User Cold Start Problem in Recommendation System - A Systematic Review (2023/IEEE)
AdTech : Paper Review
Reference
1 ABSTRACT
- 추천 시스템은 사용자 선호도를 기반으로 동작함. 그런데 새로운 사용자에 대한 세부적인 선호도 정보가 부족하여 적절한 추천을 하지 못하는 상황이 발생하는데, 이를 사용자 콜드 스타트 문제’ 라고 함 이 문제는 많은 경우 추천 시스템의 활용을 방해하는 요인이 됨.
- 이 연구는 2016년부터 2023년까지 문헌을 분석해 DATA Driven 기술과 Approach 기반 기술로 나누고, 평가 기준을 정리해 관련 연구에 참고자료를 제공. 향후 연구 방향도 제시함
2 Introduction
-
추천 시스템은 사용자의 이전 상호작용 데이터를 기반으로 관심 있을 만한 항목을 추천하고, 사용자 피드백을 활용해 추천 성능을 최적화함함.
-
그런데 이때 추천 시스템에는 콜드 스타트 문제가 존재하며, 이는 주로 사용자 콜드 스타트와 아이템 콜드 스타트로 나뉨. (예를 들어, 사용자 평가 데이터를 활용한 추천 시스템에서는 신규 사용자나 아이템에 대한 데이터가 부족할 경우 적절한 추천을 제공하기 어렵고, 이를 콜드 스타트라고 함)
-
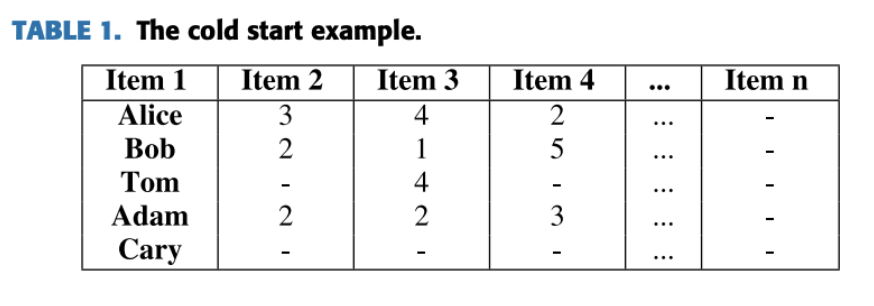
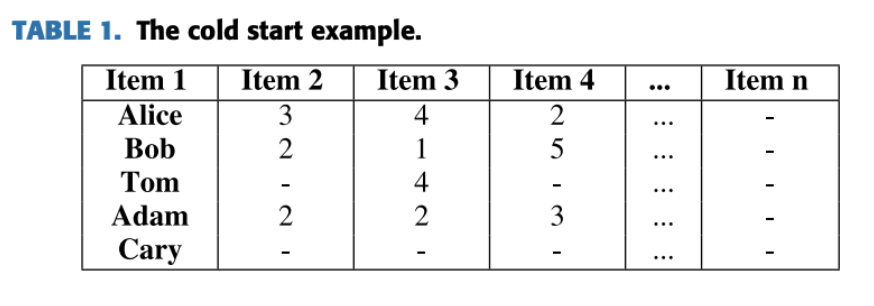
테이블 1은 콜드 스타트 문제의 예시를 보여줌. 이 매트릭스는 사용자들이 아이템에 대해 부여한 점수를 나타내며, 점수는 1부터 5까지의 정수로 표현됨. 각 점수는 사용자가 해당 아이템에 대해 매긴 평가를 의미하며, 사용자가 아이템을 평가하지 않은 경우는 ‘‘-’’로 표시됨.
Item 콜드 스타트
- 새로운 아이템의 경우, 과거 데이터가 부족해 아이템의 특성과 사용자 선호도를 이해하기 어려워 추천 결과의 정확도가 낮아짐. 테이블 1에서 Item n은 신규 아이템으로 사용자 평가가 없어, 사용자 평가 기반으로 이 아이템을 추천할 수 없음.
User 콜드 스타트
- 신규 사용자의 경우, 과거 데이터가 부족해 사용자의 관심사와 행동을 정확히 예측하기 어려워 추천 결과의 정확도가 낮아지거나 무의미한 추천이 될 수 있음.
- 테이블 1에서 Cary는 신규 사용자로, 추천 시스템을 사용한 적이 없고 아이템을 평가한 기록도 없음. 이 경우, 평가 정보를 활용한 추천은 Cary에게 적합한 아이템을 정확히 추천하기 어렵다는 단점이 있음.
- 이는 추천 시스템의 성능과 정확성에 영향을 미치며, 신규 사용자와 신규 아이템의 수가 많을수록 문제가 더 심각해짐. 콜드 스타트 문제를 해결하기 위한 다양한 접근법이 존재하며, 이를 통해 추천 시스템의 정확도와 성능을 개선하고자 함.
이 논문에서 다루고자 하는 것
- 사용자 콜드 스타트 문제와 아이템 콜드 스타트 문제를 해결하는 방법은 다르며, 본 논문은 사용자 콜드 스타트 문제에 초점을 맞춤. 그래서 여기에서는 사용자 콜드 스타트 문제를 신규 사용자 문제로 지칭 .
- 추천 시스템에서 사용자 콜드 스타트 문제를 해결하는것은 추천 정확도뿐만 아니라 사용자 경험도 향상시킴이 알려져 있음. 이 문제는 최근 몇 년간 다양한 추천 시스템 연구에서 주요 화두가 되고 있음.
Cold Start 를 해결하는 2가지 방식
- DATA-DRIVEN TECHNIQUES
- 효율적인 데이터 활용과 사용자 및 아이템 속성 간의 연결을 활용하는 접근법
- 다음과 같은 데이터 활용
- 사용자 지역 데이터
- 사용자 소셜 커뮤니티 데이터
- person belief information
- 사용자 크로스 도메인 데이터
- 방법 기반 기술
- 신규 알고리즘을 제안하거나 기존 알고리즘을 개선해 콜드 스타트 문제를 완화함.
- 다음과 같은 방법론 활용
- Matrix factorization-based approach
- hybrid approach
- collaborative filtering-based approach
- contentbased approach.
3 DATA-DRIVEN TECHNIQUES
3.1 Cross-domain data
사용자의 여러 도메인에서의 선호 데이터를 활용해 더 완전한 사용자 모델을 구축하고 추천 정확도를 높임.
- 크로스 도메인 추천은 소스 도메인 (기존에 데이터를 가지고 있는 도메인) 에서 수집된 정보를 사용해 타겟 도메인 (콜드 스타트 문제를 해결하려는 추천의 대상 도메인) 의 콜드 스타트 문제를 해결하거나 추천 품질을 개선하려는게 목적
크로스 도메인 추천 시나리오의 4가지 유형 (Cremonesi et al. [43])
- Cremonesi 등은 크로스 도메인 추천의 시나리오를 최초로 분류.
