
공부 과정을 기록하는 페이지입니다. 다음 원칙을 지켰는지 확인합니다.
1. 레퍼런스에서 어떤 부분을 더 발전시켰는지
2. DA에서 사용하는 언어와 개념을 나의 언어로 설명할 수 있는지
레퍼런스를 더 발전시킨 내용
Bigquery API 활용
용량이 큰 데이터 프레임을 pandas로 전처리하다보니 코렙에서 세션 데드 현상이 너무 빈번하게 발생했다. DB를 활용해서 필요한 데이터만 바로 코렙으로 뽑아와야 겠다는 생각이 절실히 들었다.
빅쿼리에 가입 후 버킷을 만들어서 CSV 파일을 업로드하고, 빅쿼리에 CSV 파일을 table로 import 시켰다. 빅쿼리에 import 시킨 table을 코렙에서 사용하기 위해(즉, API를 활용하기 위해) 다음과 같은 라이브러리를 활용했다.
from pandas.io import gbq빅쿼리에서 쿼리문이 제대로 작동하는 것을 확인하면서 코렙에 table을 불러왔다. 사용한 쿼리문은 다음과 같다.
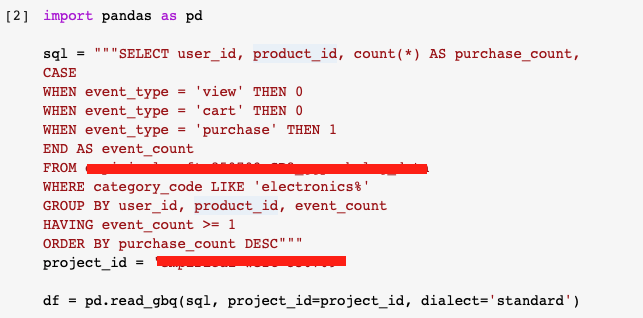
다시 보니까 중복되는 기능의 쿼리문이 눈에 보인다. 하나씩 복기해보자면, user_id, product_id 별로 테이블을 그루핑한 다음에 event_count가 1인 데이터(=구매 데이터) 중에 Electronics 제품만 조회하도록 조건을 걸었다. event_count가 어떤 내용인지는 CASE~END 쿼리문을 보면 알 수 있다.
SELECT문에서는 user_id, product_id 별로 그루핑된 정보를 리턴하도록 했고, agg 함수로 count를 사용하여 각 유저 별로 구매한 개별 product의 갯수를 확인할 수 있도록 했다.
마지막으로 의도한대로 작동하는 쿼리문인지 확인하기 위해 특정 아이템을 특정 유저가 구매한 횟수를 위의 쿼리 결과와 비교했다(한 두명 정도..).

그리고 코렙에서 pivot을 걸어서 위와 같은 TF-IDF 형태의 table을 만들었다. product_id를 인덱스에 두고 싶었는데 그렇게 되면 행의 크기보다 열의 크기가 더 큰 차원의 저주가 발생할 것 같았다.
일단 가장 급한 메모리 부족 문제는 해결했다. 빅쿼리를 사용한 김에 구글 데이터 스튜디오도 활용해봐야겠다. 희소문제를 어떻게 해결하는지가 앞으로 프로젝트의 관건이 될 것 같다.
