
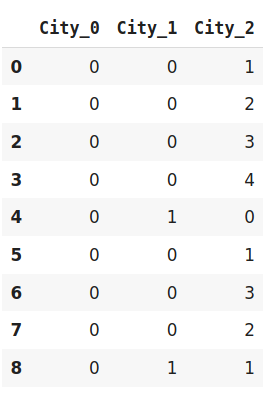
- baseN encoding : N 값을 설정해 2진 분류 이상의 분류 체계를 사용하는 encoding 방법. 범주가 많아서 one-hot encoding으로 처리하기 곤란한 경우 baseN encoding을 사용함. N=1은 one-hot encoding의 결과와 같으며, N=2는 binary encoding과 결과가 같음. 아래 이미지는 feature 세 개로 도시 8개를 5진분류한 예
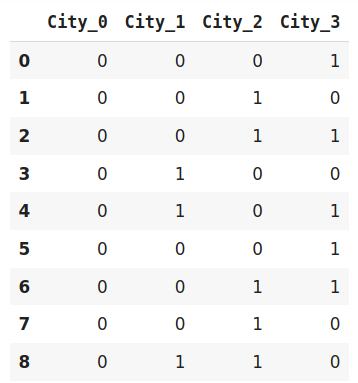
- Binary encoding : 범주형 변수를 분류할 때 사용함. 각 범주는 먼저 서수(10진법)으로 변환된 뒤 이진수로 변환됨. 이진 인코딩은 one-hot encoding 보다 적은 feature를 사용하기 때문에 차원의 저주를 줄여줄 수 있음. 즉, 카테고리의 수가 많을 때 유용함. 아래 이미지는 feature 네개를 활용해 이진분류로 도시 8개를 표현하는 예
-
CatBoost Encoder : 범주형 변수를 분류할 때 사용함. Boost encoding의 단점을 해결한 최신의(?) 기법. 범주형 특성을 수치적 특성으로 전환하는 코딩 방법임. 예를 들어 'A'라는 범주를 인코딩 값으로 범주 A의 label의 평균/중앙값 등을 사용함. 이 방법은 Data leakage 문제를 일으키는데, Catboost는 5열의 A 값을 인코딩하기 위해 3,4열의 A값을 사용함. 즉 현재 데이터의 타겟 값을 사용하지 않고 이전 데이터의 타겟 값을 사용하여 Data leakage를 방지함. 사용이 쉽고(parameter 조정이 거의 불필요하다고 함), 숫자로의 전환이 빠름
-
Count Encoder : 각 범주의 갯수를 집계한 뒤 그 값으로 인코딩하는 방법. A 범주가 123개가 있다면 A 범주는 123으로 인코딩됨. 집계된 값이 같을 경우 같은 숫자가 부여되기 때문에 충돌이 일어날 수 있음. 이 방법은 이상치에 예민하기 때문에(이상치가 모두 count됨) normalized한 뒤 사용함
-
Hashing : one-hot encoding처럼 새로운 차원을 만들어서 범주를 나타내는 방법. 'n_component' attribute로 생성하는 차원의 갯수를 조절할 수 있음. 각 변수에 고유의 값을 부여하여 인코딩함. 적은 차원으로 많은 cardinality를 표현하려는 경우 같은 해시 값이 부여되어 충돌할 수 있음(https://haehwan.github.io/posts/sta-Hashing/)
-
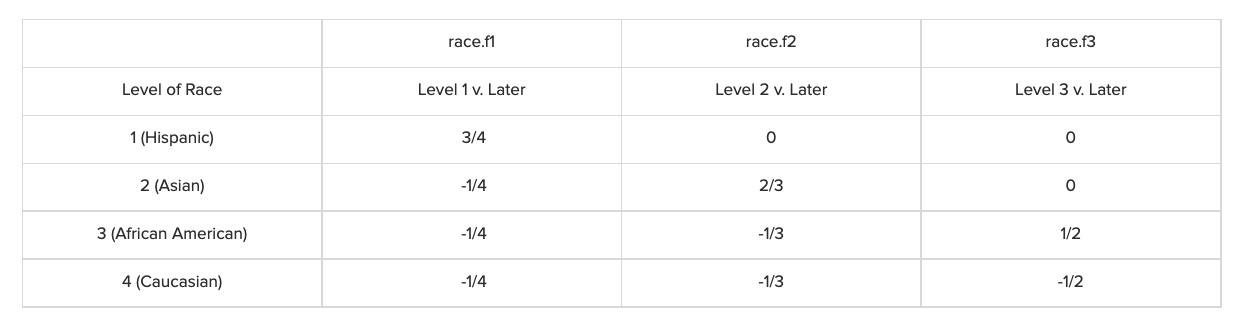
Helmert Coding : 범주형 변수의 각 level(ex. 히스패닉, 아시안, 아프리카-아메리카, 백인)을 후속 level의 평균과 비교하는 방법. 예를 들어,히스패닉은 아시아, 아프리카-아메리카, 백인의 종속변수의 평균으로 비교하고, 아시안은 아프리카-아메리카, 백인의 평균, 아프리아카-아메리카는 백인의 종속변수와 비교함
- Leave one out encoding : 해당 row를 제외한 종속변수값들의 평균을 이용해 범주형 변수값들을 인코딩하는 방법
