리눅스 명령어
- pip list | grep 모듈명
- 모듈명이 들어가는 모든 행을 찾아줌
1. 파이썬 개념정리
파이썬 코딩도장 내용을 읽고 정리한 부분입니다.
1) 클래스 상속
- 물려받은 기능을 유지한 채로 다른 기능을 추가할 때 사용
- 기존 기능을 재활용할 수 있어 효율적
- 연관되면서 동등한 기능을 할 경우 사용 (is-a 관계)
cf) 포함관계
has-a 관계, 동등한 관계가 아니라 한 쪽이 다른 한 쪽에 속하는 관계
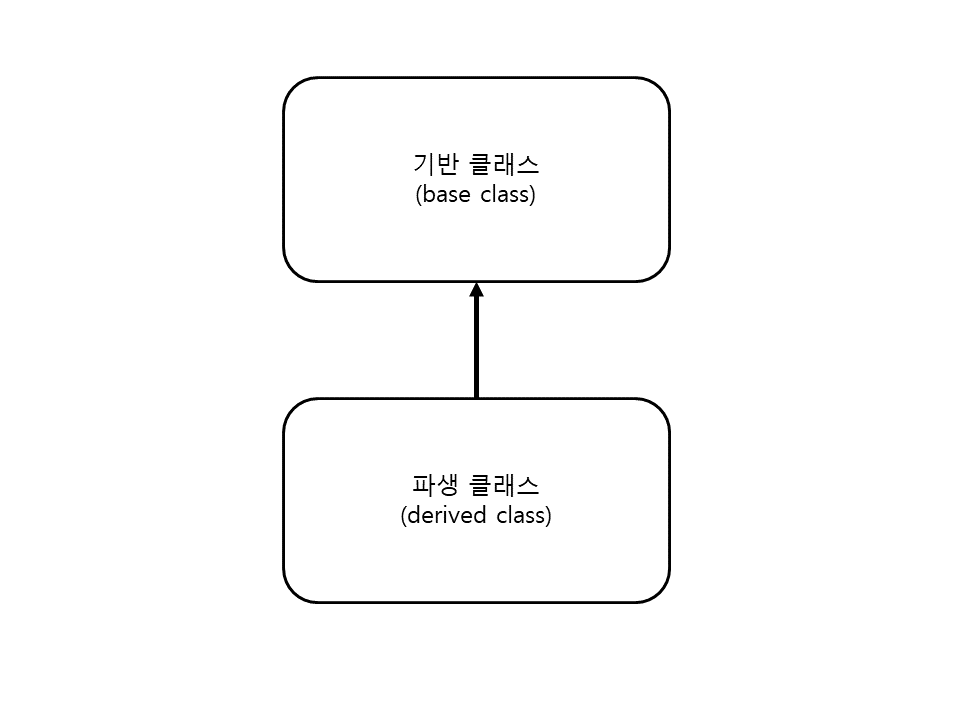
- 파생 클래스: 상속을 받아 새롭게 만드는 클래스 = 자식 클래스, 서브 클래스
- 기반 클래스: 기능을 물려주는 클래스 = 부모 클래스, 슈퍼 클래스
class 기반클래스이름:
코드
class 파생클래스이름(기반클래스이름):
코드
issubclass(파생클래스, 기반클래스)
>>> True
>>> False
class Person:
def __init__(self):
print('Person __init__')
self.hello = '안녕하세요.'
class Student(Person):
def __init__(self):
print('Student __init__')
super().__init__() # super()로 기반 클래스의 __init__ 메서드 호출
self.school = '파이썬 코딩 도장'
james = Student()
print(james.school)
print(james.hello)super.__init__()이 없는 경우- Person의 init 메소드가 호출되지 않았기 때문에 print(james.hello) 부분에서 오류가 남
super.__init__()을 사용 안해도 되는 경우- 파생 클래스에서
__init__메소드를 생략한 경우
- 파생 클래스에서
- 좀 더 명확하게 super 사용하는 방법
super(파생클래스, self).메서드
2) 오버라이딩
- 무시하다, 우선하다 => 기반 클래스의 메서드를 무시하고 새로운 매서드를 만듦
class Person:
def greeting(self):
print('안녕하세요.')
class Student(Person):
def greeting(self):
super().greeting() # 기반 클래스의 메서드 호출하여 중복을 줄임
print('저는 파이썬 코딩 도장 학생입니다.')
james = Student()
james.greeting()
>>> 안녕하세요.
