
1 배경
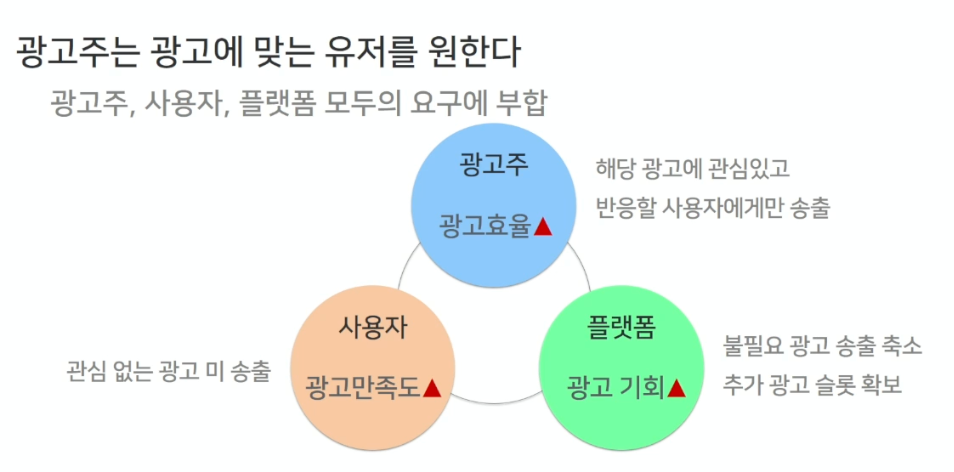
- 광고주
- 자기의 광고에 관심이 있고, 그 광고에 반응한 사용자에게만 자기의 광고가 나가기를 바람. 그렇게 되어야 광고주는 헛돈을 쓰지 않고 광고를 집행할 수 있다.
- 사용자
- 관심없는 광고가 노출되지 않아서 좋고 만족도가 올라감
- 플랫폼
- 쓸모없는 광고를 줄이고, 이 유저에게 맞는 광고만 보낼 수 있어서 많은 기회를 얻게 된다.
2 Look-alike 란?

- Look-alike (유사타겟) : 특정한 유저 그룹(seed)이 주어졌을 때, 해당 그룹과 비슷한 유저그룹을 찾아내는 모델
- Look-alike 요구 사항 : 광고 효율이 좋을 것 ( CVR이 높아야 함 )
- 더 욕심을 부리자면 CTR 과 노출량 까지 높기를 원함
- 하지만 문제사항은 다음과 같음
- 유사 targeting 을 하기 위해서는 Seed 는 "광고주가 소유" 하고 있음. 이러한 정답셋은 우리(Naver)에게 없다는것이 문제
- 그래서 네이버 플랫폼은 seed (광고주가 소유한 유저 정보)가 없기 때문에 임의로 seed를 만들어서 평가함.
- 2가지 seed set (스마트스토어 방문자, 상품페이지 조회자)를 사용하여 오프라인 테스트 진행.
- 유사 targeting 을 하기 위해서는 Seed 는 "광고주가 소유" 하고 있음. 이러한 정답셋은 우리(Naver)에게 없다는것이 문제
- 오프라인 테스트 시 Metric 은 아래와 같음
- CVR(conversion rate, 전환수/클릭수)
- CTR(click through rate, 클릭수/노출수)
- CTCVR(CTR * CVR)
- 처리량에서 고려해야 할 부분 : 1억 이상의 유저(브라우저별 익명화된 유저, 쿠키)에 대해 유사도 계산을 10분 이내로 진행 요망
3 Model Architecture
- Real-time Attention Based Look-alike Model for Recommender System(링크) 의 아이디어를 차용함
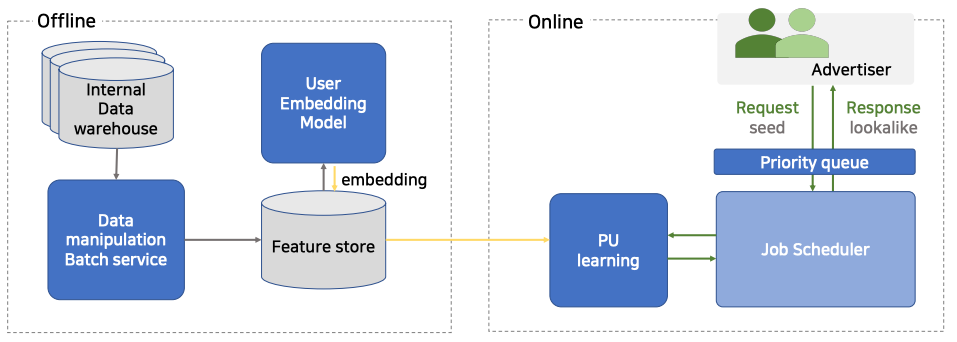
- Offline : 사용자 행태 학습 후 embedding을 만들고 이를 저장함
- Internal Data warehouse : 네이버의 각종 서비스의 사용자 행태 log 데이터
