

머신러닝은 일반적으로 지도학습과 비지도학습으로 나뉘며, 지도학습은 예측과 분류로 기능을 나눌 수 있다.
일반적으로 예측은 1) 기존 경험을 바탕으로 예측하거나 2) 통계정보를 활용하거나 3) 기준모델을 사용하거나 4) 예측모델을 사용한다.
사실 예측모델 자체가 기존 경험과 통계정보를 활용한 것이고 기준모델은 예측모델과 선형 관계(발전적 관계)이기 때문에 어떤 사건을 예측하기 위해서는 예측모델을 만들어야만 한다고 볼 수 있다.
1. 회귀직선
무언가를 예측하기 위해서는 데이터 안에서 일정한 규칙을 찾아야하는데, 그 규칙을 선으로 표현한 것이 회귀직선이다. A가 a만큼 변화했을 때 B가 b만큼 변하는 것을 설명하는 것이다.
물론 아무렇게나 선을 그을 순 없다. 회귀선을 만들 때 중요한 개념은 '잔차'이다. 회귀선은 잔차 제곱들의 합인 RSS(residual sum of squares)을 최소화하는 직선이고, 이것을 다른 말로 '비용함수'(Cost function)이라고 부르기도 한다. 머신러닝에서는 이 비용함수를 최소화 하는 모델을 찾는 과정을 '학습'이라고 한다.
RSS
=∑𝑖=1𝑛(𝜀𝑖)2
=∑𝑖=1𝑛(𝑦𝑖−𝑓(𝑥𝑖))2
=∑𝑖=1𝑛(𝑦𝑖−(𝛼𝑥𝑖+𝛽))2 #이 모델을 앞으로 자주보게 될 것이다.
그리고 이 '학습'을 통해서 모든 잔차들의 합의 제곱이 최소인 직선을 찾아 긋는다.
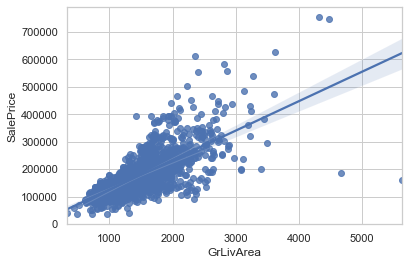
위 그래프에서
- x축에 해당하는 GrLivArea를 예측변수/설명, 특성 등으로 부르고,
- y축에 해당하는 SalePrice를 반응변수, 레이블, 타겟 등으로 부른다.
2. scikit-learn을 활용한 선형회귀모델 만들기
scikit-learn을 활용하여 모델을 만드는 순서는 보통 다음과 같다.
1) 문제를 풀기 적합한 모델을 선택하기
2) train data와 test data 준비하기
3) fit() 메소드를 사용하여 모델 학습하기
4) predict() 메소드를 사용하여 새로운 데이터 예측하기
from sklearn.linear_model import LinearRegression
model = LinearRegression() #예측모델 인스턴스를 만든다.
X_train = train[['feature']] #fit() 메소드에 적용하기 위해 pandas 행렬 형식으로 저장한다.
y_train = train[['target']]
model.fit(X_train, y_train) #train data로 모델을 학습한다.
X_test = [[4000]
y_pred = model.predict(X_test) #test 데이터를 학습한 모델에 적용하여 target 변수를 예측한다.
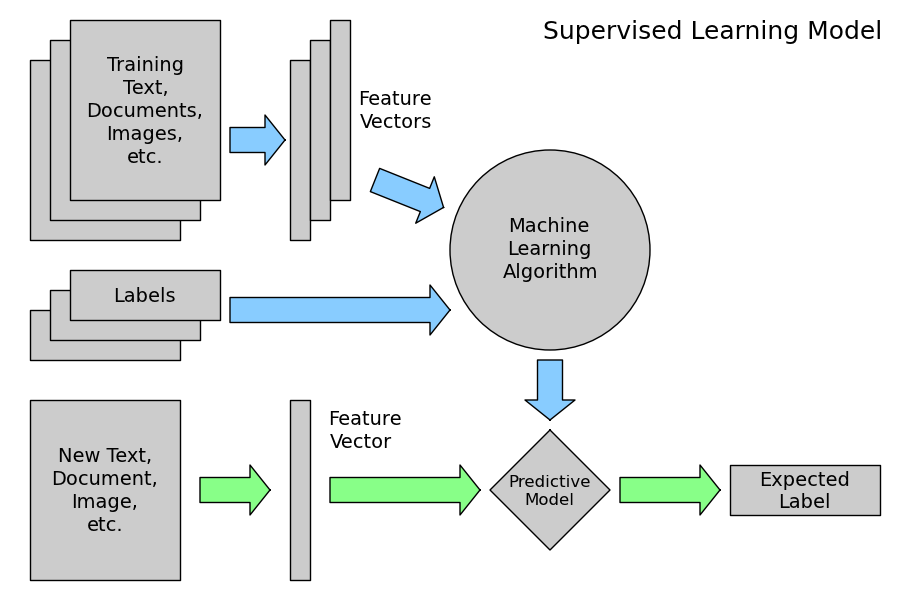
사이킷런의 과정을 위와 같은 다이어그램으로 도식화할 수 있다. 모델을 만들고자 하는 텍스트, 이미지, 음성 등에서 Feature와 Labels(지도학습의 경우)을 분리하여 Machine Learning Algorithm model을 구성한다. 이 모델이 곧 예측모델이 되는데, 이 모델에 예측/분류하고자 하는 텍스트, 이미지, 음성 등을 넣어어 Label을 예상하거나 분류하는 과정이다.
3. 선형회귀모델 계수 해석
model.coef_ #회귀계수 출력회귀계수: target에 대한 feature의 영향력을 의미한다. 회귀계수가 100이라면 feature가 1 증가했을 때 target이 100 증가한다는 의미다.
