽어들인 파일의 접근이 가능하다.
request.form에는 클라이언트에서 전송한 "files" 하위에 저장한 "data"의 정보가 담겨 있다. 읽어들인 파일 정보와 data로 저장한 변수 정보를 서버에서 꺼내는 방식이 다르다는 것을 기억해야 한다. get 함수를 통해 form 안의 "data"로 저장된 정보를 꺼내면 json 형태의 정보가 얻어진다. 이는 클라이언트에서 전송할 때 data를 json.dumps(data)로 json화 했기 때문이다. 따라서 json을 딕셔너리로 로드하기 위해서 json.loads(data) 함수를 사용해야 한다. 이후, 딕셔너리 인덱싱을 통해 각 변수 정보에 접근한다.
redirect 함수를 통해 처리 파트 주소로 이동하는데, url_for 함수를 사용하면 수신 파일 처리 함수를 인자와 함께 호출이 가능하다. 이 경우 @app.route("/plural", methods=["GET"]) 밑에 바로 선언된 plural_check를 부르는 경우다. 정보 처리에 필요한 변수들을 request 파라미터에 담아 넘긴다. 즉, url_for("부르는 함수 이름", 인자1=변수1, 인자2=변수2, ...) 형태로 사용하고 return redirect를 하면 해당 주소로 이동이 가능하다.
수신 파일 처리 파트
@app.route("/plural", methods=["GET"])
def plural_check():
id = request.args.get("id", type=str)
test_name = request.args.get("test_name", type=int)
copy_num = request.args.get("copy_num", type=int)
total_qna_num = request.args.get("total_qna_num", type=int)
testee_num = request.args.get("testee_num", type=int)
test_category = request.args.getlist("test_category")
id_path = UPLOAD_FOLDER + "/" + id
df = pd.DataFrame()
df = pointchecker(id_path, test_name, copy_num, total_qna_num, testee_num, test_category)
if len(df) == 0:
return "Error Occured", 200
json_data = df.to_json(orient="records")
return json_data, 200requests.args.get() 함수로 인자를 받을 수 있다. get() 함수를 사용할 때는, 앞에 인자의 이름을 적고 뒤에는 인자의 타입을 입력한다. 만약 인자가 list인 경우, getlist() 함수를 사용한다.
함수 정보를 전달하는 주소 형태는 다음과 같다.
/plural?id="아이디"&test_name="시험명"©_num="1부당 매수"&total_qna_num="총 문항 수"&testee_num="응시자 수"&test_category="객관식 존재"&test_category="단답식 존재"
/plural?id=222.110.177.85_2024-05-21_13-25-08&test_name=1©_num=12&total_qna_num=30&testee_num=2&test_category=1&test_category=1df에 pointchecker() 함수의 결과를 저장한다.
만약 df의 길이가 0이면 에러가 난 것으로 간주하여 Error Occured라는 메시지와 함께 response 상태를 반환한다.
만약 정상적으로 함수가 실행했다면 df의 길이가 0이 아닐 것이므로, df의 정보를 to_json() 함수를 사용해 json으로 바꾸고, 해당 json 정보를 response 상태와 함께 반환한다.
ㅤ
서버 파일 실행
cd ~/Point-Checker/Backend
python3 app.py서버 파일을 실행하면, 서버가 열린다. 지정된 url과 포트를 통해 데이터 통신이 가능해진다.
ㅤ
ㅤ
ㅤ
배포 파일 만들기
pyinstaller
Pyinstaller 매뉴얼: https://pyinstaller.org/en/stable/
라이브러리 설치
pip install pyinstaller배포 파일 만들기
서버 .exe 파일


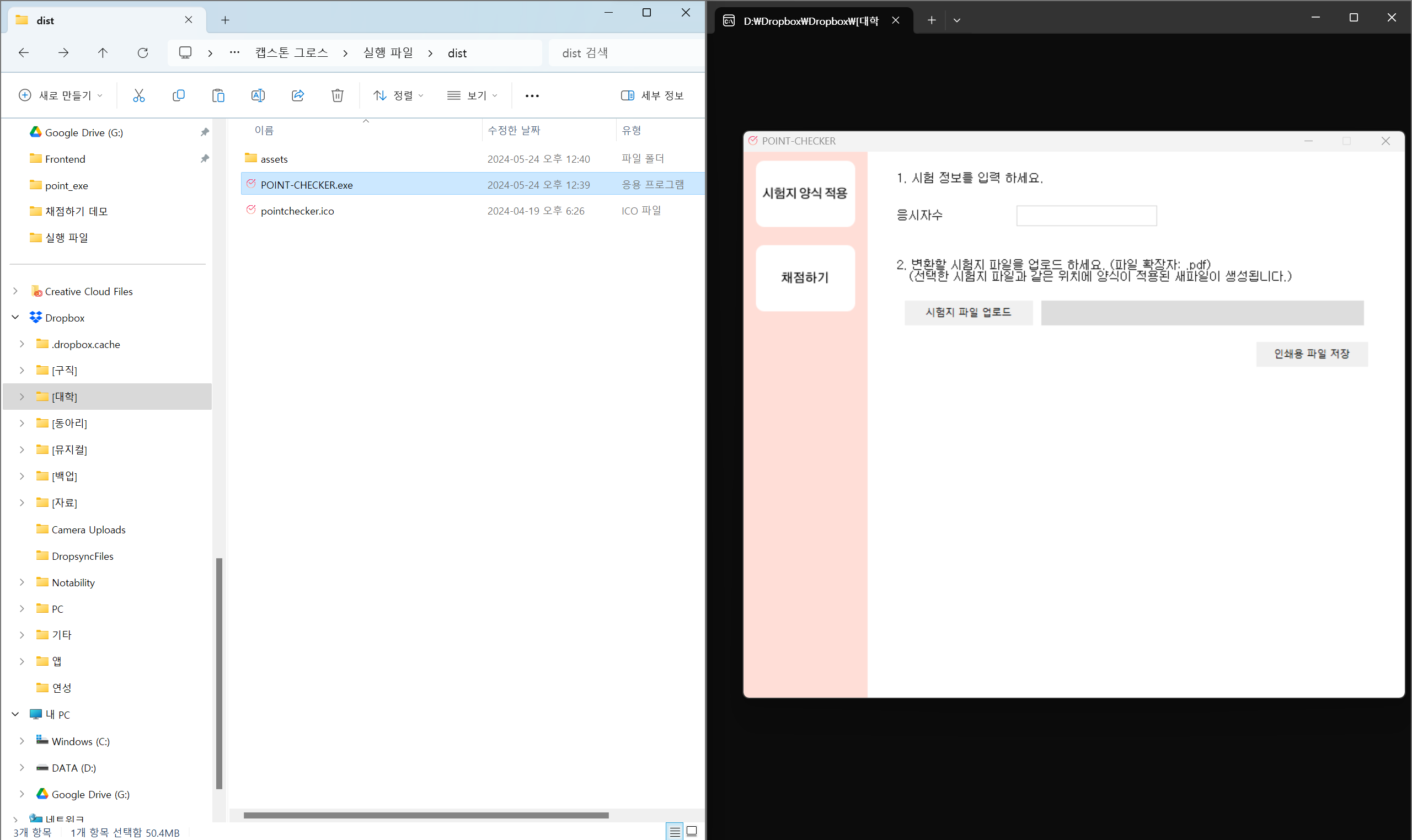
cd D:\Dropbox\Dropbox\[대학]\졸업 프로젝트\캡스톤 그로스\실행 파일
pyinstaller -F main.py -n POINT-CHECKER -i pointchecker.ico배포하고자 하는 파일이 있는 경로로 이동해 pyinstaller로 파일을 묶는다.
처음에는 "assets" 폴더, "pointchecker.ico", "main.py"가 있었다. 실행 후 "build" 폴더, "dist" 폴더, "POINT-CHECKER.spec"가 생겼다. "dist" 폴더에 들어가면, "POINT-CHECKER.exe"가 있는 것을 확인할 수 있다. "POINT-CHECKER.exe"를 실행할 때에는 반드시 해당 .exe 파일이 있는 경로에 "assets" 폴더와 "pointchecker.ico"가 있어야 한다.
