1. 파이썬 개념 정리
1) 기본 통계 데이터 계산
- 평균 계산하기
total = 0
count = 0
while True:
num = input()
if num == "":
break
else:
try:
total += int(num)
count += 1
except ValueError:
#Value error 일 때도 count += 1이 실행됨..
# => count를 total보다 위에 써서 count 가 먼저 실행되고 total이 실행됨
# 그 시점에서 except가 걸리기 때문에 count는 올라가고 total은 실행되지 않음!
print("숫자를 입력해주세요")
print("average: ", total/count)
print(total, count)- 리스트와 배열
- 파이썬 리스트의 특성
- 임의의 데이터 타입을 담을 수 있는 가변적 연속열(Sequence)형
- 파이썬 리스트는 동적 배열(Dynamic Array)
- 리스트이지만 array로 구현됨(= element들이 연속된 메모리 공간에 배치되도록 구현됨)
- list와 array의 차이
- list: 공간이 미리 정해져 있지 않아 삭제, 추가에 용이함
- array
- array(typecode, initializer)의 형태- type code
- 공간이 미리 정해져 있어 특정 값을 추가할 때 값을 저장할 공간을 먼저 추가한 뒤 그 공간에 값을 저장해야함
- 모든 원소가 같은 자료형이어야 함
2) NumPy
- NumPy 장점
- 빠르고 메모리를 효율적으로 사용하
- 벡터의 산술 연산과 브로드캐스팅 연산을 지원하는 다차원 배열 ndarray 데이터 타입을 지원
- 반복문을 작성할 필요 없이 전체 데이터 배열에 대해 빠른 연산을 제공하는 다양한 표준 수학 함수를 제공
- 배열 데이터를 디스크에 쓰거나 읽을 수 있다. (= 파일로 저장)
- 선형대수, 난수발생기, 푸리에 변환 가능, C/C++ 포트란으로 쓰여진 코드를 통합
- NumPy 사용법
- array 생성
a = np.arange(5)
b = np.array([0,1,2,3,4])
>>>[0 1 2 3 4]
>>>[0 1 2 3 4]문자열이 하나만 들어가도 나머지 자료형이 다 문자열로 바뀐다. 그 이유는 문자를 모두 숫자로 바꿀 순 없지만 숫자는 모두 문자로 바꿀 수 있기 때문이다.
- 크기
- ndarray.size: 원소의 개수
- ndarray.shape: 행렬의 모양
- ndim: 행렬의 축의 개수
+) reshape: 행렬의 모양을 바꿔줌, 행렬의 모양이 변하기 전과 후의 크기는 모두 같아야함.
A = np.arange(10).reshape(2, 5)
# 길이 10의 1차원 행렬을 2X5 2차원 행렬로 바꿈.
print("행렬의 모양:", A.shape)
print("행렬의 축 개수:", A.ndim)
print("행렬 내 원소의 개수:", A.size)
>>> 행렬의 모양: (2, 5)
>>> 행렬의 축 개수: 2
>>> 행렬 내 원소의 개수: 10- type
- numpy.array.dtype
- numpy ndarray의 원소의 데이터 타입을 반환
- array 안에 dtype을 직접 설정해서 오류를 방지할 수 있음
- type
- 행렬 자체의 자료형 반환
- numpy.array.dtype
- 특수 행렬
- 단위행렬
np.eye(3)
>>> array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])- 0 행렬
np.zeros([2,3])
>>> array([[0., 0., 0.],
[0., 0., 0.]])- 1 행렬
np.ones([3,3])
>>> array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])-
브로드캐스트
ndarray와 상수, 또는 서로 크기가 다른 ndarray끼리 산술연산이 가능한 기능list 연산과의 차이
# list 연산
print([1,2]+[3,4])
print([1,2]+3)
>>> [1,2,3,4]
>>> error
# Numpy 연산
print(np.array([1,2])+np.array([3,4]))
print(np.array([1,2])+3)
>>> [4 6]
>>> [4 5]- 전치행렬
A = np.arange(24).reshape(4,6)
print("A:", A)
print("A의 전치행렬:", A.T)
print("A의 전치행렬의 shape:", A.T.shape)
>>> A: [[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]
>>> A의 전치행렬: [[ 0 6 12 18]
[ 1 7 13 19]
[ 2 8 14 20]
[ 3 9 15 21]
[ 4 10 16 22]
[ 5 11 17 23]]
>>> A의 전치행렬의 shape: (6, 4)3차원 이해 안돼서 일단 넘김
3. NumPy로 기본 통계 데이터 계산해 보기
- array.sum(): 합
- array.mean(): 평균값
- array.std(): 표준편차
- np.median(array): 중앙값
3) 데이터의 행렬 변환
- 데이터의 행렬 변환
참고
- 소리데이터
1차원 array로 표현한다. CD음원파일의 경우, 44.1kHz의 샘플링 레이트로 -32767 ~ 32768의 정수 값을 갖는다. - 흑백 이미지
이미지 사이즈의 세로X 가로 형태의 행렬(2차원 ndarray)로 나타내고, 각 원소는 픽셀별로 명도(grayscale)를 0~255 의 숫자로 환산하여 표시한다. 0은 검정, 255는 흰색이다. - 컬러 이미지
이미지 사이즈의 세로 X 가로x3 형태의 3차원 행렬이다. 3은 Red, Green, Blue계열의 3 색을 의미한다. - 자연어
임베딩(Embedding)이라는 과정을 거쳐 ndarray로 표현될 수 있다. 블로그의 예시에서는 71,290개의 단어가 들어있는 (문장들로 이루어진) 데이터셋이 있을때, 이를 단어별로 나누고 0 - 71,289로 넘버링했다. 이를 토큰화 과정이라고 한다. 이 토큰을 50차원의 word2vec embedding 을 통해 [batch_size, sequence_length, embedding_size]의 ndarray로 표현할 수 있다.
