이화여대 캡스톤 디자인 <포인트 체커 - 객체 인식과 NLP를 활용한 객관·단답·서술식 시험 채점 AI 소프트웨어> 기술 블로그
Capstone Design Project

들어가며
이화여자대학교 캡스톤 디자인 프로젝트로 진행 중인 <포인트 체커 - 객체 인식과 NLP를 활용한 객관·단답·서술식 시험 채점 AI 소프트웨어>를 만들기 위해 "객관식 문항 객체 인식" 부분 구현이 완료되었다.
구현 기능 중 yolo 사용 과정을 간단히 소개하고, 배운 점에 대해 정리해 보고자 한다.
소개
목표하고 있는 기능을 구현하기 위해서는 우선 시험지 영역에서 '문제 번호, 문제, 정답을 포함하고 있는 영역'을 추출해야 했다. 이 영역을 'qna'라고 이름 붙였다.
또한 qna로 잘린 영역 중 문제 번호(num), 1번 선지(a1), 2번 선지(a2), 3번 선지(a3), 4번 선지(a4), 5번 선지(a5), 응시자가 고른 선지(checked)를 추출해 겹치는 사각 영역의 좌표 비교를 통해 5개의 선지 중 checked 선지는 몇 번 선지인지 알아내고 이를 Pandas 라이브러리의 dataframe 형태로 변환해 반환하는 과정을 거쳐 "객관식 문항 객체 인식" 구현을 마쳤다.
