0. 데이터 접근이 일어나는 과정
데이터가 저장된 곳이 있을 거고, 프로그램은 그걸 가져와서 연산하고, 다시 특정 위치에 저장하는 방식이다. 딱 이것 때문에 synchronization문제가 발생한다. 그 특정 위치들에 동시에 접근하려고 하기 때문이다.
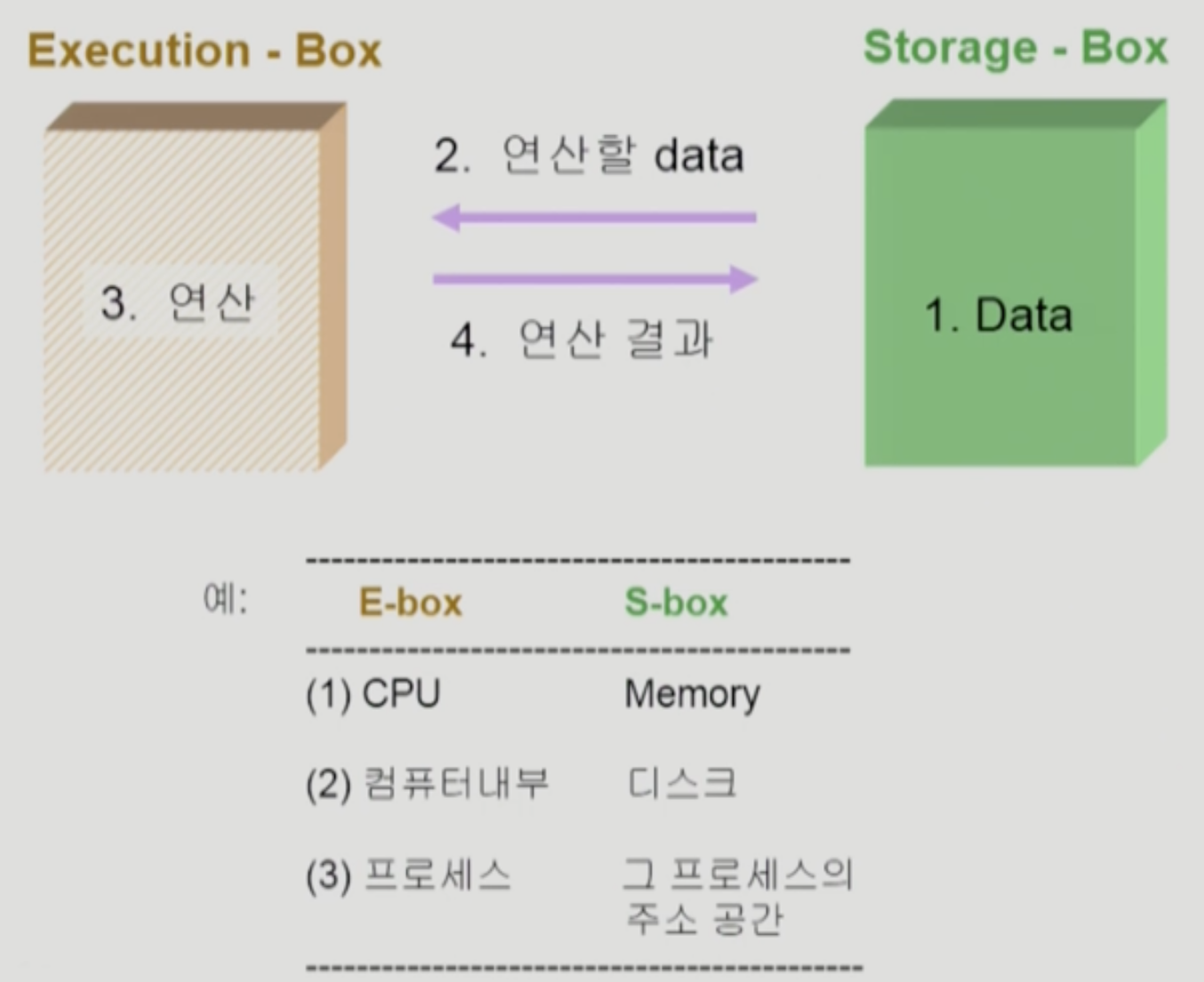
Storage는 데이터가 들어있는 저장 공간, execution은 연산 주체 정도로 생각하고 바라보자. synchronization 문제에 얽혀있는 당사자들을 위와 같이 바라볼 수 있다.