- Data manipluation Batch service : 네이버의 여러 log 데이터를 Feature로서 store에 저장
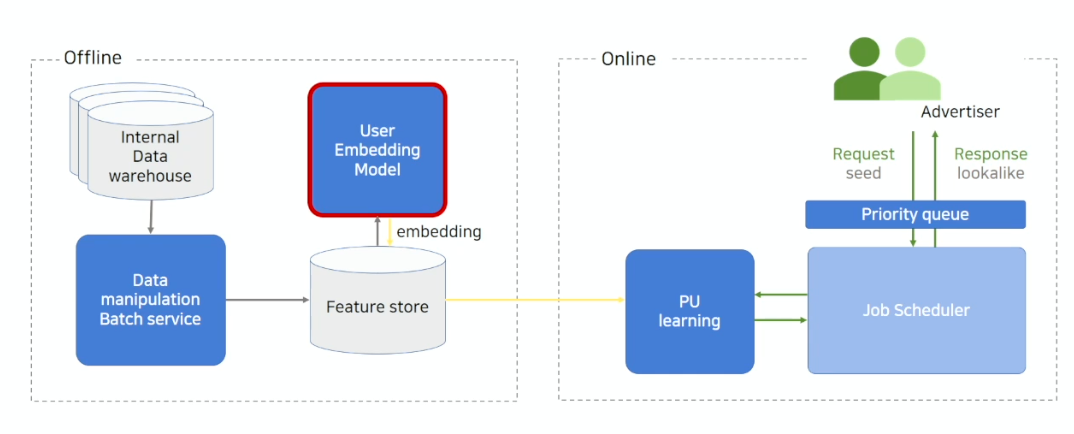
- 해당 Feature Store 를 이용하여 User Embedding Model 을 학습 후, 그 결과물을 다시 Embedding 한 뒤 이를 다시 저장함.
- 정확도가 목표이며 오프라인에서 진행되는 것이므로, 긴 기간의 데이터를 이용하여 충분한 데이터를 통해 정확한 embedding값을 계산해서 적재하고 있음
- Online : 저장된 embedding을 이용하여 실시간 요청에 따른 Look-alike learning을 진행함
- 광고주는 몇명을 늘리고, 어떤 seed 를 가지고 늘릴지를 정한 뒤 prioirty queue 에 보냄
- 광고주에게 받은 Request Seed는 priority queue에서 우선순위를 설정하여 PU learning이 진행됨.
- learning 및 inference가 끝난 결과물은 priority queue를 통해 광고주에게 전달됨.
- 이 과정 전체가 일정 시간(최대 10분) 내로 진행되어야 하기 때문에 request가 쌓이지 않도록 빠르게 처리하는 것 또한 중요함.
4 Offline Part (Embedding)
- User embedding vector 를 잘 생성하는것이 목표
- 목표(CTR, CVR, 노출, ROAS 등)에 따라 추출되는 특징이 달라짐. 이때 네이버에서는 광고주의 목표가 CVR이었기 때문에, 전환을 기준으로 임베딩을 생성함
4.1 User Embedding Model
- Multi-class classification task 에 따른 학습을 하고 있음.
- Input X : 쿠키별 사용자의 행동 데이터
- Label Y : 상품 카테고리 구매 여부
- 여러 실험 결과를 통해서 전환행태에는 상품 카테고리 구매 여부를 label로 두는 것이 가장 적절하다고 판단
- 카테고리 약 600개 (IAB audience taxonomy - purchase intent 참고)
4.2 Dataset 생성

- Input : 쿠키별 사용자의 행동 데이터
- Label : 유저가 구매한 목록의 카테고리를 one-hot으로 labeling 함.