코드에 대한 간단한 설명을 하자면, pyinstaller는 기본적으로 python으로 실행하고자 하는 .py 파일을 필요한 라이브러리가 포함된 .exe 파일로 압축을 해 준다. 압축 시 몇 가지 옵션을 지정할 수 있다. -F의 경우 한 .exe 파일로 묶으라고 지정하는 것이다. -n은 결과물인 .exe 파일의 이름을 지정하는 것이고, -i는 아이콘 파일을 지정하는 것이다.
cpu .exe 파일
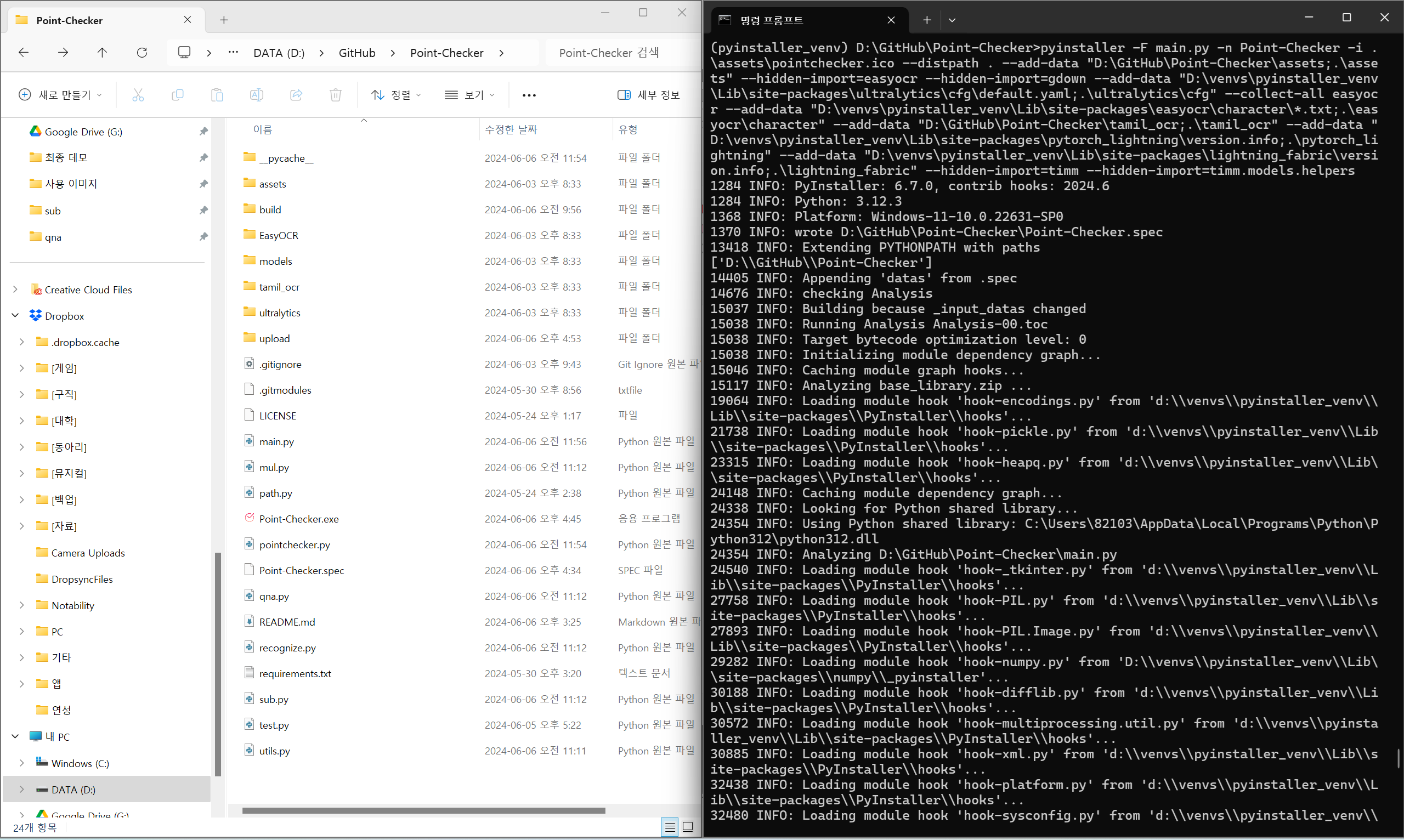
cd D:\GitHub\Point-Checker
pyinstaller -F main.py -n Point-Checker -i .\assets\pointchecker.ico --distpath . --add-data "D:\GitHub\Point-Checker\assets;.\assets" --hidden-import=easyocr --hidden-import=gdown --add-data "D:\venvs\pyinstaller_venv\Lib\site-packages\ultralytics\cfg\default.yaml;.\ultralytics\cfg" --collect-all easyocr --add-data "D:\venvs\pyinstaller_venv\Lib\site-packages\easyocr\character\*.txt;.\easyocr\character" --add-data "D:\GitHub\Point-Checker\tamil_ocr;.\tamil_ocr" --add-data "D:\venvs\pyinstaller_venv\Lib\site-packages\pytorch_lightning\version.info;.\pytorch_lightning" --add-data "D:\venvs\pyinstaller_venv\Lib\site-packages\lightning_fabric\version.info;.\lightning_fabric" --hidden-import=timm --hidden-import=timm.models.helperscpu에서만 실행되는 버전을 만들었는데, 정말... 힘들었다.
ㅤ
오류 상황
일단 말썽을 일으킨 라이브러리가 크게 세 가지 있었는데, 전부 객체인식과 OCR에 관련된 라이브러리다.
1) ultralytics
이 라이브러리는 ultralytics\cfg\default.yaml이 빠져 있어서 오류를 일으켰다.
2) easyocr
이 라이브러리는 easyocr\character*.txt가 빠져 있어서 오류를 일으켰다.
3) tamil_ocr
이 라이브러리는 pytorch_lightning\version.info, lightning_fabric\version.info, timm, timm.models.helpers가 빠져 있어서 오류를 일으켰다.
3번이 제일 말썽이었다. 아무래도 pip로 install하는 라이브러리가 아니라, github에서 끌어다 쓰는 형식이라 이래저래 엉켰던 것 같다.
ㅤ
해결 방법
오류 해결하는 방법은 간단한데, 단순하게 빠진 것들을 --add-data와 --hidden-import를 사용해서 넣어 주면 된다. .exe 내에 라이브러리를 만들어 저장하는 구조이기 때문에, 가상환경 혹은 로컬 환경에 설치된 Lib 구조를 그대로 복사해오는 느낌이다.
1) --add-data
--add-data "D:\venvs\pyinstaller_venv\Lib\site-packages\ultralytics\cfg\default.yaml;.\ultralytics\cfg"위와 같이 cfg 밑에 빠진 파일이라면, destination을 .\ultralytics\cfg로 지정해 주면 된다.
2) --hidden-import
--hidden-import=timm.models.helpersNo Module 에러가 나면 그냥 없다는 모듈 그대로 저렇게 붙여 넣으면 알아서 포함이 된다. 이 프로젝트 묶을 때 timm을 먼저 추가했는데도 timm 하위의 모듈이 없다는 오류가 떴었다... 반신반의하면서 추가했는데 오류가 고쳐진 것으로 보아 pyinstaller가 묶을 때 간혹 실수하는 모양이다.
ㅤ
ㅤ
ㅤ
프로그램 실행
실행 방법
1. 서버 환경 구축
인스턴스 생성
"백엔드 서버 구축"의 "AWS EC2" 파트를 참고해서 인스턴스 생성을 마친다.
인스턴스 연결
"백엔드 서버 구축"의 "AWS EC2" 파트틀 참고해서 인스턴스 연결을 진행한다.
아래는 간략하게 연결 과정을 기술한 것이다.
ㅤ
경로 이동
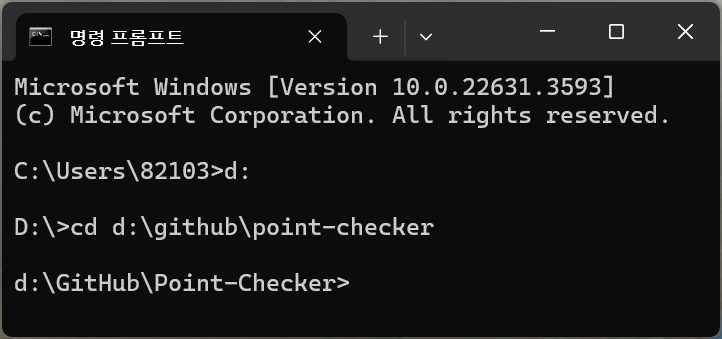
먼저 프라이빗 키(.pem)가 있는 경로로 이동한다.
d:
cd d:\github\point-checkerㅤ
키 권한 설정
만약 프라이빗 키(.pem)의 권한 설정이 400(owner read only)이 아니라면 아래 코드를 사용해 권한 변경을 완료한다. cmd에서만 사용이 가능한 코드이니 주의하라.
