
2023 - 02 - 07
지난 프로젝트에서 좀 더 진전시켜보도록 한다.
from requests import get
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?term="
search_term = "java"
response = get(f"{base_url}{search_term}")
if response.status_code != 200:
print("Can't request website")
else:
soup = BeautifulSoup(response.text, "html.parser")
jobs = soup.find_all('section', class_="jobs")
print(len(jobs))이 부분까지 했었는데, else부분에 추가로 넣을 것이다.
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
print(post)
print("/////////////////////")for - in 문으로 jobs의 갯수만큼 loop를 돌린다.
find_all을 이용해 li태그가 들어간 것만 고를건데,
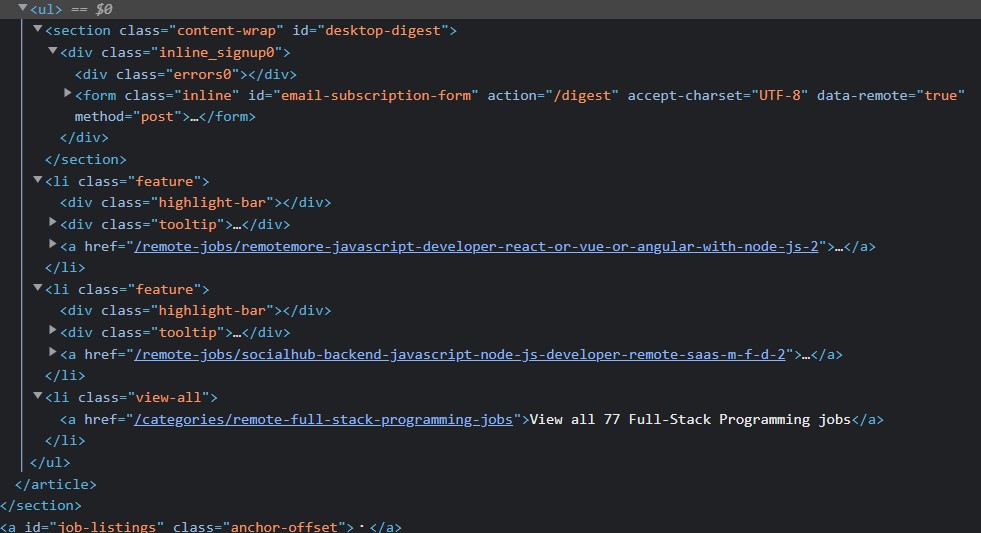
지금 보는 사진이 weworkremotely 사이트의 소스코드다.
각 li 마다 회사정보가 하나씩 들어가 있기 때문에 li를 찾아서 구분하려는 것이다.
그 정보를 job_posts에 저장해 둔다.
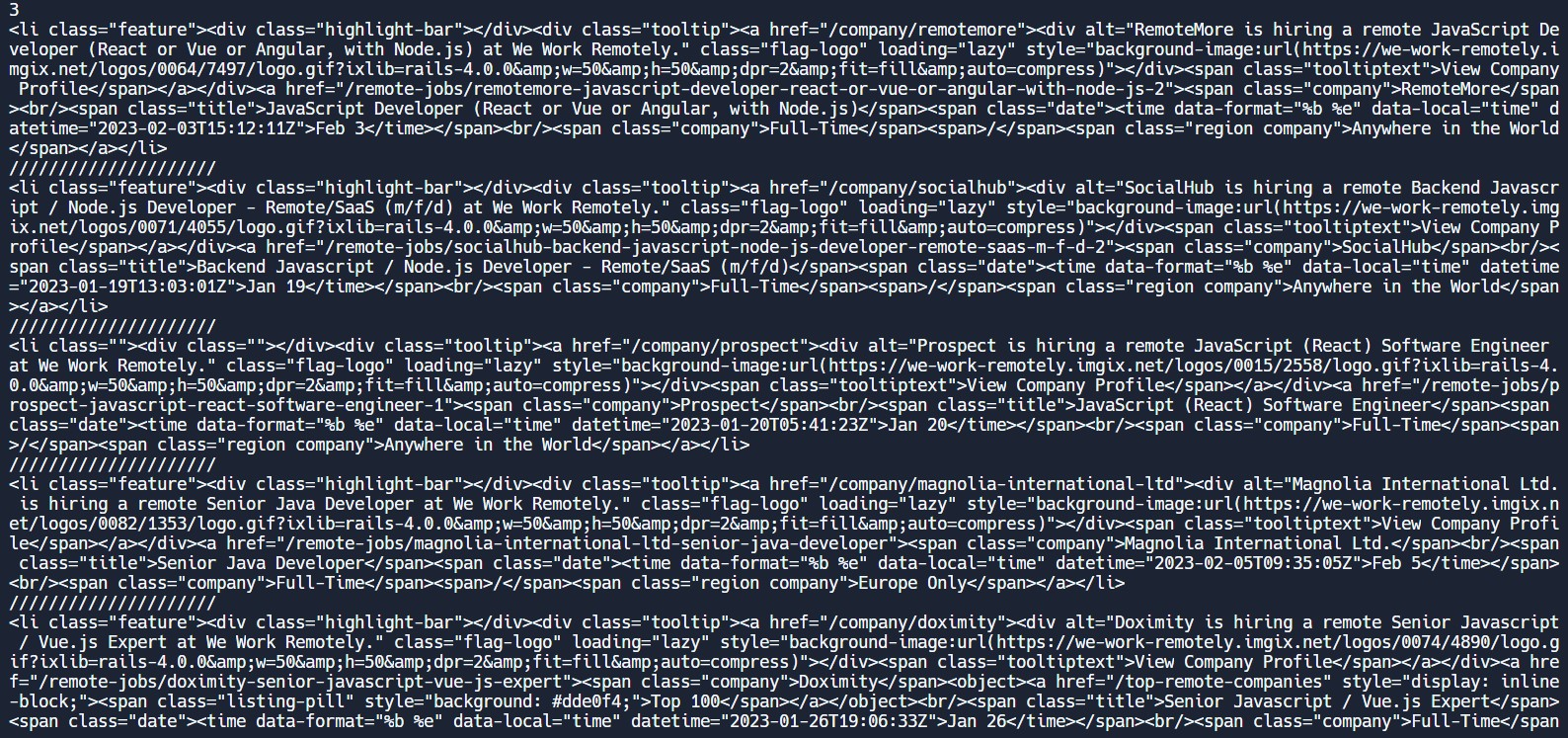
이 사진은 li 하위태그들을 보여준다.
코드에서 job_section은 list 이다. 따라서 list 함수를 사용할 수 있다는 것이다.
li마다 주소를 가지고 있다고 보면되는데, 우리는 마지막 li class="view-all"은 필요하지 않다. 그래서 이걸 지워주는 작업을 할건데,
li가 2개만 있을수도 3개 혹은 5개가 있을 수 있으니, 매번 마지막 주소만 지워주게끔 -1을 사용해 마지막 주소를 지워주도록 한다.
마지막으로 for - in 문으로 li의 갯수만큼 loop를 돌리고
li만 있는 각 코드들을 //////로 구분하여 확인 해준다.
그렇게 해서 나온 결과는 다음과 같다.
처음에 section에서 jobs가 들어있는 부분이 3개였고,
그 다음 회사별 /////로 나눠져 있다.
remotemore, socialhub, prospect,,,등으로 구분되어 있는것을 볼 수 있고, 우리가 지웠던 view_all 부분도 지워져서 보이지 않는것을 확인 할 수 있었다.
