

이번 포스팅에서는 캐글의 Open University Learning Analytics Dataset을 이용하여 랭글링의 단계 중 Sturcture와 Enriching을 중심으로 정리하려 한다.
데이터 랭글링은 raw data를 쉽고 효율적으로 가공하고 분석할 수 있도록 변환하는 과정이다.
보통 아래 6단계를 거친다.
- Discovery : EDA 단계
- Structure : raw data를 mapping하는 단계
- Cleaning : 이상치/결측치를 제거하는 단계
- Enriching : 추가로 필요한 data를 보강하는 단계
- Validating : 랭글링한 데이터의 일관성을 검증하는 단계
- Publishing : data를 활용할 수 있도록 Publishing하는 단계
1. Structure
여러개로 흩어져 있는 table을 merge하기 전에 어떤 문제를 해결할지 정해야한다.
주어진 data로 설정할 수 있는 문제는 다음과 같다.
- 회귀문제 : 이전 학기의 시험 성적과 수업 참여도 등을 통해 특정 학생이 다음 학기 수업에 어떤 성적을 낼지 예측한다.
- 분류문제 : 이전 학기의 시험 성적과 수업 참여도 등을 통해 특정 학생이다음 학기 수업을 취소할지 안할지 예측한다.
이렇게 문제를 설정하면 문제를 풀기 위한 table을 merge 할 수 있다.
1) 먼저 <어떤 학생>이 <어떤 수업>을 듣는지 알 수 있는 data table을 만든다.
#학생의 수업 등록정보와 수업 정보, 학생정보를 merge하여 <어떤 특성의 학생>이 <어떤 수업>을 <언제 등록하고, 등록취소>했는지 확인할 수 있는 table을 만듦
#다음 학기 수업을 계속 들을지, 중도에 취소할지 예측할 수 있는 feature로 활용할 수 있음
reg_courses = reg.merge(courses, on = ['code_module', 'code_presentation'], how = 'inner')
reg_courses_info = reg_courses.merge(info, on = ['code_module', 'code_presentation', 'id_student'], how = 'inner')
reg_courses_info.T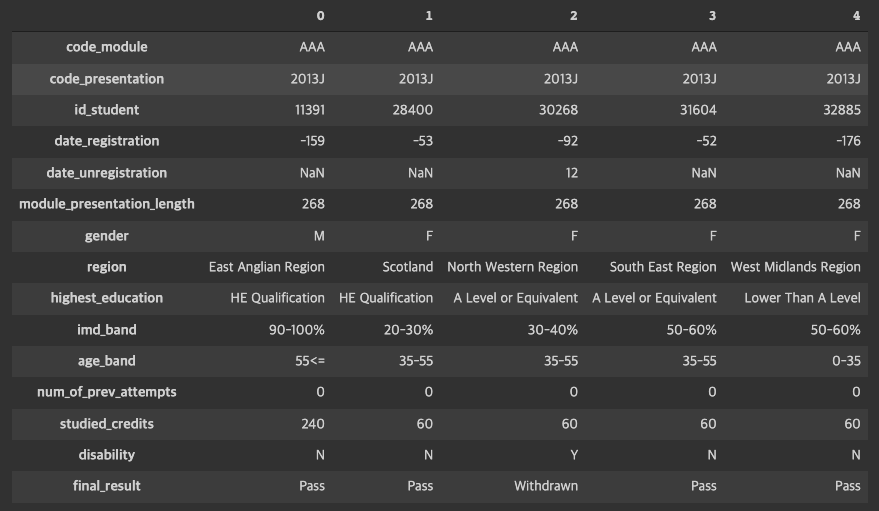
2) 그 다음 학생들의 수업 참여도를 알 수 있는 data table을 만든다.
#수업의 활동 유형을 설명하는 material과 학생의 활동 정도(클릭수)를 merge하여 수업의 유형 별로 학생의 참여도(클릭수)를 설명하는 data를 만듦
vle_material = vle.merge(materials, on=['code_module', 'code_presentation', 'id_site'], how='inner')
vle_material.isnull().sum()
vle_material.drop(columns=['week_from', 'week_to', 'date'], inplace=True) #대부분이 결측치인 columns 삭제
vle_material.T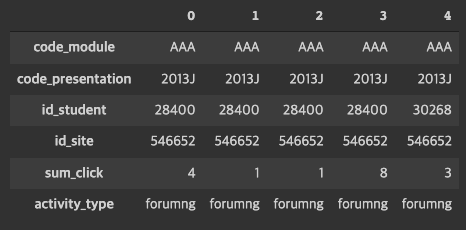
3) 마지막으로 시험(수업)의 결과를 알 수 있는 data table을 만든다.