물론, 일반적인 경우에서는 발생하지는 않는다. 어차피 cpu가 하나이면 memory 건드는건 그 하나의 cpu이고, process도 자기 주소 공간만 건드리기 때문
하지만 multi processor인 경우, process간에 공유메모리가 있는 경우와 같이 데이터를 건드리는 주체(E-box)가 여러개인 상황에서 발생할 수 있다.
즉 정리하자면,
process synchronization은
- 공유 데이터에 동시 접근시 데이터 불일치 문제 발생 가능
- 일관성 유지를 위해 실행 순서를 정해주는 메커니즘 필요
1. Race Condition
Race condition
- 여러 프로세스들이 동시에 공유 데이터를 접근하는 상황
- 공유 데이터 중 같은 부분을 건드리거나, kernel을 호출해 kernel 데이터 중 같은 부분을 건드릴 때 발생 가능할 것
이에 의해 발생하는 문제를 막기 위해 synchronization이 필요
발생 상황과 해결법
race condition은 언제 발생할까?
간단한 예시부터 들어본다.
kernel 작업 수행 중 interrupt 발생시
- kernel 모드에서 특정 데이터를 건드리다가 interrupt 발생 후 다른 작업으로 넘어가고, 거기서도 같은 데이터를 건드리는 경우
- 단순히 kernel 모드에서 작업하는 동안은 interrupt를 방지하도록 할 수 있겠다.
Process가 system call하여 kernel mode로 들어갔는데 context switch가 일어난 경우
- 프로세스1이 system call하여 데이터 조작 중, 시간이 초과되어 cpu 제어권이 프로세스2로 넘어가고, 또 system call을 해 같은 데이터를 조작하는 경우
- 위와 같게 해결. 시간 초과로 인한 interrupt 방지
multiprocessor에서 shared memory 내에 kernel data가 있을 때
- 2개의 cpu가 동시에 kernel의 공유 데이터에 접근해 조작하는 경우
