기본적인 메소드
- pandas
- data.loc[행라벨, 열 라벨]: 해당 라벨을 가진 데이터를 추출
- data.loc[[행라벨]]: 해당 행을 모두 추출. 열도 가능
- data.count(): 각 열의 결측치를 제외한 값을 반환
- data[['열 이름']].mean(): 해당 열의 평균.
- data['열 이름'].quantile(백분위수): 백분위수에 해당하는 값 반환
- data.loc[행라벨, 열 라벨]: 해당 라벨을 가진 데이터를 추출
- numpy
- np.mean(df[col]): 평균 구하기
1. 파이썬 기본 개념
1) 클래스: 프로그래밍에서 객체를 만들 때 사용
- 방식
class 클래스이름:
'''독 스트링'''
__속성 = 값 # 비공개 클래스 속성 ex) 한 캐릭터의 저장 공간이 10인 경우
def 메서드(self):
코드
def __init__(self,매개변수):
self.__속성 = 특정값 # 비공개 속성 - 클래스 안에서만 접근 가능
def __함수명(self): # 비공개 메소드
pass
def 함수명(self):
self.__함수명() # 클래스 안에서는 비공개 매서드 호출 가능 - 사용
- 인스턴스를 생성해 사용
- 클래스 속성 ↔ 인스턴스 속성
- 클래스 속성: 클래스에 속해 있으며 모든 인스턴스에서 공유
- 인스턴스 속성: 클래스에 속하지만 해당 인스턴스에서만 사용
- 정적 메소드 @staticmethod
- 인스턴스 속성, 인스턴스 메소드가 필요없을 때 사용.
- 순수함수를 만들 때 사용함
- 구분 - 인스턴스의 내용을 변경해야할 때는 인스턴트 메소드로 작성, 내용과 상관없이 결과값만 구하면 되는 경우엔 정적 메소드로 작성
- 클래스 메소드 @classmethod
- cls: 클래스 메소드의 첫 번째 매개변수
- 정적 메소드와 같이 인스턴스 없이 호출 가능 다만 클래스 속성, 클래스 메소드에 접근해야할 때 사용
- 클래스 속성 ↔ 인스턴스 속성
- 인스턴스를 생성해 사용
2) 객체지향프로그래밍
복잡한 문제를 잘게 쪼개 객체를 만들고, 객체를 조합해 문제를 해결.
현실세계의 복잡한 문제를 처리하는 데에 유리, 효율적인 유지 보수
2. 데이터 전처리 기법
1) 결측치
(1) 결측치 처리 방식
- 결측치가 있는 데이터 제거
- 결측치를 어떤 값으로 대체
- 이와 같은 경우 각 데이터의 특성을 반영해 해결해야 함.
(2) 결측치가 있는 열 측정 방법
전체 데이터 건수 - 각 컬럼별 값이 있는 데이터의 수
ex) len(data) - data.count()(3) 결측치가 있는 열 삭제 방법
data = data.drop('칼럼명', axis=1)(4) 결측치가 있는 행 측정 방법
- data.isnull(): 데이터마다 결측치가 있으면 True, 없으면 False로 반환
- data.any(axis=1): 행마다 하나라도 True가 있으면 True, 아니면 False 반환
⇒ isnull()이 True일 경우(데이터에 결측치가 하나라도 있는 경우)를 any(axis=1)이 판단해 반환해줌.