>>> 저는 파이썬 코딩 도장 학생입니다. - 원래 기능을 유지하면서 새로운 기능을 덧붙일 때 활용
3) 다중 상속
class 기반클래스이름1:
코드
class 기반클래스이름2:
코드
class 파생클래스이름(기반클래스이름1, 기반클래스이름2):
코드- 클래스를 만들 때 괄호 안에 클래스 이름을 콤마로 구분해서 넣음
4) 추상 클래스
- 인스턴스로 만들지 않고 오직 상속에만 사용
from abc import *
class 추상클래스이름(metaclass=ABCMeta):
@abstractmethod
def 메서드이름(self):
코드5) 모듈과 패키지
- 모듈
- 각종 변수, 함수, 클래스를 담아 .py 파일 단위로 작성한 것
- 생성 방법: 원하는 변수/함수/클래스 등을 작성해 py 파일로 저장. 파일 이름이 모듈이 됨
import 모듈
import 모듈 as 원하는 이름
from 모듈 import 변수, 함수, 클래스 #여러 개 가지고 올 때 콤마로 구분
from 모듈 import 변수(함수, 클래스) as 이름- 패키지
- 특정 기능과 관련한 여러 모듈을 묶은 것
- 생성 방법: 폴더를 만들고 그 안에
__init__.py파일을 생성하면 해당 폴더가 패키지로 인식됨. 3.3 버전 이상부터는 없어도 되지만 하위버전과의 호환을 위해 생성을 권장.
import 패키지.모듈
import 패키지.모듈1, 패키지.모듈2
import 패키지.모듈 as 이름
import 패키지.모듈 import 변수
import 패키지.모듈 import 변수(함수, 클래스) as 이름
2. 데이터 시각화
목표
- 여러 가지 그래프 그리기
- 탐색적 데이터 분석
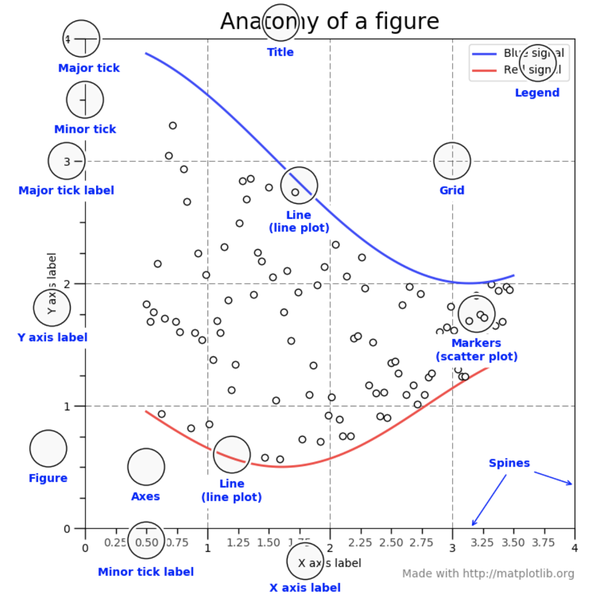
요소 별 명칭
1) 막대 그래프
# 축 그리기
fig = plt.figure() # 축 없는 그래프 객체 생성
ax1 = fig.add_subplot(1,1,1)- figure()
- figsize라는 parameter로 크기 지정 가능
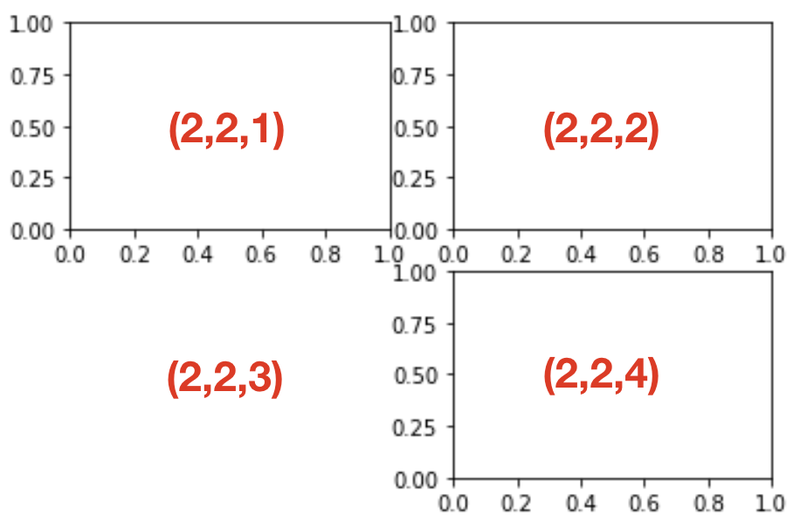
- fig.add_subplot(a, b, c)
- a(행) * b(열)의 subplot 생성
- a*b개의 subplot 중 c 번째를 보여줌
ex) fig.add_subplot(2,2,n)의 경우
ax1.bar(x, y)- x축과 y축을 리스트 형태로 만든 후 bar의 인자로 입력
+) %matplotlib inline
rich output, 즉 소리, 그림(그래프 포함), 애니메이션과 같은 결과물을 jupyter notebook과 같은 환경에서 바로 출력할 수 있게 해주는 매직 메소드
참고
3) 선 그래프
(1) 축 그리기 및 좌표축 설정
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
price.plot(ax=ax, style='black')
plt.ylim([1600,2200])
plt.xlim(['2019-05-01','2020-03-01'])- ylim: y축 범위
- xlim: x축 범위
(2) 주석달기
# 주석달기
important_data = [(datetime(2019, 6, 3), "Low Price"),(datetime(2020, 2, 19), "Peak Price")]
for d, label in important_data:
ax.annotate(label, xy=(d, price.asof(d)+10), # 주석을 달 좌표(x,y)
xytext=(d,price.asof(d)+100), # 주석 텍스트가 위차할 좌표(x,y)
arrowprops=dict(facecolor='red')) # 화살표 추가 및 색 설정- annotate()
- grid()
(3) 라인 스타일
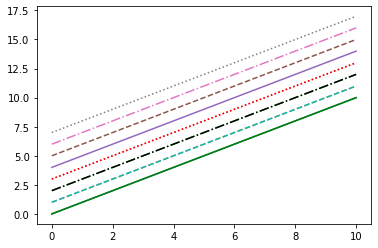
x = np.linspace(0, 10, 100) # 1부터 100까지 균등하게 생성
plt.plot(x, x + 0, linestyle='solid')
