1.딥러닝 실습
1) 텐서플로우 이용해 이미지 불러오기
1. train, validation, test set 분리
(raw_train, raw_validation, raw_test), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)데이터의 형태:
<PrefetchDataset shapes: ((None, None, 3), ()), types: (tf.uint8, tf.int64)>
<PrefetchDataset shapes: ((None, None, 3), ()), types: (tf.uint8, tf.int64)>
<PrefetchDataset shapes: ((None, None, 3), ()), types: (tf.uint8, tf.int64)>- (image, label)의 형태
- image: (None, None, 3) - (height, width, channel)
- None으로 나오는 이유: 이미지마다 크기가 다르기 때문에, 정해진 것이 없다는 의미
- channel: rgb 의미. 흑백의 경우 채널은 1개
- image: (None, None, 3) - (height, width, channel)
✔✔✔🤔
- %matplotlib inline : rich output(이미지, 동영상 등)을 별다른 함수 없이 바로 보여줌
- %config InlineBackend.figure_format = 'retina': 그래프를 더 높은 해상도로 출력해줌
2) 데이터 전처리
- 메타데이터의 label column을 가져온다.
get_label_name = metadata.features['label'].int2str- 데이터에 라벨이 알맞게 짝지어졌는지 확인한다.
for idx, (image, label) in enumerate(raw_train.take(10)): # 10개의 데이터를 가져 옵니다.
plt.subplot(2, 5, idx+1)
plt.imshow(image)
plt.title(f'label {label}: {get_label_name(label)}')
plt.axis('off') # axis 제거- 이미지 크기 조정
✔✔✔🤔
타입캐스팅(Type Casting): 형변환. ex) int ⇒ float
# 타입캐스팅의 텐서플로우 버전
image = tf.cast(image, tf.float32)
#픽셀 크기 -1~1 사이 값으로 수정
image = (image/127.5) - 1이렇게 raw_train, raw_test, raw_validation을 변환한 값은 각각 train, test, validation에 저장.
3) 모델 생성
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, MaxPooling2D- models: 모델 그 자체를 구축하기 위한 함수들을 포함
- layers: 모델의 구성 요소인 여러 가지 종류의 레이어(layer)라는 함수들을 가짐
model = Sequential([
Conv2D(filters=16, kernel_size=3, padding='same', activation='relu', input_shape=(160, 160, 3)),
MaxPooling2D(),
Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'),
MaxPooling2D(),
Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'),
MaxPooling2D(),
Flatten(),
Dense(units=512, activation='relu'),
Dense(units=2, activation='softmax')
])- MaxPooling2D()
폴링 계층 중 하나- 이미지 크기를 줄이면서 생기는 손실을 막기 위해 사용
- 합성곱 계층의 과적합을 피하기 위해 사용
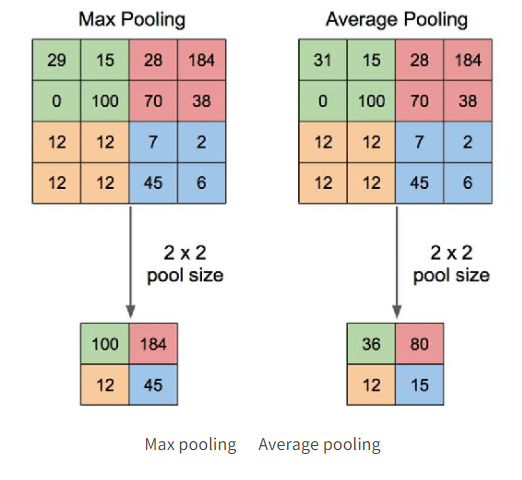
사진 출처
Max pooling은 4*4 그림이 있을 때 그 그림을 2*2 씩 4개 부분으로 나눈 후 2*2 영역 안에 있는 수 중 가장 큰 수를 고르는 방법이다. 반면 Average pooling은 2*2 안에 있는 숫자의 평균을 구한다.
model.summary()결과
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 160, 160, 16) 448
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 80, 80, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 80, 80, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 40, 40, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 40, 40, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 20, 20, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 25600) 0
_________________________________________________________________
dense (Dense) (None, 512) 13107712
_________________________________________________________________
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 13,132,322
Trainable params: 13,132,322
Non-trainable params: 0
_________________________________________________________________-
(160, 160, 3) 크기의 이미지가 모델에 입력된 후 각 레이어를 지나면서 그 이미지의 사이즈가 어떻게 변화하는지 보여줌. height, width는 점점 작아지고 channel은 늘어나고 있음을 알 수 있다.
