JOIN
1) JOIN
- RDB에서 2개 이상의 테이블 혹은 DB를 넘나들며 데이터를 검색하는 방법
- 여러 테이블을 하나의 테이블 처럼 활용하기 위함
- 주로 Primary key, foreign key 활용
- 최소한 하나의 컬럼은 공유되고 있어야 join 사용 가능
2) 테이블 예시
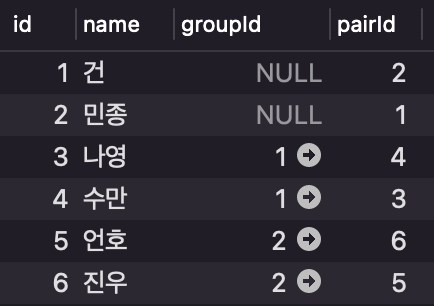
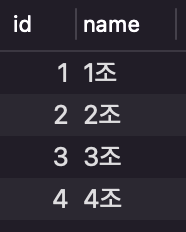
- 위 테이블을 이용해 join 결과들을 보여주려 한다.
3) 종류
Inner Join
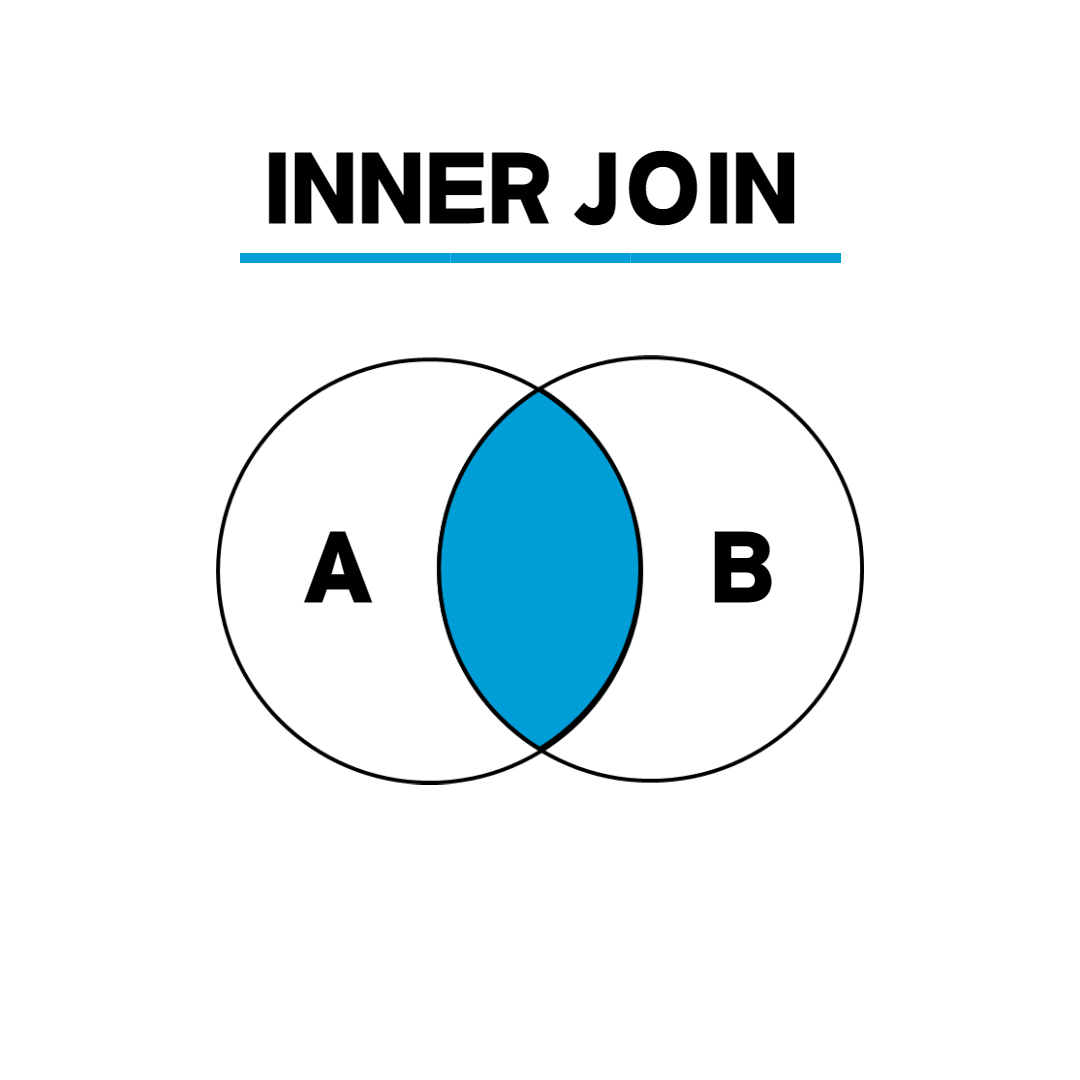
조인 조건에 부합하는 결과만을 확인할 때 사용한다.
