[논문] Metadata Embeddings for User and Item Cold-start Recommendations (LightFM) 정리
0. 요약
user와 item의 속성 정보(content feature)의 잠재 변수(latent factor)를 선형 결합의 형태로 표현한 Hybrid Matrix Factorization 모델을 제안.
1. Introduction
Cold-start 문제를 해결하는 추천 알고리즘을 만드는 것은 여전히 어려운 일이다. user와 item에 대한 latent factor를 효과적으로 표현하기 어렵기 떄문에, 기존의 MF는 이러한 Cold-start 상황에서 매우 낮은 성능을 보인다.
Content-based model은 item의 metadata를 활용함으로써 이러한 문제를 해결할 수 있지만, Collaborative information을 활용할 수 없는 단점이 있어 user에 대한 Cold-start 문제는 여전히 남아있다.
패션 쇼핑 서비스인 Lyst에서는 다음과 같은 3가지 문제를 해결하기 위해 LightFM 이라는 추천 알고리즘을 개발한다.
-
매우 많은 item이 존재함.
- 하루에 수만개의 새로운 item이 등록되고, 8백만개 이상의 item이 존재
- data가 Sparse 해짐
-
유행에 민감한 패션 업계.
- 짧은 기간의 데이터만 활용 가능함.
-
대다수의 user가 첫 방문한 user임.
- cold-start문제를 발생시킴
LightFM은 hybrid content-collaborative 모델로 기본적으로 MF 모델(collaborative)과 유사하며, content-based 모델과 같이 content feature에 대한 함수(e.g. linear combination)를 활용한다.
이를 통해, Cold-start 에서는 CB 모델과 유사한 성능을, Warm-start에서는 MF 모델과 유사한 성능을 보이게 된다.
2. LightFM
2.1 Motivation
LightFM 은 다음의 두가지를 만족하기 위해 고안되었다.
-
interaction data로 부터 user와 item에 대한 representation을 학습할 수 있을 것
+ latent representation을 활용하여 해결
+ latent representation을 통해 Content-based 모델과 유사한 성질을 가질 수 있으며, 하나의 item에 인터랙션을 한 유저들에게도 그와 유사한 다른 item을 추천해주는 것이 가능함 -
새로운 user와 item에 대해서 적용가능 할 것
- item과 user를 그들의 content feature에 기반한 representation을 생성함으로서 해결- linear combination을 활용 (denim jacket = denim + jacket)
2.2 The Model
item과 user는 여러개의 content features를 가지고 있다고 가정한다.
(item : 색상, 가격, 종류, etc / user : 국적, 나이, 성별, etc)
각각의 feature는 고유한 embedding vector를 가지고, 특정 item과 user의 content feature들의 embedding vector의 합이 해당 item과 user의 latent representation이 된다.
: set of Users, : set of Items
: set of user features, : set of item features
,
: user representation, : item representation
최적화를 위한 objective function은 likelihood를 사용하며 다음과 같다.
최적화 알고리즘은 asynchronous stochastic gradient descent를 활용한다.
3. Experiment
Dense / Sparse 환경에서의 성능을 확인하기 위해 두가지 데이터 셋에 대해서 실험을 수행한다.
- Dense interaction data : MovieLens
- Sparse interaction data : CrossValidated
3.1 Experimental Setup
-
Warm-start
: 20%의 interaction pair를 random하게 sample하여 test set을 생성
: !모든 item과 user는 train set에 존재 -
Cold-start
: 20% interaction pair를 train set에서 추출해서 test set을 생성(train에서 제거)
: content metadata(tag)만 있는 상황을 가정함 -
평가 지표
: ROC AUC
3.2 Experiment Result
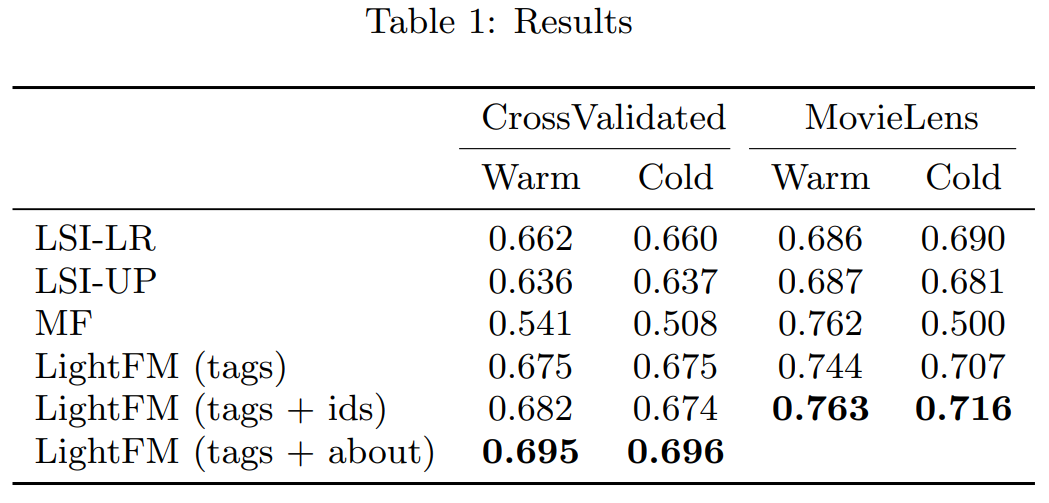
Warm-start, Cold-start, Dense, Sparse 환경 모두에서 뛰어난 성능을 보인다.
4. Usage
4.1 Tag Embedding

LightFM은 user-item interaction으로 부터 semantic relationship을 학습한다. 이는 word2vec, GloVe와 같은 word embedding과 유사한 결과를 보이게 된다.
이 결과를 활용해
- Tag 추천
: user에게 적합한 검색어, tag를 추천 - 장르/카테고리 추천
: item을 특정 장르, 카테고리로 분류
을 할 수 있다.