# 각 행에 결측치가 하나라도 있는지 여부
data.isnull().any(axis=1)✔✔✔
data[data.isnull().any(axis=1)]⇒ 값이 True인 데이터만 추출 = 결측치만 있는 행을 추출
✔✔✔ 🤔
data[조건] => 조건에 해당하는 행 추출
(5) 결측치 삭제 방법
- dropna(): 결측치를 삭제해주는 메서드
- subset: 특정 칼럼 선택
- how: all - 컬럼 전부가 결측치인 행을 삭제하겠다는 의미 / any - 하나라도 결측치인 경우 삭제하겠다는 의미
- inplace: DataFrame 내부에 바로 적용
trade.dropna(how='all', subset=['수출건수', '수출금액', '수입건수', '수입금액', '무역수지'], inplace=True)(6) 수치형 데이터 / 범주형 데이터 보완 방법
| 범주형 데이터 | 연속형 데이터 |
|---|---|
| 특정 소속에 따라 문항을 구분 지음 | 관측 값이 숫자로 나타나는 경우 |
| 학년, 만족도 조사 등 | 키, 몸무게, 측정 시간 등 |
| 빈도와 퍼센트를 이용해 분석 | 기술통계량 가능 |
- 수치형 데이터
| 방법 | 예상되는 문제 or 방법 |
|---|---|
| 특정 값 지정 | 결측치가 많은 경우 모두 같은 값으로 대체하면 데이터의 분산이 실제보다 작아질 수 있음 |
| 평균, 중앙값 등으로 대체 | 결측치가 많은 경우 데이터의 분산이 실제보다 작아질 수 있음 |
| 다른 데이터를 이용해 예측값으로 대체 | ex) 머신러닝 모델로 예측값을 만들고 이 값으로 결측치를 보완 |
| 앞, 뒤 데이터를 통해 결측치 대체 | ex) 시계열의 특성을 가진 데이터(ex_기온을 측정하는 센서 데이터에서 결측치가 발생한 경우)의 경우 전후 데이터의 평균으로 보완 가능) |
- 범주형 데이터
| 방법 | 예상되는 문제 or 방법 |
|---|---|
| 특정 값 지정 | 기타, 결측과 같이 새로운 범주를 만들어 결측치를 채울 수 있음 |
| 최빈값 등으로 대체 | 결측치가 많은 경우 최빈값이 지나치게 많아질 수 있으므로 결측치가 많을 때는 다른 방법을 사용해야함 |
| 다른 데이터를 이용해 예측값으로 대체 | - |
| 앞, 뒤 데이터를 통해 결측치 예측 | 시계열의 특성을 가진 데이터의 경우 가능. ex) 특정인의 2019년 직업이 누락됐을 때, 2018년과 2020년의 직업이 같다면 그 직업으로 결측치를 대체. 만약 두 해가 다르다면 둘 중 하나를 선택해 대체 |
2) 중복된 데이터
(1) 중복된 데이터 확인
- 중복될 경우 True로 반환
data.duplicated()(2) 중복된 행 확인
data[trade.duplicated()](3) 중복된 다른 행 확인
- 중복된 행을 확인해 조건을 설정함
#예
trade[(trade['기간']=='2020년 03월')&(trade['국가명']=='중국')](4) 중복된 데이터 삭제
data.drop_duplicates(inplace=True)- subset, keep
- subset: column label or sequence of labels, optional
- keep: {'first', 'last', False}, default 'first'
- 중복된 값이 있을 경우 먼저 입력된 값을 남겨둘지, 마지막에 입력한 값을 남겨둘지.
🤔 false는 겹치는 모든 것을 drop
- 중복된 값이 있을 경우 먼저 입력된 값을 남겨둘지, 마지막에 입력한 값을 남겨둘지.
data.drop_duplicates(subset=['id'], keep='last')4. 이상치 (Outlier)
| 이상치를 판단한 뒤 시행하는 방식 |
|---|
| 이상치를 원래 데이터에서 삭제. 이후 이상치끼리 따로 분석하기 |
| 이상치를 다른 값으로 대체. 데이터가 적으면 이상치를 삭제하기보다 대체하는 것이 나을 수 있음. 예를 들어 최대, 최소값을 설정해 데이터의 범위를 제한할 수 있음. |
| 결측치와 마찬가지로 다른 데이터를 활용해 예측 모델을 만들어 예측값을 활용할 수 있음 |
| Binning을 통해 수치형 데이터를 범주형으로 바꿀 수 있음 |
(1) z score
- 간단, 가장 자주 사용되는 방법. 표준편차를 이용함.