SELECT <열 목록>
FROM <기준 테이블>
INNER JOIN <조인 테이블>
ON <조인될 조건>
[WHERE 검색 조건]- 기준 테이블과 조인 테이블에 공통적으로 존재하는 컬럼을 가지고서 결합하는 조인
예시
SELECT *
FROM user as l
INNER JOIN groupTable as r
ON l.groupId = r.id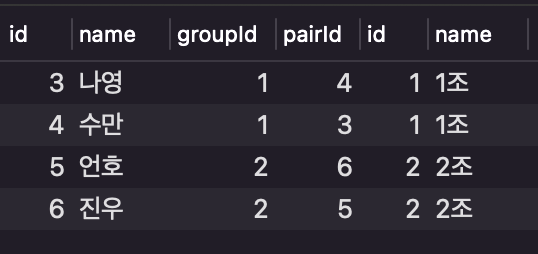
Outer Join
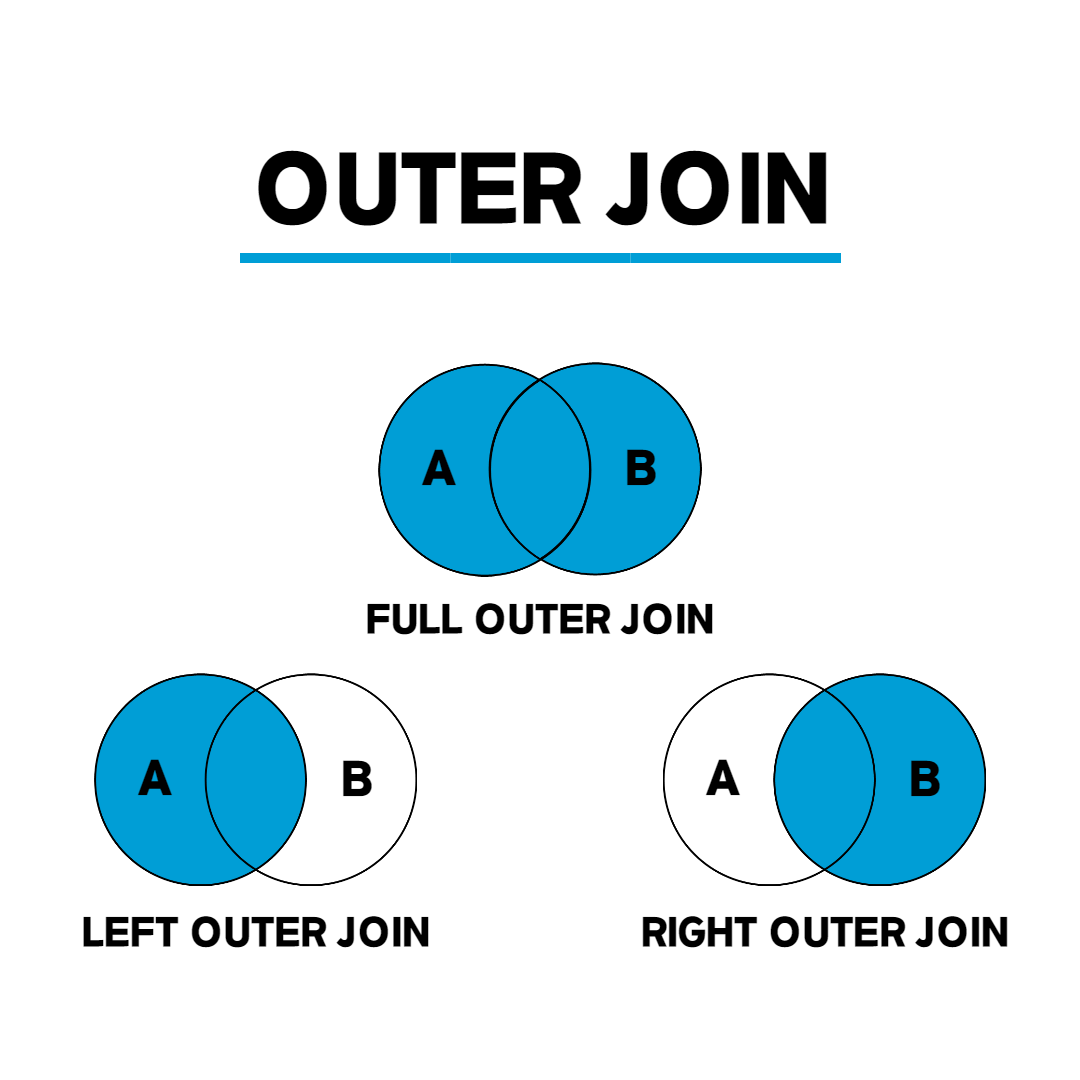
기준 테이블의 조회 결과와 함께 조인 조건에 부합하는 조인 테이블 데이터를 확인할 때 사용한다.
SELECT <열 목록>
FROM <LEFT 테이블>
<LEFT | RIGHT | FULL> OUTER JOIN <RIGHT 테이블>
ON <조인될 조건>
[WHERE 검색 조건]- 기준 테이블의 결과를 출력하게 된다.
