Spark : RDD(Resilient Distributed Datasets) Paper 및 Main Idea 살펴보기
Spark : Internal Structure
Reference
https://www.usenix.org/system/files/conference/nsdi12/nsdi12-final138.pdf
https://www.usenix.org/legacy/event/hotcloud10/tech/full_papers/Zaharia.pdf
https://www.slideshare.net/yongho/rdd-paper-review#5
https://www.linkedin.com/pulse/just-enough-spark-core-concepts-revisited-deepak-rajak/
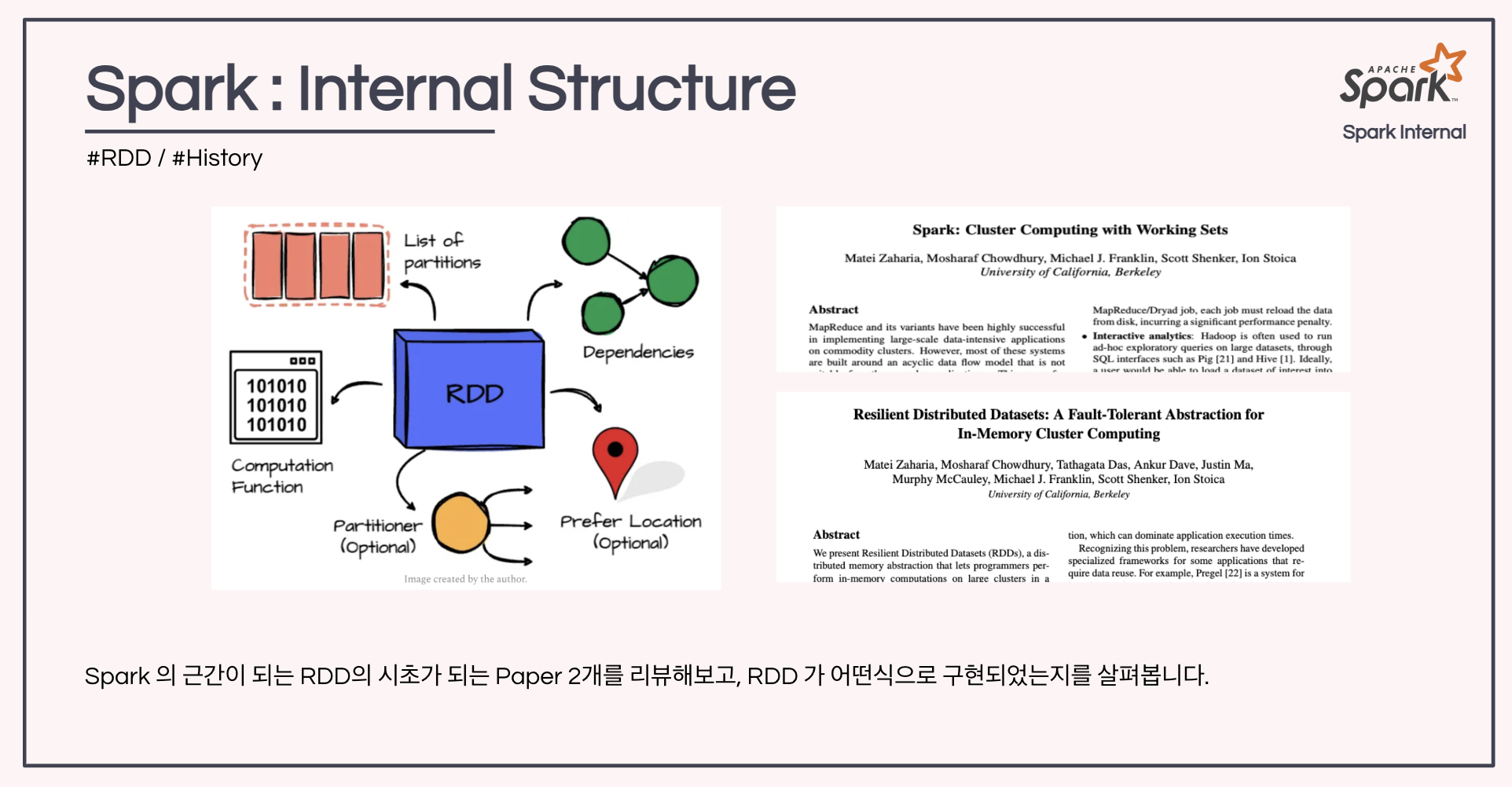
1 Introduction

- Spark 의 근간을 이루는 두 논문! 위 내용을 요약하자면 아래와 같은 두가지 입니다.
- Spark = RDD + Interface
- 즉 "RDD" 를 알아야 SPARK 를 다룰 수 있음! 이제 RDD 를 한번 알아보도록 합시다.
논문 구성
- Introduction - 왜 이런 요상한 것을 만들었는가에 대한 설명
- Resilient Distributed Datasets - RDD라는게 어떤 특성을 가지고 있고, 왜 좋은지에 대해 설명
- Spark Programming Interface - RDD로 일반 문제를 풀 수 있음을 예제로 보임
- Representing RDD - RDD는 어떻게 표현되고, Lineage는 또 어떠한가?
- Implementation - 잡스케쥴링, 인터프리터 통합, 메모리 관리, 체크포인팅등을 어지 구현?
- Evaluation - 성능 평가. 특히 메모리에 자료를 올려농은 Hadoop과도 비교함
- Discussion - RDD는 제한된 세트인데도 왜 대부분의 프로그램 모델이 표현될까?
- Related Work - 홀로 태어난 것이 아니라, 이것이 나오기 까지 영향 준 다른 프로젝트들
- Condusion
2 Motivation
2.1 HDFS 보다는 RAM !
Hadoop 의 MapReduce
- mapReduce가 대형 데이터 분석을 쉽게 만들어주긴 했음
- 그런데 아래의 것들을 잘 못하는 상태
- 더 복잡하고, multi-stage 한 처리 (머신러닝, 그래프)
- interactive 하고 ad-hoc한 쿼리
- 이런거 해결할려고, pregel 같은 특수목적 분산 프레임웍들은 나왔지만 뭔가 근본적인 접근을 원하는 상태
고민을 해보자!
- 효율적인 Data Sharing 도구가 빠진것 같다!
- MR이 iteration에서 빡센 이유는 각 iteration을 돌때마다 스테이지간 자료 공유가 HDFS를 거치기 때문이지 않을까?
- 그걸 넘쳐나는 RAM으로 하자!
그러면 위쪽의 단계마다 HDFS쓰는 것보단 아래쪽의 램에 저장해 놓고 계속 쓰면 빠르겠지?