- 평균을 빼주고 표준편차로 나누어 z score을 계산한다. 이때 z score가 특정 기준을 넘어서는 데이터를 이상치라고 판단한다.
- 평균과 표준편차가 outlier의 영향을 받음. 그렇기 때문에 outlier가 유발하는 왜곡에 영향을 쉽게 받는다.
- 작은 데이터셋인 경우 z-score 방법으로는 이상치를 알아내기 힘들다. 데이터셋의 아이템이 12개 이하인 경우는 적용 불가.
✔✔✔ 🤔
1. 이상치를 원래 데이터에서 삭제만 해도 될까?/ 삭제하고 이상치끼리 따로 분석하는 것까지 완료해야할까? >> 상황에 따라 판단하면 됨. 현업 데이터 분석 시 이상치 분석에 큰 시간을 들이지 않는 것을 추천함.
- Binning을 쓰는 이유는 무엇일까?
연속형 데이터를 구간화하여 범주형 데이터처럼 사용하기 위함
(2) IQR(Interquartile range) 방법
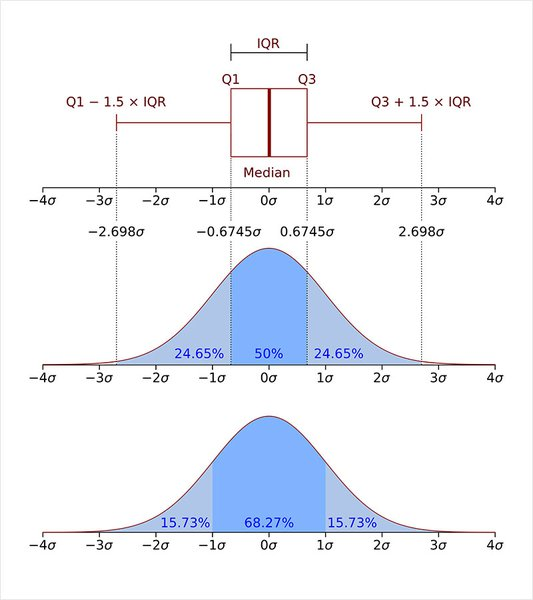
- IQR = 제3사분위수 - 제1사분위수
- Q1 - 1.5IQR, Q3 + 1.5IQR 사이에 있는 경우 이상치가 아님 (그 외 범위 이상치로 판단)
Q3, Q1 = np.percentile(data,[75, 25])
IQR = Q3 - Q15. 정규화
일반적으로 칼럼 간에 범위가 크게 다를 경우 칼럼의 영향력 또한 달라질 수 있다. 이런 경우를 방지 하기 위해 전처리 과정에서 데이터를 정규화한다.
1) 표준화(standarization)
데이터의 평균은 0, 분산은 1로 변환
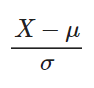
2) Min-Max Scaling
데이터의 최솟값은 0, 최댓값은 1로 변환

3) 방식
- 직접 계산
공식을 활용해 직접 계산한다. - sklearn 이용
from sklearn.processing import MinMaxScaler
train = [[10, -10], [30, 10], [50, 0]]
test = [[0,1]]
scaler = MinMaxScaler()
scaler.fit_transform(train)
scaler.transform(test)✔✔✔ 🤔
transform 과 fit_transform 의 차이는? 참고- transform: test data에만 사용. train data로부터 학습된 평균값과 분산값을 적용하기 위해 사용. - fit_transform: training data에만 사용왜 fit_transform 을 test data에 사용하지 않을까?