- LEFT/RIGHT/FULL로 기준 테이블을 지정한다.
- LEFT의 경우 FROM 예약어 후에 오는 테이블이 기준 테이블이 된다.
- RIGHT의 경우 JOIN 예약어 후에 오는 테이블이 기준 테이블이 된다.
- LEFT & RIGHT이다. 모든 테이블의 값이 출력된다.
- 기준 테이블의 결과를 모두 출력하고, 조인 조건에 해당하는 Row들을 조인 테이블에서 가져온다. 이 때 조건에 부합하는 데이터가 없는 경우 NULL로 채워넣어 출력한다.
- mysql의 경우 FULL OUTER JOIN이 존재하지 않아, LEFT OUTER JOIN, RIGHT OUTER JOIN을 합쳐야한다.
예시 - Left Outer Join
SELECT *
FROM user as l
LEFT OUTER JOIN groupTable as r
ON l.groupId = r.id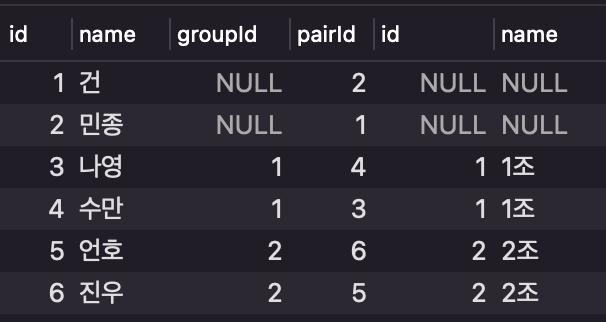