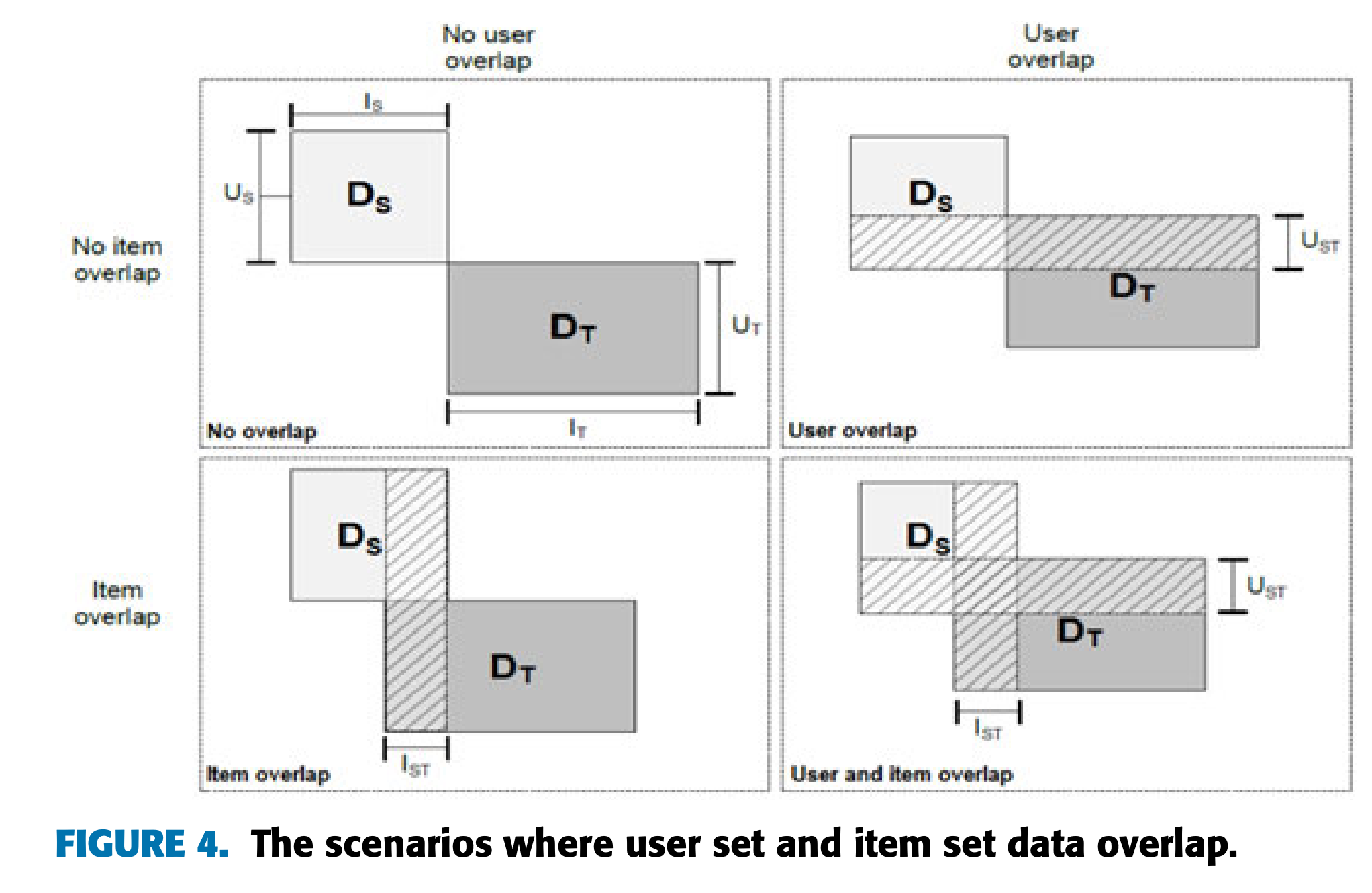
- Fig. 4에 제시된 네 가지 시나리오는 아래와 같음
- No Overlap: 사용자와 아이템이 도메인 간 중복되지 않음.
- Ex : 소스 도메인: 중국의 온라인 도서 판매 플랫폼 (책 추천) , 타겟 도메인: 프랑스의 음악 스트리밍 플랫폼 (노래 추천) 이는 사용자 그룹이나 아이템(책/노래) 모두 두 플랫폼 간에 겹치지 않음.
- User Overlap: 사용자만 도메인 간 중복됨.
- Ex : 소스 도메인: 비디오 스트리밍 플랫폼 (영화 추천), 타겟 도메인: 전자책 플랫폼 (책 추천) 특정 사용자가 두 플랫폼에 모두 가입되어 있음.
- Item Overlap: 아이템만 도메인 간 중복됨.
- Complete Overlap: 사용자와 아이템 모두 도메인 간 중복됨.
- Ex : 소스 도메인: 온라인 쇼핑몰 (상품 추천), 타겟 도메인: 소셜 미디어 플랫폼 (상품 광고 추천) 동일한 사용자가 두 플랫폼을 모두 이용하고, 같은 상품(아이템)이 양쪽에 등장.
- No Overlap: 사용자와 아이템이 도메인 간 중복되지 않음.
- 대부분의 문제 해결 방법은 사용자 중복(User Overlap)과 사용자 및 아이템 중복(User and Item Overlap)에 초점을 맞춤 ( 당연하겠지만, 모두 중복되는 경우 크게 신경쓸 건 없기 때문 )
크로스 도메인의 추천 작업
- 크로스 도메인 추천 시스템에서 작업은 크로스 도메인 정보를 기반으로 두 가지로 분류됨:
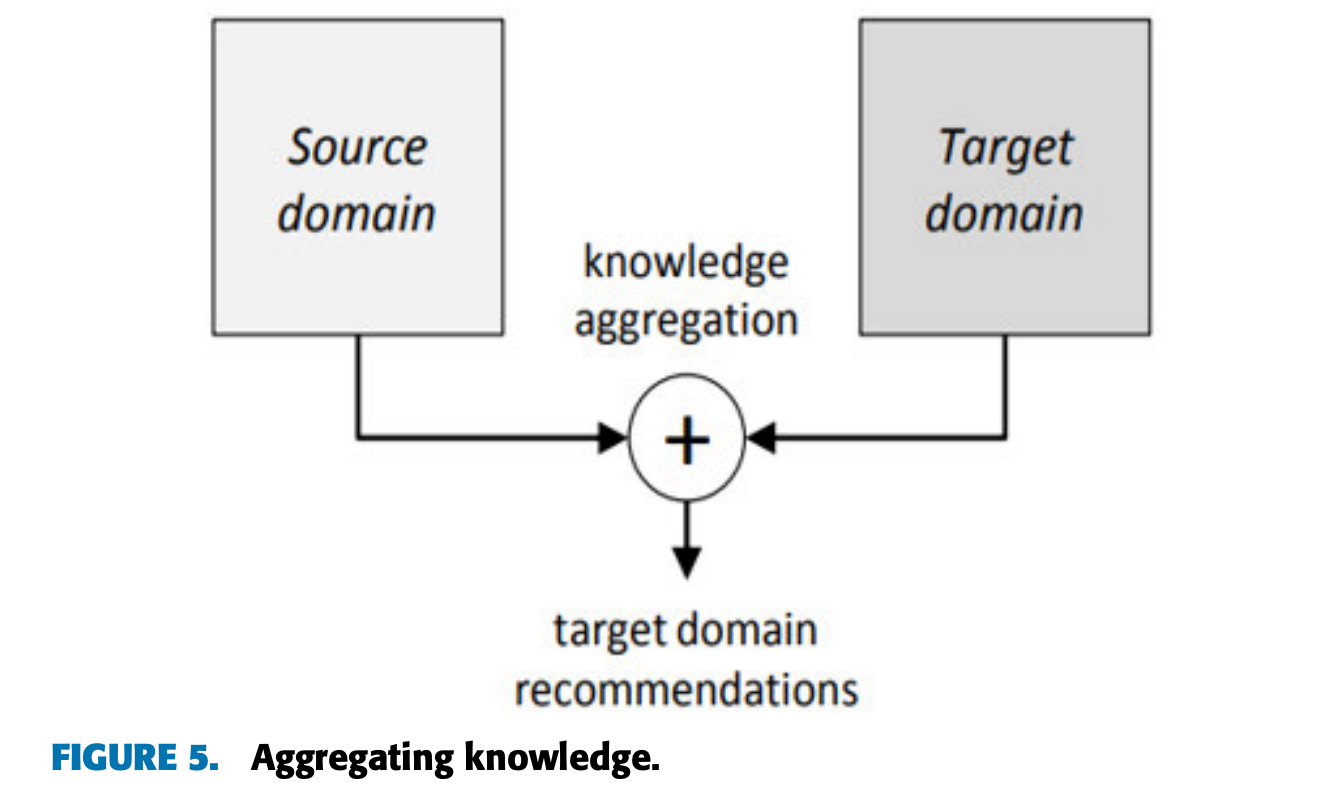
- 정보의 통합 (Aggregating Knowledge)
- 여러 소스 도메인의 지식을 타겟 도메인으로 통합한 뒤, 이를 활용해 추천을 생성.
