
Orange로 하는 Housing price prediction
Orange3를 활용하여 대표적인 Regression 문제라 불리는 Housing price prediction을 해보겠습니다.
데이터 준비
시작에 앞서서 우선 Orang3에서 제공하는 housing 데이터를 받아야 합니다.
위의 그림과 같이 datasets 위젯을 클릭한 후 housing를 검색합니다.
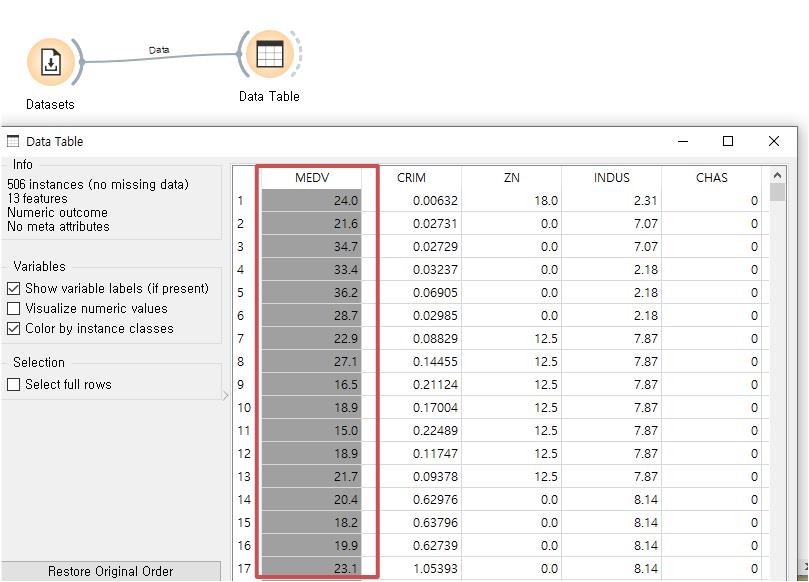
dataset이 제대로 들어왔는지 Data Table 위젯을 열어서 어떤 데이터들이 들어가 있는지 확인해 봅시다.
위의 데이터를 보면 빨간색 사각형으로 체크한 부분이 있는데 이 부분이 바로 저희가 예측을 해야하는 target에 해당하는 부분입니다.
그리고 왼쪽 위에 Info 부분에 대해 추가로 설명하면, 506 instances 옆에 (no missing data)이 부분은 데이터에 결측치가 없다는 의미입니다.
13 features : feaure가 13개 있다는 의미입니다.
Numerice outcome : 결과가 Numerice 즉 숫자로 나온다는 의미입니다.
Data Table에서 보이는 fature들의 의미
- housing 데이터셋에서 각 feature들이 가지는 의미를 살펴보겠습니다.
CRIM : 마을 별 1 인당 범죄율
ZN : 25,000 평방 피트 이상의 부지에 구역화 된 주거용 토지의 비율.
INDUS : 도시 당 비 소매 사업 에이커의 비율
CHAS : Charles River 더미 변수 (유도가 강 경계면 = 1, 그렇지 않으면 0)
NOX : 산화 질소 농도 (1000 만분 율)
RM : 주거 당 평균 방 수
AGE : 1940 년 이전에 지어진 소유주 소유 유닛의 비율
DIS : 보스턴 고용 센터 5 곳까지의 가중 거리
RAD : 방사형 고속도로 접근성 지수
TAX : $ 10,000 당 전체 가치 재산 세율
PTRATIO : 도시 별 학생-교사 비율
B : 1000 (Bk-0.63) ^ 2 여기서 Bk는 도시 별 흑인 비율입니다.
LSTAT : 인구의 낮은 지위 %
MEDV : 소유주가 거주하는 주택의 중간 가치 ($ 1000)
모델 학습 & 결과
Linear Regression 모델
Linear Regression 위젯으로 학습을 하고 그 결과를 Predictions로 확인을 해보겠습니다.