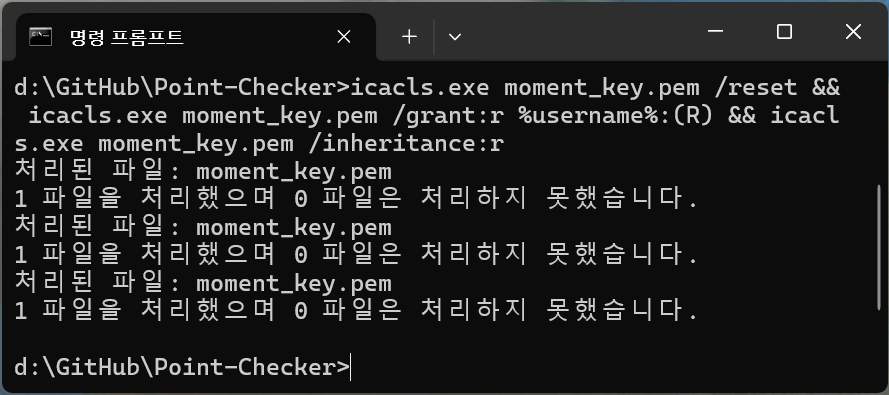
icacls.exe moment_key.pem /reset && icacls.exe moment_key.pem /grant:r %username%:(R) && icacls.exe moment_key.pem /inheritance:rㅤ
ssh 연결
프라이빗 키(.pem)가 담긴 경로에서 해당 코드를 사용한다.

ssh -i "moment_key.pem" ubuntu@ec2-13-125-91-116.ap-northeast-2.compute.amazonaws.comㅤ
서버 오픈
app.py가 담긴 경로에서 python3를 통해 app.py를 실행한다. 이때, python이 아닌 python3을 사용해야 한다는 점을 주의하라.
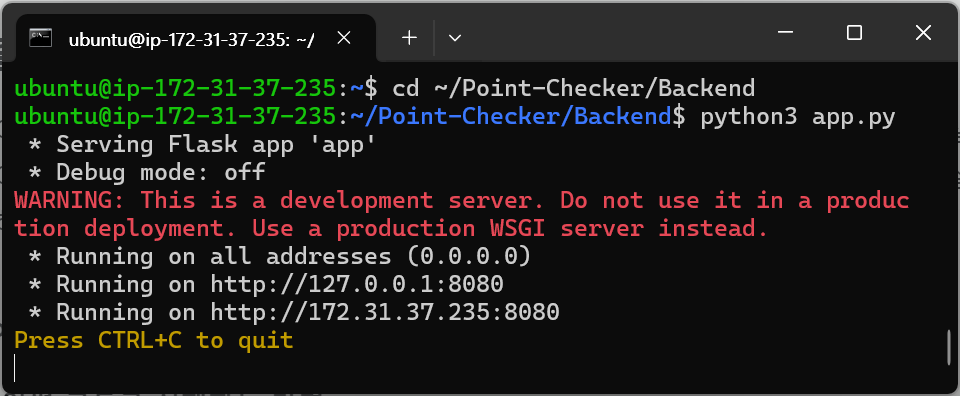
cd ~/Point-Checker/Backend
python3 app.pyㅤ
2. 서버 파일 실행
apt-requirements.txt
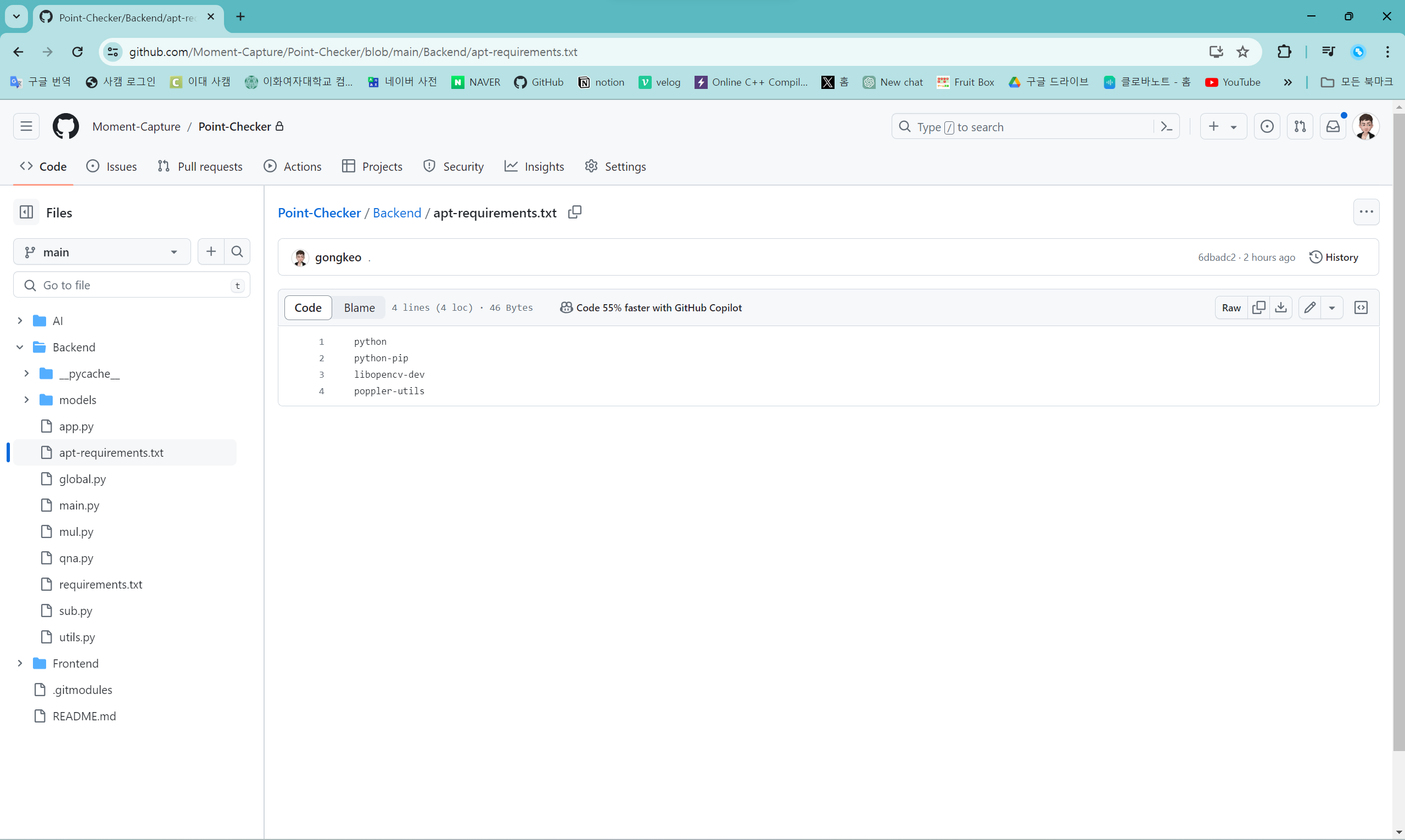
sudo apt-get python
sudo apt-get python-pip
sudo apt-get libopencv-dev
sudo apt-get poppler-utils 인스턴스 연결이 진행된 상태에서 Point-Checker 리포지토리의 Backend 디렉토리의 apt-requirements.txt에 적힌 패키지들을 다운 받는다. sudo apt-get 명령어를 이용해 다운 받을 수 있다.