- kernel 내부에 있는 공유 데이터에 접근할 때마다, 그 데이터에 대한 lock/unlock 시행
특히 kernel을 건드리는 경우 이런 문제가 발생할 확률이 높다. user level에서는 문제가 별로 안생길만한게 맞는데, kernel은 다르다. 여러 process들이 system call을 외쳐대기도 하고, 또 kernel이 요청받은 작업을 수행하다가도 다른 interrupt가 들어오면, 자기 자신이 자신을 멈추고 다른 작업을 수행해야하기 때문이다. 이 과정에서 kernel이 갖는 data 공간이 꼬일 가능성이 있다. 즉, system call에 의해 다양한 상황에서 kernel이 호출되고, 같은 data를 건드리게 되기 때문
조금 더 구체적인 예시를 봐보자
예시 1
두 프로세스가 같은 자원에 접근할 때이다.
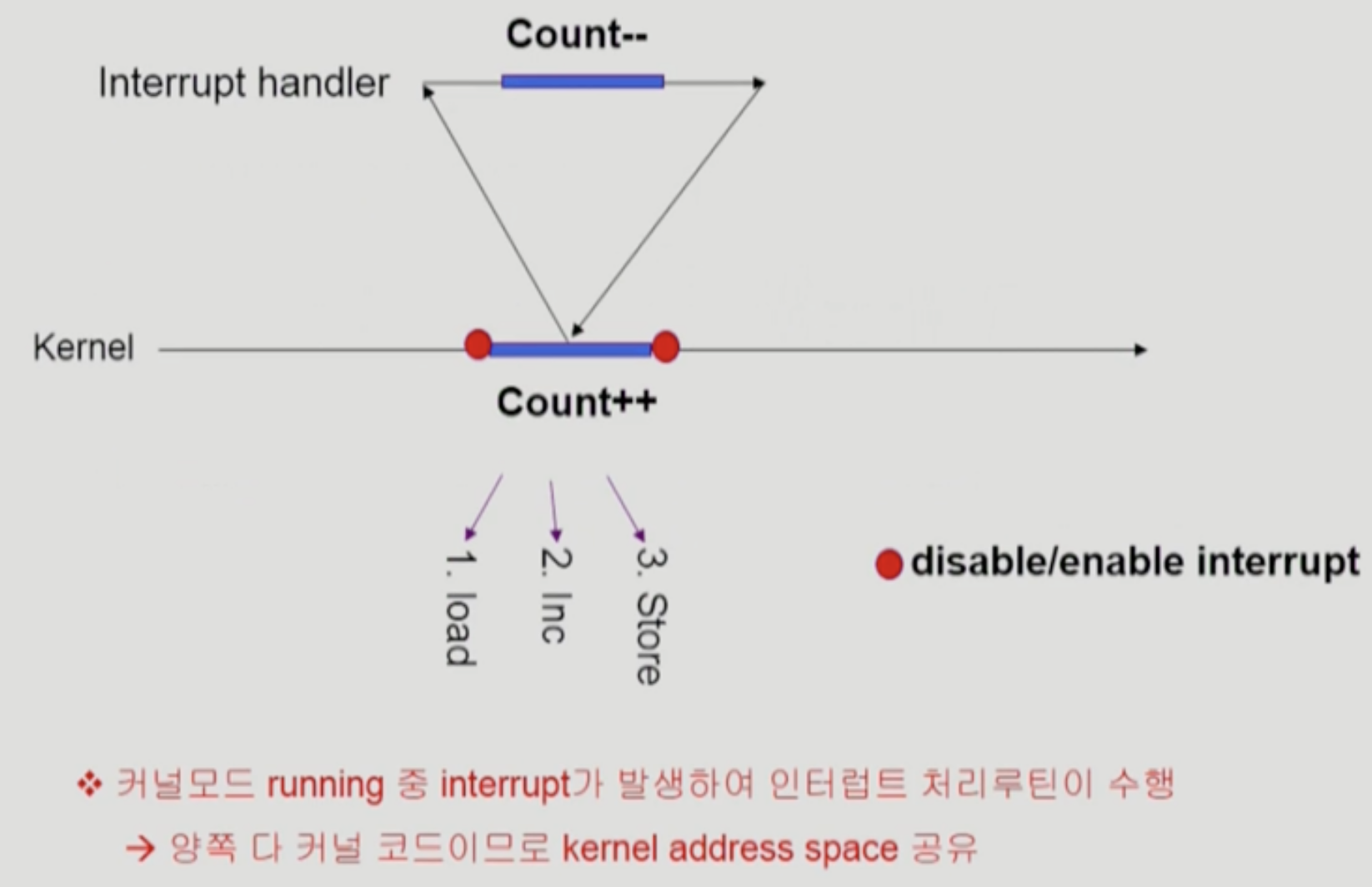
- count에 0이 저장되어있고, kernel에서 count 값을 증가시키는 연산을 수행중이라고 하자.
- 고급 언어에서 저런 단순한 연산도 낮은 레벨에서는 여러개의 instr로 쪼개진다.
- 해당 값을 register에 저장하는 작업을 마치고, 이를 증가시키려고 할 때 interrupt가 발생했다고 하자. 이번 프로세스에서는 다시 count 값을 감소시키는 연산이 수행된다고 하자.
- interrupt가 끝나고, 다시 수행중이던 연산이 끝나면, 결국 count-- 연산은 무시되고 count값이 1이 된 채로 남겨지게 된다
- register에 저장될 때, 0이라는 값이 저장되며, interrupt 후 다시 값을 증가시키는 연산이 수행될 때는 -1이 아니라 0을 가지고서 연산을 수행하기 때문이다.
이 경우, 특정 작업이 진행되는 동안만큼은 interrupt가 되지 않도록 하게 함으로써 문제 해결 가능
예시 2
두 프로세스가 kernel의 함수를 호출해 같은 자원을 건드리는 경우이다.