-
None: 정해지지 않았단 의미. batch의 크기에 따라 달라질 수 있는 수
✔✔✔🤔
출처
배치는 모델의 가중치를 한번 업데이트시킬 때 사용되는 샘플들의 묶음을 의미합니다. 만약에 총 1000개의 훈련 샘플이 있는데, 배치 사이즈가 20이라면 20개의 샘플 단위마다 모델의 가중치를 한번씩 업데이트시킵니다. 그러니까 총 50번(=1000/20) 가중치가 업데이트되겠죠. 하나의 데이터셋을 총 50개의 배치로 나눠서 훈련을 진행했다고 보면 됩니다. -
flatten: 3차원 이미지를 1차원으로 펼치는 과정
-
dense: 512개의 노드로 축소. 다음 단계인 최종 출력은 두 개의 숫자로 구성된 하나의 확률분포를 출력
요약
딥러닝 모델은 (160, 160, 3) 크기의 3차원 이미지를 입력받아 여러 레이어를 거치며 형태를 바꾸다가 최종적으로는 몇 개의 숫자를 출력해내는 함수
4) 모델 compile 및 fit
learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'])
print("슝~")- complie: 모델 학습을 위해 학습 과정을 설정하는 단계
- optimizer: 학습을 어떤 방식으로 시킬 것인지 결정
- loss: 모델이 학습해나가야 하는 방향을 결정
- metrics: 모델의 성능을 평가하는 척도(정확도(accuracy), 정밀도(precision), 재현율(recall))
history = model.fit(train_batches,
epochs=EPOCHS,
validation_data=validation_batches)- 결과로 나오는 accuracy, val_accuracy: accuracy는 훈련 데이터에 대한 것. val_accuracy는 validation set에 대한 것임.
- training accuracy는 10 epoch를 진행하는 동안 꾸준히 증가함.
- 해당 모델에서 validation accuracy는 초반에 75%~80% 사이까지는 증가하지만 증가폭이 training dataset에 비해 매우 작고, 증가하는 양상도 불안정
- training accuracy는 현재 학습하는 데이터셋에 대한 정확도이기 때문에 모델의 구조나 데이터셋 등에 문제가 없다면 일반적으로 학습하면 할수록 꾸준히 계속 오른다. 반면 validation accuracy는 학습하지 않은 데이터셋에 대한 정확도이기 때문에 일정수준까지 오른 후에는 오를지 장담 불가
✔✔✔🤔 과적합(Overfitting, 오버피팅)
모델의 성능이 제대로 올라가려면 training set 외에서도 성능이 좋아야 하는데, training set만으로 계속 학습하다 보니 그 데이터에만 과도하게 적합(fitting) 되어서 일반화 능력이 떨어지게 되는 것
✔✔✔🤔 zip 예시
numbers = [1, 2, 3] letters = ["A", "B", "C"] for pair in zip(numbers, letters): print(pair) . >>> (1, 'A') >>> (2, 'B') >>> (3, 'C')
5) transfering
컴퓨터 비전에서의 전이학습
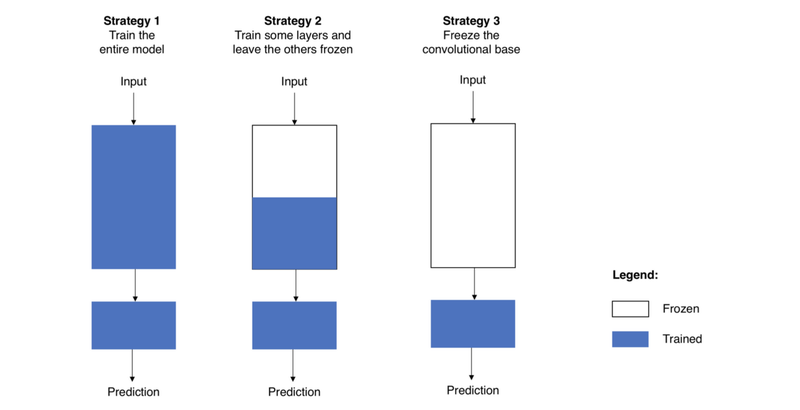
⇖ 세 가지 전략
이미 학습된 모델을 활용하는 것
사전 학습된 모델
본인이 풀고자 하는 모델과 비슷하면서 더 많은 양의 데이터로 학습한 모델
CNN
- Convolutional base: 합성곱층과 풀링층이 여러겹 쌓여있는 부분, 이미지로부터 특징을 효과적으로 추출(feature extraction)
- 낮은 레벨의 계층은 input에 가까운 계층. 이미지에서 주로 일반적인(general) 특징을 추출한다.
- 높은 레벨의 계층은 output에 가까운 계층으로, 보다 구체적이고 특유한 특징을 추출한다.
- Classifier: 주로 완전 연결 계층 (fully connected layer, 모든 계층의 뉴런이 이전 층의 출력 노드와 하나도 빠짐없이 모두 연결되어 있는 층, 반드시 1차원)로 이루어짐. 추출된 특징을 잘 학습해서 이미지를 알맞은 카테고리로 분류
Transfering
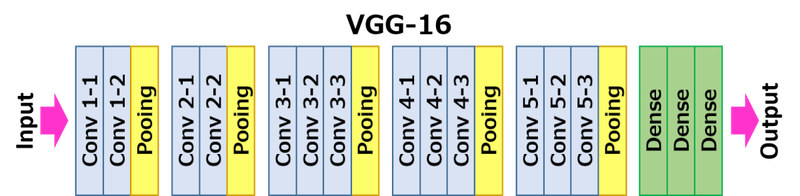
뒤의 Dense 부분은 cutomizing을 위해 쓰지 않음
- Global Average Pooling: 2, 3차원을 1차원으로 변환하는 방법. flatten 보다 나음
6) tf_flower 실습
오류
Received a label value of 4 which is outside the valid range of [0, 2)
prediction_layer = tf.keras.layers.Dense(5, activation='softmax')Dense의 인자를 제대로 설정하지 않아서 생긴 문제. 5개로 분류해야하는데 2를 넘겨줘서 오류남
2. 혼공머 정리
✔✔✔🤔 과대적합 / 과소적합
- 과대적합: 훈련세트에서 점수가 굉장히 좋았는데 테스트 세트에서 점수가 굉장히 나쁠 경우. 모델을 덜 복잡하게 만들어야 함.