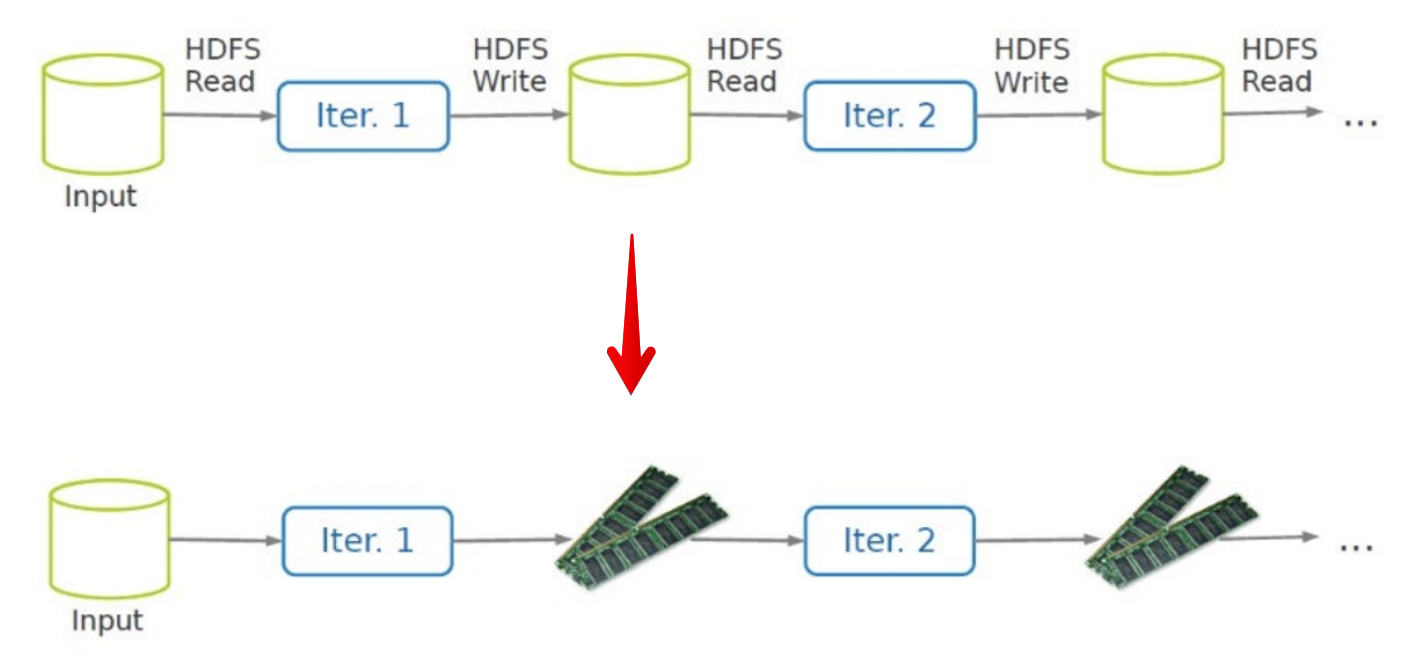
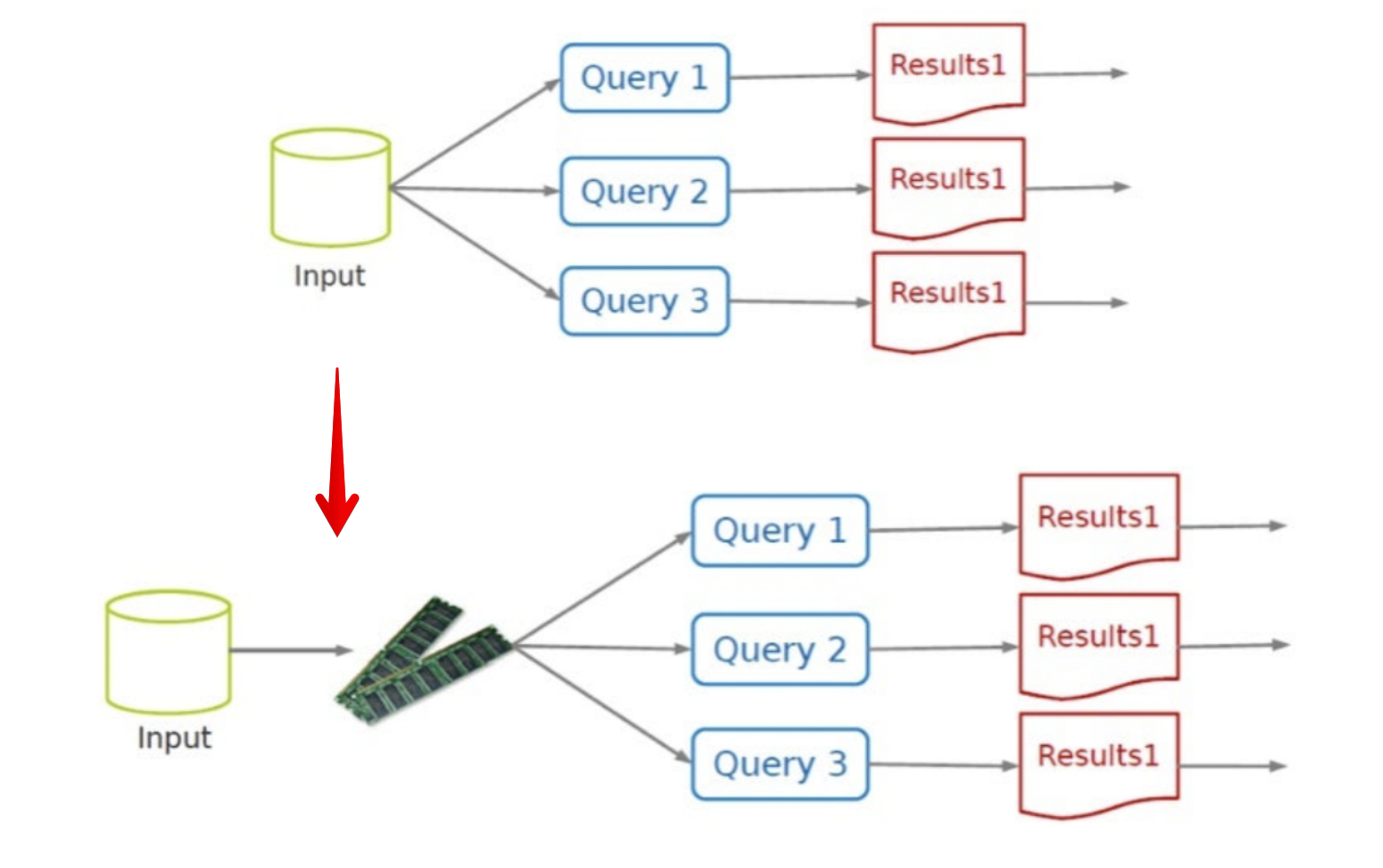
또한 쿼리할 때 마다, 처음부터 읽어오기보단, 한번 램에 올려 놓고, 그다음에 쿼리 하는 방식으로 처리해보자!
2.2 Fault 가 나면 어떡하지?
중간에 뽀개지면(fault)어떡하나?
- 어떻게 하면 fault-tolerant & efficient한 램스토리지를 만들수 있지?
기존의 Ram 을 쓰던 방식
- 기존의 RAM을 쓰던 패러다임
- RAM은 Random Access Memory 이니까. update는 되야 되지 않을까?
- 그래서 fine-grained update가 지원되는 RAMCloud, Piccolo등의 접근이 있었다.
- 근데 fault-tolerance위해 개판됨 replicating \& checkpointing의 빡셈
- 한놈이 부셔져도, 무사하려면? -> 복사해 둬야겠군 -> replicating
- replicating하는 동안은 멈춰야하겠지? -> 멈춘다고? -> 느려!
- replicating으로도 불안하면 disk에 써야겠지? -> checkpointing( 데이터를 저장소에 저장하는 과정 ) -> 엄청 느리다!
우리가 GFS (HDFS) 를 쓸떄는 어떻게 썻을까?
- 그런데 가 어떻게 Breakthrough를 일으켰는지 생각해보자.
- Modifiy가 안되는파일 시스템
- 무조건 쓰며 달리는 파일 시스템
- 그게 뭔 파일 시스템이야 스럽지만 그걸로 많은 것을 단순화시켜 큰 시스템을 만들 수 있었다.
2.3 Read - Only RAM 을 이용!
RAM도 read-only로만 써볼까?
- 뭔가 일이 착착 풀리기 시작한다. 이것이 RDD!
- Resilient Distributed Datasets
- 어떤 특성을 가지나?
- Immutable, partitioned collections of records
- 스토리지 - 로 변환하거나, 만 가능
- 그럼 뭐가좋나?
- 어 만들어진 이래 고쳐진 적이 없다고? (immutable = read-only)
- 그럼 어떻게 만들어졌는지만 기록해두면 또 만들 수 있겠네?
- 부모로부터 어찌만들어졌는지 계보(lineage)만 기록해도 fault-tolerant!
3 RDD 의 구현
- 코딩은 어찌 하는가?
