
⦁ 이제 우리는 새로운 사이트를 탐험해 볼 것이다.
사이트의 이름은 indeed인데, 이 곳에서도 weworkremotely에서 했던 것과 마찬가지의 작업을 할 것이다.
하지만 사이트 get함수로 사이트의 정보를 받아오려고 했지만, 403에러가 나며 실패했다. 그 이유는 사이트가 우리를 봇으로 알아보고 막았기 때문이다. 이러한 문제를 위해 몇가지 코드를 추가 했다.
from requests import get
from bs4 import BeautifulSoup
from extractors.wwr import extract_wwr_jobs
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
browser = webdriver.Chrome(options=options)
search_term = "phython"
browser.get(f"https://kr.indeed.com/jobs?q={search_term}&limit=50")
soup = BeautifulSoup(browser.page_source, "html.parser")
job_list = soup.find("ul",class_="jobsearch-ResultsList")
jobs = job_list.find_all("li",recursive=False)
for job in jobs:
zone = job.find("div",class_="mosaic-zone")
if zone == None:
print("job li")
else:
print("mosaic li")⦁ 먼저 소개할 프로그램이 있다. 이 프로그램의 이름은 Selenuim 이다.
브라우저를 자동화 할 수 있는 프로그램으로 사이트가 봇이라고 느끼지 못하고, 브라우저라고 생각하게 되어 access 요청을 받아준다.
이를 실행하는 방법은 다음과 같다.
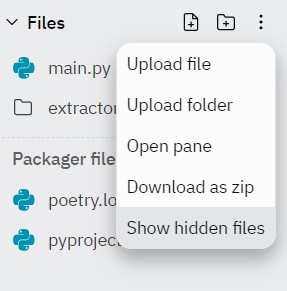
먼저 위에 점 세개를 클릭한뒤, Show hidden files를 클릭해준다.
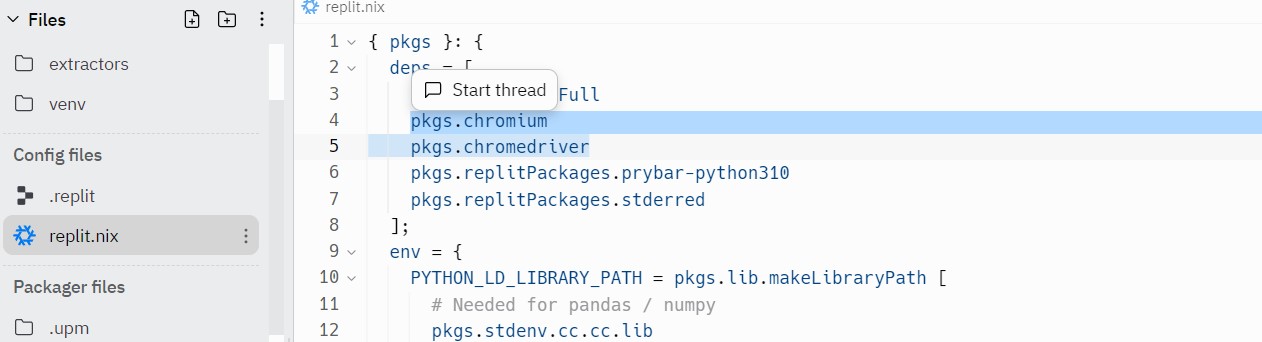
그렇게 하면, replit.nix라는 파일이 보이는데, 거기에 드래그를 한 부분 처럼
pkgs.chromium
pkgs.chromedriver이라고 적어주고 Run을 한다. 그러면 자동으로 설치가 완료된다.
⦁ 3~6줄
그럼 이제 main으로 돌아가서 Selenuim에 필요한 코드를 적어준다.
from extractors.wwr import extract_wwr_jobs
from selenium import webdriver
from selenium.webdriver.chrome.options import Options첫번째 코드는 우리는 파이썬에게 이 extractors 폴더의 wwr 파일에 있는 extract_jobs를 import 하라는 뜻이다.
이처럼 파일의 함수를 import하고 싶으면
< from 폴더이름.파일이름 import function이름 > 이라고 하면 된다.
세번째 코드는 Replit 안에서 브라우저가 동작하게 몇가지 옵션을 전달해야 하기 때문에 Options를 import 해 주었다.
⦁ 7~9줄
options = Options()
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")Options()의 instance라는 것을 알려주도록 options를 만들어준다.
다음 2,3번째 코드는 replit만을 위해 있는 코드이므로 아직 신경쓰지 않아도 된다.
⦁ 11~14줄
browser = webdriver.Chrome(options=options)
search_term = "phython"
browser.get(f"https://kr.indeed.com/jobs?q={search_term}&limit=50")
soup = BeautifulSoup(browser.page_source, "html.parser")첫번째 줄은 크롬 브라우저를 만들어준다.
검색 단어는 phython으로 해주고,
세번째 줄은 '브라우저야 이 페이지를 방문해줘' 라는 뜻이다.
마지막 줄은 4일차 때 배웠던 것과 같이 페이지의 소스코드를 볼 수 있게 하기 위한 것이다.
