MNIST 데이터셋은 딥러닝을 처음 공부하는 사람들이 풀어보는 문제입니다. 숫자 손글씨 이미지에 대한 데이터와 라벨이 포함되어 있으며 60000개의 트레이닝 데이터와 10000개의 테스트 데이터가 있습니다.
👀 데이터 살펴보기
keras의 내장 함수를 호출해서 mnist 데이터셋을 불러올 수 있습니다.
import tensorflow.keras
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()저의 경우에는 데이콘 문제 페이지에서 데이터를 받아와서 로드하는 방식으로 데이터셋을 불러왔습니다.
import pandas as pd
df = pd.read_csv('./mnist/train.csv', index_col=['index'])csv 파일에서 불러왔기 때문에 데이터프레임 형식으로 되어있습니다. 데이터프레임을 살펴보면 첫번째 열에는 우리가 찾고자 하는 라벨이 있고 나머지 열은 이미지의 픽셀 데이터가 저장되어 있습니다
| index | label | px1 | px2 | ... | px783 | px784 |
|---|---|---|---|---|---|---|
| 0 | 5 | 0 | 0 | ... | 0 | 0 |
| 1 | 0 | 0 | 0 | ... | 0 | 0 |
| 2 | 4 | 0 | 0 | ... | 0 | 0 |
| 3 | 1 | 0 | 0 | ... | 0 | 0 |
| 4 | 9 | 0 | 0 | ... | 0 | 0 |
🪐 데이터 전처리
먼저 입력 데이터 라벨 데이터를 나누고 이를 array형태로 바꿔줍니다.
X_array = df.iloc[:, 1:].to_numpy()
y_array = df.iloc[:,0].to_numpy()
X_array.shape, y_array.shapeshape 확인 결과
((60000, 784), (60000,))라벨 데이터를 원핫인코딩을 해줍니다.
from sklearn.preprocessing import OneHotEncoder
oh_enc = OneHotEncoder(dtype=int)
oh_enc.fit([[i] for i in range(10)])
y_array = oh_enc.transform(y_array.reshape(-1, 1)).toarray()x 데이터인 픽셀데이터는 0~255의 정수값으로 되어있는데 이를 Normalization을 해서 학습 성능을 높여줄 필요가 있습니다.
X_array = X_array.reshape(-1,28,28, 1).astype(float) / 255이미지 데이터를 시각화해서 확인해보겠습니다.
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 14))
for i in range(1, 26):
plt.subplot(5, 5, i)
plt.imshow(X_array[i], 'gray')
plt.axis('off')
plt.show()
🎓 딥러닝 모델링
이미지와 같은 2차원 데이터는 CNN을 거쳐서 학습을 시켜줘야 합니다. 그 이유는 일반적인 딥러닝 모델은 flatten된 1차원 형태의 데이터를 학습하는데 이렇게 되면 공간적 정보가 손실됩니다. 그래서 CNN을 사용하면 공간적 정보를 유지하며 특징을 뽑아낼 수 있게 됩니다.
CNN에서는 convolution 레이어와 pooling 레이어를 번갈아가며 거치고 마지막에는 flatten을 해서 일반 Dense 레이어를 통과할 수 있는 형태로 만들어 줍니다.
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
model = Sequential()
model.add(Conv2D(32, kernel_size = (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])학습을 하기 전에 모델 평가를 위해서 학습 데이터와 테스트 데이터를 나누어 줍니다.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X_array, y_array, test_size=0.2, stratify=y_array, random_state=4)학습 데이터와 테스트 데이터 비율은 8:2이고 계층적 데이터 샘플링을 했습니다.
학습을 할 때에는 2번 연속 검증데이터 loss 값이 진전이 없다면 조기종료 시킵니다. 그리고 검증 데이터의 비율은 3:1이고 배치 사이즈는 256으로 설정했습니다.
from tensorflow.keras.callbacks import EarlyStopping
e_st = EarlyStopping(patience=2, restore_best_weights=True)
history = model.fit(x_train, y_train, epochs=10, validation_split=0.25, callbacks=[e_st], batch_size=256)학습이 잘 되었는지 확인하기 위해서 학습과정을 시각화해서 보겠습니다.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()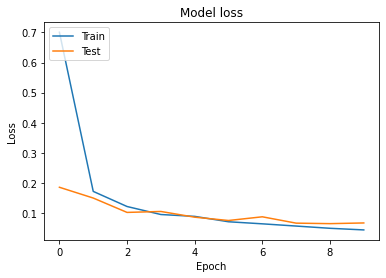
학습 데이터와 검증 데이터의 loss값 차이가 크지 않은 것을 보니 과대적합이 되지 않았다고 판단 해볼 수 있습니다.
테스트 데이터로 성능을 확인해보겠습니다.
model.evaluate(x_test, y_test)결과
375/375 [==============================] - 2s 5ms/step - loss: 0.0812 - accuracy: 0.9755
[0.08122505992650986, 0.9754999876022339]상당히 괜찮은 성능을 보입니다.