예시- Right Outer Join
SELECT *
FROM user as l
RIGHT OUTER JOIN groupTable as r
ON l.groupId = r.id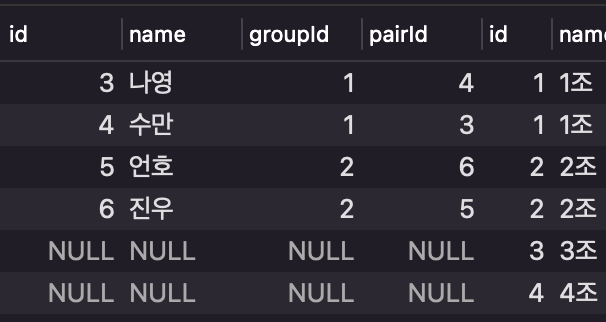
예시 - Full Outer Join
SELECT *
FROM user as l
LEFT OUTER JOIN groupTable as r
ON l.groupId = r.id
UNION DISTINCT
SELECT *
FROM user as l
RIGHT OUTER JOIN groupTable as r
ON l.groupId = r.id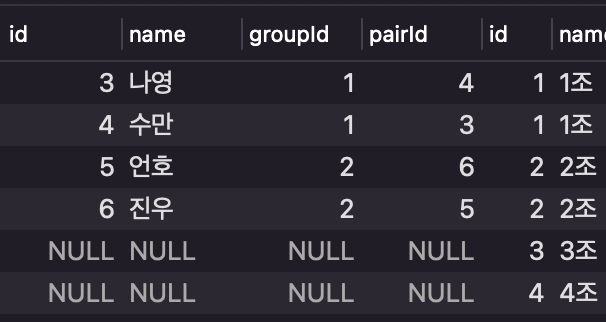
Cross Join
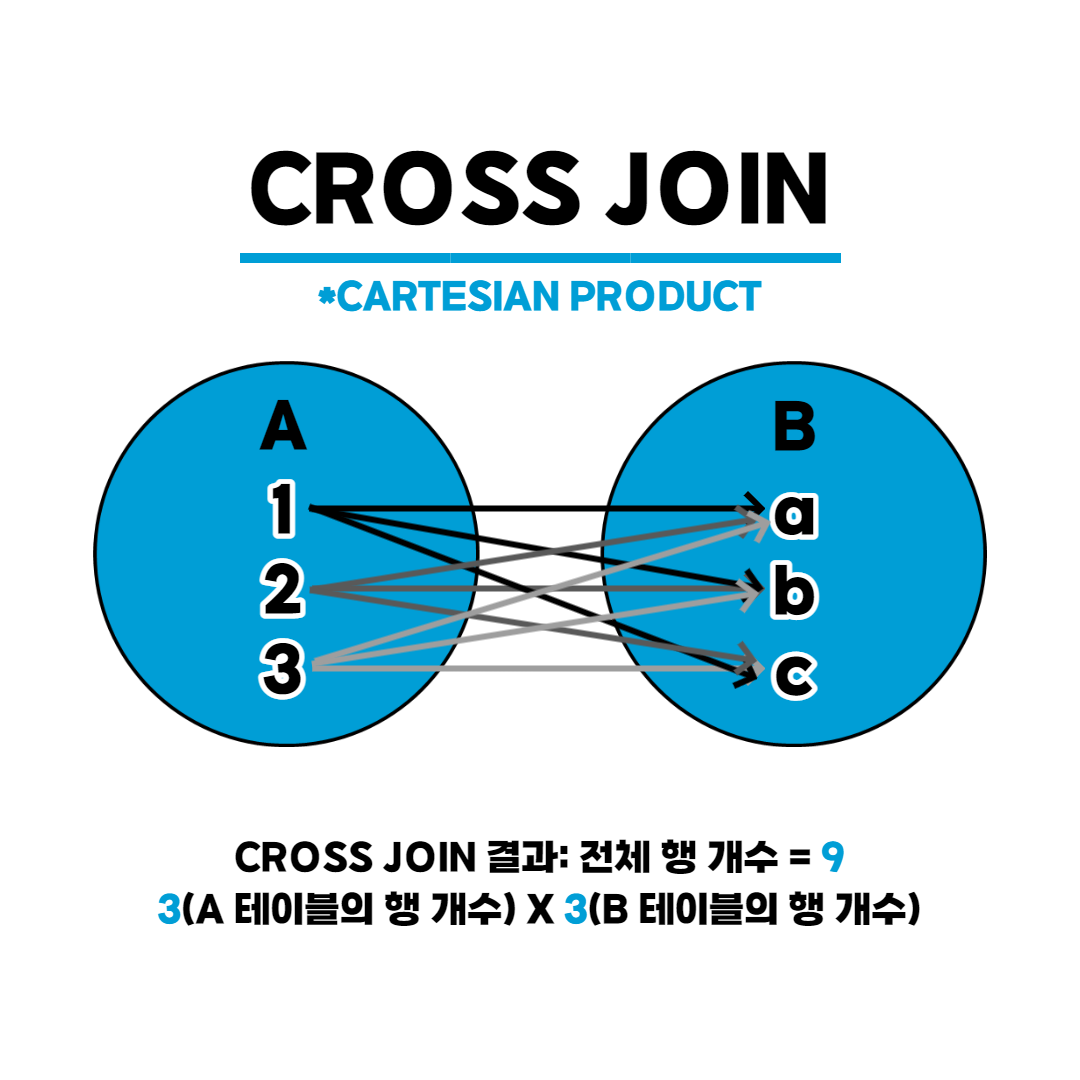
모든 경우의 수를 출력한다.