requirements.txt
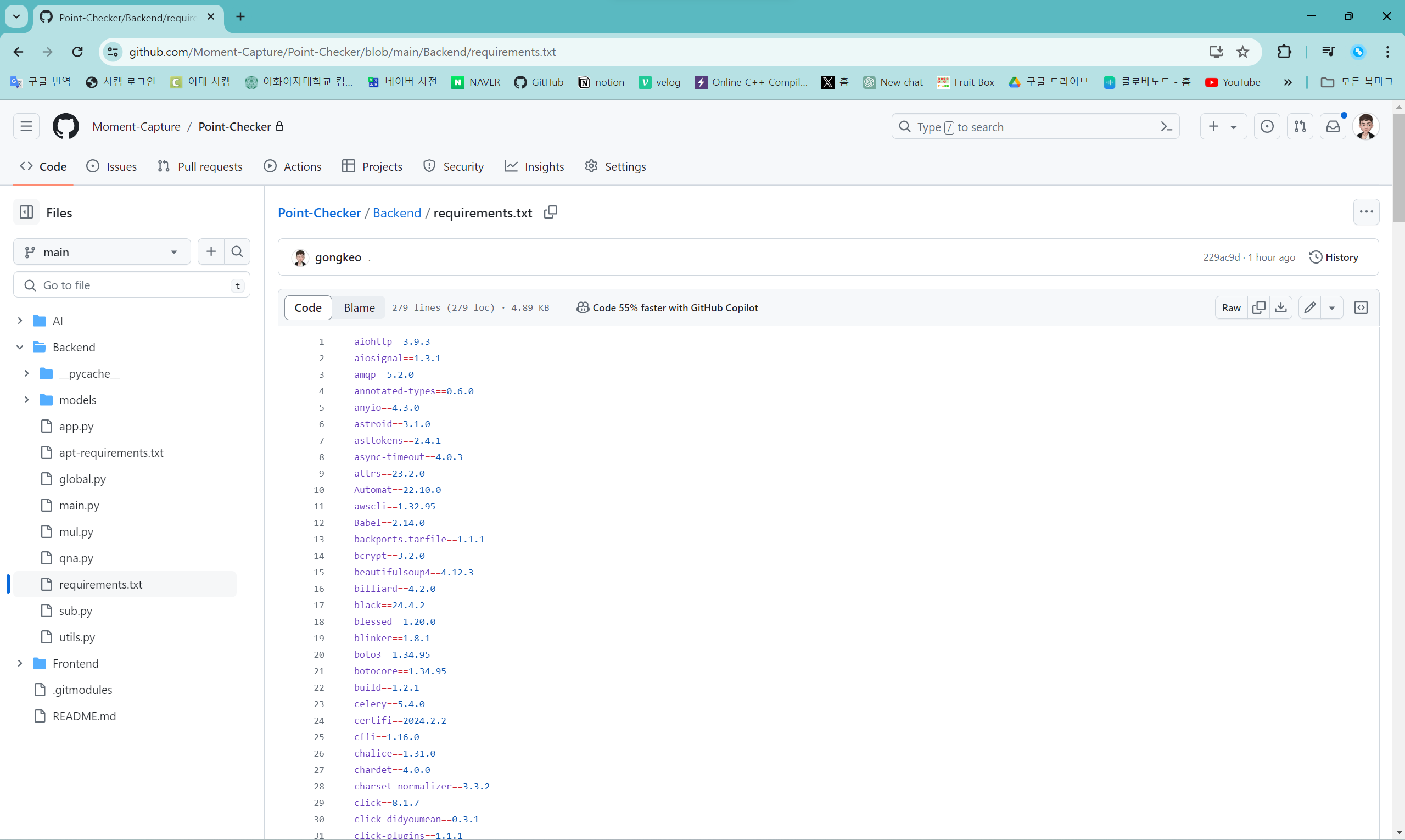
pip install -r requirements.txtPoint-Checker 리포지토리의 Backend 디렉토리의 requirements.txt에 적힌 파이썬 라이브러리를 다운 받는다. pip install -r 명령어를 이용해 다운 받을 수 있다.
app.py
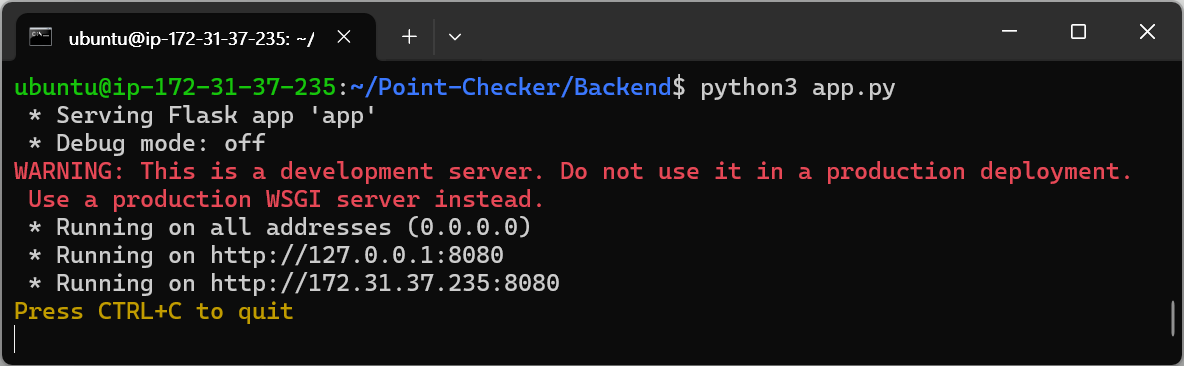
python3 app.pypython으로 실행하면 오류가 발생한다. python3 명령어로 실행해야 한다.
서버 파일인 app.py가 있는 경로에서 해당 코드를 실행하면, app.py가 실행되며 서버가 열리게 된다. 클라이언트의 데이터를 받고 싶다면, 항상 app.py가 실행되는 상태여야 한다.
ㅤ
3. 클라이언트 파일 실행
클라이언트 파일 실행 방법이 두 가지 있다. 첫 번째 방법은 .exe 파일 실행하는 방법이고, 두 번째 방법은 파이썬 코드로 실행하는 방법이다. Point-Checker.exe파일 실행이 용이하므로 전자를 추천하는데, 우선 두 실행 방법 모두 기재해 두겠다.
1) .exe 파일 실행하는 방법
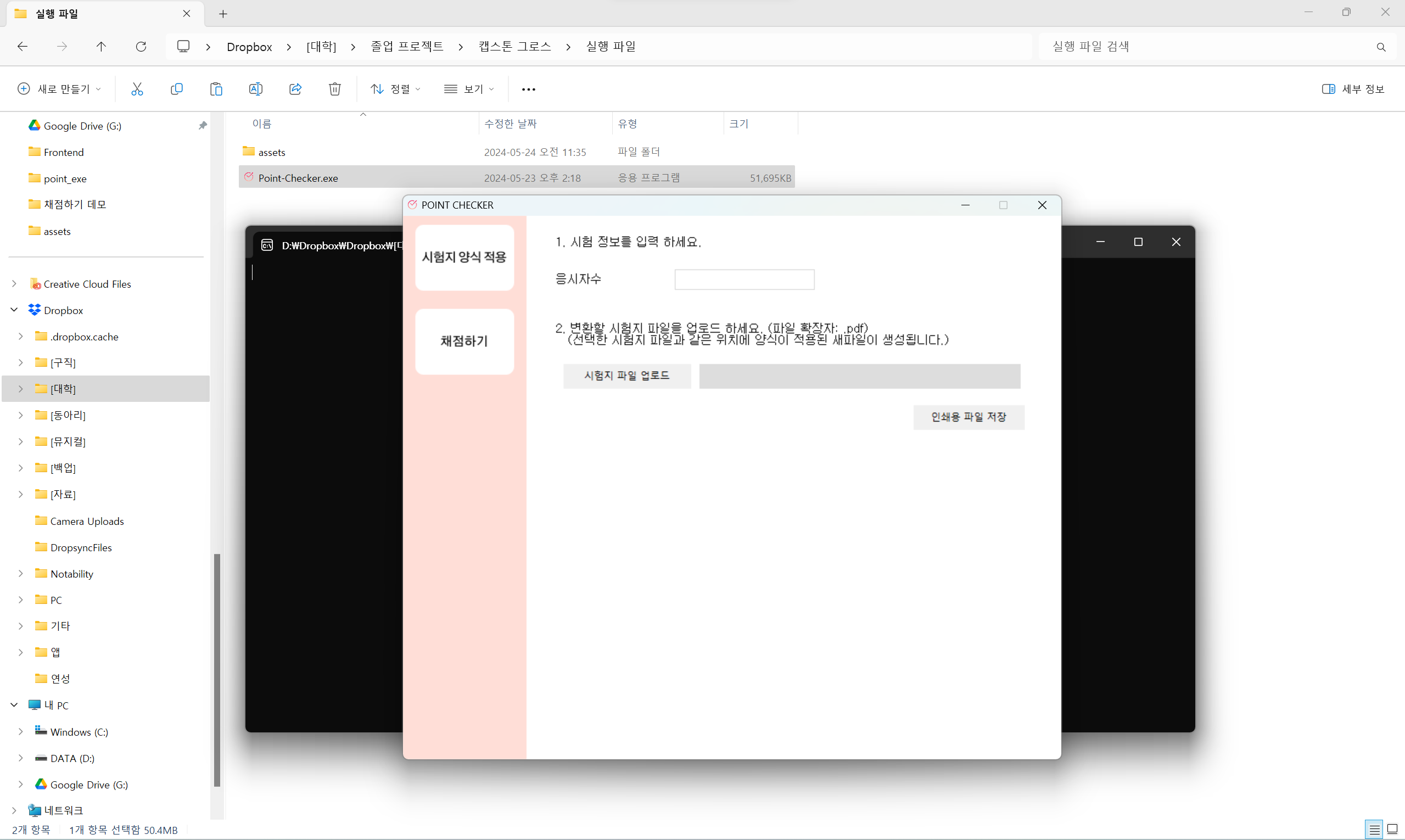
실행 파일을 클릭하면 실행된다. 이때, 실행 파일이 포함된 경로에 assets 폴더가 꼭 같이 있어야 한다.
