
Random Forests 주요 라이브러리
- category_encoders
- ipywidgets
- scikit-learn
1. Random Forests
- 결정트리모델은 한 개의 트리만 사용하기 때문에 한 노드에서 생긴 에러가 하부 노드에서도 계속 영향을 주는 특성이 있습니다.
- 그리고 트리의 깊이에 따라 과적합되는 경향이 있습니다. 이러한 문제를 해결하기 위해 앙상블 모델인 랜덤포레스트 모델을 사용합니다.
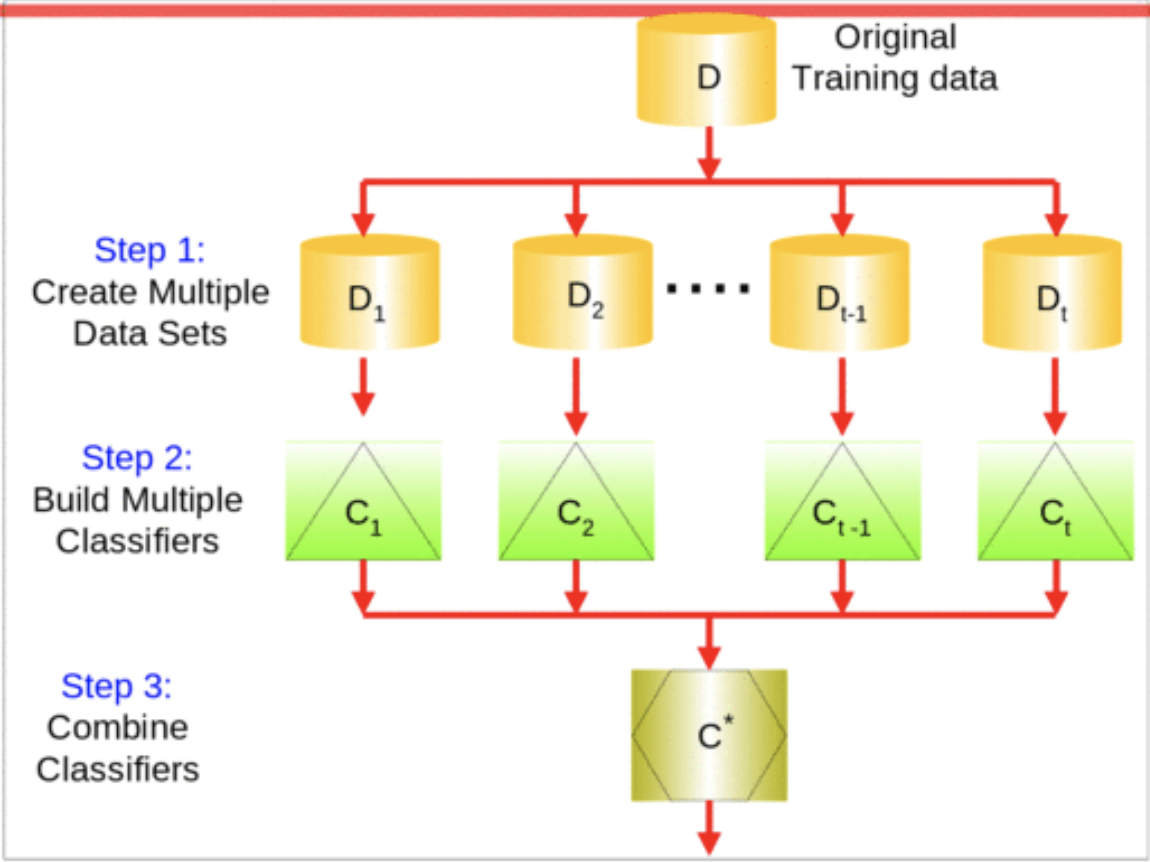
1) Ensemble model
- 앙상블 방법은 한 종류의 데이터로 여러 머신러닝 학습모델(weak base learner)을 만들어 그 모델들의 예측결과를 다수결이나 평균을 내어 예측하는 방법입니다.
- N개의 결정트리는 독립적으로 만들어지며(이후에 정리할 boosting 모델과 중요한 차이점입니다), 부트스트랩이라는 샘플링 과정으로 N개의 결정트리를 만듭니다.