객체 인식을 하는 ai 툴로 yolov8을 사용했다. yolo는 mAP이라는 지표로 ai의 정확도를 평가한다. mAP는 mean Average Precision의 약자로, AP값의 평균을 의미한다. 객체 인식의 성능은 영역과의 오차에 threshold를 두고 그 오차를 넘으면 검출을 하지 않은 것으로 판정한다. 이러한 방식으로 정확도를 평가해 AP값을 구하고, 이의 평균을 구하면 mAP 지표가 나온다.
qna - 문제&답 영역 검출
그래프
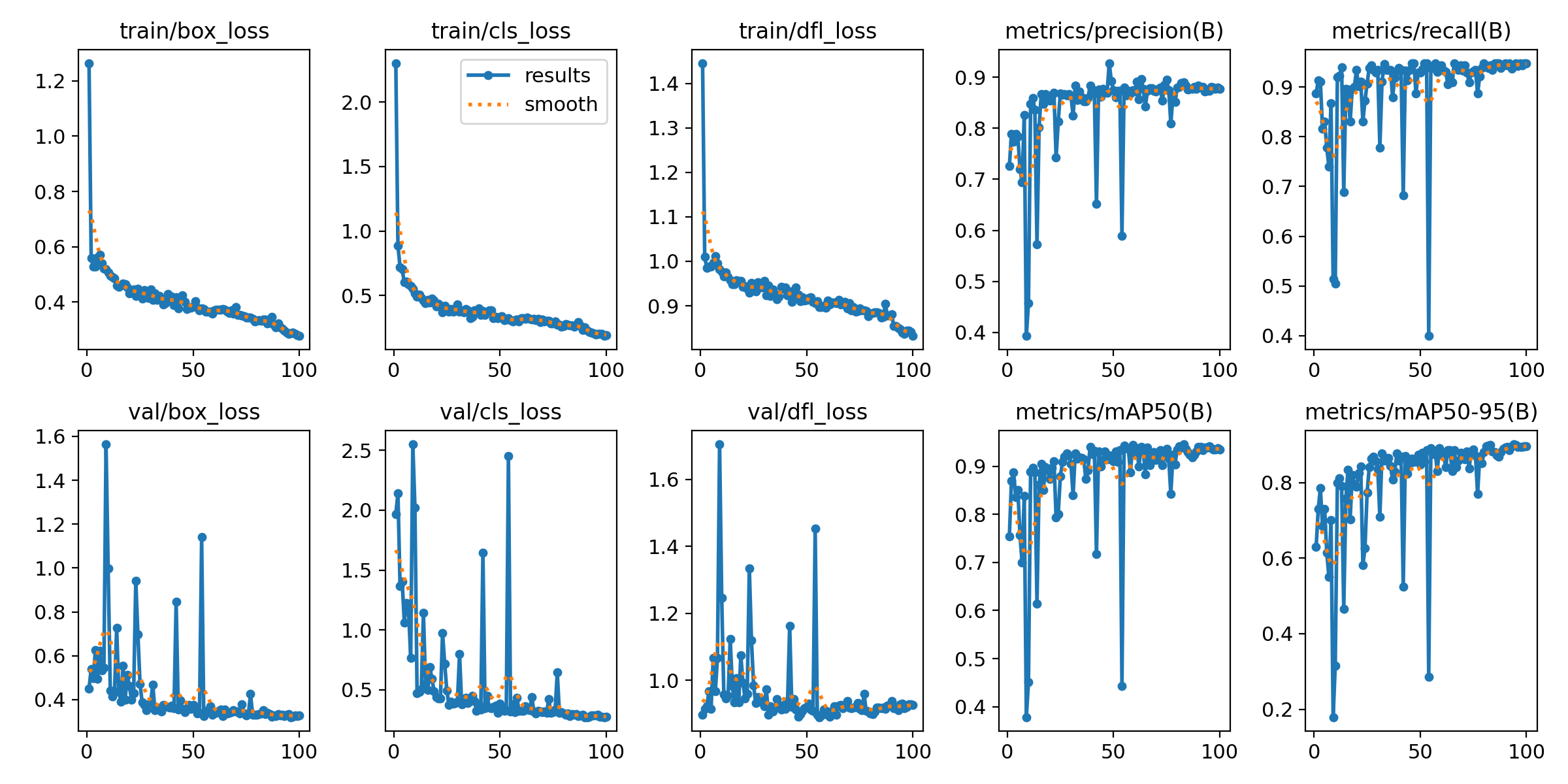
mAP 지표가 0.9에 점차 가까워지는 모습을 보인다. 해당 모델은 mAP50 값이 0.939로 비교적 높은 성능으로 학습됐다.
결과




일부 문제를 제외하면 대부분을 인식한다.
crop - 선지 추출
그래프
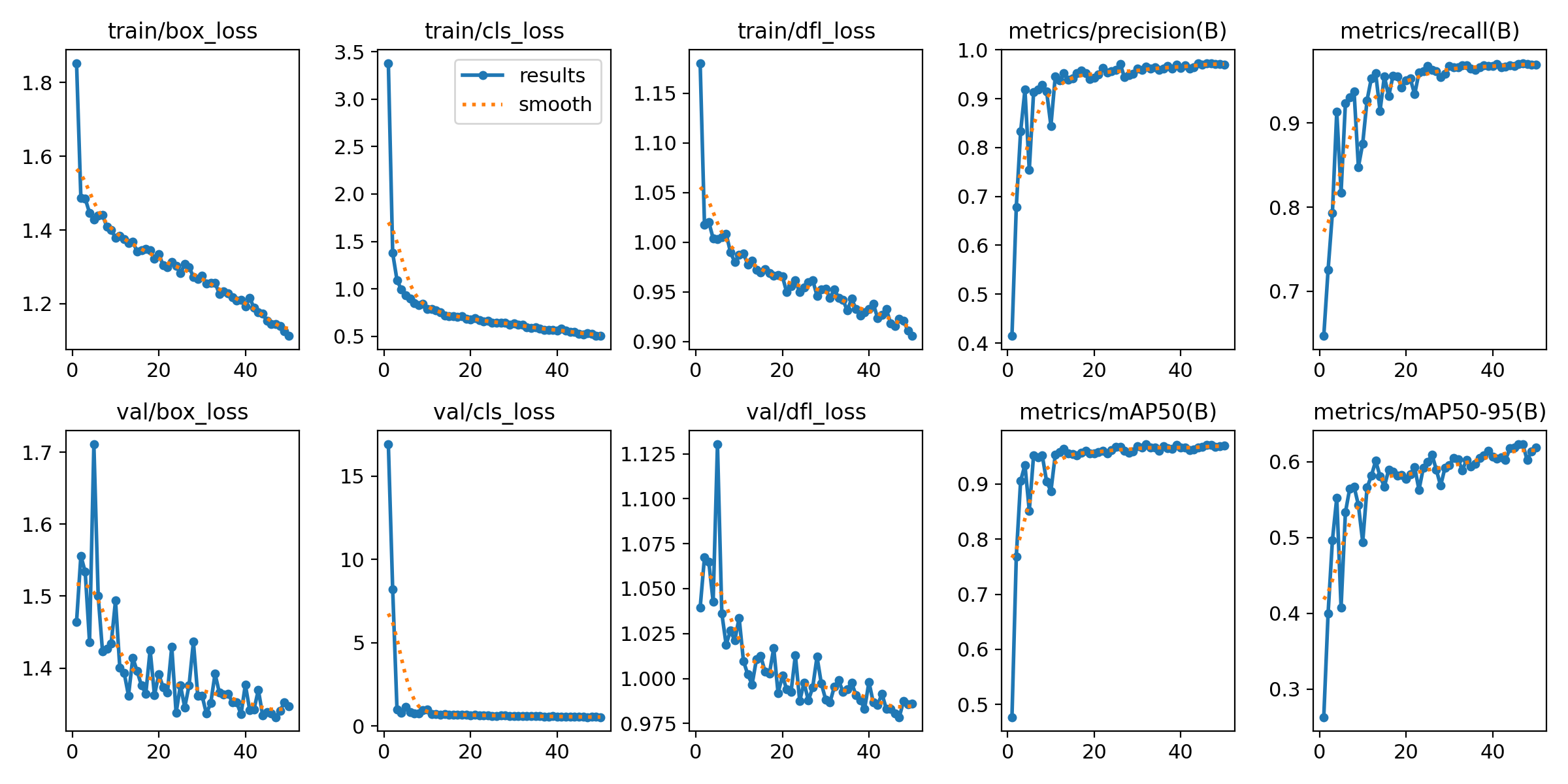
mAP 지표가 0.9에 점차 가까워지는 모습을 보인다. 해당 모델은 checked의 mAP50 값이 0.97로 비교적 높은 성능으로 학습됐다.
결과



거의 모든 문제의 문항 번호, 선지 번호를 검출하고 checked를 검출한다.
구현 과정
사용 환경
GPU 컴퓨터가 없기 때문에, GPU 클라우드를 지원하는 구글 코랩을 사용하여 프로젝트를 진행했다. 구글 드라이브의 코랩 환경에서 yolov8을 사용하는 과정을 설명할 것이다.
설명
1. drive mount
from google.colab import drive
drive.mount('/content/drive')시작하기 전에 항상 해야 하는 드라이브 마운트.
2. requirements 확인
처음 사용 시
%cd /content/drive/MyDrive/순간포착/Colab
!git clone https://github.com/ultralytics/ultralytics.git
!pip install ultralytics
import ultralytics
ultralytics.checks()처음 yolov8을 사용하는 거라면 먼저 사용하고자 하는 디렉토리로 이동한 후, git clone을 통해 ultralytics의 라이브러리를 클론한다.
그리고 사용하는 코랩 pip에 ultralytics를 load하고 사용 가능한 환경인지 체크한다.
이미 clone 후라면
!cd /content/drive/MyDrive/MomentCapture/Colab/ultralytics/
!pip install -U ultralyticsultralytics 폴더로 이동해 U 옵션을 사용해 ultralytics를 install하면 git으로 clone된 환경을 업데이트할 수 있다.