2) 파이썬 코드로 실행하는 방법
requirements.txt
pip install -r requirements.txtPoint-Checker 리포지토리의 Frontend 디렉토리의 requirements.txt에 적힌 파이썬 라이브러리를 다운 받는다. pip install -r 명령어를 이용해 다운 받을 수 있다.
home.py
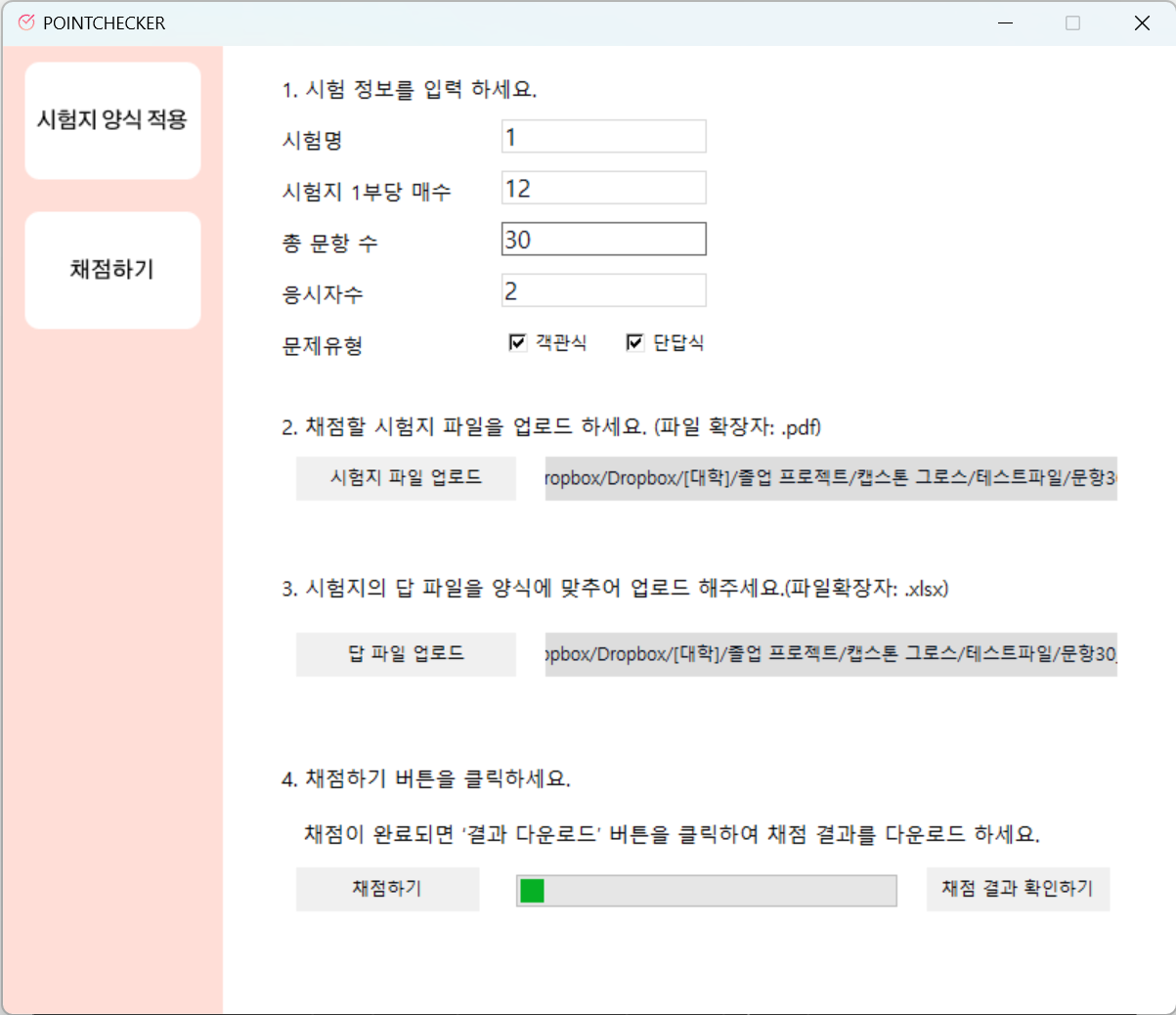
python home.py로컬에서 home.py를 실행하면 .exe 파일이 열리게 된다.
ㅤ
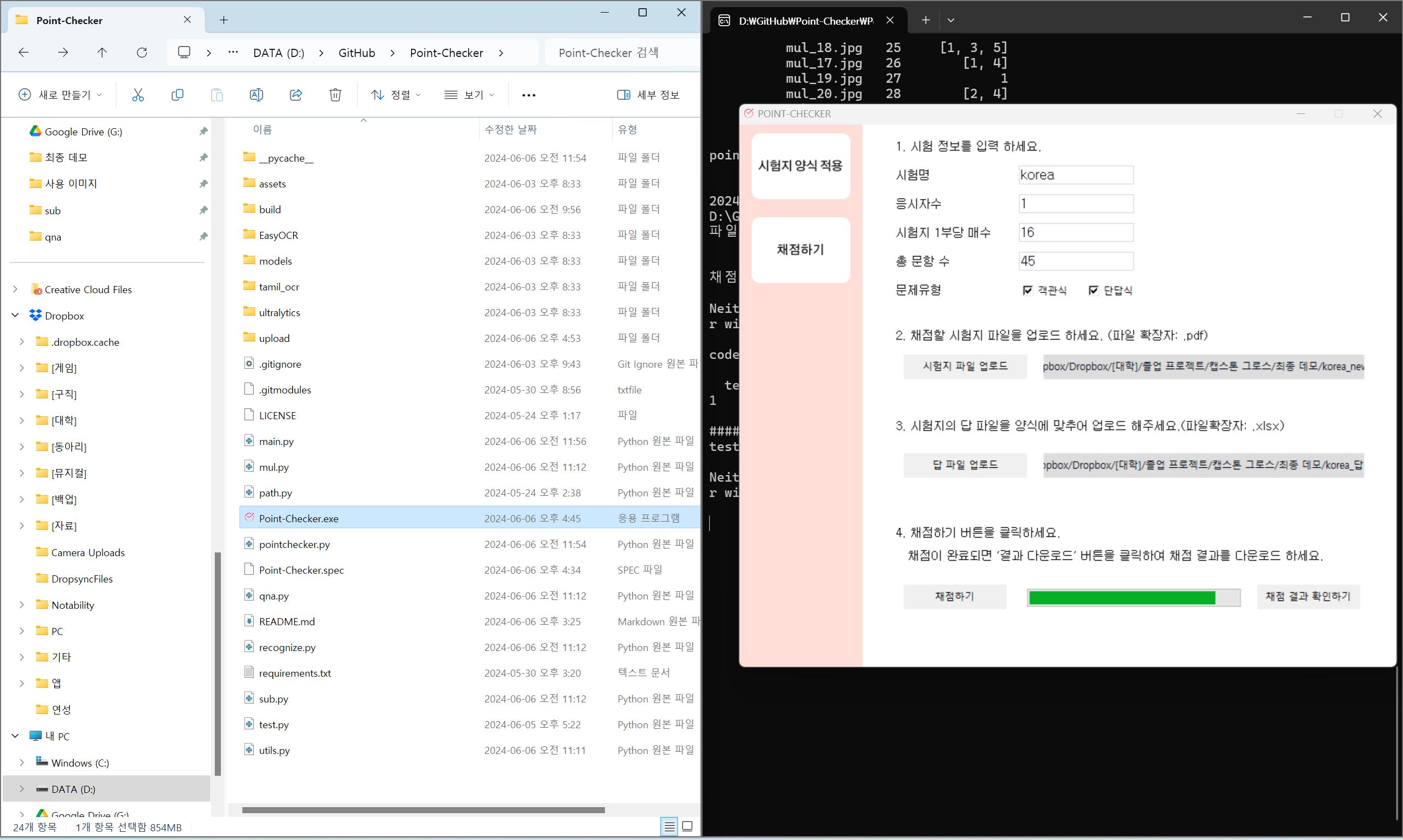
4. 채점하기
"채점하기" 화면에서, 시험 정보를 입력하고 "채점하기" 버튼을 누르면 파일이 전송된다. 이때, "시험지 1부당 매수"와 "응시자수"와 "문제 유형"은 필수로 입력해야 하며 올바른 정보가 아닐 경우 오류가 발생하게 된다. 시험지 파일 및 답 파일 업로드 역시 필수로 진행돼야 한다.