SELECT <열 목록>
FROM <기준 테이블>
CROSS JOIN <조인 테이블>
[WHERE 검색 조건]- 열 목록에 나열된 목록들의 모든 가능한 조합이 출력된다.
- 따라서 조인 조건을 명시하지 않는다.
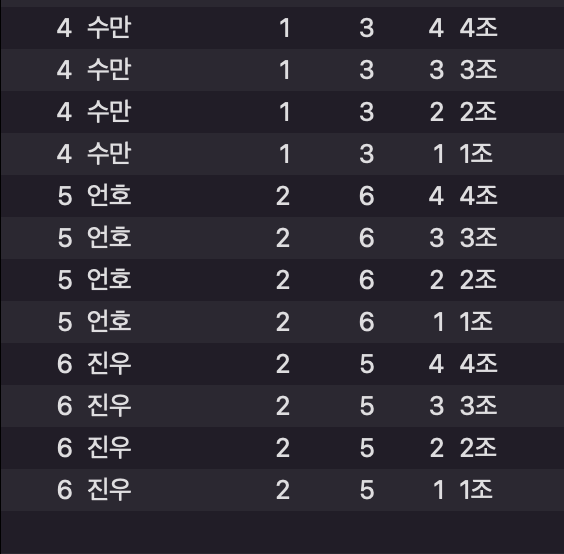
예시
SELECT * FROM user as l CROSS JOIN groupTable as r;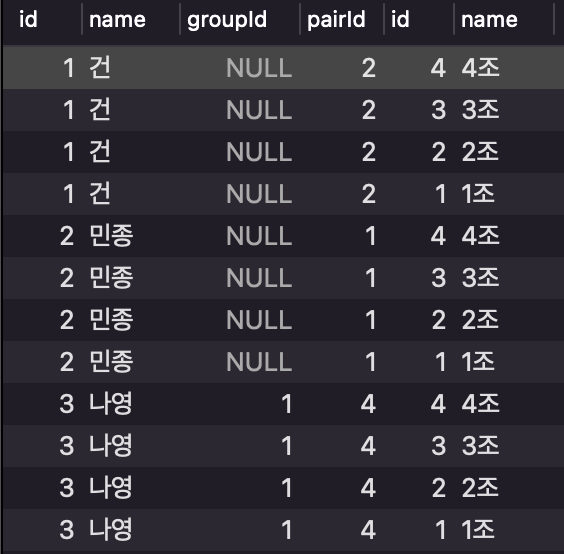
Self Join

자기 자신을 참조하는 조인
SELECT <열 목록>
FROM <테이블>
INNER JOIN <테이블>
ON <조인될 조건>
[WHERE 검색 조건]- 자기 자신을 조인하는 방법이다.
