
tree model에서 주로 사용하는 라이브러리
- category_encoders : object type 인코딩 라이브러리
- graphviz : 트리 시각화 라이브러리
- scikit-learn : tree model 라이브러리
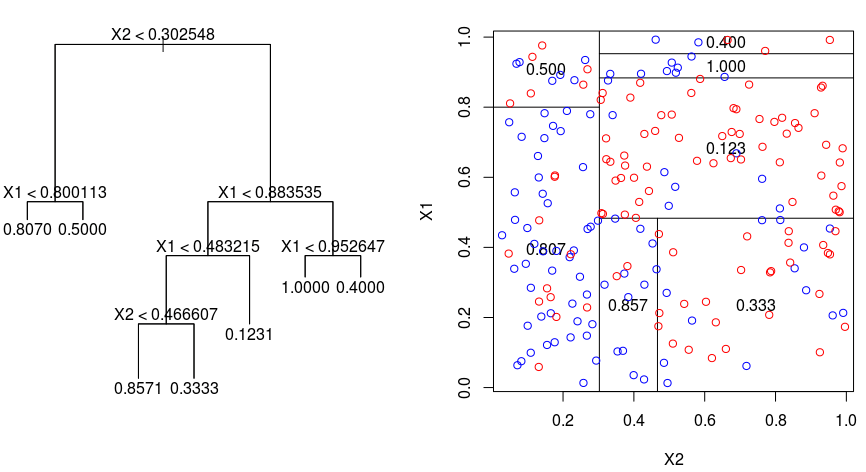
1. Decision Trees
- 분류와 회귀문제에 모두 적용 가능한 모델입니다.
- 데이터를 분할하여 마지막 노드에서 input value의 output value를 예측합니다.
- 결정트리라는 데이터를 분할하면서 스무고개처럼 정답을 찾아가는데, 이때 중요한 건 어떤 feature를 어떻게 분할하는지입니다.
- 결정트리가 데이터를 분할하는 기준은 지니불순도입니다. 불순도의 감소가 큰 feature를 우선적으로 분할합니다.
- 지니불순도란, 타겟 데이터의 클래스 비중을 의미한다고 생각하면 간편합니다. 클래스의 비중이 한쪽이 높을 수록 지니불순도가 낮습니다. 지니불순도가 낮을 수록 해당 feature는 타겟을 더 분류할 수 있다는 의미입니다.
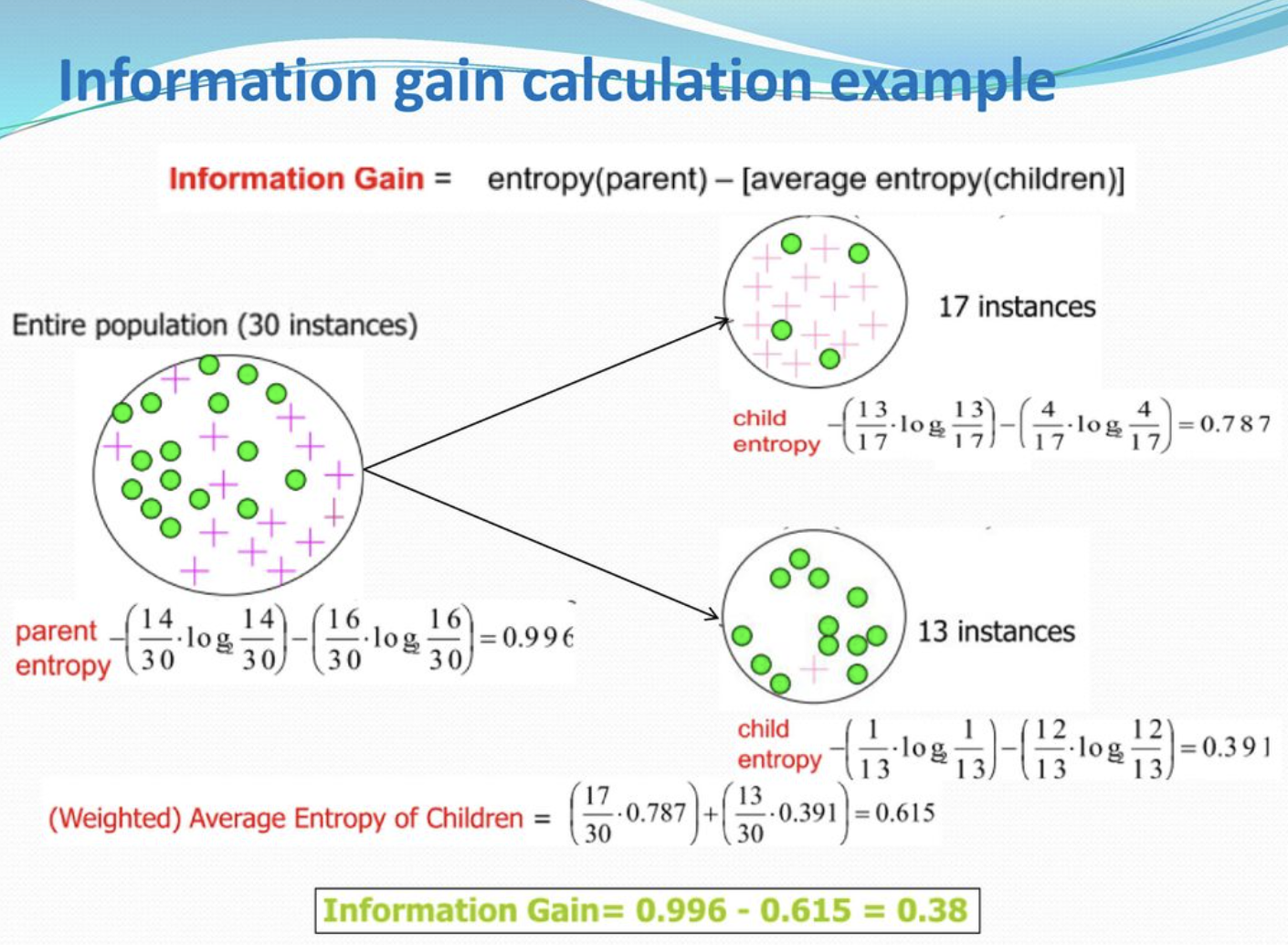
- 불순도 감소가 큰 feature를 고르는 과정은 다음과 같습니다.