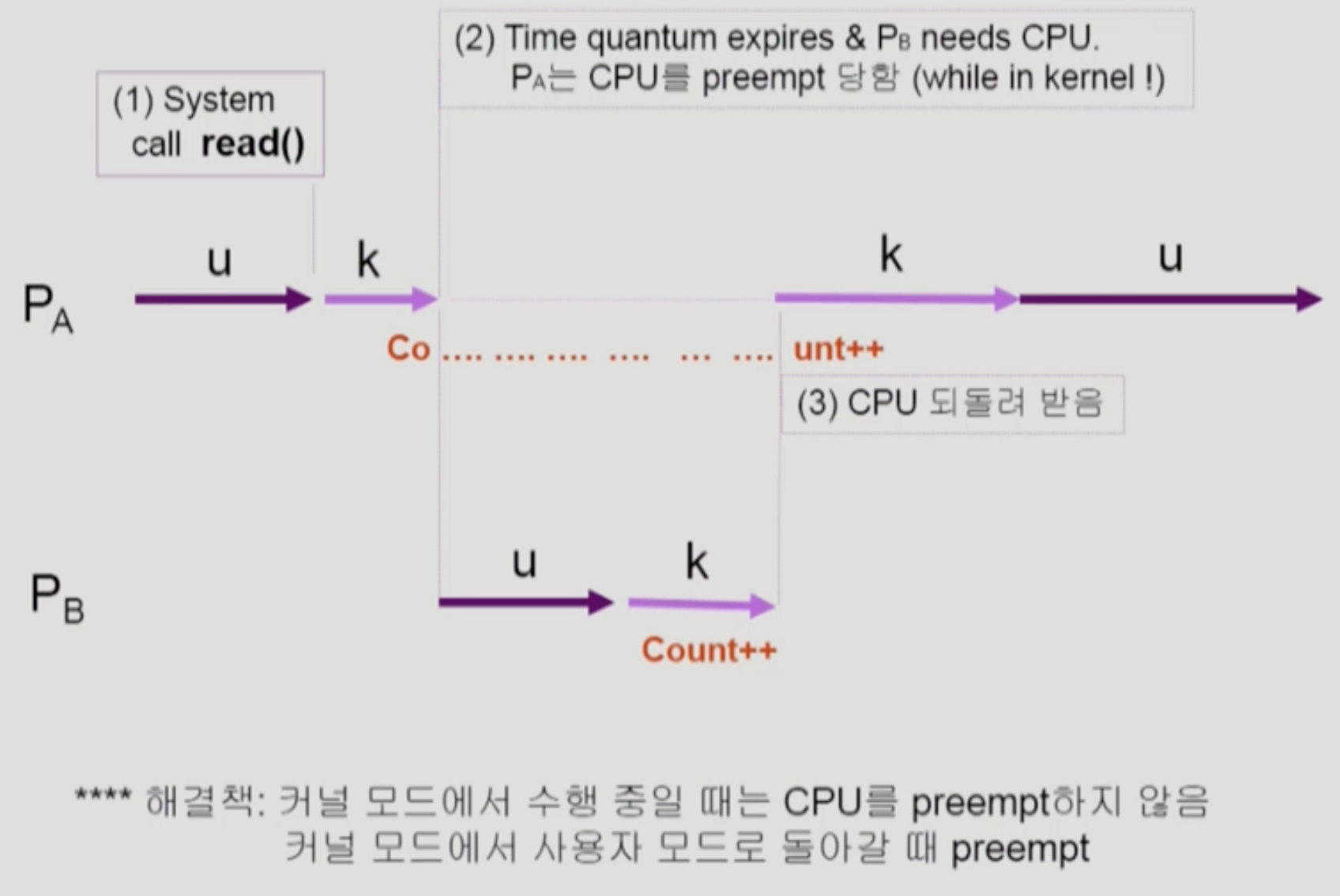
- A가 kernel mode로 들어가서 count를 올리려다가 할당 시간이 끝나서 B로 넘어갔다고 하자.
- B도 kernel mode로 들어가서 count를 올리는 작업을 한다고 하자.
- 그럼 이후 다시 A로 돌아와 count를 올리더라도 count는 2가 아니라 1만큼 올라가게 된다.
이 경우, kernel mode일 때 만큼은 할당 시간이 끝나도 cpu를 뺏기지 않도록, 즉 preemptive하지 않도록 정책을 설정하는 식으로 해결가능. user mode로 빠져나올 때 빼앗도록
예제 3
cpu가 여러개 있는 경우이다.