이를 실행하면
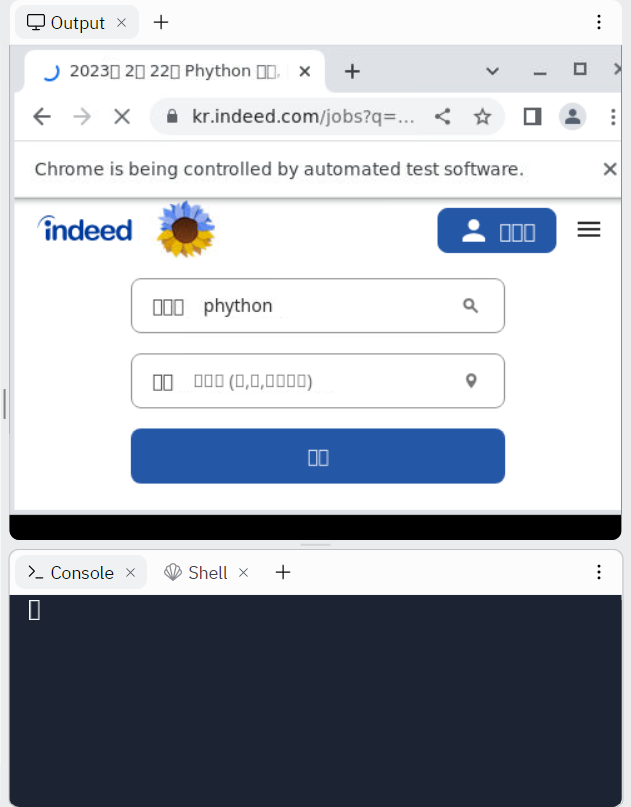
이처럼 작은 창으로 사이트에 접속이 가능하게 된다.
⦁ 16~17줄
job_list = soup.find("ul",class_="jobsearch-ResultsList")
jobs = job_list.find_all("li",recursive=False)먼저 사이트 소스코드에서 많은 li중에 직업공고의 내용을 포함하고 있는, li를 찾은뒤, 그 li가 어느 ul에 속한지를 찾는다.
그 결과 그 ul의 class가 "jobsearch-ResultsList"라는 것을 확인 했으므로, find method를 써줘서 job_list에 넣어준다.
그 다음 jobs = job_list.find_all("li")를 해주었는데, 이렇게 했을때 나타나는 문제점이, 올라와 있는 공고보다 더 많은 수의 li가 확인 된 것인데, 그 이유가 li태그의 하위 li태그들 까지 전부 count된 것이기 때문이다. 따라서 이러한 현상을 없애기 위해서는 한단계 밑의 li만 찾도록 만들어야 하는데, recursive=False가 그 해결방법이다.
⦁ 19~24줄
for job in jobs:
zone = job.find("div",class_="mosaic-zone")
if zone == None:
print("job li")
else:
print("mosaic li")중간에 결과를 출력해 보았을때,
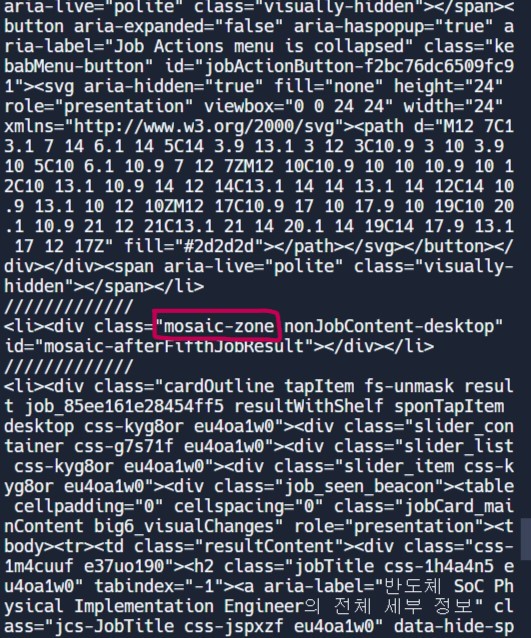
이런식으로 나오게 되는데, 사진에 표시된 mosaic-zone이라는 것은 직업 공고가 아니다. 따라서 이 부분을 지우는 작업을 해야한다.
for loop를 돌리면서, job에서 mosaic-zone이 포함된 li를 zone이라고 정의한뒤, zone이 None이면, "job li"라고 하고, 그렇지 않다면 "mosaic li"라고 출력한다.
이 말의 뜻은 우리가 찾아놓은 li 사이에 class="mosaic-zone"인 div를 찾으려 하는 것이다. 만약 그 div를 찾으면 우리가 "mosaic-zone"을 가진 li안에 있다는 소리이고, 못찾으면 직업을 가지고 있는 li안에 있다는 소리이다.
⦁ 결과
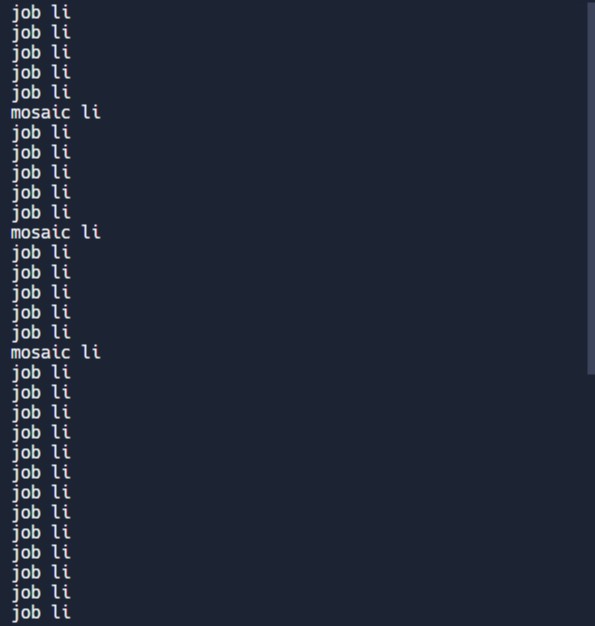
결과를 출력해 봤을 때, job li와 mosaic li가 정확하게 구분되어 나오는 것을 확인 할 수 있다.