- DryadLINQ-like API in the Scala language
- 코딩을 하는 것은 실제로 계산 작업이 되는게 아니라, 점점더나아가며 lineage 계보를, directed acyclicgraph(DAG)로 디자인 해 나가는 것
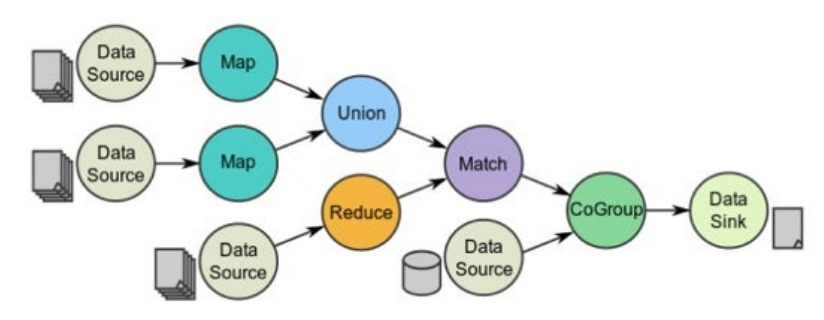
- 그래서 2가지 RDD operator가 있다 transformations & actions
3.1 Transformation
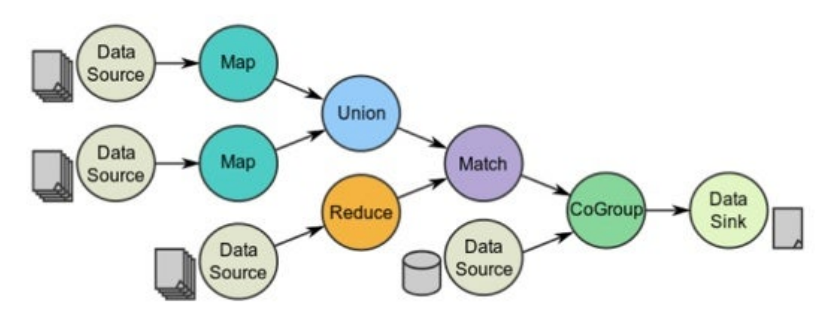
- Spark에서 Transformation(변환)은 기존의 RDD, DataFrame 또는 Dataset에서 새로운 RDD, DataFrame 또는 Dataset을 생성하는 연산
- map, reduce만 있던 MR보다 명령어가 풍부한것을 볼 수 있다.
Transformation의 특징
- Lazy Execution(지연 실행):
- Transformation은 실행 즉시 결과를 생성하지 않습니다. 대신, 실행 계획(DAG)에 추가만 하고, 실제 데이터 처리는 액션(Action)이 호출될 때 이루어집니다.
- 이로 인해 최적화된 실행 계획을 만들 수 있습니다.
- Immutable(불변성):
- Transformation은 기존 데이터셋을 변경하지 않고, 항상 새로운 데이터셋을 반환합니다. 원본 데이터셋은 변하지 않습니다.
- 종류:
- Narrow Transformation: 데이터의 각 파티션이 다른 파티션에 영향을 주지 않는 변환(예:
map,filter). - Wide Transformation: 데이터의 각 파티션이 여러 다른 파티션에 영향을 주는 변환(예:
groupByKey,reduceByKey).
- Narrow Transformation: 데이터의 각 파티션이 다른 파티션에 영향을 주지 않는 변환(예:
3.2 Action
- Spark에서 Action은 Transformation으로 정의된 작업을 실제로 실행해서 결과를 반환하거나 저장하는 연산임. Action을 호출하면 Transformation으로 구성된 작업이 트리거되어 실행되며, Spark의 Lazy Execution을 끝냄.
Action의 특징
- 실제 실행 트리거
- Transformation은 실행 계획만 만들고, Action이 호출될 때 실제 데이터 처리가 시작됨.
- 결과 반환 또는 저장
- 데이터를 드라이버로 가져오거나 파일, 데이터베이스 등에 저장함.
- 클러스터와의 통신
- 데이터를 수집하거나 저장하는 과정에서 네트워크 통신이 발생함.
| Transformation | Action |
|---|---|
| DAG만 정의함 | DAG를 실행시킴 |
| 새로운 데이터셋 반환 | 결과 반환 또는 저장 |
| Lazy Execution | 실행을 트리거함 |
| map, filter | collect, count |
3.3 Lazy - Execution
lazy-execution
- 인터프리터에서 룰루랄라, transformation들로 코딩하고 있으면 아무일 안생기고, 리니지만 신나게 생성되어 감
- action들은 실제로 “야 내놔"하는 작업들
- action에 해당하는 명령이 불리면 그제서야 쌓였던 것 실행 (lazy-execution)
lazy-Excution 의 이점
- 최적화된 실행 계획
- Spark는 액션(action) 명령이 호출될 때까지 작업을 미루며, 그 사이에 모든 변환(transformation) 단계를 DAG(Directed Acyclic Graph) 형태로 저장합니다.
- 최종 실행 단계에서 Spark는 전체 DAG를 분석하여 중간 단계 최적화(예: 중복 제거, 연산 병합, 재사용 등)를 수행합니다.
- 결과적으로, 효율적인 실행 계획이 생성되어 전체 작업 속도가 빨라집니다.
- 자원 효율성
- 지연 실행 덕분에 불필요한 작업이나 데이터를 계산하지 않습니다. 필요하지 않은 데이터는 읽거나 처리하지 않으므로 메모리와 CPU 사용량을 최소화합니다.
- 예를 들어, 필터링된 데이터를 사용하는 경우, 실제 필요한 데이터만 읽고 처리합니다.
- 디버깅 및 로직 설계의 유연성
- Lazy Execution을 사용하면 작업이 실제 실행되기 전에 DAG를 시각화하거나 검토할 수 있습니다.
- 잘못된 작업이나 비효율적인 연산을 최종 실행 전에 확인하고 수정할 수 있습니다.
4 Dependency
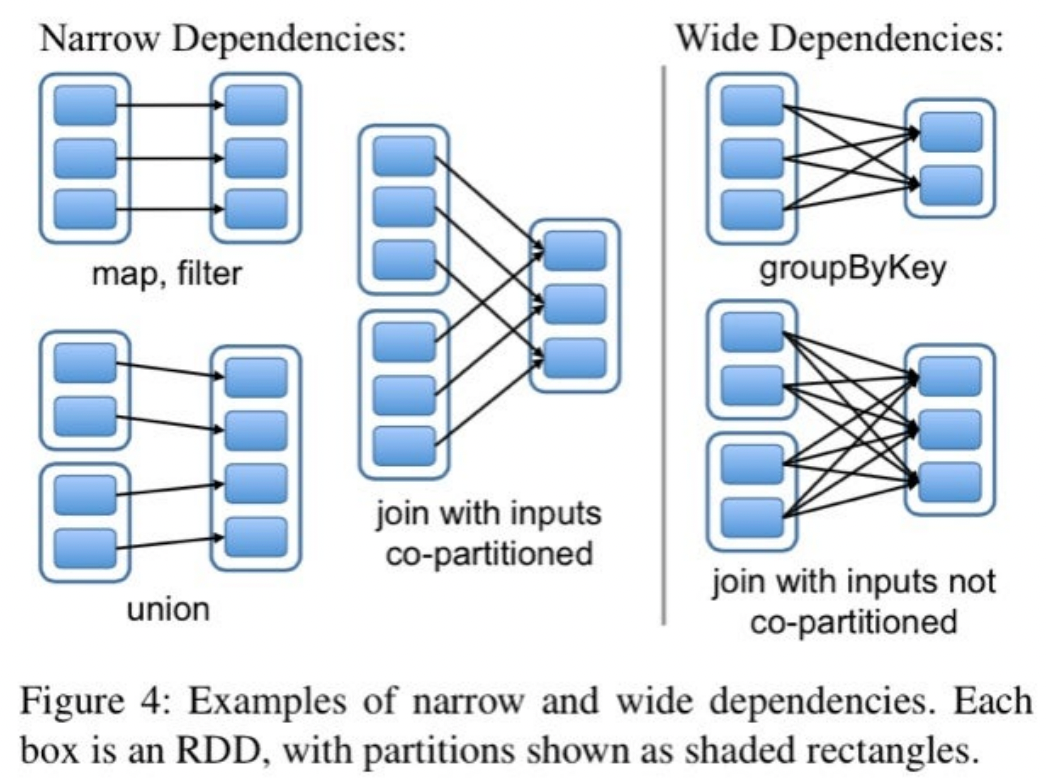
- Spark에서 Dependency(의존성)는 RDD나 DataFrame이 어떻게 다른 RDD나 DataFrame에서 생성되었는지를 나타냄. 즉, 데이터셋 간의 관계와 연산 과정을 설명하는 개념임.