- 유저가 여러가지 카테고리를 가져 너무 많이 구매하면 max 를 20개로 제한.
- 만약 이를 제한하지 않으면 모델에 너무 같은 유저에 대한 데이터가 중복해서 들어가 Bias 가 생길 수 있기 때문이다.

- Sampling : Negative Sampling 과정을 통해서, 학습량을 줄임
- 1:10 negative sampling 을 진행함. 즉 positive 1개당 10개의 nagative 를 학습
- sampling distribution : 카테고리가 자주 등장할수록 많이 sampling 되도록 수정함. ( log - uniform distribution )
- 1:10 negative sampling 을 진행함. 즉 positive 1개당 10개의 nagative 를 학습
4.3 Model
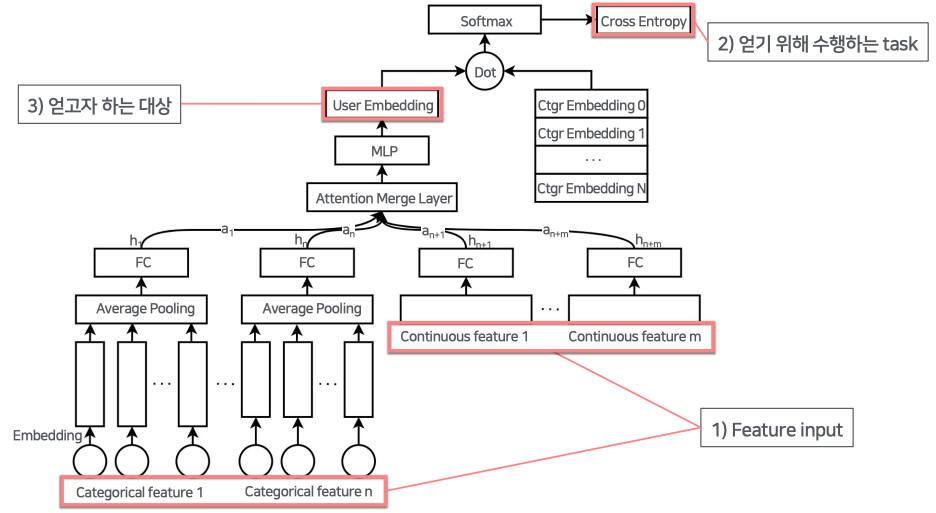
Feature Input
- 카테고리 Feature
- Categorical Feature 의 경우 ont - hot vector 로 이루어져 있어, embedding 을 통하여 continuous vector 로 바꾸어줌.
- 각 feature 들은 Average pooling 을 통하여 FC 로 합쳐줌
- embedding 을 통해 continuous feature 로 바꿔줌
- Categorical Feature 의 경우 ont - hot vector 로 이루어져 있어, embedding 을 통하여 continuous vector 로 바꾸어줌.
- 연속형 Feature : 스케일링 (min max ....)
- FC layer를 통해 차원 맞춰주기
- 차원을 맞춘 이유는 Attention Merge Layer로 feature vector 들을 합쳐주기 위함 attention score를 이용하여 weighted sum을 진행.