업로드한 시험지 파일은 "시험지 양식 적용"이 되어, 시험지 각 상단에 식별 코드가 부여된 시험지여야 한다.
ㅤ
ㅤ
실행 결과
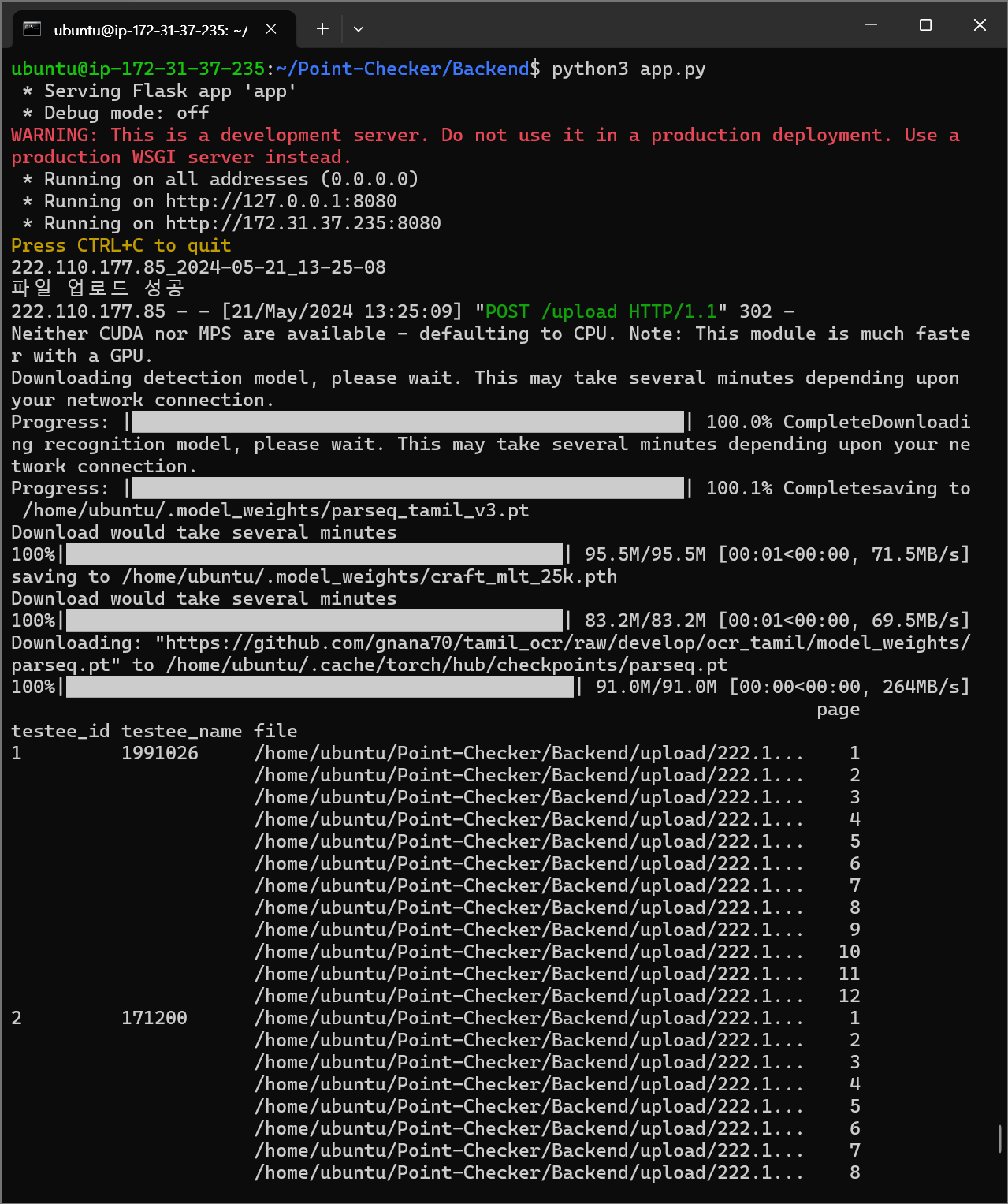
서버
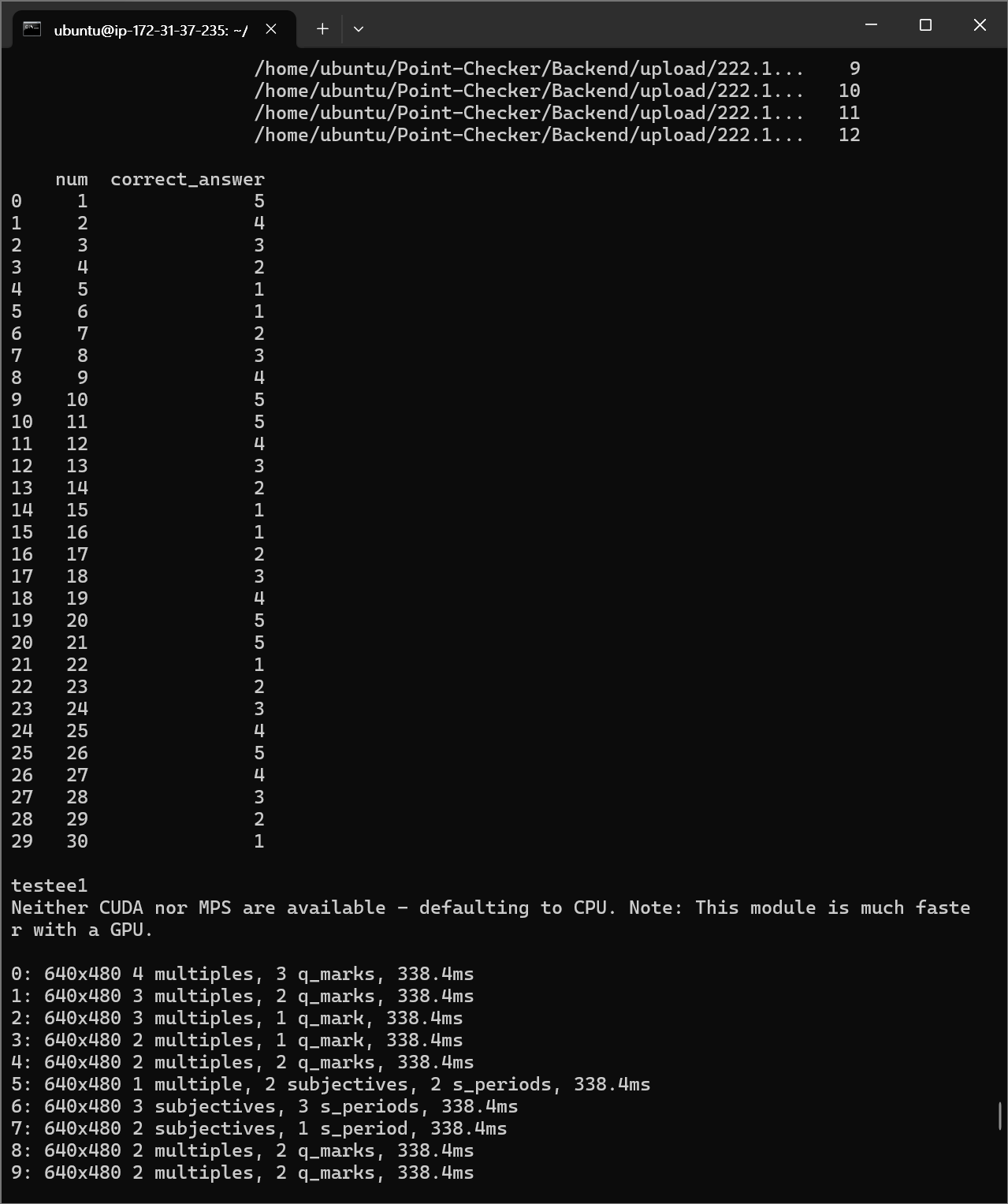
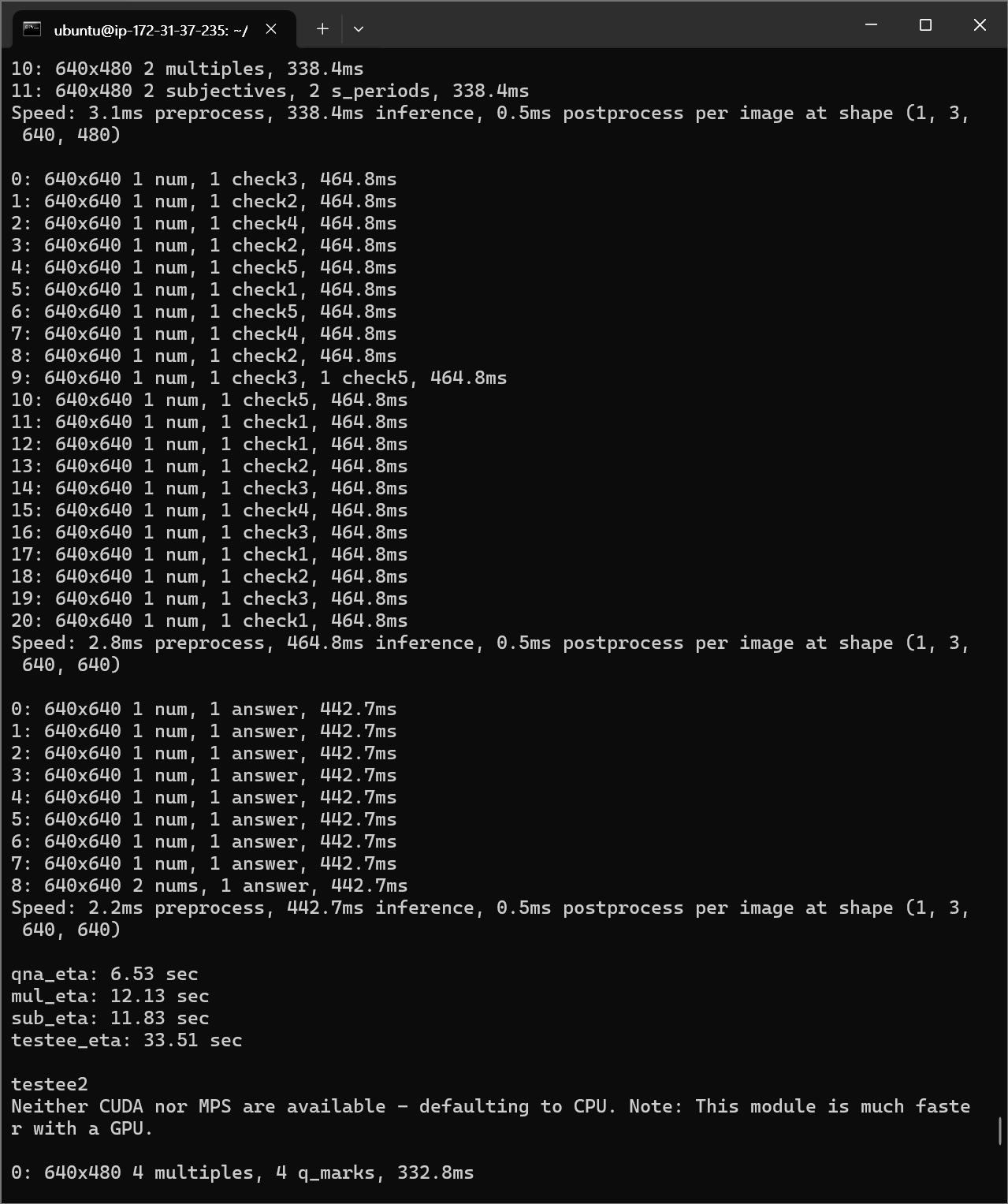

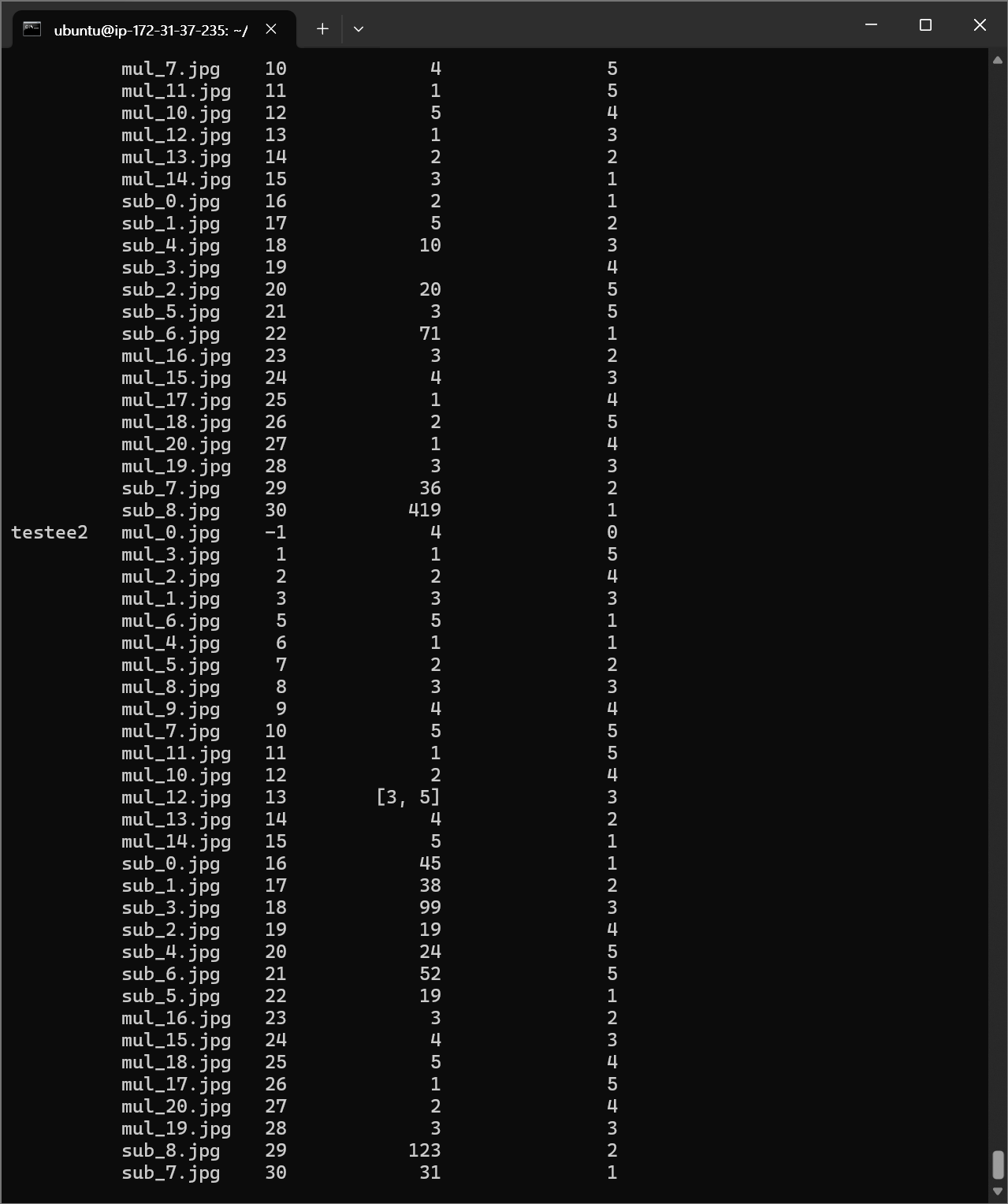

ㅤ
클라이언트

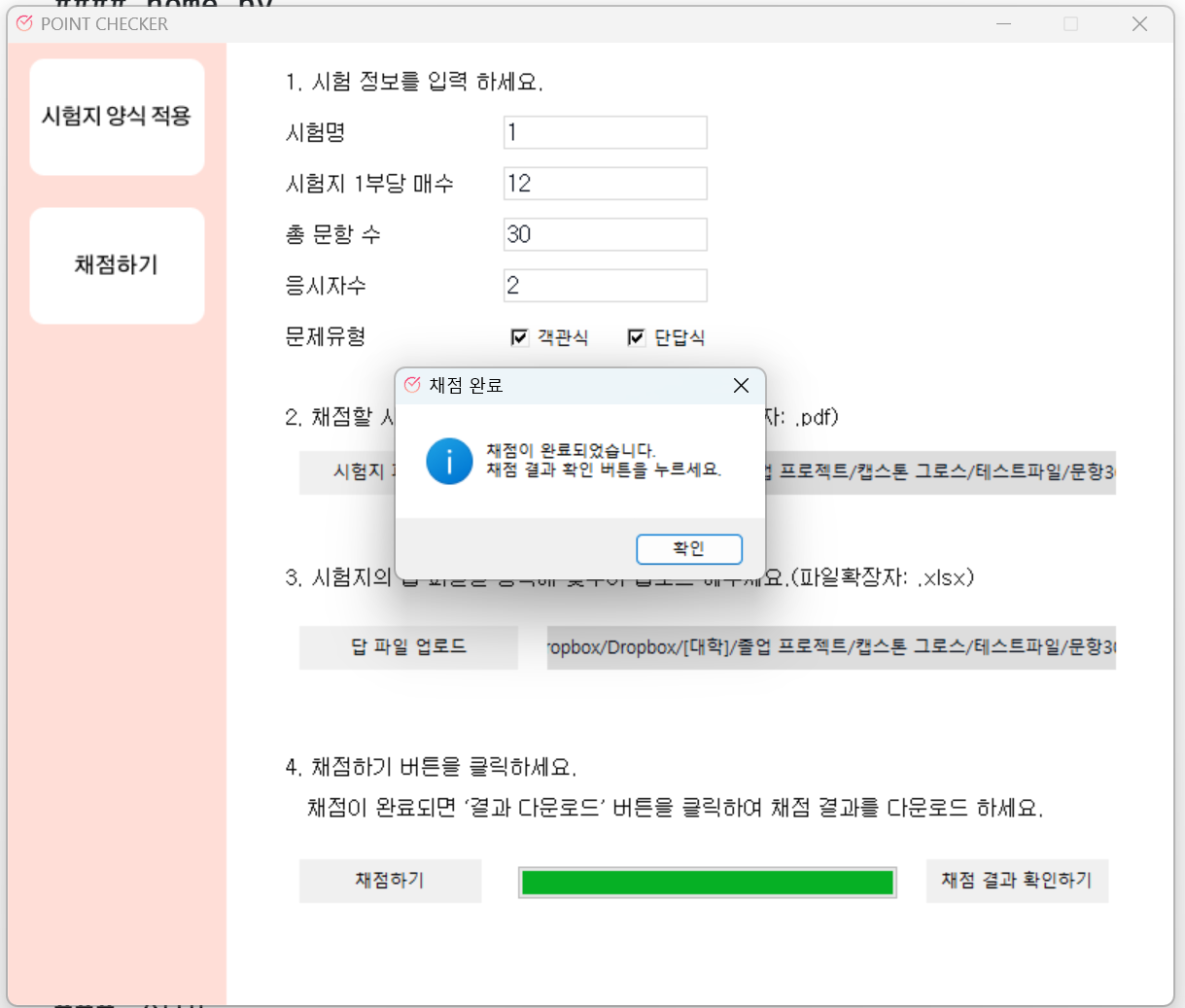