- Spark는 이 의존성을 기반으로 실행 계획(DAG, Directed Acyclic Graph)을 생성하고 작업을 최적화함.
4.1 Narrow Dependency
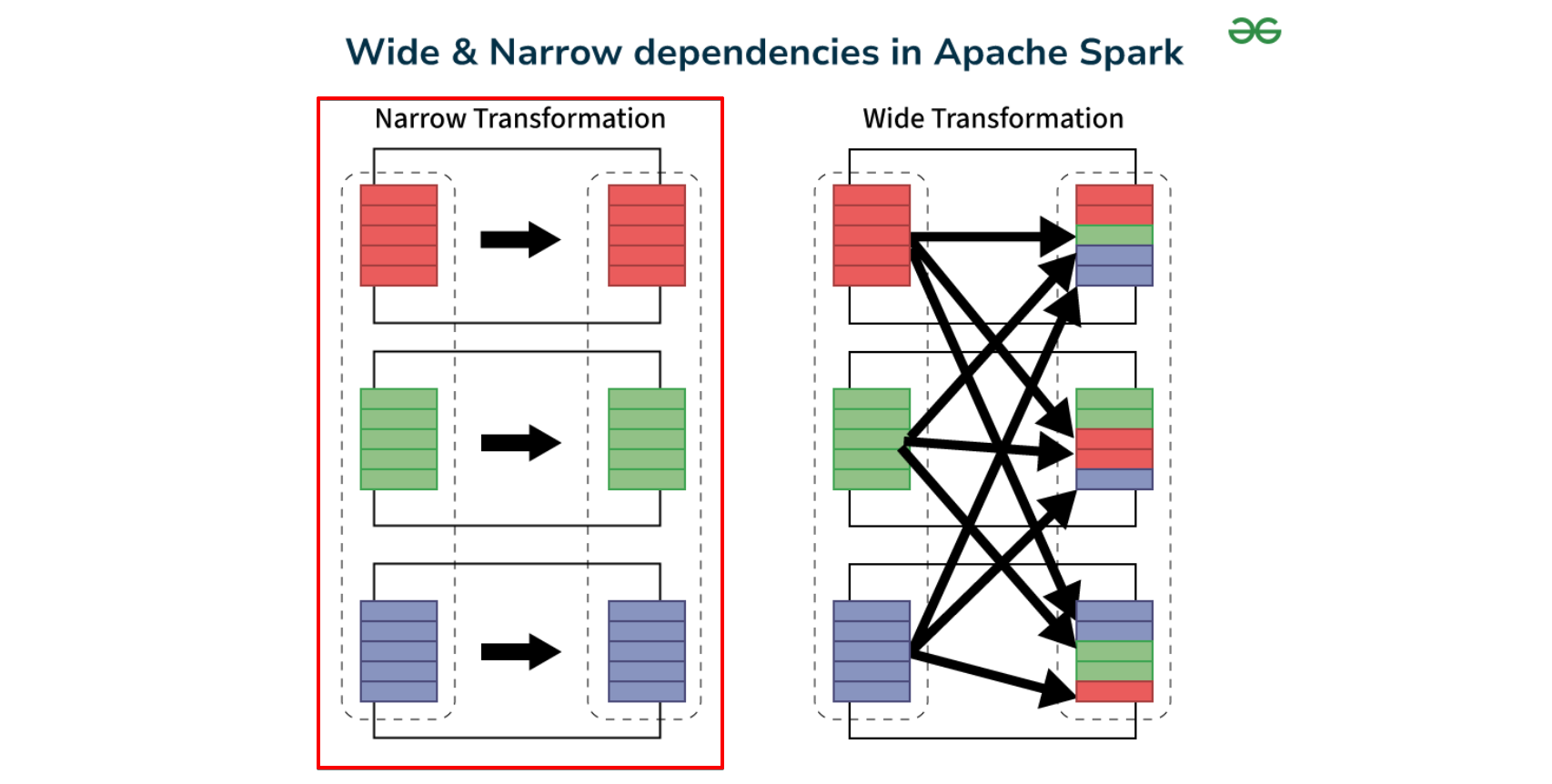
Narrow Dependency는 Spark에서 RDD나 DataFrame의 각 파티션이 오직 하나의 부모 파티션에만 의존하는 경우를 말함. 이 의존성은 데이터를 처리하거나 계산할 때 다른 파티션과의 연관성이 없다는 것을 의미함. 따라서, Narrow Dependency는 Spark 작업에서 병렬 처리와 효율적인 실행을 가능하게 함.
RDD 의 특징
- 데이터 독립성
- 각 파티션이 독립적으로 처리되므로 다른 파티션과의 통신이 필요 없음. (네트워크 안탄다는 소리, 즉 엄청 빠르다.)
- narrow는 한 책상 (한 노드 안에서) 다 처리 가능하다. 메모리의 속도로 동작한다. 왕빠름
- 셔플 없음
- 데이터가 노드 간에 이동하지 않기 때문에 셔플(shuffle) 과정이 발생하지 않음.
- 따라서, 실행 속도가 빠르고 네트워크 비용이 적음.
- 복구 용이
- 특정 파티션이 손실되더라도 해당 부모 파티션만 다시 계산하면 되기 때문에 복구가 빠르고 효율적임. (설사 가지고 있는 파티션이 부셔져도, 그 노드에서 다 복원가능하다.)
Narrow Dependency의 주요 연산
| 연산 | 특징 | Input (Partition) | Output (Partition) |
|---|---|---|---|
| Map | 1:1 관계 | [1, 2], [3, 4] | [2, 4], [6, 8] |
| Filter | 조건에 맞는 데이터만 출력 | [1, 2], [3, 4] | [2], [4] |
| FlatMap | 여러 요소로 변환 | ["a b"], ["c"] | ["a", "b"], ["c"] |
| Union | 두 데이터 결합 | [1, 2], [3, 4] | [1, 2], [3, 4] |
| MapPartitions | 전체 파티션 단위 처리 | [1, 2], [3, 4] | [3], [7] |
| Sample | 데이터 샘플링 | [1, 2], [3, 4] | [1], [3] |
4.2 Wide Dependency
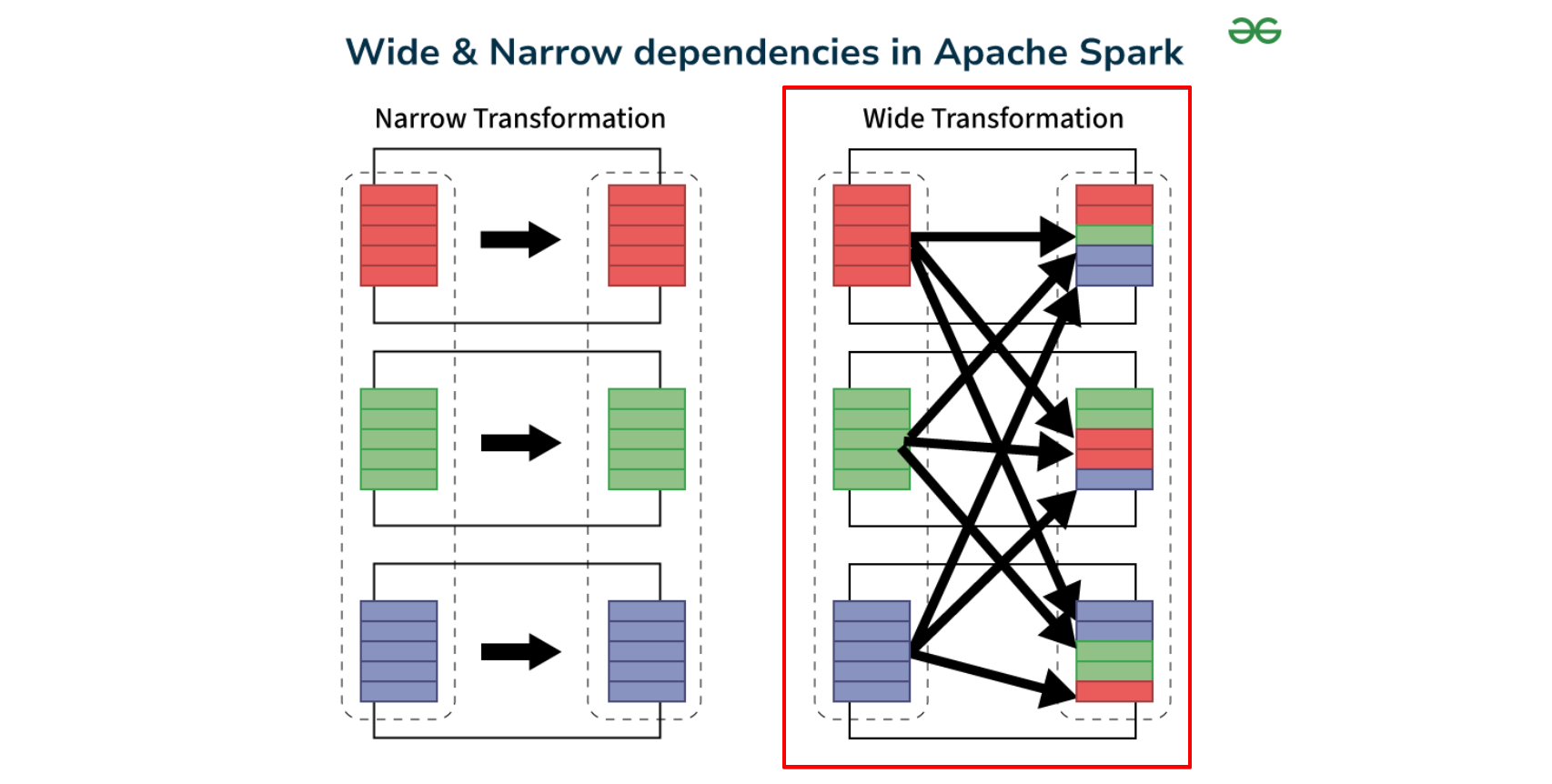
Wide Dependency는 Spark에서 RDD나 DataFrame의 각 파티션이 여러 부모 파티션에 의존하는 경우를 말함. 데이터가 한 파티션에서 여러 파티션으로 분산되거나, 여러 파티션에서 하나의 파티션으로 합쳐지는 연산에서 나타남. 이는 셔플(shuffle)을 유발하며, 네트워크 비용이 발생하는 경우가 많음.