모델이 학습된 후 평가에 이용해야하는 데이터가 test data인데, fit_transform을 test data에 사용할 경우 모델이 test data도 학습하게 됨. 따라서 fit_transform을 사용할 경우 test data를 성능 평가에 사용할 수 없게 되는 것. 전처리를 위해 정규화 과정(transform)만 거치고 학습(fit)은 하지 않는 것.
주의
train, test 데이터가 나뉜 경우 train 데이터를 정규화 시킨 기준 그대로 test 데이터도 정규화 해줘야함.
6. 원-핫 인코딩
머신러닝이나 딥러닝 프레임워크에서 범주형을 지원하지 않는 경우 원-핫 인코딩을 해야함.
1) 원-핫 인코딩
카테고리 별 이진 특성을 만들어 해당하는 특성만 1, 나머지는 0으로 만드는 방법.
2) 판다스에서 원-핫 인코딩 하기
get_dummies 사용
# 원래 head
data['열 이름'].head()
# get_dummies
get_dum = pd.get_dummies(data['열 이름'])ex) 5개의 값이 나온다면, 5개가 각각 1이고 나머지 4개가 0인 경우를 반환함
나온 결과를 합치면 다음과 같이 됨

7. 구간화 (Binning)
구간화는 히스토그램과 같이 연속적인 데이터를 구간을 나눠 분석할 때 사용함
✔✔✔🤔
구간화와 clustering의 차이점은?'구간화는 단순히 수치형 데이터를 범주형 데이터로 활용하기 위해 처리하는 과정이고 clustering은 머신러닝에서 이용하는 한 방법으로 유사한 성향을 가진 개체를 모아 군집을 만들고 그 특성을 관찰하거나 목표변수와의 관계를 파악하는 방법임💥 정리 여러 개체가 있을 때 특성을 고려해 같은 그룹을 만드는 것이 클러스터링이고 개체의 속성 중 연속형 데이터를 가진 값을 범주형으로 바꾸는 것이 구간화
1) 구간을 직접 설정하는 방법
- 구간을 설정함
bin = [0, 2000, 4000, 6000, 8000, 10000]- cut 함수에 데이터와 구간을 입력해 구간별로 구분
ctg = pd.cut(salary, bins=bin)- 구간 별 개수 세기
ctg.value_counts().sort_index()2) 균등하게 나누는 방법
ctg = pd.cut(salary, bins=6)3) 데이터의 분포를 비슷한 크기의 그룹으로 나누는 방법
ctg = pd.qcut(salary, q=5)3. 회고
갑자기 linear regression 이나 clustering을 예시로 들어 설명해서 당황했다. 어렴풋이 아는 개념이라 그냥 슥 읽고 넘겼는데 나중에 다시 읽었을 때 완전히 이해하고 넘어갈 수 있었으면 좋겠다.
오늘은 LMS 시간에 배운 내용을 정리하면서 중간 중간 질문이 생겨서 ✔✔✔🤔 이 모양을 이용해 의문점을 남겨보았다. 그리고 블로그 정리 시간에 구글링 해보면서 직접 답을 찾아봤는데 확실히 그 사이 공부가 된 건지 '이런 질문을 왜 했지?'하는 생각이 들기도 했다. 공부가 잘 되고 있는지 확인하는 방법 중 하나가 과거의 내가 질문한 사항에 대해서 현재의 내가 답해보는 것이라고 생각한다. 현재의 내가 납득이 갈만하게 설명할 수 있다면 그 개념은 80퍼센트 정돈 안다고 자부해도 괜찮다. 20퍼센트를 남겨두는 이유는.. 남에게 설명했을 때 막힌다면 소용없다고 생각하기 때문에..
어쨌든 첫 날 예상한 대로 날이 갈 수록 내용이 많아지는데 아직까진 감당할만 해서 다행이다. 개념을 이해하긴 하는데 이걸 내 스스로 활용할 수 있을지는 아직 잘 모르겠다. 역시 답은 연습이겠지.. 나중에 데이터톤 같은 데도 나가보고 싶다.