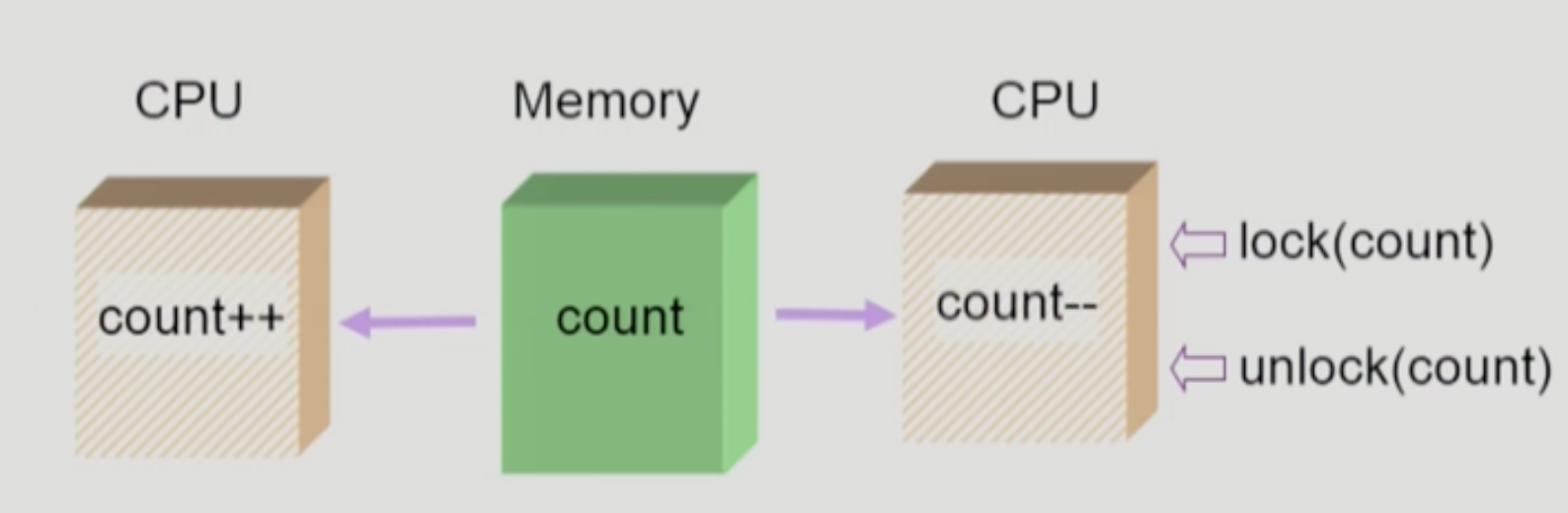
- 앞에서 본 어떤걸로도 해결되지 않는다. 작업이 진행되는 도중 interrupt되지 않게 하는것이나 preemptive를 막는다고 되는게 아니다.
data에 접근시 해당 data에만 lock을 걸어버리는 방법으로 해결 가능하다. 접근하기 전에 lock을 걸고, 하고 싶은 연산을 쭉 수행하다가 모든 연산이 끝나면 다시 lock을 해제하는 것- 결국 kernel에 여러 cpu가 동시에 접근해서 생기는 문제이다. kernel에 하나의 cpu만 접근할 수 있도록 제한할 수도 있겠다. cpu가 kernel에 접근시 kernel 전체에 lock을 걸고, 끝나면 lock을 해제하는 방식. 꽤 비효율적이다.
어쨋든 이렇게 공유데이터에 접근하는 주체가 여러개 있다는 전재하에 발생하는 문제를 어떻게 풀 것인가에 대해 다룰것이다.
일관성 유지를 위해서는 협력하는 프로세스간의 실행 순서를 잘 정해줄 메커니즘이 필요한 것이다.
물론 공유 데이터의 동시 접근은 데이터 불일치 문제를 발생시킬 수 있지만, 공유데이터에 접근을 항상 하는 것은 아니다. 그러한 부분이 종종 있는 것이다. 그런 부분을critical section이라고 한다. 아래서는 공유 데이터를 건드리는 프로세스들의 순서를 정해줄 메커니즘을 critical section이라는 부분을 기준으로 해결해나가는 다양한 방법들을 알아볼 것이다.
2. Critical Section
Critical section
공유데이터에 접근하는 코드를 의미한다
- 하나의 process가 critical section에 있을 때, 다른 process는 critical section에 들어가면 안된다.
해결 방안
기본 접근
do{
entry section
critical section
exit section
remainder section
} while(1);- critical section 앞 뒤로, entry/exit임을 알리는 무언가를 배치해 현재 process 실행 흐름 중 critical section에 들어와있음을 인지시키는 방법
- 이 process가 critical section에 들어와있다면 다른 process는 들어가지 않고 기다릴 것
- 간단해 보이지만 고급 언어의 코드 한줄이 아니라 cpu instr 하나 단위로 interrupt가 걸리기 때문에 고려할게 많다.
해결법 충족 조건
Mutual Exclusion (상호 배제)
- 하나의 process가 critical section에 들어가있으면, 다른 process들은 critical section에 들어가지 못하도록 해야한다.
Progress
- Critical section에 아무도 들어가있지 않은 상황에서, 들어가고자 하는 process가 있다면 critical section에 들어가게 해줘야한다.