Wide Dependency의 특징
- 파티션 간 데이터 이동
- 작업 수행 시 데이터가 노드 간에 이동(셔플)되기 때문에 실행 비용이 높음.
- 느린 작업 속도
- 네트워크 통신과 디스크 I/O가 발생하므로 Narrow Dependency에 비해 작업 속도가 느림.
- 복구가 복잡
- 특정 파티션이 손실되면, 해당 데이터를 다시 계산하기 위해 여러 부모 파티션을 재계산해야 함.
- 병렬 처리 제한
- 한 파티션이 여러 부모 파티션에 의존하므로 병렬 처리 효율이 떨어질 수 있음.
Wide Dependency 연산 예시
| 연산 | 특징 | Input (Partition) | Output (Partition) |
|---|---|---|---|
| GroupByKey | 키별로 데이터를 그룹화, 셔플 발생 | [("a", 1), ("b", 2)], [("a", 3), ("b", 4)] | [("a", [1, 3])], [("b", [2, 4])] |
| ReduceByKey | 키별로 값을 병합, 셔플 발생 | [("a", 1), ("b", 2)], [("a", 3), ("b", 4)] | [("a", 4)], [("b", 6)] |
| Join | 두 데이터셋을 키로 결합, 셔플 발생 | RDD1: [("a", 1)], [("b", 2)] RDD2: [("a", 3)], [("b", 4)] | [("a", (1, 3))], [("b", (2, 4))] |
| SortBy | 데이터를 정렬, 셔플 발생 | [4, 1], [3, 2] | [1, 2], [3, 4] |
| Distinct | 중복 제거, 셔플 발생 | [1, 2, 2], [3, 3, 4] | [1, 2], [3, 4] |
| Coalesce (셔플) | 파티션 수를 줄이되 데이터 재분배 | [1, 2], [3, 4] | [1, 2, 3, 4] |
5 Job Schecduling
Spark의 Job Scheduling은 작업을 실행하고 관리하는 프로세스임. 사용자가 Spark 애플리케이션을 제출하면, Spark는 작업을 실행하기 위해 Job, Stage, Task 로 나누고 이를 클러스터 자원 관리자(YARN, Mesos, Kubernetes 등)를 통해 병렬로 처리함.
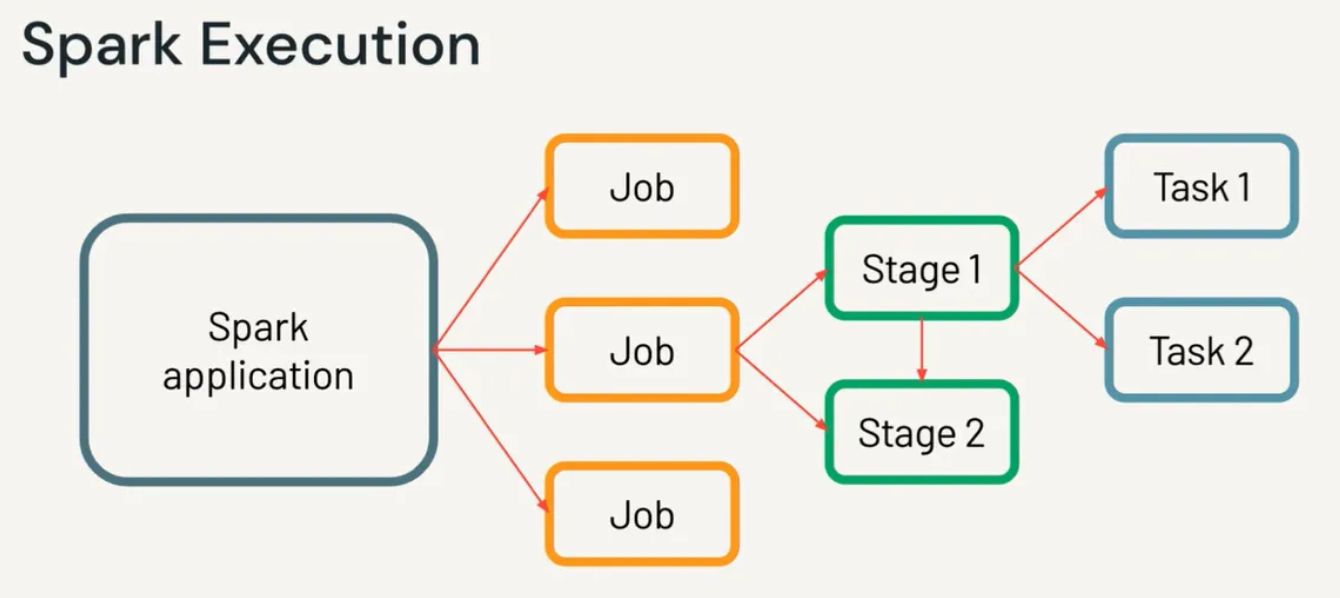
Spark Job Scheduling의 주요 단계
- JOB 정의
- 사용자가 Action을 호출하면 Spark 애플리케이션은 실행 계획을 생성하고, 이를 Job으로 정의함.
- 한 개의 Action은 하나의 Job에 해당하며, 여러 Action을 호출하면 여러 Job이 생성됨.
- Job 분할: Stage로 나눔
- Job은 DAG Scheduler에 의해 여러 Stage로 분할됨.
- Stage는 셔플 여부에 따라 결정됨:
- 셔플 없음 → 같은 Stage에 포함.
- 셔플 발생 → Stage가 분리됨.
- Stage 분할: Task로 나눔
- 각 Stage는 데이터 파티션 단위로 더 작은 작업인 Task로 분할됨.
- 동일 Stage 내에서는 모든 Task가 병렬로 실행됨.
- Task 실행
- Task Scheduler가 각 Task를 실행할 노드(Executor)를 할당함.
- 작업은 병렬로 실행되며, 실패 시 재시도 가능함.
- 결과 수집
- 모든 Task가 완료되면 Stage가 종료되고, Job 결과가 반환됨.