- 예: 사용자의 여러 플랫폼에서의 선호 데이터를 통합해 더 정교한 추천 제공.
- 사용자가 영화 스트리밍 플랫폼(소스 도메인 A)에서 선호한 장르와 도서 리뷰 플랫폼(소스 도메인 B)에서 선호한 카테고리를 결합해 음악 스트리밍 플랫폼(타겟 도메인)에서 음악 추천.
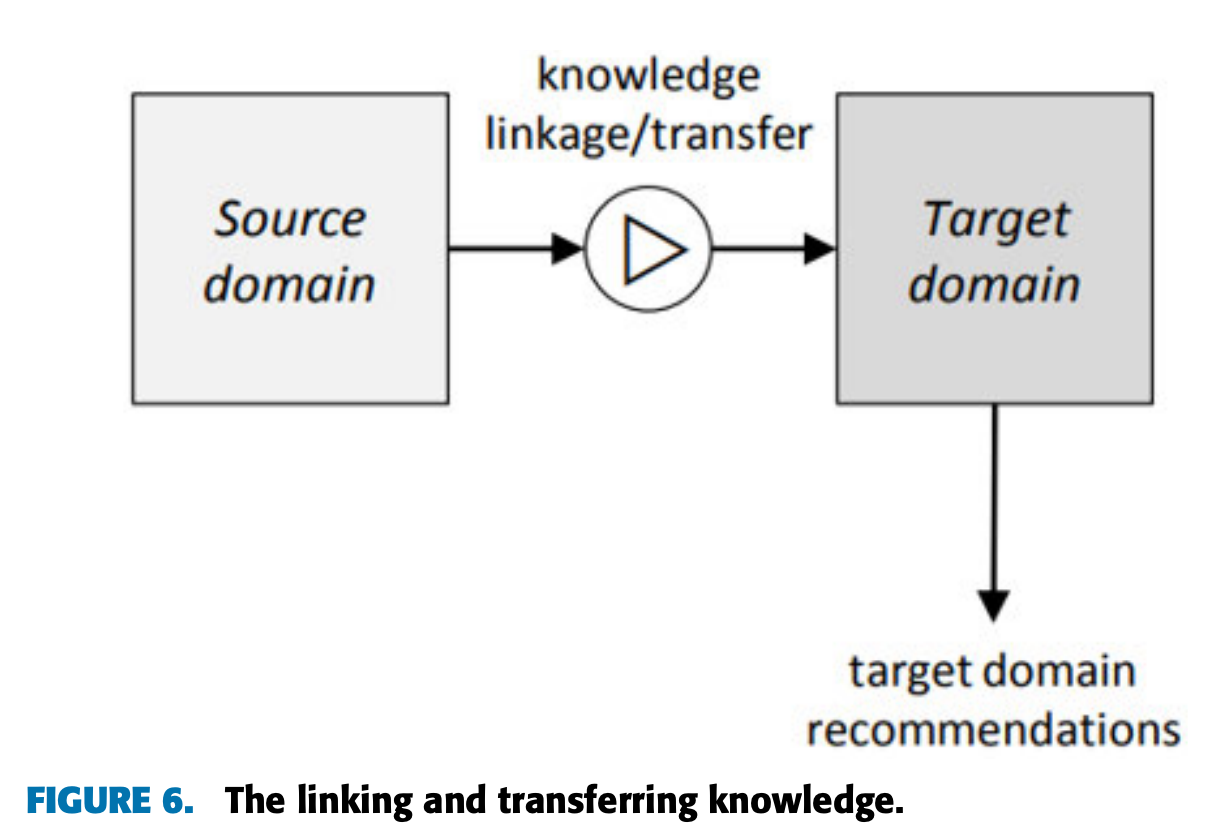
- 정보 연결 및 전이 (Linking/Transferring Knowledge)
- 도메인 간 의미적으로 연결 가능한 정보를 활용하거나 정보를 전이하여 추천 품질을 개선.
- 예: 서로 다른 도메인에서 연관성 있는 아이템을 매핑해 추천.
- "코미디 영화"와 "유머 책"처럼 의미적으로 연관된 카테고리를 연결해 추천.
- 예: 서로 다른 도메인에서 연관성 있는 아이템을 매핑해 추천.
- 도메인 간 의미적으로 연결 가능한 정보를 활용하거나 정보를 전이하여 추천 품질을 개선.
- 도메인 간의 연관성을 이해하고 데이터를 변환해 사용하는 방식.