- 당연한 이야기이지만, 설계를 잘 못하면 둘이 동시에 들어가고자 해서 둘다 못들어가는 상황 발생
Bounded Waiting (유한 대기)
- Process가 critical section에 들어가려고 요청한 후부터 그 요청이 허용될 때까지 다른 process들이 critical section에 들어가는 횟수에는 한계가 있어야한다. 무한정 기다리게 하면 안된다. starvation x
- 셋이 있는데 둘이서만 번갈아 들어가는 경우가 발생할 수 있을 것이다.
Algorithm 1 - 올바르지 않은 예
Synchronization variable 1개 선언
do{
while (turn != 0);
critical section
turn = 1;
remainder section
} while(1);- P0, P1 두개의 process가 공유 데이터를 가지고 논다고 하자. 위 코드는 P0 기준으로 작성되었다.
- turn이라는 변수를 두어 제어한다. 자신에게 매칭되는 turn 번호가 아니면, 무한대기하도록 하는 것
- P1이 자신의 차례가 끝났을 때 turn을 0으로 바꾸어 P0이 critical section에 진입 가능할 것
→ 문제가 있다. P1이 들어가야만 P0가 critical section에 들어갈 수 있다. 서로 critical section에 들어가는 빈도가 다를 수 있다. Progress 조건을 만족하지 않는다.
Algorithm 2 - 올바르지 않은 예
Synchronization variable process 개수만큼 선언
do{
flag[i] = true; // i wanna get in
while (flag[j]); // is another one also in? then wait
critical section
flag[i] = false; // i'm out now
exit section
remainder section
} while(1);- 처음에는 flag 배열의 모든 값을 false로 초기화 한다.
- P_i가 critical section에 들어갈 차례가 되면 자신의 flag를 true로 변환한다. 의사표시를 하는 셈
- 상대방의 flag를 확인하고 true가 있다면 기다린다. 그러다 critical section에 아무도 없으면 자신이 들어간다.
- 빠져나올 때는 자신의 flag를 false로 돌린다.
→ flag[i] = true;가 실행된 후 cpu를 뺏기면, 둘 다 flag가 true가 되어버리는 상태가 발생한다. Progress 조건을 만족하지 않는다.
Algorithm 3 - Peterson’s Algorithm
1과 2를 합친 것
do{
flag[i] = true; // i wanna get in
turn = j; // set the turn to another one first
while (flag[j] && turn == j); // wait only if ...
critical section
flag[i] = false; // i'm out now
exit section
remainder section
} while(1);- 자신의 flag를 true로 바꿔 들어갈 의사를 표시하고, turn은 상대방 차례로 바꾼다.
- 이번 차례가 상대방 차례가 아니라 내 차례이거나, 상대방의 flag가 true가 아니라면, 내가 critical section으로 들어간다.
- flag는 동시에 true가 될 수 있으나, turn은 가장 마지막에 실행된 process에 의해 어떤 것으로라도 일단 바뀌기는 할 것이기 때문에 critical section 관리가 잘 수행된다.
→ 세 조건을 모두 잘 만족한다. Busy waiting(=spin lock)이라는 문제가 발생하기는 한다. 결국 P0가 critical section에 들어와있는 상태로 cpu가 P1에게 넘어가고, P1이 critical section에 들어가고자 할 때, 아무리 while문을 돌아도 자신에게 차례가 넘어올리는 절대 없다. cpu 낭비 발생
Synchronization Hardware
하드웨어적으로도 해결 가능하다. Test & Modify를 atomic하게 수행할 수 있도록 지원하는 경우, 앞의 문제는 간단히 해결 가능하다.
잘 생각해보자. 따지고 보면 데이터를 읽고 쓰는 것을 하나의 instr으로 처리할 수 없었기에 공유 메모리에서 synchronization 문제가 발생했던 것이다. 그냥 이 과정 자체를 하나의 instr을 해결되도록 해버리면 해결되는 것
Test_and_Set이라는 instr이 주로 활용된다. 원래 값을 읽어내고, 그 자리를 1로 채운다.
boolean lock = false; // synchronization variable
do {
while (Test_and_Set(lock));
critical section
lock = false;
remainder section;
}- Test_and_Set(lock)이 0을 반환하면, critical section에 바로 들어가면 된다. lock은 1이 될 것
- 1을 반환한다면, 계속해서 기다리게 될 것
- 다시 critical section에서 나오면, lock은 0(false)가 될 것
프로그래머가 매번 이런 작업을 하는 것은 꽤나 힘들 것이다. 이를 위해 추상 자료형인 semaphores라는 것을 정의하고 사용한다. 다음 시간에 알아보자