스케줄링 흐름
- 사용자가 Spark 애플리케이션 제출 → Driver 프로그램 실행.
- Driver가 Job을 생성하고 DAG Scheduler가 실행 계획을 최적화.
- Stage로 나눔 → 각 Stage를 Task로 분할.
- Task Scheduler가 Task를 Executor에 배치.
- Task 완료 후 결과를 Driver로 반환
6 Woker
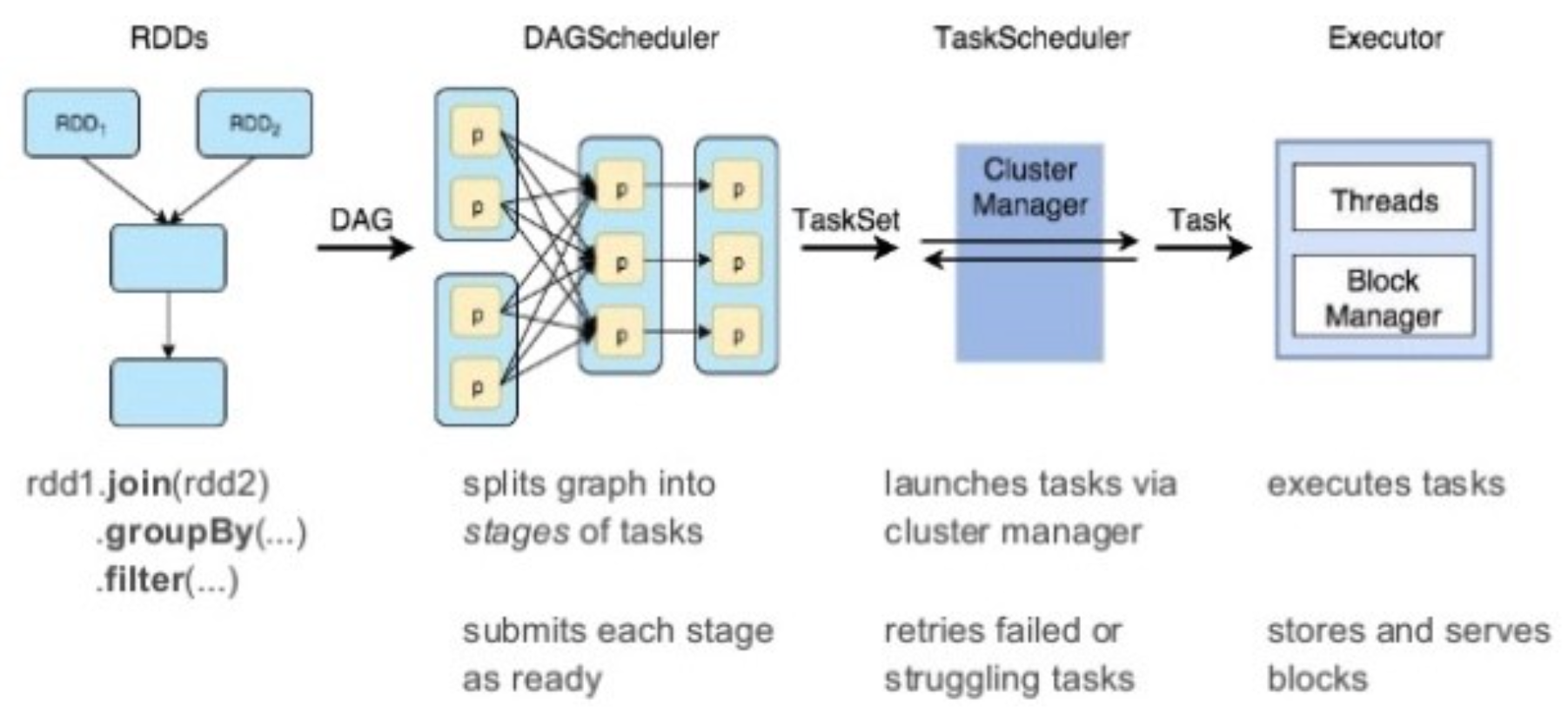
Spark에서 Worker(작업 노드)들은 Driver가 생성한 Task들을 받아 병렬로 실행함. 이 과정은 Spark의 분산 처리 구조와 Task Scheduling 메커니즘에 의해 이루어짐. Spark가 Job을 Worker에 나눠주는 과정을 단계별로 살펴보면 아래와 같음.
1. Job 분해
- 사용자가
Action을 호출하면, Spark는 Job을 생성하고, 이를 여러 Stage로 분할함. - 각 Stage는 데이터의 파티션 단위로 나뉘며, 하나의 Stage는 여러 Task로 구성됨.
- Task는 RDD나 DataFrame의 파티션 단위 연산을 수행하는 가장 작은 실행 단위임.
2. Task 생성
- Stage가 분해되면 각 데이터 파티션에 대해 하나의 Task가 생성됨.
- 예를 들어, RDD가 4개의 파티션으로 나뉘어 있으면, 해당 Stage는 4개의 Task로 구성됨.
3. Task 배포
- Scheduler가 생성된 Task를 클러스터의 Worker(Node)들에 배포함.
- Task는 다음 기준을 따라 Worker에게 할당됨:
- 데이터 로컬리티: Task가 가능한 한 데이터를 가진 노드에서 실행되도록 배치.
- 부하 균형: 각 Worker에 할당된 Task 수가 균형을 이루도록 배치.
- 자원 가용성: Executor의 CPU 코어 및 메모리 사용량을 고려하여 배치.
4. Worker에서 Task 실행
- Worker 노드의 Executor가 Task를 실행함.
- 각 Worker는 다음과 같은 단계를 통해 Task를 처리:
- 입력 데이터 읽기: 파티션 데이터를 HDFS나 로컬 디스크에서 읽음.
- 연산 수행: Task가 지정된 Transformation이나 Action을 수행.
- 출력 저장: 중간 결과를 메모리, 디스크 또는 네트워크를 통해 다음 Stage로 전달.
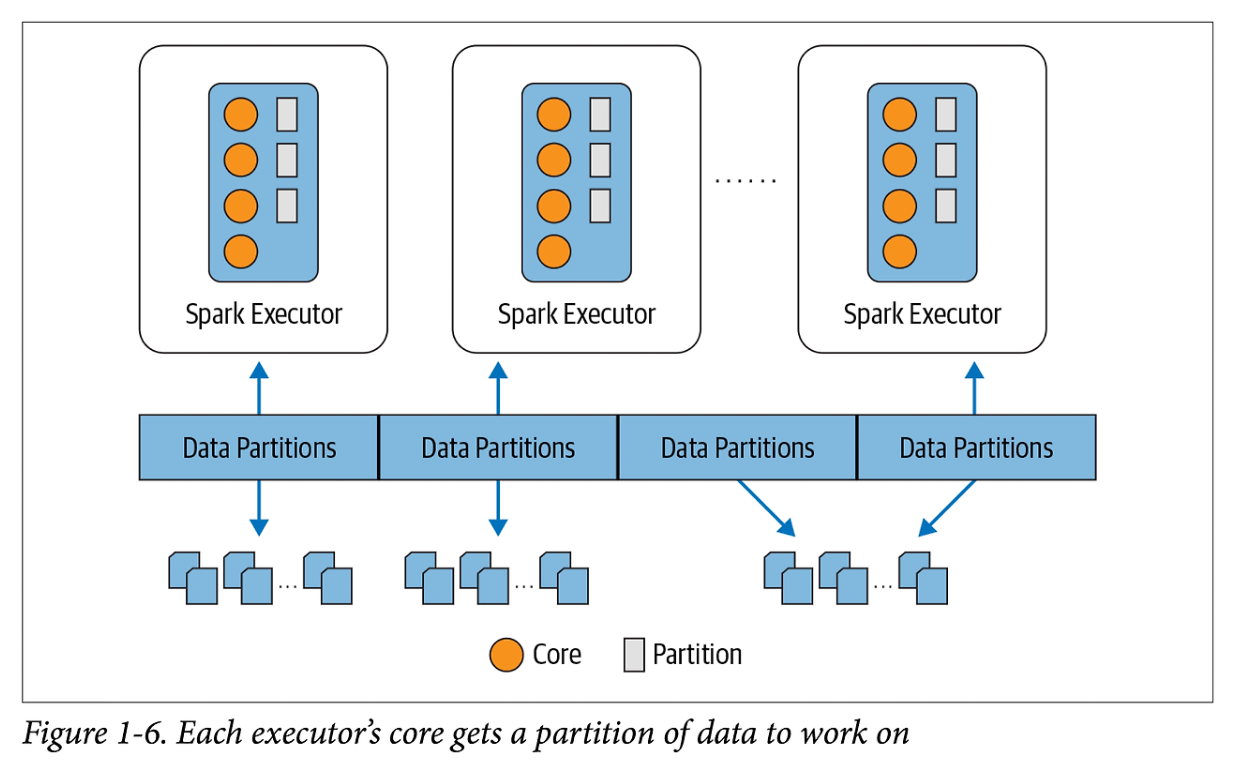
- Executor의 Core 당 Task 1개 , 1개의 Task에서 1개의 Partition을 처리하므로 Core 수 = Task 수 = Partition 수를 처리하게 됨. 이때 Partition 수에 따라 각 Partition의 크기가 결정되는데, Partition의 수 = Core 수 라면, Partition의 크기 = Memory 크기이다. 즉, Partition의 크기가 Core당 필요한 메모리의 크기를 나타낸다.