3. train
처음 train
autosplit
from ultralytics.data.utils import autosplit
autosplit(path='../dataset/qna/images')ultralytics 기능 중 autosplit이라는 게 있다. train과 val dataset을 임의로 나눠 주는 것인데, 디폴트 비율은 train:val = 9:1이다. autosplit 함수의 weights 인자를 통해 비율 조정이 가능하다. path 인자에 이미지가 바로 저장된 폴더의 경로를 입력하면 해당 폴더 안에 저장된 이미지를 인식해 해당 폴더의 부모 폴더에 autosplit_train.txt와 autosplit_val.txt로 나눠진 결과를 저장한다.
ultralytics autosplit 설명 참조 링크
예) path='../dataset/qna/images'일 경우,
images 속에 있는 몇백 개의 사진들을 인식해 분류하고 qna 폴더 안에 autosplit 텍스트 파일들을 저장한다.
data.yaml
path: /content/drive/MyDrive/MomentCapture/Colab/dataset/qna
train: autosplit_train.txt
val: autosplit_val.txt
names:
0: qna
1: num
2: a1
3: a2
4: a3
5: a4
6: a5
7: checked그리고 이 정보를 'data.yaml'이라는 파일에 저장해야 autosplit 텍스트 파일들이 작동한다.
path에는 autosplit 텍스트 파일을 포함하는 폴더의 경로를 적으면 된다. (위의 경우, qna 폴더가 된다.) train과 val에는 각각 txt 파일 이름을 적으면 되고, names에는 라벨 이름들을 적으면 된다.
yolo
%cd /content/drive/MyDrive/MomentCapture/Colab/ultralytics/yolo는 실행 경로가 꼭 ultralytics 폴더 밑에 있을 때 실행된다. 오픈 소스를 사용할 때 대부분 실행 경로를 바꾼 후 사용해야 하기 때문에 오류가 난다면 실행 경로 확인부터 해야 한다.
from ultralytics import YOLO
model = YOLO('yolov8m.pt')
results = model.train(
data='../dataset/qna/data.yaml',
batch=20,
epochs=100,
name='qna_train2_epoch100')처음 실행하는 것이기 때문에 기본으로 제공되는 yolov8m.pt 파일을 사용한다. data에는 data.yaml의 경로를 적고, batch와 epochs는 적절한 숫자를 찾아 입력한다. 참고로 epochs는 50과 100을 실행했는데, 100이 적당한 훈련 숫자라 100번을 골랐다.
transfer train
%cd /content/drive/MyDrive/MomentCapture/Colab/ultralytics/from ultralytics import YOLO
model = YOLO('./runs/detect/train3_qna_2021-수능_epoch100/weights/last.pt')
results = model.train(
data='../dataset/2021_9월/data.yaml',
batch=20,
epochs=100,
name='train4_qna_2021-수능_2021-9월_epoch100')처음 학습을 시킬 때는 라벨링 작업이 다 된 2021 수능을 먼저 시키고, 2021 9월 평가원 모의고사 라벨링 작업 후 따로 학습을 시켰기 때문에 위와 같은 코드를 사용했다. transfer train은 train으로 만들어진 모델을 골라 weights 밑의 last.pt를 사용하여 이어서 학습시키면 된다.
4. validation
%cd /content/drive/MyDrive/MomentCapture/Colab/ultralytics/from ultralytics import YOLO
# Load a model
model = YOLO('./runs/detect/qna_train1_epoch50/weights/best.pt') # load a custom model
# Validate the model
metrics = model.val(
data='../dataset/qna/data.yaml',
name='qna_val_train1') # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category
성능을 평가할 수 있는 val 기능이다. 위 기능을 통해 train한 모델들을 비교하고 가장 성능이 괜찮게 나오는 걸 골라 사용했다.