- 이미지의 행렬 변환
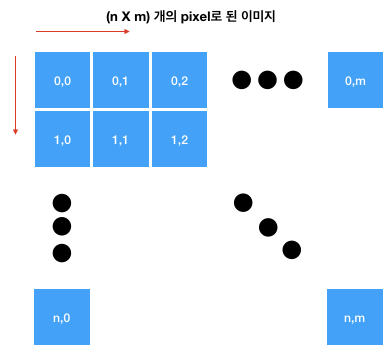
- 사용하는 라이브러리
- matplotlib
- PIL
4) 구조화된 데이터란?
- 구조화된 데이터란?
- 데이터 내부에 자체적인 서브 구조를 가지는 데이터
5) 구조화된 데이터와 Pandas
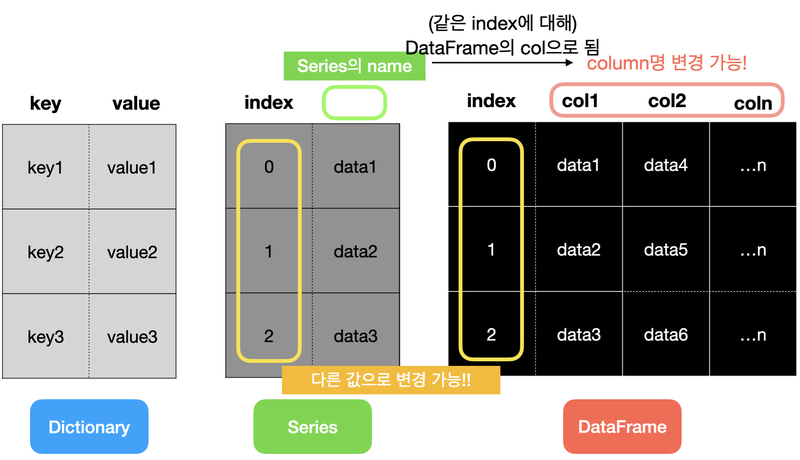
1. Series
- 일련의 객체를 담을 수 있는 1차원 배열과 비슷한 자료구조
- index와 value 존재
- index는 인자로 넣어주는 방식, 혹은 할당 연산자로 따로 지정해줄 수 있음
- series.index
- RangeIndex: 초기 인덱스
- Index: 문자열로 인덱스를 업데이트 했을 때
- int64Index: 정수로 업데이트 했을 때
- series.index
- 딕셔너리 활용
- name
DataFrame의 column명에 해당
- DataFrame
- 표와 같은 구조, 여러 개의 column 가짐
- index는 행의 이름, colums는 열의 이름
6) Pandas와 함께 EDA 시작하기
- EDA(Exploratory Data Analysis, 데이터 탐색)
- head
첫 번째 5행 출력, ()안에 출력할 행의 수 설정 가능 - tail
마지막 5행 출력, ()안에 출력할 행의 수 설정 가능 - info
각 컬럼 별로 null 값과 자료형을 보여줌 - describe()
기본적인 통계 데이터 보여줌 - isnull().sum()
결측값을 확인하고 그 총합을 알려줌
7) 언패킹
- 언패킹
- 함수(*리스트 /튜플) ⇒ 인자가 순서대로 출력됨
- 함수(**딕셔너리)
- 키워드에 해당하는 키는 문자열 형태여야 함
- 가변인수 함수를 만들 때 사용 가능
- *arg, *kwarg(키워드 인수를 사용하는 가변 인수)
- 고정인수와 가변인수는 함께 사용 가능하지만, 가변인수가 뒤에 와야함
- 가변인수에 여러 개의 값이 입력되었을 때 가변인수를 return 하면 튜플로 반환됨
8) 문자열 포매팅
%d는 %와 d 사이에 0과 숫자 개수를 넣어주면 자릿수에 맞춰서 앞에 0이 들어감. 예를 들어 %03d로 지정하면 1은 '001', 35는 '035'가 된다. { }를 사용할 때는 인덱스나 이름 뒤에 :(콜론)를 붙이고 03d처럼 0과 숫자 개수를 지정하면 된다.
- '%0개수d' % 숫자
- '{인덱스:0개수d'}'.format(숫자)
'%03d' % 1
>>> '001'
'{0:03d}'.format(35)
>>> '035'2. 회고
5일만에(코딩 공부만으론 4일) 이렇게 내용이 어려워질 줄은 몰랐다. 클래스를 아직 배우지 않았는데 언급돼서 당황했다. 그래도 항상 검색만 하면서 사용했던 것들을 다시 한 번 정리할 수 있어 좋았다. 3차원 배열에서 전치행렬이 잘 이해가 안되어 일단 넘겼으니까 다음에 공부할 때 좀 더 면밀히 살펴보는 것이 좋을 듯 하다.

🐬 파이썬 / 인공지능 / 머신러닝