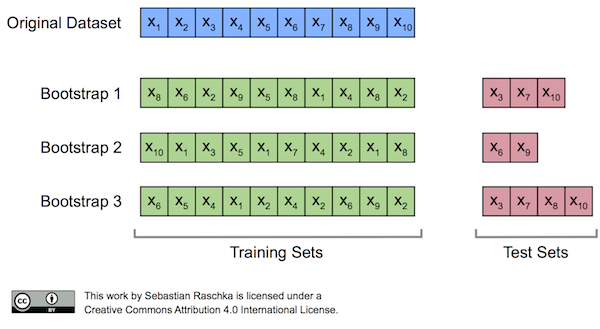
2) 부트스트랩
- 앙상블에 사용하는 작은 모델들은 부트스트래핑이라는 샘플링 과정으로 얻은 부트스트랩세트를 사용하여 학습합니다.
- 부트스트랩은 원본 데이터에서 복원추출로 여러개의 샘플을 만드는 방법입니다. 복원추출이기 때문에 부트스트랩세트에는 같은 샘플이 들어갈 수 있습니다. 이론 상 약 0.368 비율의 샘플이 부트스트랩세트에 포함되지 못합니다.
- 이렇게 부트스트랩세트에 포함되지 못한 데이터는 test 데이터로 사용합니다. 부트스트랩 과정에서 포함되지 못한 샘플을 Out of Bag 샘플이라고 부릅니다.
- 샘플 뿐만 아니라 특성도 무작위로 선택됩니다. 특성 n개 중 일부인 k개의 특성을 선택하고, 이 k개에서 최적의 특성을 찾아내어 분할합니다. 이때 k개는 일반적으로 을 사용합니다.
- 이렇게 부트스트랩으로 만들어진 샘플과 무작위로 선택된 특성을 이용하여 N개의 트리를 만들고, OOB 데이터로 검증을 하여 N개의 결과를 도출합니다.
3) bagging
- 부트스트랩세트로 만들어진 기본모델들을 합치는 과정을 Bagging(
BootstrapAggregating)이라고 합니다. 회귀문제일 경우 기본모델 결과들의 평균으로 배깅을 하고, 분류문제일 경우 다수결로 가장 많은 모델들이 선택한 범주로 예측합니다.
4) Ensemble model이 과적합이 적은 이유
- 결정트리는 데이터에 과적합하는 경향이 있습니다.
- Ensemble 모델은 데이터(더 정확히는 bootstrap set)에 과적합된 모델을 여러개 만든 뒤 합계(평균/다수결)을 냅니다. 이 합계 과정에서 개별 모델의 과적합된 특성은 깎여나갑니다. 다른 말로 모델들이 일반적인 특성에 수렴합니다.
2. Modeling
1) OneHotEncoding vs. OrdinalEncoding
- tree 모델에서 OneHotEncoding을 사용하면 class가 많은 feature가 분기에서 불리해집니다.
- 트리구조에서는 중요한 특성이 상위노드에서 먼저 분할이 일어나는데, 만약 high cardinality를 가진 특성이 중요한 특성이라면 OneHotEncoding이 이 특성을 뿔뿔이 흩어놓습니다. 하여, 이 특성은 상위에서 분기될 기회를 잃습니다.
- 결과적으로 원핫인코딩의 영향을 받지 않는 수치형 특성이 상위노드를 차지할 기회가 높아지고 전체적인 성능 저하가 생길 수 있습니다.
- 이런 이유 때문에 tree 모델에서는 주로 OrdinalEncoding을 사용합니다. 물론, OrdinalEncoding에도 주의할 점이 있습니다.
- 범주들을 순서가 있는 숫자형으로 바꾸면 원래 그 범주에 없던 순서정보가 생깁니다. 이런 이유로 순서형 인코딩은 범주들 간에 분명한 순위가 있을 때 그 연관성에 맞게 숫자를 정해주는 것이 좋습니다.
- 하지만, tree 모델은 범주의 순서를 사용하여 분기하는 모델이 아니기 때문에 OrdinalEncoding을 사용하여도 무방하지만, 해석에는 주의해야합니다.

-