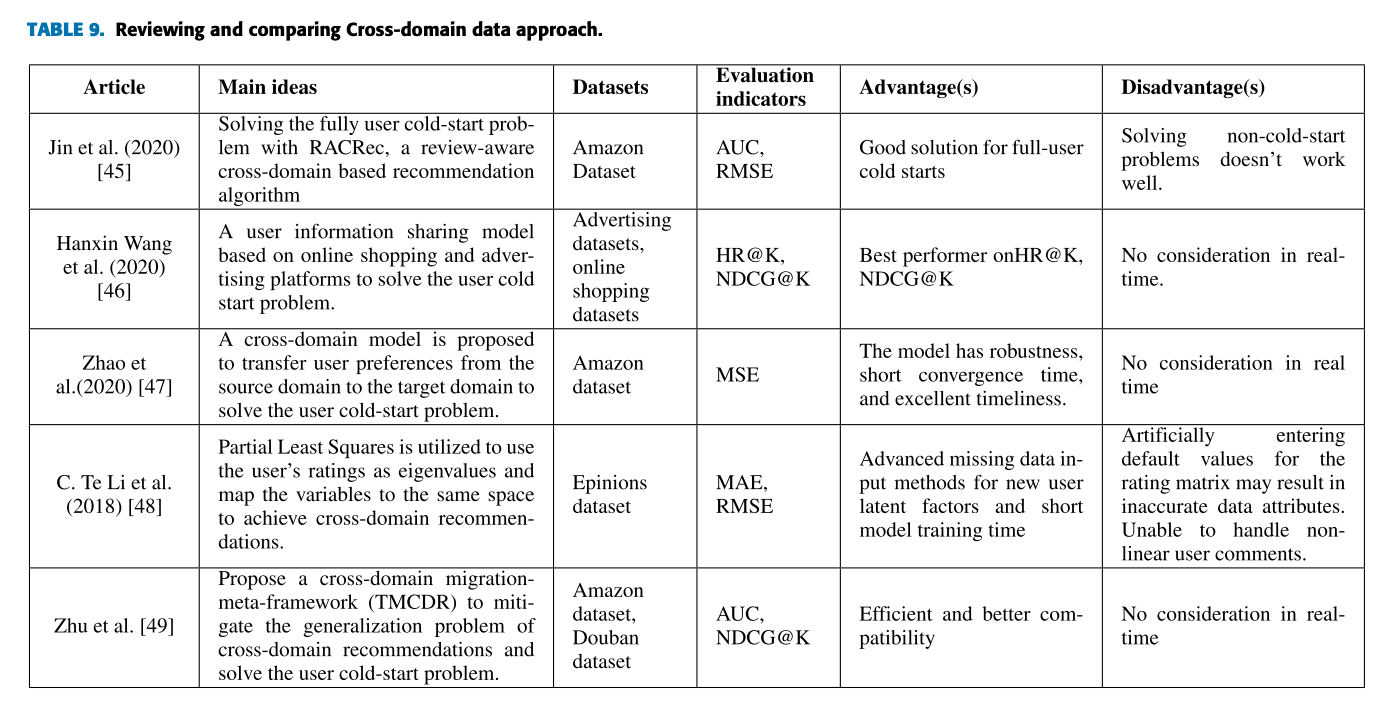
| 논문 (Article) | 주요 아이디어 (Main ideas) | 데이터셋 (Datasets) | 평가지표 (Evaluation indicators) | 장점 (Advantages) | 단점 (Disadvantages) |
|---|---|---|---|---|---|
| Jin et al. (2020) [45] | RACRec이라는 리뷰 기반 크로스 도메인 추천 알고리즘을 사용하여 완전한 사용자 콜드 스타트 문제를 해결. | Amazon 데이터셋 | AUC, RMSE | 전체 사용자 콜드 스타트 문제에 대한 효과적인 해결책 제공. | 콜드 스타트 외의 문제를 해결하는 데에는 성능이 낮음. |
| Hanxin Wang et al. (2020) [46] | 온라인 쇼핑 및 광고 플랫폼에서 사용자 정보를 공유하는 모델을 통해 사용자 콜드 스타트 문제를 해결. | 광고 데이터셋, 온라인 쇼핑 데이터셋 | HR@K, NDCG@K | HR@K 및 NDCG@K에서 최상의 성능을 보임. | 실시간 고려가 없음. |
| Zhao et al. (2020) [47] | 소스 도메인에서 타겟 도메인으로 사용자 선호도를 전이하여 사용자 콜드 스타트 문제를 해결하는 크로스 도메인 모델을 제안. | Amazon 데이터셋 | MSE | 모델의 강건성과 짧은 수렴 시간, 우수한 시간 효율성을 보임. | 실시간 고려가 없음. |
| C. Te Li et al. (2018) [48] | 사용자의 평점을 고유값(eigenvalues)으로 사용하고 변수를 동일 공간에 매핑하여 크로스 도메인 추천을 달성하기 위해 부분 최소 제곱법(PLS)을 활용. | Epinions 데이터셋 | MAE, RMSE | 새로운 사용자에 대한 고급 결측 데이터 입력 방법과 짧은 모델 학습 시간. | 평점 행렬에 기본값을 인위적으로 삽입하면 부정확한 데이터 속성이 발생할 수 있으며 비선형 사용자 코멘트를 처리하지 못함. |
| Zhu et al. (2019) [49] | 크로스 도메인 마이그레이션 메타 프레임워크(TMCDR)를 제안하여 크로스 도메인 추천의 일반화 문제를 완화하고 사용자 콜드 스타트 문제를 해결. | Amazon 데이터셋, Douban 데이터셋 | AUC, NDCG@K | 효율적이고 더 나은 호환성을 제공. | 실시간 고려가 없음. |
3.2 Social network data
- 소셜 네트워크 플랫폼의 급격한 성장은 사용자들의 일상과 추천 시스템에 중요한 데이터를 제공.
- 소셜 네트워크를 활용하면 사용자 선호를 더 잘 이해할 수 있어, 사용자 콜드 스타트 문제를 효과적으로 해결 가능. 이는 아래 2가지 접근법이 존재
Feature Mapping Models
- 아이디어:
- 소셜 네트워크 데이터를 기반으로 사용자 특징을 추출하고, 이를 사용해 새로운 사용자를 위한 추천 생성.
- 예: Facebook ID, DBpedia ID 등을 활용해 자동으로 사용자 프로필 생성.
- 구체적 예:
- 신규 사용자가 Facebook 또는 DBpedia ID로 로그인하면 사용자 프로필 생성 모듈이 자동으로 프로필 작성.
- 생성된 프로필을 바탕으로 사용자를 특정 "클러스터"에 배정.
- 클러스터 내 사용자들이 각 아이템에 매긴 평균 평점을 계산하고, 가장 높은 평점을 받은 아이템 클러스터를 신규 사용자에게 추천.
Similarity-Based Models
- 아이디어:
- 소셜 네트워크에서 사용자 간 유사성을 측정해 새로운 사용자를 위한 추천을 수행.
- 모델 공식:
- : 소스 도메인 와 타겟 도메인 간 유사성 행렬.
- 구체적 사례:
- 이웃 탐색: 사용자 평점 행렬을 활용해 가장 가까운 이웃(nearest neighbors) 선정.
- 속성 분석: 소셜 네트워크 데이터를 분석해 각 사용자 간 속성 유사도 계산.
- 이웃 그룹 생성: 사용자 친구 네트워크에서 이웃 그룹 선택 후, 가중합(weighted sum)으로 유사성 결정.
- 최종 평점 계산: 예측된 이웃들의 평점을 가중합하여 아이템에 대한 최종 추천 평점 생성.