- attention score matrix 어떤 input이 들어오느냐에 따라 feature의 중요도를 연산하여 학습. 최종 weight 를 계산
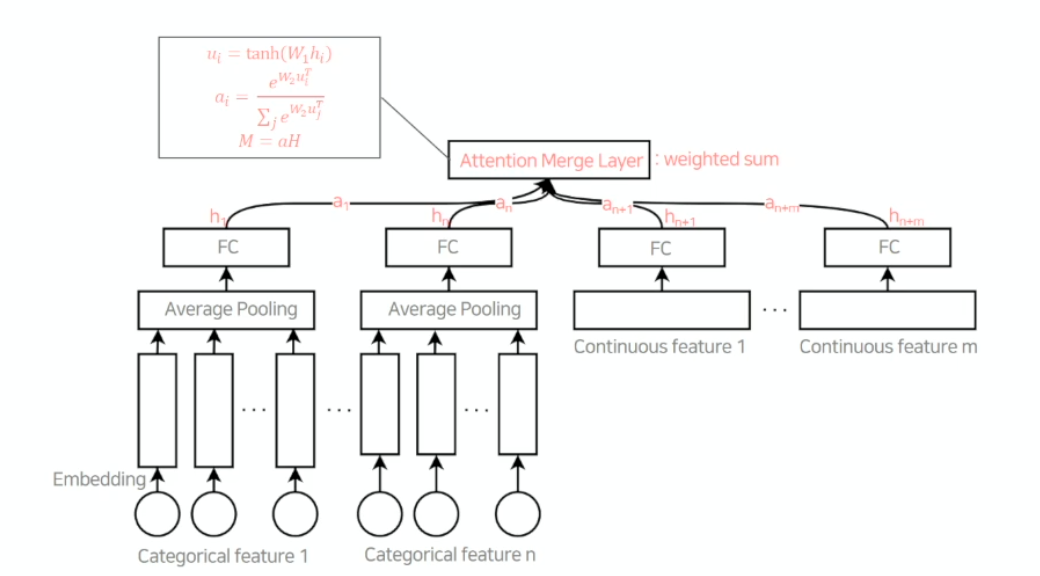
- MLP (Multi Layer Perceptron)를 지나 최종적으로 User Embedding Vector가 만들어짐
- Negative sampling을 진행했던 카테고리의 embedding matrix와 dot product 를 통해 각 카테고리별 logit을 만들어냄
- Softmax, Cross Entropy로 loss 계산
4.4 User Embedding 시각화

- 두 브랜드의 유저가 다른공간에 잘 나타나고 있는것을 볼 수 있음
5 Online Part : Look-alike Learning
- 목표 : Seed와 user embedding을 사용하여 가까운 사용자 set 반환
- Seed : 1,000 ~3M 사용자 셋 (1만~10만 권장)
- User Embedding : Offline part에서 생성
- 처리 속도 : 10분 이내 ASAP 완료
5.1 PU Learning
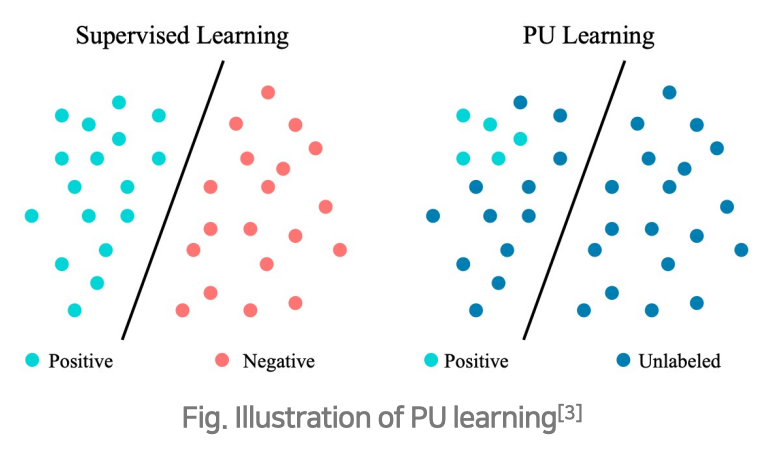
- 원래의 supervised learning에서는 positive와 negative example이 모두 존재하지만, 현재의 데이터는 positive와 unlabeled만 존재함. PU learning은 U를 positive와 negative로 분리하는 classifier를 만드는 것이 목표
- Positive example(P) : {Seed}
- Unlabeled example(U) : {전체 유저 - Seed}

- 2-stage learning
- stage 1.
- P 와 (U 전체에서 샘플링한 데이터) 을 이용해 모델을 Training
- Classifier 1 에 대해서 을 구분하도록 모델링 함
- 구분된 결과 중 positive를 , negative를 으로 표현한다.
- stage 2.
- 을 다시 샘플링하여 를 만든다.
- P와 (negative)를 학습하여 classifier 2를 만든다.
- stage 1.