7 여러 시나리오
7.1 수행중 메모리가 모자라면 어찌 되나요?
- LRU로 (LRU 알고리즘 : 가장 오랫동안 참조되지 않은 페이지를 교체하는 기법)안쓰는 파티션 날림
- 캐시랑 하는짓이 유사/ 원본을 다시 가져올 수 있다는 점도 캐시랑 유사하니 당당히 캐시랑 비슷하게 동작
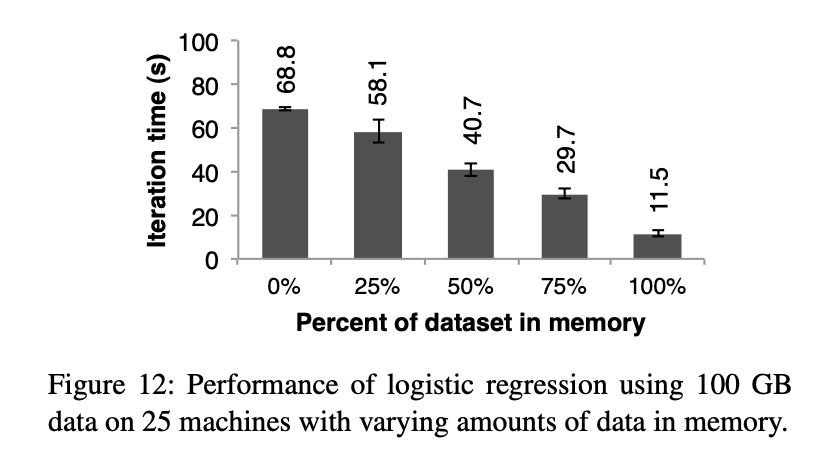
만약 작업(job)의 데이터를 저장할 만큼 충분한 메모리가 없는 경우 Spark가 어떻게 동작하는지에 대한 실험하기 위해 각 머신에서 RDD를 저장할 수 있는 메모리를 특정 비율로 제한하도록 Spark를 설정했음.실험 결과는 FIGURE-12에 나와 있으며, 이는 로지스틱 회귀(Logistic Regression) 작업에서 다양한 저장 공간 설정에 따른 성능을 보여줌. 결과적으로, 저장 공간이 줄어들수록 성능이 점진적으로 저하되는 것을 확인할 수 있었음.
7.2 수행중 Fault가나면 Recovery 영향은?
lineage 는 용량이 작기때문에 잘 로깅해 놓고 있다가(부담없다) 특정 파티션에 문제 생기면 다른 노드서 땡겨서 실행. 여기에서는 Fault 가 났을떄 어느정도의 성능 감소가 있는지 알아보자.
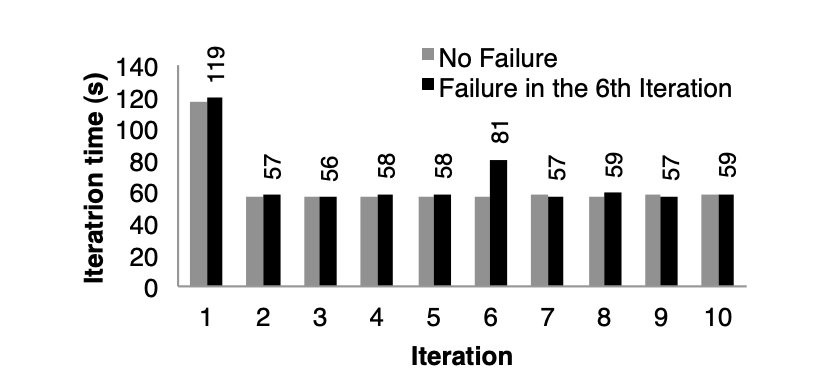
k-means 애플리케이션에서 노드 장애 발생 시 RDD 파티션을 계보(lineage)를 통해 복구하는 데 드는 비용을 평가함. 그림 11은 75개 노드로 구성된 클러스터에서 k-means를 10번 반복 실행했을 때, 정상 운영 시의 실행 시간과 6번째 반복 초기에 노드 하나가 장애를 겪는 경우의 실행 시간을 비교한 결과를 보여줌.
장애가 없는 경우, 각 반복(iteration)은 100GB의 데이터를 처리하며 400개의 태스크로 구성되고, 반복 시간은 약 58초였음. 그러나 6번째 반복에서 한 노드가 종료되면서 해당 노드에서 실행 중이던 태스크와 RDD 파티션이 손실됨. Spark는 다른 머신에서 이러한 태스크를 병렬로 재실행하면서 손실된 입력 데이터를 다시 읽고 계보를 통해 RDD를 복구했으며, 이로 인해 반복 시간이 80초로 증가했음. 이후 손실된 RDD 파티션이 복구되자 반복 시간은 다시 58초로 감소함.
8 성능
8.1 HDFS 와의 비교
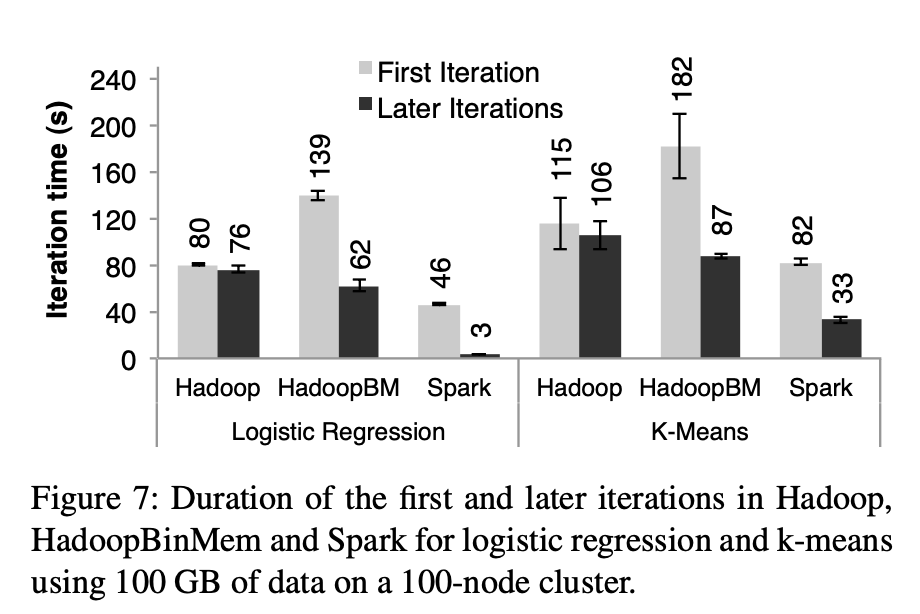
첫 번째 반복
- 모든 시스템은 첫 번째 반복에서 HDFS로부터 텍스트 입력을 읽어옵니다. 그림 7의 밝은 색 막대에서 볼 수 있듯이, Spark는 실험 전반에서 Hadoop보다 다소 빠르게 동작했습니다.