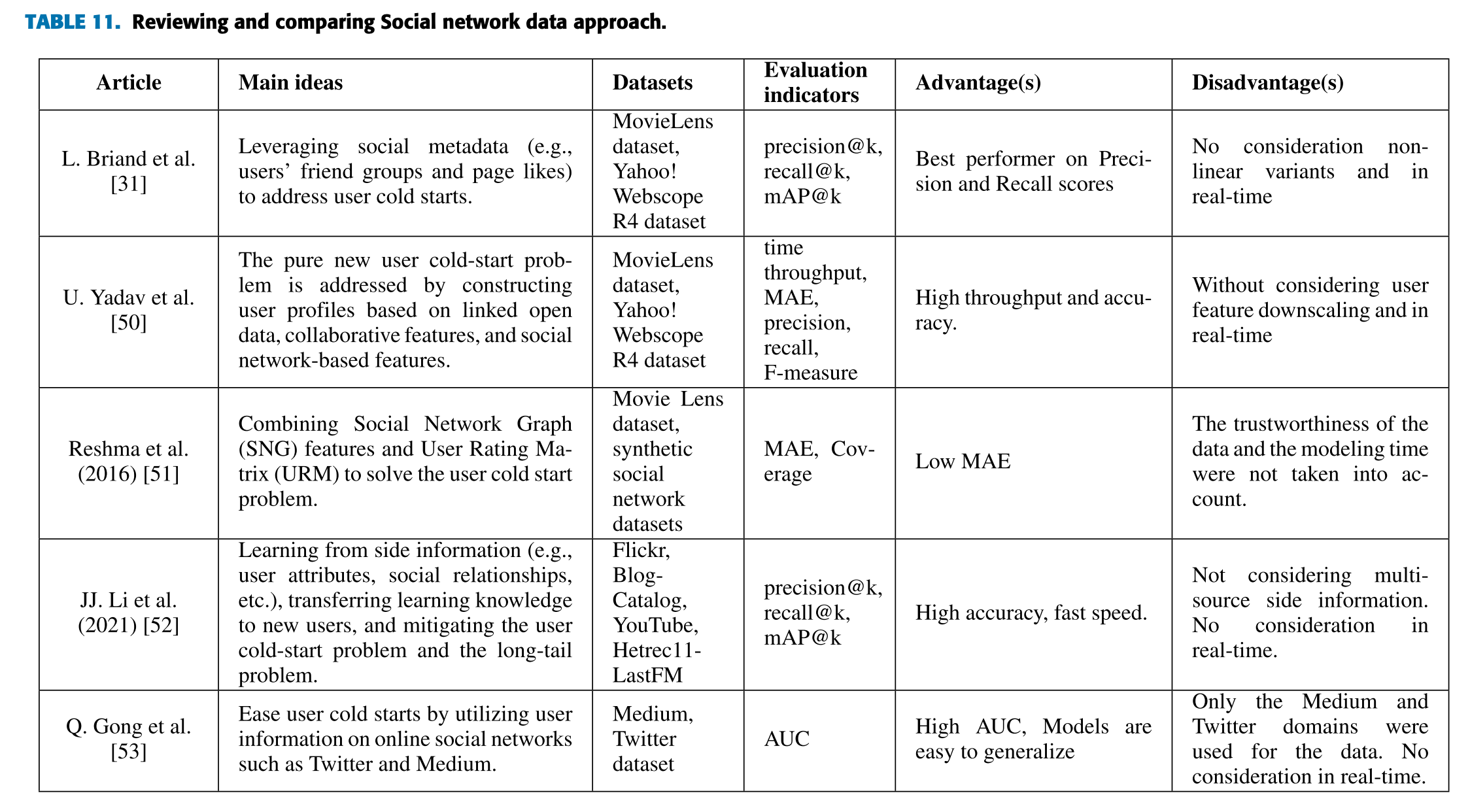
| 논문 (Article) | 주요 아이디어 (Main ideas) | 데이터셋 (Datasets) | 평가지표 (Evaluation indicators) | 장점 (Advantages) | 단점 (Disadvantages) |
|---|---|---|---|---|---|
| L. Briand et al. [31] | 소셜 메타데이터(예: 사용자의 친구 그룹 및 페이지 좋아요)를 활용하여 사용자 콜드 스타트 문제를 해결. | MovieLens 데이터셋, Yahoo! Webscope R4 데이터셋 | precision@k, recall@k, mAP@k | Precision 및 Recall 점수에서 최고의 성능. | 비선형 변형(non-linear variants) 및 실시간 처리 미고려. |
| U. Yadav et al. [50] | 연결된 오픈 데이터, 협업 특징, 소셜 네트워크 기반 특징을 바탕으로 사용자 프로필을 생성하여 순수한 신규 사용자 콜드 스타트 문제를 해결. | MovieLens 데이터셋, Yahoo! Webscope R4 데이터셋 | time throughput, MAE, precision, recall, F-measure | 높은 처리량과 정확도. | 사용자 특징 축소(user feature downscaling) 및 실시간 처리가 고려되지 않음. |
| Reshma et al. (2016) [51] | 소셜 네트워크 그래프(SNG) 특징과 사용자 평점 행렬(URM)을 결합하여 사용자 콜드 스타트 문제를 해결. | MovieLens 데이터셋, Synthetic Social Network 데이터셋 | MAE, Coverage | 낮은 MAE 값. | 데이터 신뢰성과 모델링 시간이 고려되지 않음. |
| JJ. Li et al. (2021) [52] | 부가 정보(예: 사용자 속성, 소셜 관계 등)를 학습하여 신규 사용자에게 지식을 전이하고 콜드 스타트 및 롱테일 문제를 완화. | Flickr, Blog-Catalog, YouTube, Hetrec11-LastFM | precision@k, recall@k, mAP@k | 높은 정확도와 빠른 속도. | 다중 소스 부가 정보(multi-source side information) 및 실시간 처리가 고려되지 않음. |
| Q. Gong et al. [53] | Twitter 및 Medium과 같은 온라인 소셜 네트워크에서 사용자 정보를 활용하여 사용자 콜드 스타트를 완화. | Medium, Twitter 데이터셋 | AUC | 높은 AUC 점수 및 일반화 용이. | Medium 및 Twitter 도메인만 사용되었으며 실시간 처리가 고려되지 않음. |
4 APPROACH-DRIVEN TECHNIQUES
4.1 Meta Learning
메타 러닝이란?
- 메타러닝은 제한된 예제만으로도 새로운 작업에 빠르게 적응할 수 있게 해주는 기술
- New User 에 대한 추천 문제는 제한된 수의 샘플로 학습해야 하는 문제로 볼 수 있으며, 이 때문에 메타러닝 접근법을 사용하면 사용자 콜드 스타트 문제를 매우 효과적으로 해결할 수 있음을 알 수 있음!
- 현재 많은 연구자들이 이런 New User 문제를 해결하기 위해 메타러닝을 활용하고 있습니다
1.메트릭기반(metrics-based) 메타러닝
- 핵심 개념: TASK 간 샘플의 유사도를 학습하여 새로운 작업에서도 빠르게 학습을 수행.
- 방법: 특정 메트릭(예: 코사인 유사도, 유클리디안 거리 등)을 기반으로 샘플 간의 관계를 정의하고 이를 통해 분류나 회귀를 수행.
- 예를 들어, Jiang et al 은 사용자의 공통된 지식을 기반으로 관심사가 비슷한 사용자들을 클러스터링하는 방법을 제안. 이렇게 클러스터링된 사용자 데이터를 활용해 변환 네트워크(transformation network) 구축하며, 이를 통해 메타러닝으로 얻어진 전역 초기화(global initialization) 매개변수를 클러스터에 맞는 최적의 초기화 매개변수로 변환합니다. 이는 다양한 취향을 가진 사용자들로 인해 발생할 수 있는 부정적인 영향을 줄이고, 메타러닝 모델의 성능을 향상시킬 수 있음
2.모델 기반 메타러닝
- 핵심 개념: 학습된 모델 자체가 새로운 작업에 적응할 수 있도록 설계된 구조를 가짐.