예시
시작 전, INSERT INTO user (name, groupId) VALUES ('짝없음', 3;로 pairId가 없는 row 추가
SELECT * FROM user as l
INNER JOIN user as r
ON l.id = r.pairId;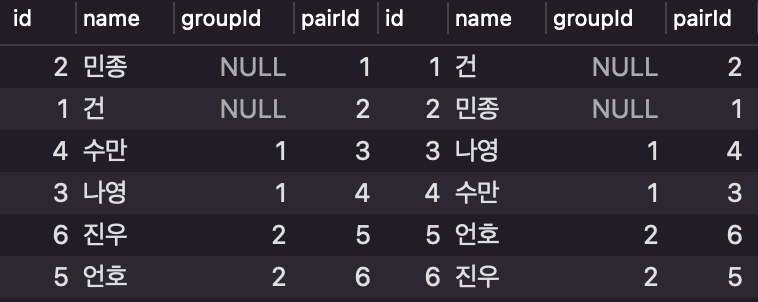
4) Time Complexity
사실 사용법의 기초적인 부분 숙지는 그리 어렵지 않다. 많이들 join을 남발하면 안된다고 하는데, 그 이유가 궁금했다. Join은 어떻게 작동하는 것일까?
Nested Loops
DBMS는 쿼리를 파싱하고, 해당 쿼리를 수행하기 위한 최적의 방법을 선택하는 기능이 내장되어있다. Mysql은 mysql 엔진 내에서 sql optimizer가 이 역할을 담당한다.
다양한 알고리즘들이 있지만 mysql은 nested loop과 그 파생 알고리즘만을 지원한다고 한다.(8.0.18부터 hash join도 지원한다고 한다!!!!) 여기서는 nested loop에 대해 간략히 알아본다.
그래서 얘는 어떻게 동작하지?
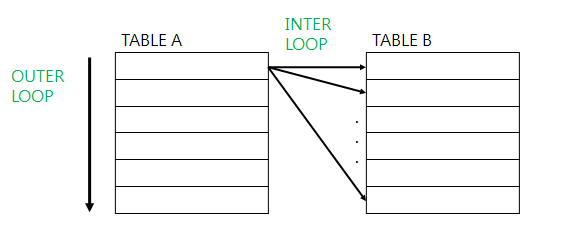
이름과 같이 마치 이중 루프와 매우 흡사하게 동작한다.
참고로 기준 테이블(위 예시의 A)는 driving table/outer table이라고 하며, 조인 테이블(위 예시의 B)는 driven table/inner table이라고 한다.
A의 레코드 하나 하나에 대해 B의 레코드를 스캔하고, 조인 조건에 맞는 레코드를 리턴한다. 테이블의 레코드 수를 R(테이블)이라고 한다면, R(A)*R(B)를 소요하는 것이다.
주의할 점
Nested Loop을 사용할 때는 driving table의 선택이 중요하다고 한다. 어차피 R(A)*R(B)만큼의 연산을 수행하는 것은 같을텐데 왜?라는 의문이 떠오르는 것이 당연하다.
생각보다 아주아주 기본적인 동작 방식은 단순하지만, 최적화를 하기 위해 BKA(Batched Key Access), BNL(Block Nested Loop)과 같은 방식들이 사용되고 있다. 또한 기본적으로는 index를 활용하는 방법도 있다. 여기서 주의할 부분이 존재한다.
기본적으로 driving table의 각 레코드 마다 driven table에서 조인 조건에 부합하는 레코드를 찾아낼 때 index를 사용할 수 있도록 하면, 시간이 더 줄어들 수 있다.
따라서 어차피 전체를 scan하는 driving table은 작게, driven table의 join key는 index를 사용하도록 하는 것이 가장 기본적인 주의할 점이 된다.
index를 사용해 scan하는 것에도 종류가 있다.
join key로 사용되는 index가 unique하다는 것이 보장되면, index unique scan을 한다. 당연히 아주 빠르고, 베스트한 경우이다,
join key로 사용되는 index가 unique하지 않다면, index range scan을 한다. unique scan보다는 느리지만, 전체 full scan을 때리는 것보다야 낫다.
기타
다른 글에서 읽은 것인데, driven table이 어마 무시하게 커지면 결국 지연이 발생하며, 이 때는 오히려 driving table을 크게 만드는 것도 방법이 된다고 한다. driving table을 전체 full scan하기는 하겠지만, driven table에 대응 하는 레코드를 찾는 것이 얼마 안걸리기 때문이다. 점포, 주문을 예시로 들었는데, 점포 id는 unique하므로, index unique scan이 일어날 것이니 베스트이겠다. 다른 방법으로는 hash join을 사용하는 방법이 있다고 한다.
Ref