- 이러한 차이는 Hadoop의 마스터와 워커 간 하트비트 프로토콜에서 발생하는 신호 오버헤드 때문이었습니다. HadoopBinMem은 데이터를 바이너리로 변환하는 추가 MapReduce 작업을 실행해야 했고, 이 데이터를 네트워크를 통해 복제된 메모리 내 HDFS 인스턴스로 전송해야 했기 때문에 가장 느렸습니다.
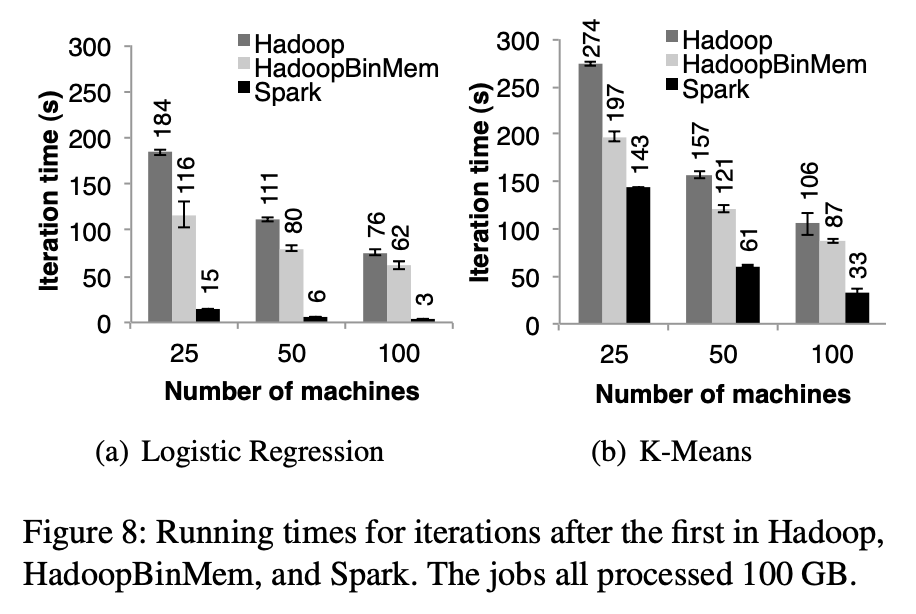
이후 반복(iteration)
- 그림 7은 이후 반복에 대한 평균 실행 시간을, 그림 8은 클러스터 크기에 따른 확장성을 보여줍니다. 로지스틱 회귀의 경우, Spark는 100대의 머신에서 Hadoop 및 HadoopBinMem에 비해 각각 25.3배 및 20.7배 더 빠른 성능을 보였습니다.
- 더 많은 계산을 요구하는 k-means 애플리케이션에서도 Spark는 1.9배에서 3.2배의 속도 향상을 달성했습니다.
속도 향상의 원인 분석
- Spark가 바이너리 데이터를 메모리에 저장하는 Hadoop (HadoopBinMem)보다도 20배 빠르다는 점은 놀라운 결과였습니다.
- HadoopBinMem에서는 Hadoop의 표준 바이너리 형식(SequenceFile)을 사용하고, 블록 크기를 256MB로 설정했으며, HDFS의 데이터 디렉토리를 메모리 기반 파일 시스템으로 강제 지정했습니다. 하지만 Hadoop은 여전히 다음과 같은 요인들로 인해 더 느리게 실행되었습니다:
- Hadoop 소프트웨어 스택에서 발생하는 최소한의 오버헤드
- 데이터를 제공할 때 HDFS에서 발생하는 오버헤드
- 바이너리 레코드를 메모리 내에서 사용할 수 있는 Java 객체로 변환하는 과정에서 발생하는 역직렬화 비용
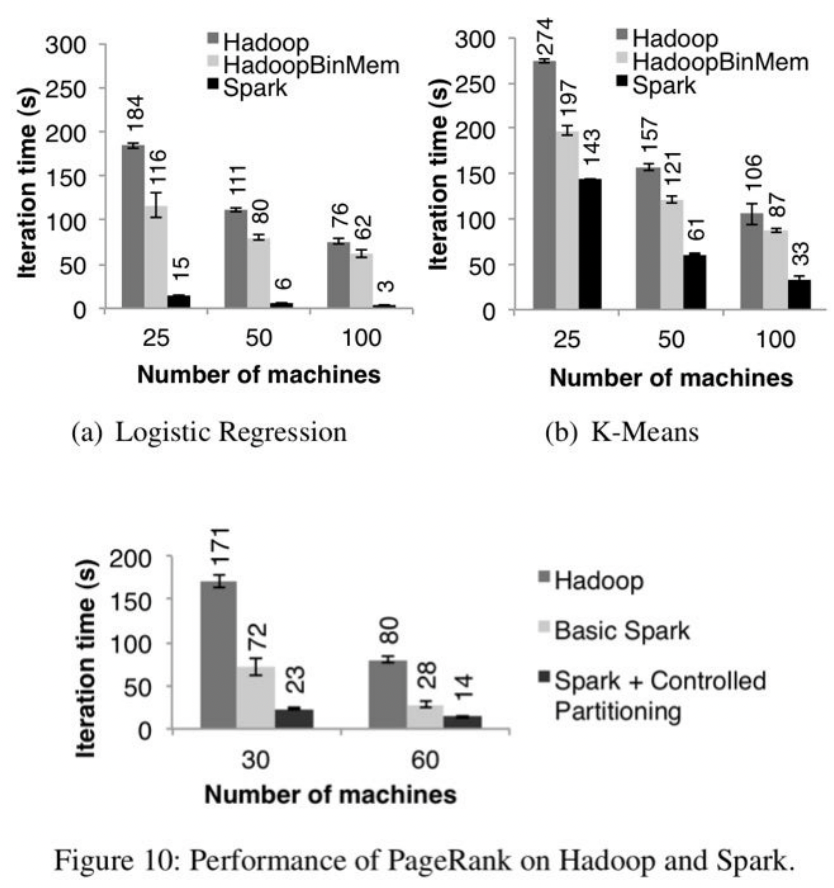
- 이러한 경향은 "머신이 늘어도" 똑같은것을 볼 수 있습니다.
RAM쓰니까 당연히 빠르겠거니 했지만 왜 in-memory HDFS를 쓰는 HadoopBinMem보다 빠른가?
- Hadoop의 소프트웨어 스택이 너무 복잡해서 기본요금이 비쌈
- HDFS라는파일 구조체가다루는데 비쌈
- Bin을 계산을 위해 Java object로 또 돌리는데 계산 비용 (spark은 java object상태로 계속 활용한다. 물론용량큼)
결국 RDD가 Spark이 짱이다! in-memory 로 전부 처리하는 hadoop도 안된다더라! 의미 (하긴 아무리 메모리라도 애초에 작업 반복할때마다 전부 썼다 읽었다 하는데 될리가 없을듯)
8.2 RDD 의 표현 범위
- 비록 RDD의 조합 기반 변환(coarse-grained transformations)에 기초한 인터페이스가 처음에는 제한적으로 보일 수 있지만, 이러한 변환은 다수의 병렬 애플리케이션에 적합합니다.
- RDD는 지금까지 별도의 시스템으로 제안된 여러 클러스터 프로그래밍 모델(예: MapReduce, DryadLINQ, SQL, Pregel, HaLoop)을 효율적으로 표현할 수 있을 뿐만 아니라, 이러한 시스템으로는 구현할 수 없던 새로운 애플리케이션(예: 인터랙티브 데이터 마이닝)도 지원할 수 있습니다.
9 Conclusion
RDD(Resilient Distributed Dataset) 는 다음과 같은 특성을 지닌다.
| 특징 | 설명 |
|---|---|
| Resilient | RDD lineage 그래프를 통한 fault-tolerant가 빠졌거나,node의 실패로 인한 손상된 파티션을 다시 실행시킨다. |
| Distributed | 클러스터의 여러 노드에 데이터가 분산되어 저장 |
| Dataset | 원천 데이터값 혹은 값의 값들로 이루어진 파티션된 collection 데이터 (튜플 혹은 다른 레코드로써 사용될 수 있는 데이터 객체들) |