- 방법: 모델 내부에 빠른 학습을 위한 메커니즘을 내장(예: 메모리 증강, 재귀 구조).
- 대표 기법: MANN(Memory-Augmented Neural Networks), RL 기반 메타러닝.
- 예를 들어 Dong et al. 은 MAMO(Memory-Enhanced Meta Optimization)를 활용한 콜드 스타트를 학습. 이 방법에서는 특정 특(feature)에 대한 메모리를 활용해 개별적인 편차 항목(deviation items)을 제공하며, 모델의 매개변수를 구성.
3.최적화 기반 메타러닝
- 핵심 개념: 최적화 알고리즘을 조정하여 새로운 작업에 빠르게 학습하도록 함. ( 적은 수의 예제만으로도 모델이 잘 학습할 수 있도록 만드는 것)
- 방법: 모델의 초기 파라미터를 최적화하거나, 최적화 과정 자체를 학습.
- 단점: 학습 비용이 크며, 최적화 과정이 복잡할 수 있음.
- 예를 들어 Huang et al. 은 메타러닝에 기반한 새로운 사용자 시퀀스 추천 프레임워크인 metaCSR을 제안했습니다. 이 프레임워크는 새로운 사용자를 위한 효과적인 초기화를 학습할 때, MAML(Model-Agnostic Meta-Learning)을 활용해 기존 사용자들로부터 전이 가능한 정보를 추출하고 확산시킴
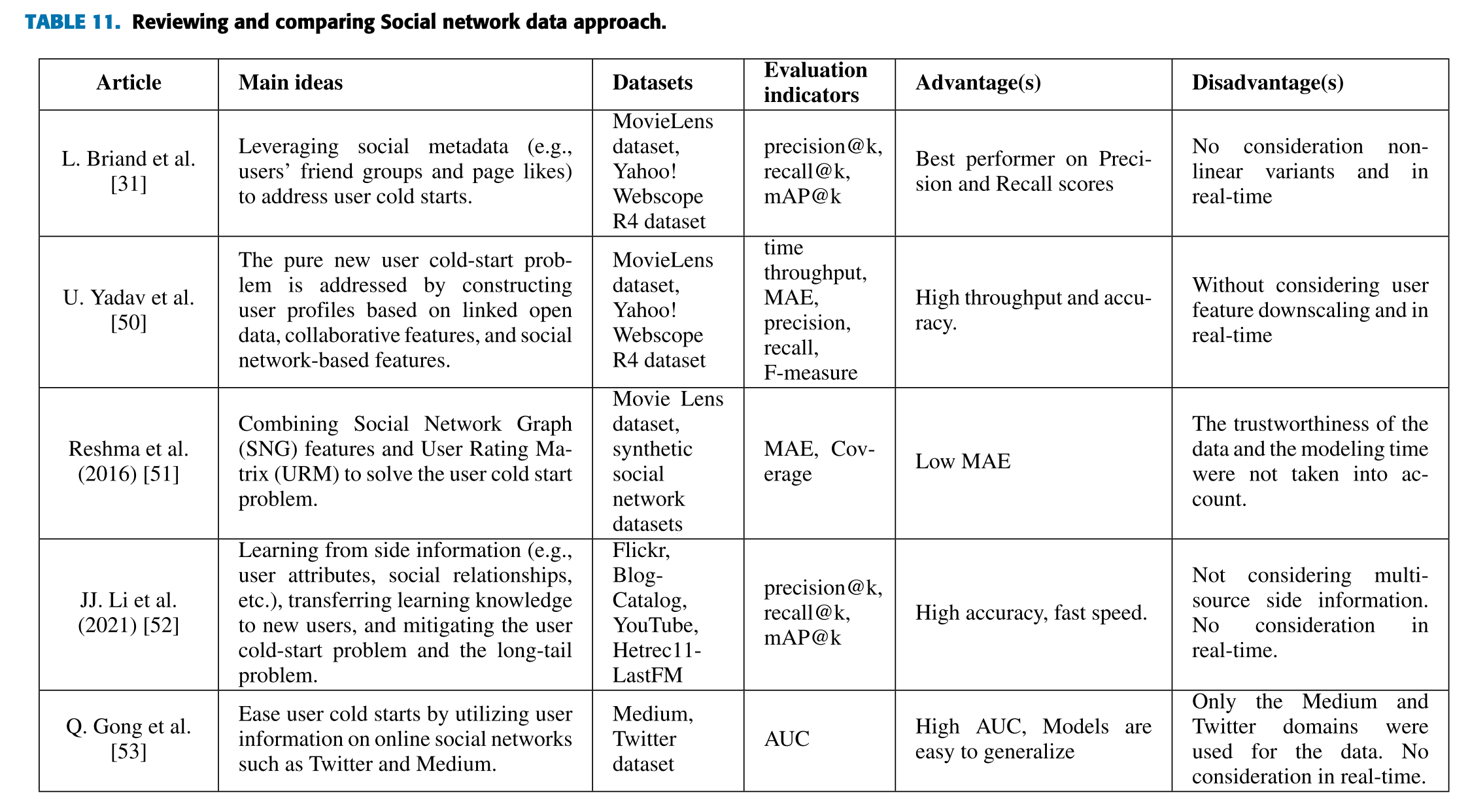
| 논문 (Article) | 주요 아이디어 (Main ideas) | 데이터셋 (Datasets) | 평가지표 (Evaluation indicators) | 장점 (Advantages) | 단점 (Disadvantages) |
|---|---|---|---|---|---|
| Y. Lu et al. [54] | 하이퍼네트워크 기반 메타러닝 추천 시스템을 제안하여 사용자 콜드 스타트 문제를 해결. | MovieLens, BookCrossing | NDCG@N, Recall@N, Hit@N | 사용자 관심을 더 빠르게 포착하고 추천 성능 향상. | 폭발적인 파라미터 문제 미고려. |
| Huang et al. [55] | 사용자 콜드 스타트 시퀀스 추천 문제를 해결하기 위한 메타러닝 기반 프레임워크 제안. | 1M, Last.fm, Amazon-Video | AUC, MAP, Hit@N, NDCG@N | 콜드 스타트와 비콜드 스타트 상황 모두에서 더 나은 성능을 보이며, 새로운 작업에 대한 일반화 가능성 제공. | 실시간 처리 미고려. |
| Jiang, F et al. [56] | 메타러닝 기반 적응형 추천 모델을 제안하여 사용자 콜드 스타트 상황에서 메타러닝 모델의 성능을 향상. | MovieLens, Yelp | MAE, RMSE, nDCG@N | MAE 및 RMSE 값이 더 작고, nDCG@N 값이 더 큼. | 실시간 고려 없음. |
| G. Wang et al. [57] | 메타 전환 학습 프레임워크를 기반으로 사용자 선호 패턴의 동적 변화를 향상. | Electronics, MovieLens-25M, VOD | MRR, Hit@N, NDCG@N | 높은 정확도. | 강건성이 부족함. |
| M. Dong et al. [58] | 이전 학습 데이터를 활용하여 사용자 콜드 스타트 문제를 해결하는 특화된 특징 기반 메타러닝 모델 제안. | MovieLens-1M, BookCrossing | MAE, NDCG@N, DCG@N | 사용자 콜드 스타트 문제 해결에 좋은 성능 및 빠른 테스트 속도. | 추가 정보가 없을 때 성능 저하, 학습 속도 낮음. |
| S. Liu et al. [59] | 메타러닝과 주제 메커니즘을 결합하여 사용자 콜드 스타트 문제를 완화. | MovieLens-1M, BookCrossing | MAE, RMSE | 적용 가능한 예제를 통해 사용자 콜드 스타트 문제를 해결하는 좋은 방법 제공. | 정보 제공 없이 일반화 논의 부족. |