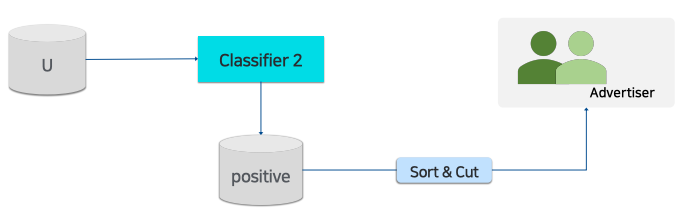
- classifier2을 이용하여 에서 positive한 user를 찾는다. positive한 확률로 sorting하여 topK를 구함 (classifier2로 추천 유저 선별)
5.2 Ex : PU Learning
-
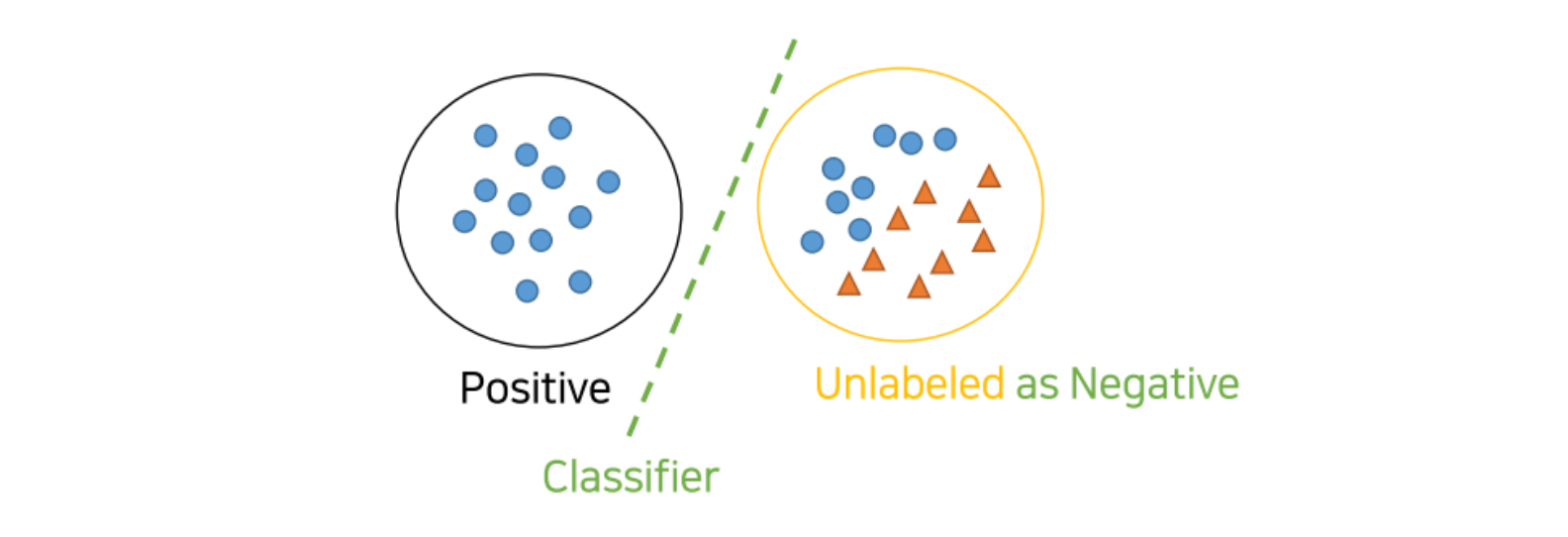
모든 Unlabeld dataset을 negative로 취급하여 P vs N 를 분류하는 clf 모델 학습
-
1에서 학습한 clf를 이용하여 Unlabed(unknown class) dataset를 scoring하고, reliable negatives(RN) set 을 만듦(비교적 Negotive에 가까운 점수를 가진 애들을 분리)

- P vs RN을 분류하는 clf 모델을 학습시킴. 그리고 남아 있던 Unlabeled dataset(즉, 2에서 Negative에 가깝다고 나오지 않은)을 scoring매기고, 추가적으로 RN에 가까운지 먼지를 측정하여 분류
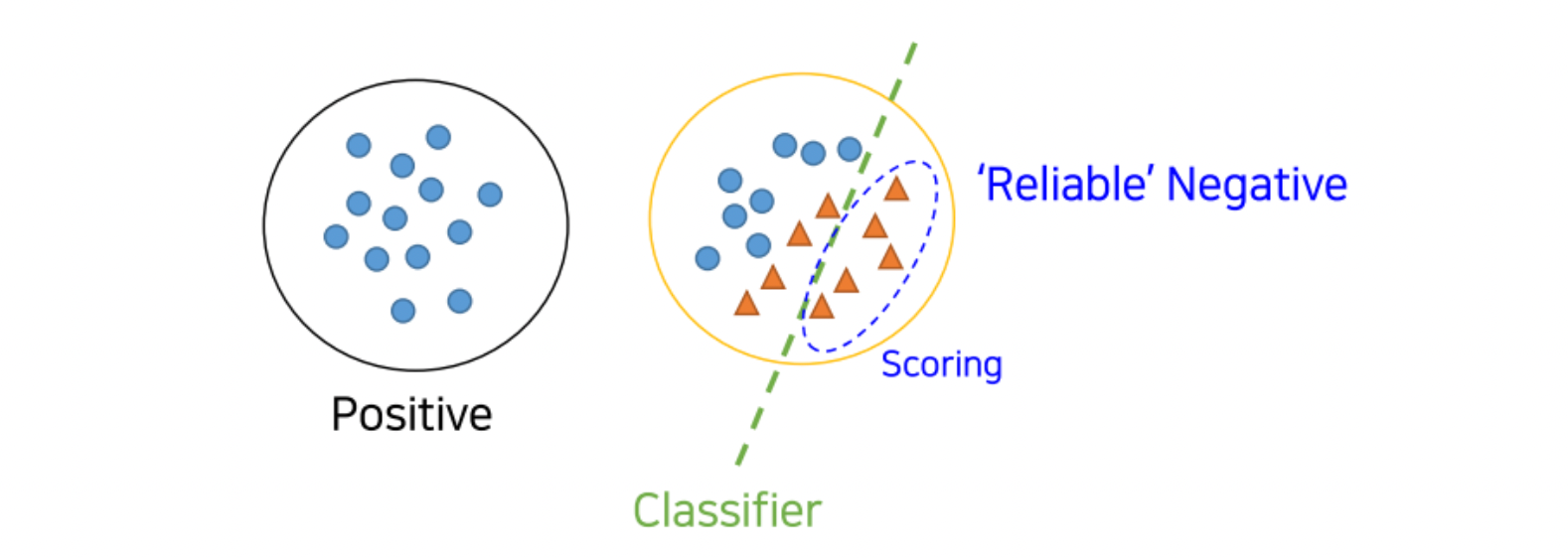