#<수업의 시험(평가) 정보>와 <평가 결과> 결합
ass_result = ass.merge(results, on = ['id_assessment'], how = 'inner')
ass_result.T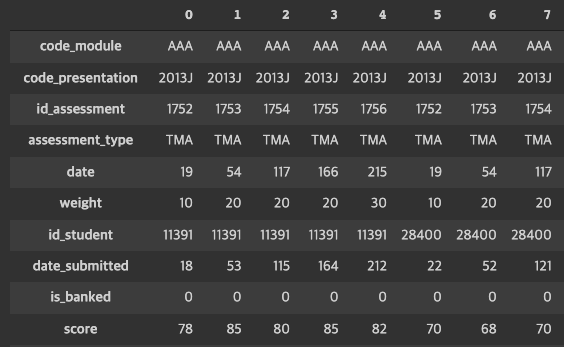
7개의 테이블을 이렇게 3개로 merge했다.
1) 학생의 개인정보(성별, 지역, 나이, 수업 등록일, 수업 취소일 등) table
2) 학생의 수업 활동 참여도 table
3) 시험(수업) 평가 결과 table
2. Enriching
Enriching는 기본적으로 feature engineering을 포괄하는 개념이다.
아래의 과정은 feature engineering과 같다.
#수업의 평가 정보와 평가 결과 결합
ass_result = ass.merge(results, on = ['id_assessment'], how = 'inner')
ass_result
#제출일이 지나서 과제를 제출한 경우(feature engineering)
ass_result['late_submission'] = ass_result['date'] - ass_result['date_submitted']
ass_result['late_submission'] = ass_result['late_submission'] < 0
ass_result
#학생 당 지각제출의 횟수 계산
total_late_count = ass_result.groupby(['id_student', 'code_module', 'code_presentation']).agg(total_late_submission = ('late_submission', sum)).reset_index()
total_late_count.head()
#학생 당 전체 과제 제출 횟수
total_count_assessments = ass_result[['id_student', 'code_module', 'code_presentation', 'id_assessment']].groupby(['id_student', 'code_module', 'code_presentation']).size().reset_index(name = 'total_assessments')
total_count = total_late_count.merge(total_count_assessments, on = ['id_student', 'code_module', 'code_presentation'], how = 'inner')
#학생 당 지각제출의 비율 계산
ass_result = ass_result.merge(total_count, on = ['id_student', 'code_module', 'code_presentation'], how = 'inner')
ass_result['late_submission_rate'] = ass_result['total_late_submission'] / ass_result['total_assessments']
ass_result.drop(columns = ['total_late_submission', 'total_assessments'], inplace = True)
ass_resultgroupby로 feature를 만드는 방법에 어느정도 패턴이 있다는 걸 알 수 있다.
1) 두개 이상의 feature를 결합하여 하나의 feature를 만든다.
2) 새롭게 만든 feature는 groupby로 셀 수 있는 class인 True / False로 만든다.
3) 관심 대상(이 경우엔 id_student)를 중심으로 새롭게 만든 feature를 groupby().sum()한다.
4) 앞에서 만든 '총계'를 기존의 table에 붙인다(merge(on = 'id_student').
#낙제 비율 계산
ass_result['fail'] = ass_result['score'] < 40
total_fails_per_student = ass_result.groupby(['id_student', 'code_module', 'code_presentation']).agg(total_fails = ('fail', sum))
total_fails_late = total_count_assessments.merge(total_fails_per_student, on = ['id_student', 'code_module', 'code_presentation'], how = 'inner')
total_fails_late['fail_rate'] = total_fails_late['total_fails'] / total_fails_late['total_assessments']
total_fails_late.drop(columns = ['total_assessments', 'total_fails'], inplace = True)
total_fails_late
ass_result = ass_result.merge(total_fails_late, on = ['id_student', 'code_module', 'code_presentation'], how = 'inner')
ass_result#학생 당 총 클릭횟수 계산
total_click_per_student = vle_material.groupby(['code_module', 'code_presentation', 'id_student']).agg(total_click = ("sum_click", sum)).reset_index()
total_click_per_student.head()모두 1 ~ 4의 반복이다.
빠른 wrangling을 위해 자주 사용하는 feature engineering의 패턴을 익혀두는 것이 좋을 것 같다.
