
from requests import get
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?term="
search_term="java"
response = get(f"{base_url}{search_term}")
if response.status_code != 200:
print("Can't request website")
else:
results = [] #(2)
soup = BeautifulSoup(response.text, "html.parser")
jobs = soup.find_all('section',class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all(
'span', class_="company")
title = anchor.find('span', class_='title')
job_data = {
'link': f"https://weworkremotely.com/{link}",
'company': company.string,
'region': region.string,
'position': title.string
}
results.append(job_data) #(1)
for result in results:
print(result)
print("////////////")⦁ 23번째 줄까지 작성을 해 보았고, 24번째 줄 부터 새로운 내용을 추가했다. 지금까지는 결과를 출력해 봤을때 html의 태그들이 함께 나와 보기가 불편했다. 그 점을 해결하기 위해 각각의 요소들을 dictionary에 정리해 dictionary 자체를 출력하는 방법을 썼다.
보통
<span class="title">title</span> 이런 코드를 BeautifulSoup로 받아둘 텐데, string method로 호출하면, BeautifulSoup는 title만 남겨준다.
link 같은 경우 완전한 주소로 적혀 있지 않기 때문에 필요한 부분을 채워넣었다.
⦁ 코드에 #(1)과 #(2)로 표시를 해 뒀다. 이렇게 하는 이유는
for loop로 나오는 결과들을 한번에 보고 싶은데, for loop는 loop하나를 돌고나면, 그 내용들은 삭제가 되고 새로운 loop의 내용만을 가지고 있게 된다. 결과를 저장해두고 한번에 출력해야 하기 때문에 #(2)처럼 빈 공간을 확보 해 두고(이때도 물론 loop에 영향을 받지 않는 level에서 적어둬야 한다.), #(1)처럼 .append로 내용을 계속 덧붙여 주는 형식으로 하면 된다.
결과를 확인해 보면,
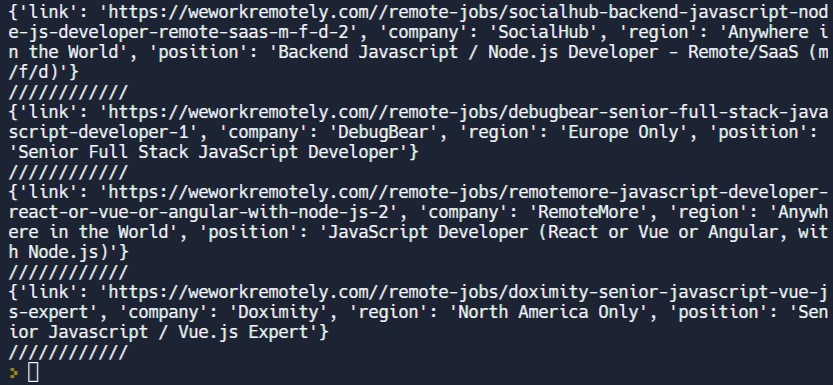
이런 식으로 link, company, region, position 순으로 값들이 잘 나오는 것을 확인 할 수 있다.
⦁ 이번에는 기존 main파일에서만 출력을 했는데, weworkremotely의 공고 뿐 아니라, 다른 사이트에서도 같은 방식으로 공고를 출력하기 위해 extrators라는 폴더를 만들고 그 안에 wwr.py라는 파일을 만들었다. 그리고 거기에 기존에 있던 main 파일의 코드를 붙여넣었고, main파일은 form-import를 제외하고 남겼다.
이렇게 하는 방식을 "refactoring" 라고 하는데, 이 말의 뜻은
<결과의 변경없이 코드의 구조를 '읽기쉽고, 재사용하기 쉽게' 조정하는 것>이다.
main파일의 코드 구성은 다음과 같다.
from requests import get
from bs4 import BeautifulSoup
jobs = extract_wwr_jobs("java")
print(jobs)
wwr파일에 extract_wwr_jobs라는 함수를 만들어뒀다.
이 함수는 우리가 지금까지 써왔던 search_term을 대신 하여 검색어를 argument로 받을 것이다.
다음은 wwr파일의 코드이다.
from requests import get
from bs4 import BeautifulSoup
def extract_wwr_jobs(keyword):
base_url = "https://weworkremotely.com/remote-jobs/search?term="
response = get(f"{base_url}{keyword}")
if response.status_code != 200:
print("Can't request website")
else:
results = []
soup = BeautifulSoup(response.text, "html.parser")
jobs = soup.find_all('section', class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all(
'span', class_="company")
title = anchor.find('span', class_='title')
job_data = {
'link': f"https://weworkremotely.com/{link}",
'company': company.string,
'region': region.string,
'position': title.string
}
results.append(job_data)
return results위에서 설명했다시피, keyword를 받는 extract_wwr_jobs라는 함수를 만들어 놓고, main에 있던 코드를 넣어주었다. 그리고 마지막에 결과를 출력하는 부분만 지우고 results를 return하게 했다. 이는 나중에 내용들을 모두 엑셀 파일에 넣어 주는 작업을 하기 편하게 하기 위함이다.