- 과소적합: 훈련 세트보다 테스트 세트의 점수가 높거나 두 점수가 모두 너무 낮은 경우, 모델이 너무 단순해서 적절한 훈련이 이뤄지지 않은 경우
✔✔✔🤔 모델 기반 학습 / 사례 기반 학습
- 모델 기반 학습: 머신러닝 알고리즘이 최적의 모델 파라미터를 찾아가는 과정
- 사례 기반 학습: 모델 파라미터 없이 훈련 세트를 저장만 하는 경우
1) 회귀
- 지도학습의 일종
- 정해진 클래스 없음. 임의의 수치를 출력
✔✔✔🤔 회귀와 비지도 학습
- 정답을 통해 학습하여 숫자형 데이터를 출력하는 문제가 회귀 (분류는 범주형 데이터를 예측하는 문제)
- 비지도 학습은 정답을 예측하는 것이 아니라 주어진 데이터의 특성을 찾는 것
- 결정계수

- 예측이 타깃에 가까워질 수록 1에 가까워짐
2) k-최근접 이웃 회귀
- 원리
- k 최근접 이웃과 동일하게 k개의 이웃을 참고함. 이 참고한 값을 기반으로 수치를 예측함.
- 이웃 수에 따른 특징
- 이웃의 개수를 줄이면 훈련 세트에 있는 국지적인 패턴에 민감해짐
- 이웃의 개수를 늘리면 데이터 전반에 있는 일반적인 패턴을 따를 것
- 과대적합일 경우 해결책이 될 수 있음
- 한계
새로운 샘플이 training set의 범위를 벗어날 경우 올바른 값을 예측하지 못함
3) 선형 회귀
- 의미
특성이 하나인 경우 특성을 가장 잘 나타내는 직선을 학습하는 알고리즘. - 기울기, y 절편
lr.coef_
lr.intercept_4) 다항 회귀
- 의미
다항식을 사용한 선형 회귀
x^n 을 하나의 변수로 볼 수 있기 때문에 선형 회귀라고 할 수 있음
5) 다중 회귀
- 의미
여러 개의 특성을 사용한 선형 회귀
ex) 특성이 2개면 선형 회귀는 평면을 학습함
✔✔✔🤔 특성 공학
각 특성을 서로 곱해서 또 다른 특성을 만드는 식으로, 기존의 특성을 사용해서 새로운 특성을 뽑아내는 작업을 특성 공학(feature engineering)이라고 한다.
✔✔✔🤔 변환기
사이킷런에서 특성을 만들거나 전처리하기 위한 다양한 클래스를 제공하는데, 이를 변환기라고 칭함. 타깃 데이터 없이 입력 데이터를 변환함.
-
문제
특성의 수를 늘리면 과대 적합이 일어날 가능성이 커짐. -
규제
과대 적합을 막는 방법
선형 회귀 모델의 경우 특성에 곱해지는 계수의 크기를 작게 만듦
6) 릿지 회귀
- 선형 회귀에 규제를 추가한 모델
- 계수를 제곱한 값을 기준으로 규제를 적용
- 일반적으로 라쏘보다 선호
7) 라쏘 회귀
- 계수의 절대값을 기준으로 규제를 적용
✔✔✔🤔 하이퍼파라미터
머신러닝 알고리즘이 학습하지 않는 파라미터. 사용자가 사전에 지정해야함. 릿지, 라쏘의 규제 강도인 alpha를 예로 들 수 있음.
3. 회고
학습대상이 갑자기 텐서플로우를 다뤄본 적 있는 사람이라고 해서 다뤄본 적 없지 않나? 했는데 생각해보니까 가위바위보 분류기에서 한 번 해본 거였다.. 하면서 이해가 잘 될까 싶었는데 그래도 앞에서 뜻까지 알려주진 않더라도 코드 한 번 봐본 것만으로 읽는게 완전히 낯설게 느껴지진 않았다. 역시 너무 매달리기보단 수용할 수 있는 만큼만 하고, 좀 더 익숙해졌을 때 깊게 공부하는 방식이 내겐 더 맞는 거 같다.
6개월 안에 배우는 만큼 진도가 빠르다. 한 번 놓치면 밑도 끝도 없이 쌓일 거 같아서 최대한 그날 다 끝내려고 한다. 그래도 아직은 감당할 만해서 다행이라고 생각한다.