- 3 의 과정을 계속적으로 수렴할때까지 반복(iterative)
6 Service Part
6.1 서비스 시스템
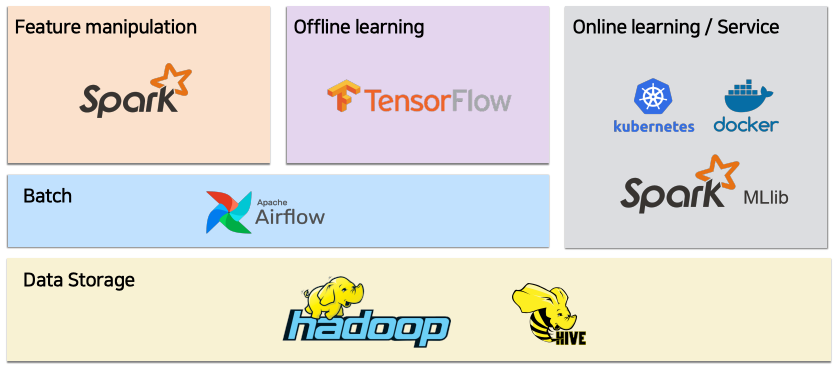
- Hadoop / Hive / Spark /Airflow 사용
- feature - manipulation : 유저 행동 데이터를 조합하여 피쳐로 생성
- offline learning : 임베딩 만드는 작업
6.2 최적화 (학습, 추론 속도 향상)
- Offline
- TF graph 최적화 : CPU 병목 제거, GPU Utilization 향상. non-TF python 코드 최소화 (CPU 를 사용하게 되므로 이를 제거), TF primitives 사용하여 자동으로 Tensor Flow 가 GPU 최적화를 하도록 함
- Data I/O 최적화 : tf.data api 사용으로 대용량 데이터 hdfs를 통해 학습 및 추론
- 결과 : 최적화 전 대비 학습 속도 600% 향상
- Online
- Spark Physical Plan 분석을 사용하여 속도는 빠를 수 있도록 최적화 ( partition 최적화, persist 등일 듯.)