| J. Misztal-Radecka et al. [60] | 사용자와 신규 아이템 보정을 위한 메타-User2Vec 접근법 제안. | MovieLens, DeskDrop | NDCG@N | 잠재적인 특징 고려, 구현 용이. | 다중 데이터 융합 미고려. |
| Y. Shen et al. [61] | 클릭 예측 정확도를 높이고 사용자 상호작용 데이터를 빠르게 학습하며 사용자 콜드 스타트 문제를 완화하는 메타러닝 모델 제안. | MovieLens, Taobao, Taobao RealImp | Logloss, AUC | 높은 정확도, 강건성, 짧은 학습 시간. | 다중 데이터 융합 미고려. |
| H. Lee et al. [62] | 사용자 상호작용 부족 및 선호 정보로 인해 발생하는 사용자 콜드 스타트 문제를 완화하기 위한 메타러닝 기반 추천 모델 제안. | MovieLens, BookCrossing | MAE, NDCG | 보다 정확한 데이터 구분 및 사용자 선호 필요. | 다중 데이터 융합 미고려. |
| X. Lin et al. [63] | 메타러닝 추천기를 활용해 사용자 선호도를 계산하는 새로운 작업 적응 메커니즘 제안. | MovieLens, Last.FM3, Gowalla | Precision@N, NDCG@N, MAP@N | 높은 정밀도 및 적합성. | 다중 데이터 융합 미고려. |
| T. Wei et al. [64] | MetaCF라는 메타러닝 기반 추천 시스템을 제안하여 서브그래프 샘플링을 사용하여 학습. | Amazon-Electronics, Kindle, LastFM | HR@10, NDCG@10 | 소수의 상호작용 데이터만으로 빠르게 신규 추천에 적응 가능. | 낮은 해석 가능성. |
| K. P. Neupane et al. [65] | 메타러닝과 증거 기반 추론을 통합하여 불확실성을 완화한 사용자 콜드 스타트 추천 시스템 제안. | MovieLens, BookCrossing, Netflix, Last.FM | RMSE, NDCG | 사용자 별 희소 데이터에서 높은 성능 제공. | 낮은 해석 가능성 및 다중 데이터 융합 미고려. |
| H. Bharadwaj [66] | 사용자 및 항목 ID를 활용하고 평점을 사용하여 사용자 콜드 스타트 문제를 해결하는 메타러닝 모델 제안. | MovieLens, Netflix, MyFitnessPal | Precision@k, AUC, MRR | 강건성, 빠른 학습, 높은 정확도. | 낮은 해석 가능성, 실시간 처리 미고려. |
| H. Wang et al. [67] | MetaCF 및 Reptile을 통합하여 사용자 콜드 스타트 문제를 해결하는 ML2E 알고리즘 제안. | MovieLens-1M, BookCrossing | Logloss, AUC | 사용자 콜드 스타트 문제에 대한 낮은 로그 손실, 일반화 가능성 높음. | 낮은 해석 가능성. |
4.2 Deep Learning
딥러닝 알고리즘
- 딥러닝 알고리즘은 신경망(neural network)을 기반으로 하는 머신러닝 알고리즘의 한 종류입니다. 딥러닝은 다층 신경망(multi-layer neural network)을 사용해 입력 데이터를 학습하고 분류
- 추천 알고리즘에서는 다음과 같은 딥러닝 기법들이 활용되고 있음
- 오토인코더(Autoencoder)
- 그래프 신경망(Graph Neural Networks, GNNs)
- 생성적 적대 신경망(Generative Adversarial Networks, GANs)
- 기타 등
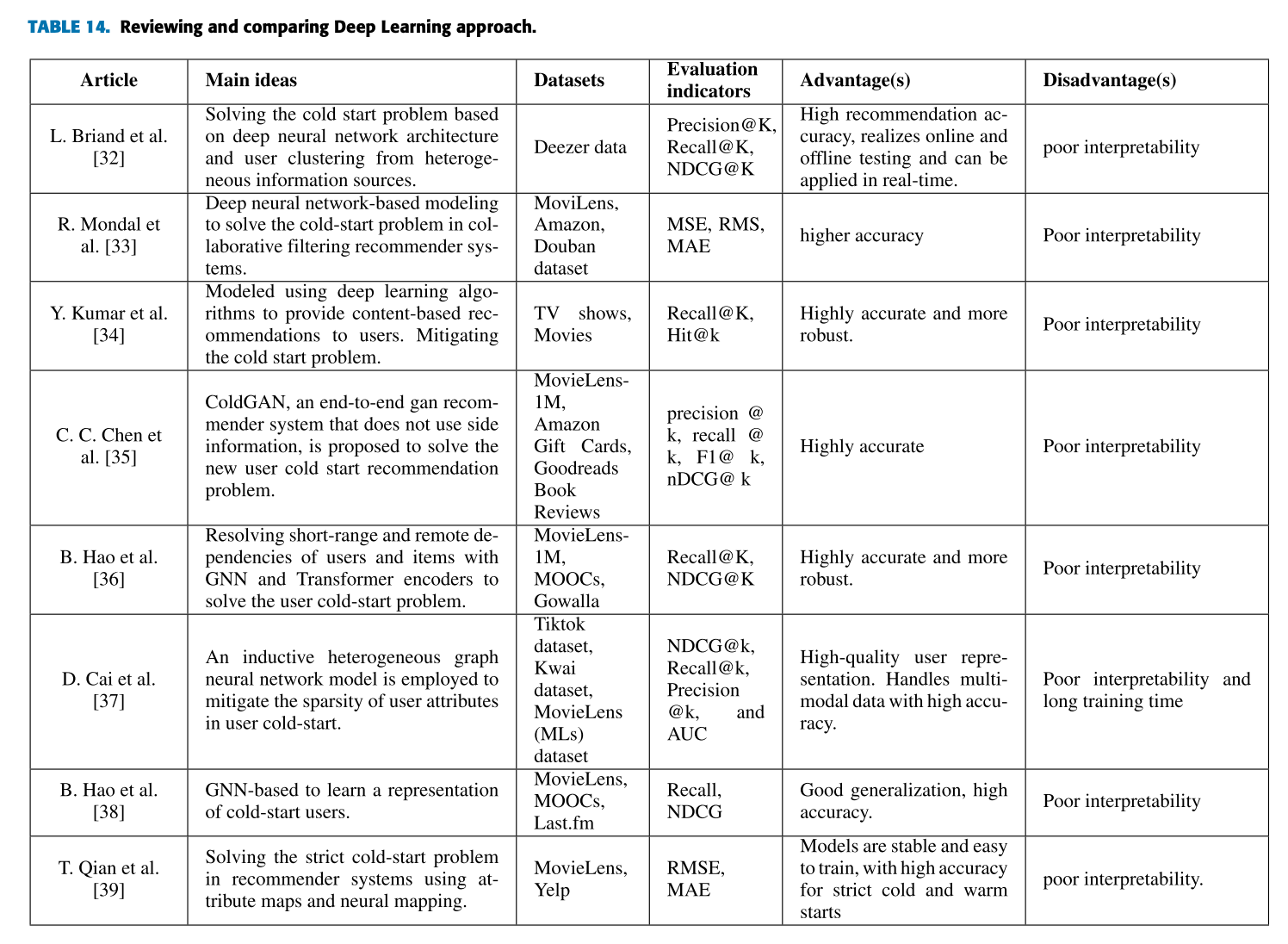