- feature의 class 별로 앤트로피를 계산한 뒤 feature class의 평균 앤트로피를 계산하여 뺍니다. 이 값을 Information gain이라고 부릅니다.
- feature 내부의 지나불순도(앤트로피)가 작을 수록(즉, 클래스 비중이 불균형할 수록) Information gain의 값은 커집니다.
- Information gain의 값이 크다는 의미는 해당 feature로 분기했을 때 불순도의 감소가 최대가 된다는 의미로도 해석할 수 있습니다. feature의 불균형의 Information gain으로 표현됐기 때문입니다.
- tree 모델은 Information gain이 높은 feature부터 분기해가며 train data를 학습해나갑니다.
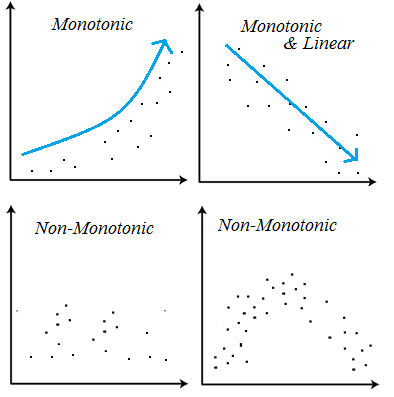
- 위와 같이 분할해나가는 속성 덕분에 트리모델은 선형모델과 달리 비선형, 비단조 데이터 분석에 용의합니다.
2. Modeling
1) 인코딩
- tree 모델은 feature의 클래스에 따라 분기하기 때문에 feature class의 관계에 덜 예민합니다.
- 예를 들어, 1~90살까지 분포되어 있는 age feature를 tree model은 Information gain이 가장 큰 지점, 예를 들어 45살에서 분기시킵니다. 그 다음 1~45살을 20살을 기준으로 분할하고, 1~20살을 1~10살로 분할해서 마지막 노드에 샘플이 하나가 남을 때까지 분할합니다.
- 사실상 연속형 변수를 명목형 변수처럼 다루고 있다는 것을 알 수 있습니다.
- 이런 이유로 tree 모델을 인코딩할 때는 문자형 변수를 정수로 치환하는 OrdinalEncoding을 주로 사용합니다. 명목형 변수가 OrdinalEncoding으로 순서 정보를 갖게 되어도 tree 모델은 개의치 않기 때문입니다.
2) feature 간 공분산성 문제
- tree 모델은 선형 모델과 달리 feature 간 공분산성에도 덜 예민한 편입니다.
- 데이터 안의 feature가 서로 영향을 주지 않고, 개별 feature가 분기하여 모델을 만들기 때문에 다른 feature의 영향에서 자유롭습니다.
3) 과적합 문제
- tree 모델은 마지막 leaf에 하나의 값이 남을 때까지 분기합니다(min_samples_leaf = 1).
- 이러한 특성 때문에 tree 모델은 train 데이터의 특성을 과도하게 학습하여 일반화 성능을 잃어버리게 됩니다.
- 과적합 문제를 해결하기 위해 tree 모델의 min_samples_split, min_samples_leaf, max_depth 등의 하이퍼파라미터를 조정합니다.
4) 특성중요도
- 선형모델에서 회귀 계수로 특성과 타겟의 관계를 확인했다면 결정트리에서는 특성중요도로 특성과 타겟의 관계를 확인할 수 있습니다. 이 값으로 특성이 얼마나 일찍 그리고 자주 분기에 사용됐는지 알 수 있습니다.
- 물론, 특성중요도의 위와 같은 특성으로 feature 내 클래스가 많으면 더 중요한 특성으로 여겨지는 착시현상이 일어나기도 합니다(class가 많으면 더 많이 분기하기 때문에).
- 이 문제를 해결하기 위해 permutatuon importance와 같은 방법을 사용하는데, 이 방법에 대해서는 추후 정리하겠습니다.

-