- 결과 : 최적화 전 대비 학습+추론 200% 향상
7 Expreiments & Results
7.1 Offline test
- 모델이 잘 만들어지고, 괜찮은 임베딩이 만들어 지고 있는지의 피드백을 받기 위해서 오프라인 테스트를 계속 진행
- 과거 배너광고(Display Ad) data를 활용함
- 실험 그룹
- 대조군 1 : non-target ( 랜덤한 유저 )
- 대조군 2 : 2018년 look-alike 모델 ( 유저 행동 vector 와 seed vector 사이의 거리를 계산함. )
- 실험군 : 현재의 look-alike 모델
- 평가 지표 : CTCVR, CVR, CTR (중요도 순)
- 대상 광고 : 다양한 카테고리 별 광고 (중앙값 사용)
- 시드 규모 : 1M, 3M, 5M
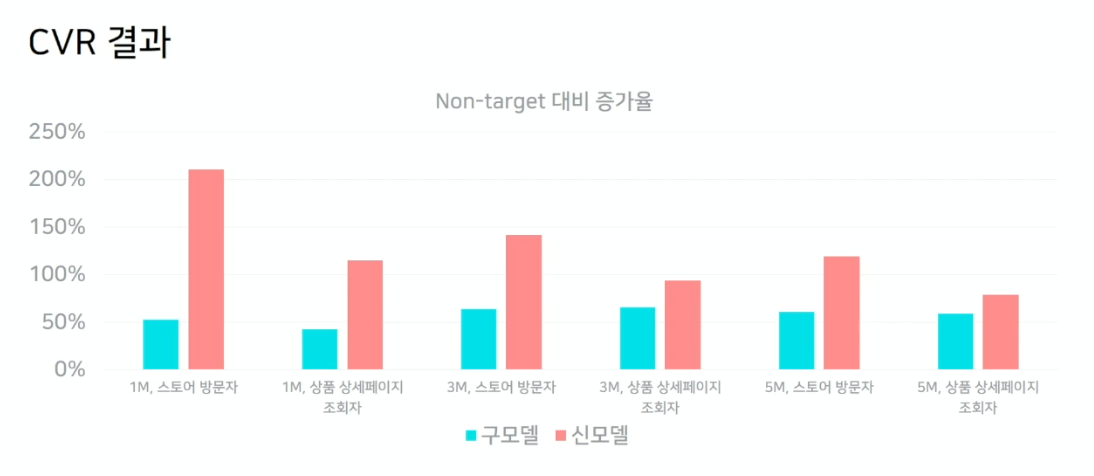
- Nontarget 대비 증가율을 나타냄. (100% 는 기존 대비 2배의 성능이 나오는 것)
- CTCVR 결과
- seed를 1M, 3M, 5M으로 확대할수록 cold-user까지 실험군에 포함되게 되어 성능이 떨어짐을 알 수 있음
- 상품 상세페이지 조회자 seed보다, 스토어 방문자 seed가 더 성능이 좋음. 그만큼 seed의 선정이 중요함을 의미함.