5. detect
%cd /content/drive/MyDrive/MomentCapture/Colab/ultralytics/from ultralytics import YOLO
# Load a model
model = YOLO('./runs/detect/qna_train1_epoch50/weights/best.pt') # pretrained YOLOv8n model
# Run batched inference on a list of images
results = model(source='../dataset/detect/2019_수능', save=True, name='qna_detect_train1_2019_수능', save_crop=True) # return a generator of Results objects
# Process results generator
for result in results:
boxes = result.boxes # Boxes object for bbox outputs
masks = result.masks # Masks object for segmentation masks outputs
keypoints = result.keypoints # Keypoints object for pose outputs
probs = result.probs # Probs object for classification outputsresults에 결과물을 어떻게 할지 정할 수 있는 옵션들이 몇 개 있다. 이 프로젝트에서는 save를 가장 먼저 사용했고, 추가적으로 save_crop 기능을 유용하게 사용했다. save_crop=True로 설정하면 모델이 감지한 영역에 따라 알아서 crop하고 label 폴더를 형성해 그 밑에 저장해 준다. qna 영역 감지 모델을 사용해 crop한 qna를 checked 선지 감지 모델의 입력 데이터로 사용했으므로 꼭 필요한 옵션이라고 할 수 있다.
문제 해결
잘림 현상
문제


yolov5으로 학습했을 때, qna 검출 부분에서 난항을 겪었다. 문항 번호를 다 포함하지 않고, 정답 영역을 포함하지 않은 채로 인식해 사용이 어려웠기 때문이다.
해결
yolov5에서 yolov8을 사용하니 같은 epoch와 batch를 사용했음에도 성능의 개선이 이루어진 것을 관찰할 수 있었다. 따라서, yolov8을 사용하는 방향으로 문제를 해결했다.
한글 인코딩 실패 현상
문제
구글 코랩의 pip 문제인 것 같은데, 드라이브 마운트 후 train이나 val 함수를 실행시키면 autosplit 텍스트 파일을 읽을 때 한글 인코딩 오류가 발생한다. 이미지 파일명이 한글이라서 발생하는 문제 같다.
해결
사실상 직접적인 해결이 불가하다.
통상적으로 이용되는 방법을 다 사용해 봤다. 인코딩 형식을 바꾸거나, 파일을 다시 저장하거나. 하지만 소용이 없었다. 그냥 불편하더라도 새로 기능을 이용하고 싶을 때는 코랩 리소스를 초기화해서 새로 드라이브를 마운트하고 기능을 이용하는 수밖에 없는 것 같다.
대안으로, 차후 저장할 이미지들은 이름을 영어로 짓기로 했다.
배운 점
yolov8을 사용하는 방법을 통해 오픈 소스를 내 환경에 맞게 활용하는 방법을 배울 수 있었다. 또한 객체 인식 모델을 학습시키며 fine tuning 경험을 늘릴 수 있어 여러모로 도움이 됐다.
그리고 매번 프로젝트를 하며 느끼는 점이지만 오류의 절반은 실행 경로 미스와 같은 사소한 부분에서 비롯된다. 또한 문제 해결을 하면서 한글 사용을 왜 지양해야 하는지 알게 되었다. 차후 프로젝트를 진행할 때는 혹시 모를 상황에 대비해 한글 사용을 피해야 겠다.
나가며
현재 구현된 기능 중 수정해야 할 사항은 qna 문제 영역이 잘렸을 때 crop 모델에서 어떻게 처리해야 할 것인지, 예외 사항에 대한 대비를 해야 한다는 점이다. 이 부분 해결 방법을 현재 생각 중이다.
또한 앞으로 프로젝트의 진행을 위해서는 NLP를 공부해야 한다. 레퍼런스는 찾아 뒀고, 또 서술형 채점에 대한 선행 연구 프로젝트가 있어 해당 git을 둘러 보며 공부할 예정이다.
Reference
https://velog.io/@nayeon_p00/series/2021CapstoneDesign
https://github.com/boostcampaitech3/final-project-level3-nlp-03
https://github.com/ultralytics/ultralytics