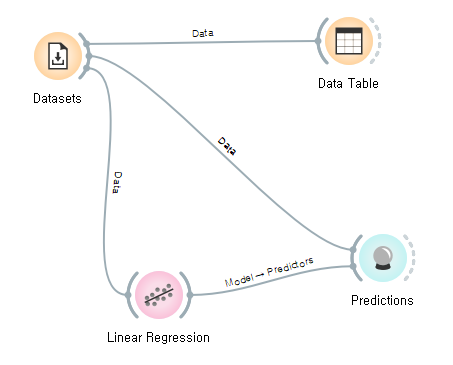
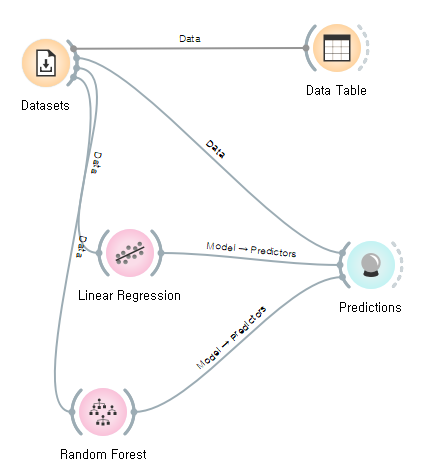
위와 같이 연결을하고 여기서 중요한 점은 Linear Regression과 Predictions하고만 연결하는것이 아닌 Datasets과 Predictions도 연결을 해주어야 합니다.
이 이유로는 우선 Datasets을 가지고 Linear Regression 주택값에 대해 학습을 합니다.
그러면 feature로 학습을해서 주택값을 예측하는 모델이 만들어 집니다.
해당 모델의 성능을 확인해야하니 Data를 predictions 위젯에 주고 해당 데이터에서 주택값을 예측하기 위해 Linear Regression을 연결하기 때문에 위와 같은 연결된 구성이 만들어 집니다.
그러면 Predictions를 클릭해서 결과를 확인해 봅시다.
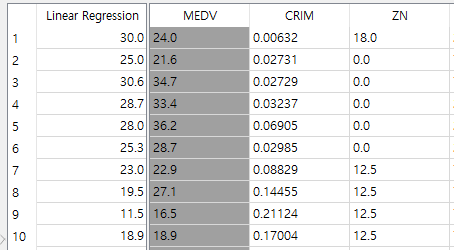
Linear Regression로는 그렇게 좋은 결과가 나오지는 않았네요.
다른 모델로도 한번 확인을 해봅시다.
Randomforest 모델
Randomforest도 위와 같이 연결을 해주면 됩니다.
결과를 확인해 봅시다.
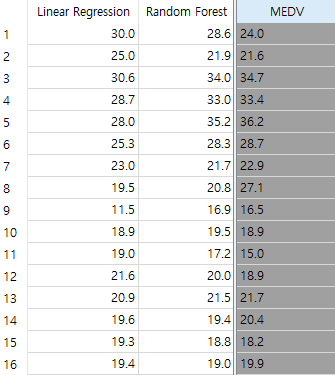
결과를 봤을때 Linear Regression보다 Random Forest가 더 좋은 결과를 보이는것을 알 수 있습니다.
그럼 여기까지 Orange3로 해보는 Housing price prediction을 해봤습니다.
물론 위에서 한 방법만으로 실제로 사용하기에는 힘들긴 합니다. 데이터 전처리도 해야하고 feature engineering도 해야하는 여러 작업이 필요하지만, Orange3에서 제공하는 Housing Datasets으로는 위젯들의 값을 변경하지 않고 그대로 사용해도 예측이 잘 이루어집니다.
위에서 제가 한 모델 말고 다른 모델들도 사용해보면서 실제 코드들에 대해서도 공부하면 더 이해도 잘가고 좋을것 같네요.
그럼 이만 포스팅을 마치겠습니다.