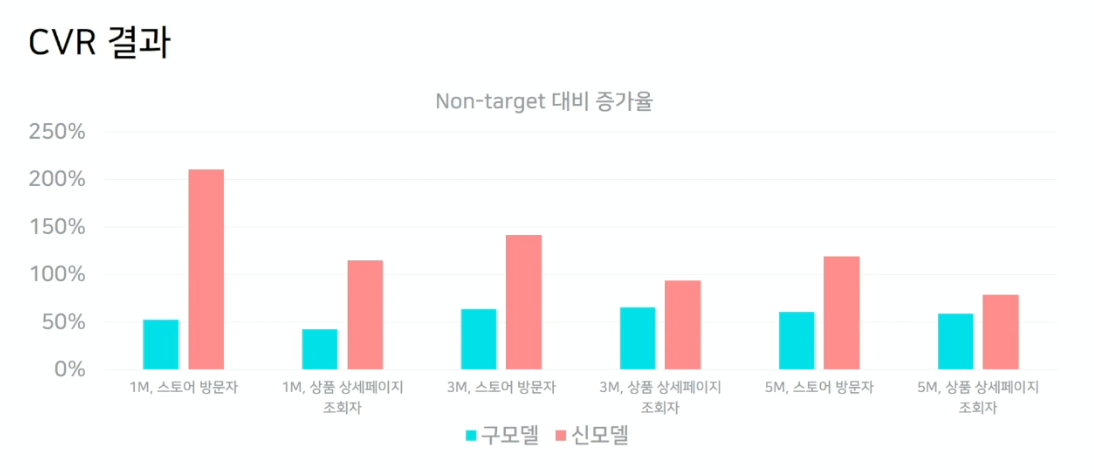
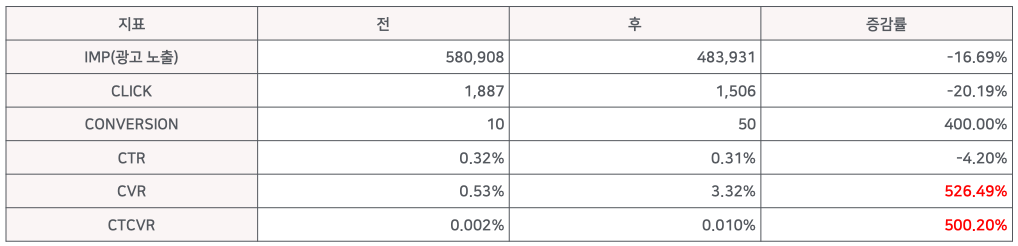
- CTR 은 살짝 낮아졌지만, CVR 이 매우 증가하여서 CTCVR 이 높아진것을 확인 가능
7.2 Online test
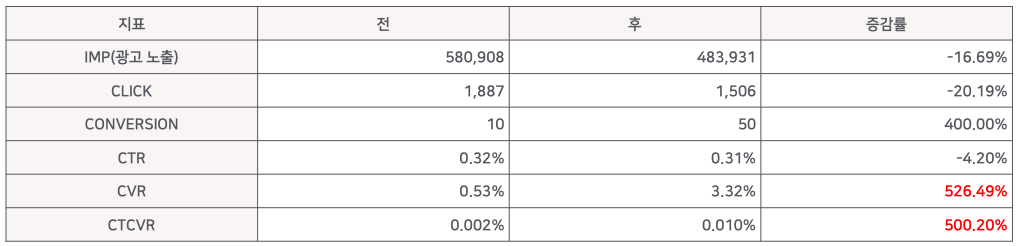
- 신 모델을 런칭한 후에 어떻게 변화했는지 살펴봄 ( 2개 광고 회사로 실험한 것이므로 일반화할 수 없다. )
- 결과적으로 약간의 ctr 손해가 있었으나, CTCVR과 CVR에서 500% 이상 상승
7.3 성능 개선 실험
CTR 개선 실험
- CTR 은 구 모델이 더 좋은게 많아서, CTR 도 높이고 싶었음.
- 실험: User embedding learning task의 target 변
- 실험군: 상품 구매 + 검색광고 클릭
- 대조군: 상품 구매
- 결과: CTR, CVR 소폭 하락
- 하락 이유 분석
- 상품 구매가 검색광고 클릭보다 CTR, CVR에 좋은 데이터일 수 있음
- 성질이 다른 두 target을 함께 학습해서 학습 난이도 상승, fitting이 잘 안됨
- 다른 소스에 있는 데이터를 같이 결합하면 안좋을 것 같다는 생각
노출 수 개선 실험
- 타게팅 기능을 사용하기 위해, 일정 광고 노출량 확보 필요
- 실험: 유저 filtering
- 네이버 서비스 활동성 지표 생성
- 지표가 낮은 유저는 추천 후보에서 제거
- 확대 규모: 3 M
- 두 모델에 비해서 노출수가 정상적으로 확보된것을 볼 수 있음
8 결론


3년차 데이터 분석가