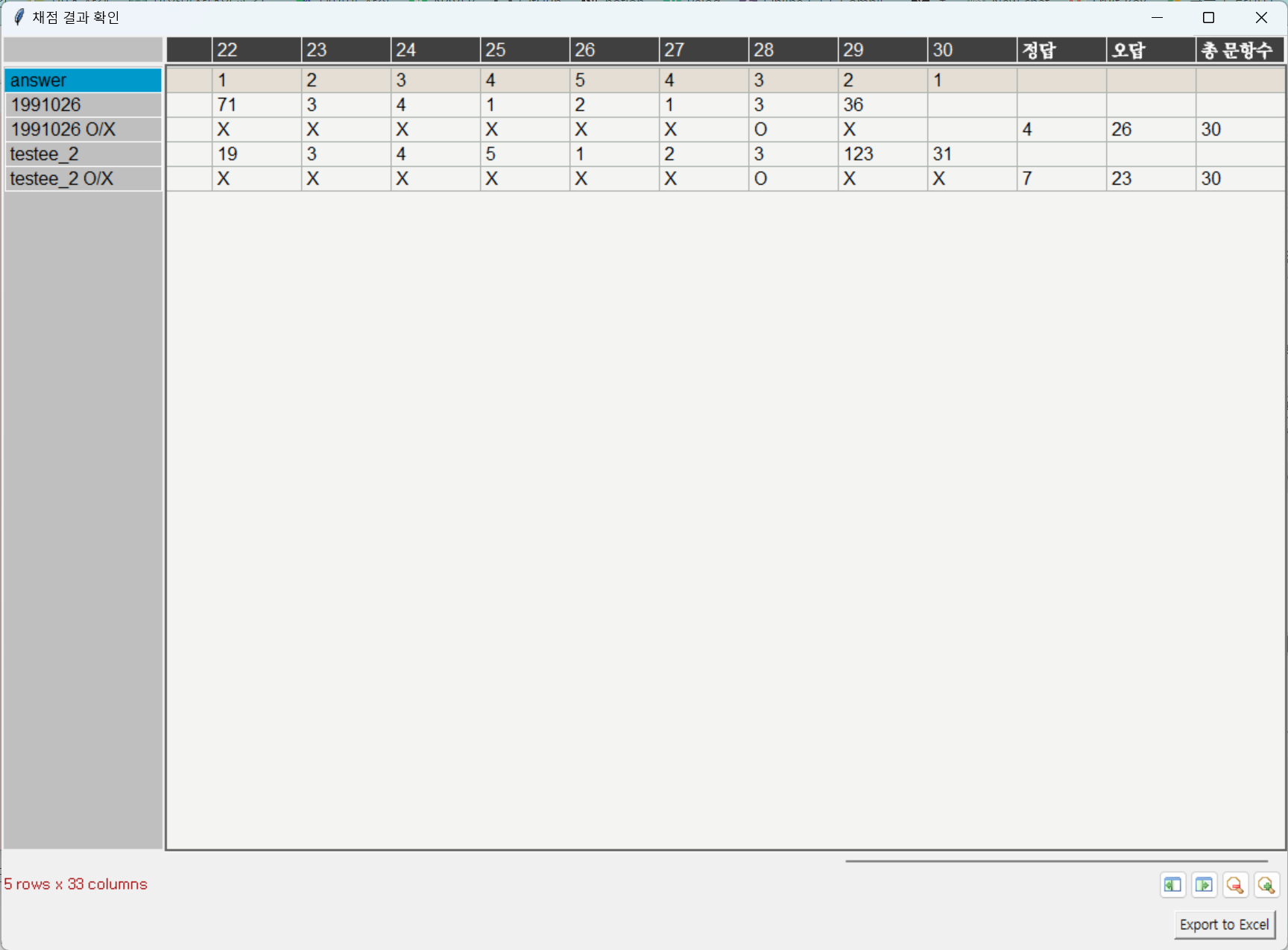
ㅤ
ㅤ
ㅤ
나가며
기술 구현은 스타트 때 하던 것을 이어서 해서 소폭의 변화만 있었다. 라벨링 방향을 수정하고 라벨링 작업을 더 진행했다는 점이 기억에 남는다.
기술 구현을 위해 사용하는 서버 구축 부분이 까다로웠다. gpu를 사용하고 싶어서 할당량 요청을 보냈는데, 할당량 처리가 바로 되지 않아 기다리는 시간이 고통스러웠다는 점이 기억에 남는다. 또한 Private Repository를 통해 작업을 진행했기 때문에, 키를 발급하고 키를 통해 git에 접속해야 했다. 해당 과정에 대한 기술 때문에 글이 조금 길어진 점 양해를 바란다.
약 일 년동안 진행했던 프로젝트가 끝나가서 시원 섭섭하다. 폴 발레리가 "작품은 완성할 수 없으며, 단지 어느 시점에서 포기하는 것뿐이다"라느 말을 남겼다는 걸 어디서 본 적 있다. 이 글을 쓰면서 이 말이 떠올랐다. 완성도 중요하지만 완성 시점을 생각하지 않을 수 없다는 깨달음과 함께 글을 마친다.
*ps. p3-2xlarge 인스턴스 6일 켜 뒀더니 100만원이 나왔다... 안 쓸 때 인스턴스 중지하거나 덜 비싼 인스턴스를 고르자.