plt.plot(x, x + 1, linestyle='dashed')
plt.plot(x, x + 2, linestyle='dashdot')
plt.plot(x, x + 3, linestyle='dotted')
plt.plot(x, x + 0, '-g') # solid green
plt.plot(x, x + 1, '--c') # dashed cyan
plt.plot(x, x + 2, '-.k') # dashdot black
plt.plot(x, x + 3, ':r'); # dotted red
plt.plot(x, x + 4, linestyle='-') # solid
plt.plot(x, x + 5, linestyle='--') # dashed
plt.plot(x, x + 6, linestyle='-.') # dashdot
plt.plot(x, x + 7, linestyle=':'); # dotted- plot(x, y, linestyle='원하는 옵션')
(4) pandas.plot 메소드 인자
1. ax: 그래프를 그릴 matplotlib의 서브플롯 객체.
2. alpha: 투명도 (0 ~1)
3. kind: 그래프의 종류: line, bar, barh(90도 꺾임), kde
4. logy: Y축에 대한 로그 스케일
5. use_index: 객체의 색인을 눈금 이름으로 사용할지의 여부
6. rot: 눈금 이름을 로테이션(0 ~ 360)
7. xticks, yticks: x축, y축으로 사용할 값
8. grid: 축의 그리드 표시할지 여부
(5) pandas의 data가 DataFrame 일 때 plot 메서드 인자
1. subplots: 각 DataFrame의 칼럼을 독립된 서브플롯에 그린다.
2. sharex: subplots=True 면 같은 X 축을 공유하고 눈금과 한계를 연결한다.
3. sharey: subplots=True 면 같은 Y 축을 공유한다.
4. figsize: 그래프의 크기, 튜플로 지정
5. title: 그래프의 제목을 문자열로 지정
6. sort_columns: 칼럼을 알파벳 순서로 그린다.
4) 실습
- 범주형 데이터: 주로 막대 그래프를 이용해 나타냄
pandas, matplotlib 이용
grouped = df['tip'].groupby(df['sex'])
- tip이라는 컬럼을 성별을 기준으로 정리. grouped에는 성별 그룹에 대한 평균, 총합 등의 정보가 저장됨
- 이렇게 저장된 값을 dict 형태로 변환한 뒤 key, value 값을 각각 x축과 y축 값으로 활용하면 됨
Seaborn과 matplotlib 이용
sns.barplot(data=df, x='sex', y='tip') # 성별에 대한 팁 평균 확인 가능
✔✔✔🤔
plt.figure(figsize=(10,6)) # 도화지 사이즈를 정합니다. sns.barplot(data=df, x='sex', y='tip') plt.ylim(0, 4) # y값의 범위를 정합니다. plt.title('Tip by sex') # 그래프 제목을 정합니다.plt와 sns는 서로를 어떻게 인식해서 같이 쓸 수 있는걸까?
- 수치형 데이터
- 산점도
- 선그래프
sns.lineplot(x=x, y=np.sin(x))
sns.lineplot(x=x, y=np.cos(x))- 히스토그램: 도수분포표를 그래프로 나타낸 것
5) Heatmap
- 방대한 양의 데이터와 현상을 수치에 따른 색상으로 나타낸 것
- 데이터 차원에 대한 제한은 없음. 다만 모두 2차원으로 시각화해서 표현
💥 pivot() 함수
축, 점을 기준으로 바꾼다는 의미. 데이터 표를 재배치할 때 사용
3. 회고
오늘은 빨리 마감한다. 왜냐하면 어제 저녁에 백신을 맞았는데 괜찮은 거 같다가도 상태가 영 안좋아서.. 잡은 김에 끝내놓으려고 집중해서 정리하는데 그만큼 머리가 더 아파진 것 같다. 그나마 LMS 내용이 어제보다 쉬워서 다행이었다. 사실 다 기억 못하고 찾으면서 할 거 같아서 이전보다 태그를 좀 더 자세히 써놨다. 자꾸 나중으로 미뤄버리는 거 같은데.. 주말에 복습을 해야겠다.