| 논문 (Article) | 주요 아이디어 (Main ideas) | 데이터셋 (Datasets) | 평가지표 (Evaluation indicators) | 장점 (Advantages) | 단점 (Disadvantages) |
|---|---|---|---|---|---|
| L. Briand et al. [32] | 이질적인 정보 소스를 기반으로 사용자 클러스터링과 딥 뉴럴 네트워크 아키텍처를 활용해 사용자 콜드 스타트 문제 해결. | Deezer 데이터셋 | Precision@K, Recall@K, NDCG@K | 높은 추천 정확도, 온라인 및 오프라인 테스트 가능, 실시간 적용 가능. | 낮은 해석 가능성. |
| R. Mondal et al. [33] | 협업 필터링 추천 시스템에서 콜드 스타트 문제를 해결하기 위한 딥 뉴럴 네트워크 기반 모델 제안. | MovieLens, Amazon, Douban 데이터셋 | MSE, RMS, MAE | 더 높은 정확도 제공. | 낮은 해석 가능성. |
| Y. Kumar et al. [34] | 딥러닝 알고리즘을 사용해 콘텐츠 기반 추천을 제공하고 콜드 스타트 문제 완화. | TV 쇼, 영화 데이터셋 | Recall@K, Hit@K | 높은 정확도와 강건성 제공. | 낮은 해석 가능성. |
| C. C. Chen et al. [35] | 추가적인 사용자 정보를 사용하지 않고 새로운 사용자 콜드 스타트 문제를 해결하기 위한 GAN 기반 추천 시스템 (ColdGAN) 제안. | MovieLens-1M, Amazon Gift Cards, Goodreads, Book Reviews | Precision@K, Recall@K, F1@K, NDCG@K | 높은 정확도 제공. | 낮은 해석 가능성. |
| B. Hao et al. [36] | GNN과 Transformer 인코더를 사용해 사용자와 아이템 간의 단기 및 장기 의존성을 해결하며 콜드 스타트 문제를 해결. | MovieLens-1M, MOOCs, Gowalla 데이터셋 | Recall@K, NDCG@K | 높은 정확도와 강건성 제공. | 낮은 해석 가능성. |
| D. Cai et al. [37] | 사용자 속성의 희소성을 완화하기 위해 유도적 이질 그래프 신경망 모델을 제안. | Tiktok, Kwai, MovieLens 데이터셋 | NDCG@K, Recall@K, Precision@K, AUC | 높은 품질의 사용자 표현 생성, 다중 모달 데이터 처리 가능. | 낮은 해석 가능성, 긴 학습 시간. |
| B. Hao et al. [38] | GNN 기반으로 사용자 콜드 스타트 문제 해결을 위한 사용자 표현 학습. | MovieLens, MOOCs, Last.fm 데이터셋 | Recall, NDCG | 좋은 일반화 능력과 높은 정확도 제공. | 낮은 해석 가능성. |
| T. Qian et al. [39] | 속성 매핑과 뉴럴 매핑을 활용해 엄격한 콜드 스타트 문제를 해결하기 위한 추천 시스템 제안. | MovieLens, Yelp 데이터셋 | RMSE, MAE | 모델이 안정적이고 학습이 용이하며, 콜드 및 웜 스타트 상황에서 높은 정확도 제공. | 낮은 해석 가능성. |
4.3 Matrix Factorization
- Matrix Factorization(행렬 분해)는 주로 추천 시스템에서 사용되는 알고리즘으로, 사용자-아이템 평점 데이터를 기반으로 잠재적 패턴(Latent Features)을 추출하여 사용자와 아이템 간의 관계를 예측하는 데 활용
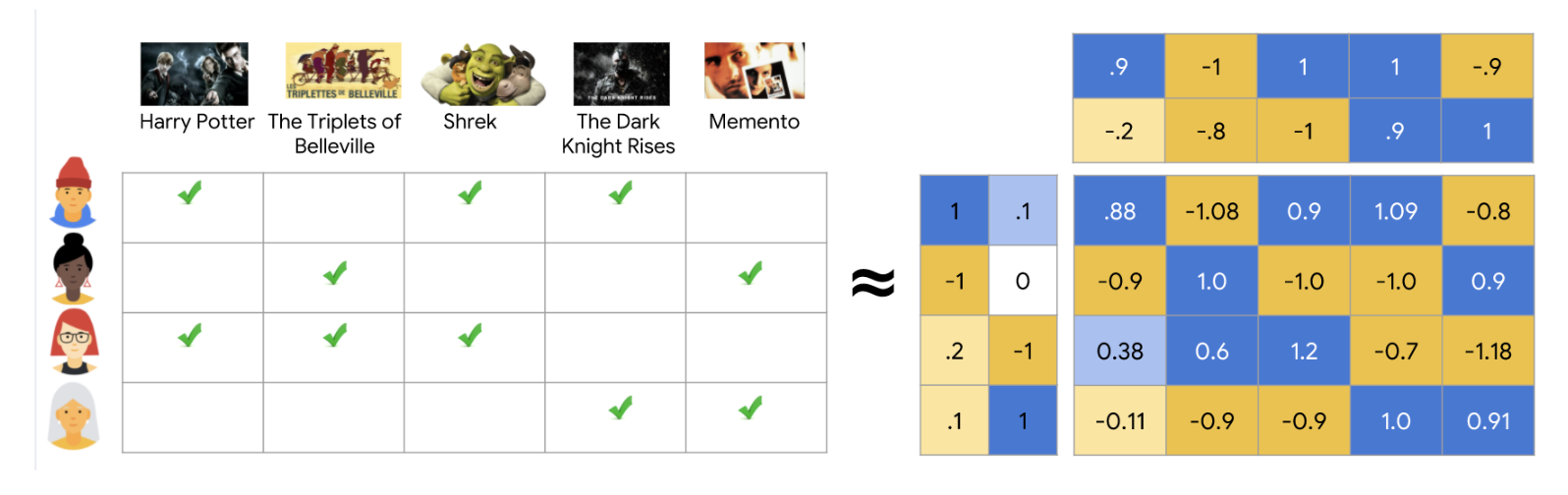
- 주어진 사용자-아이템 평점 행렬을 두 개의 저차원 행렬로 분해하여 새로운 사용자-아이템 평점을 계산하거나 예측함.
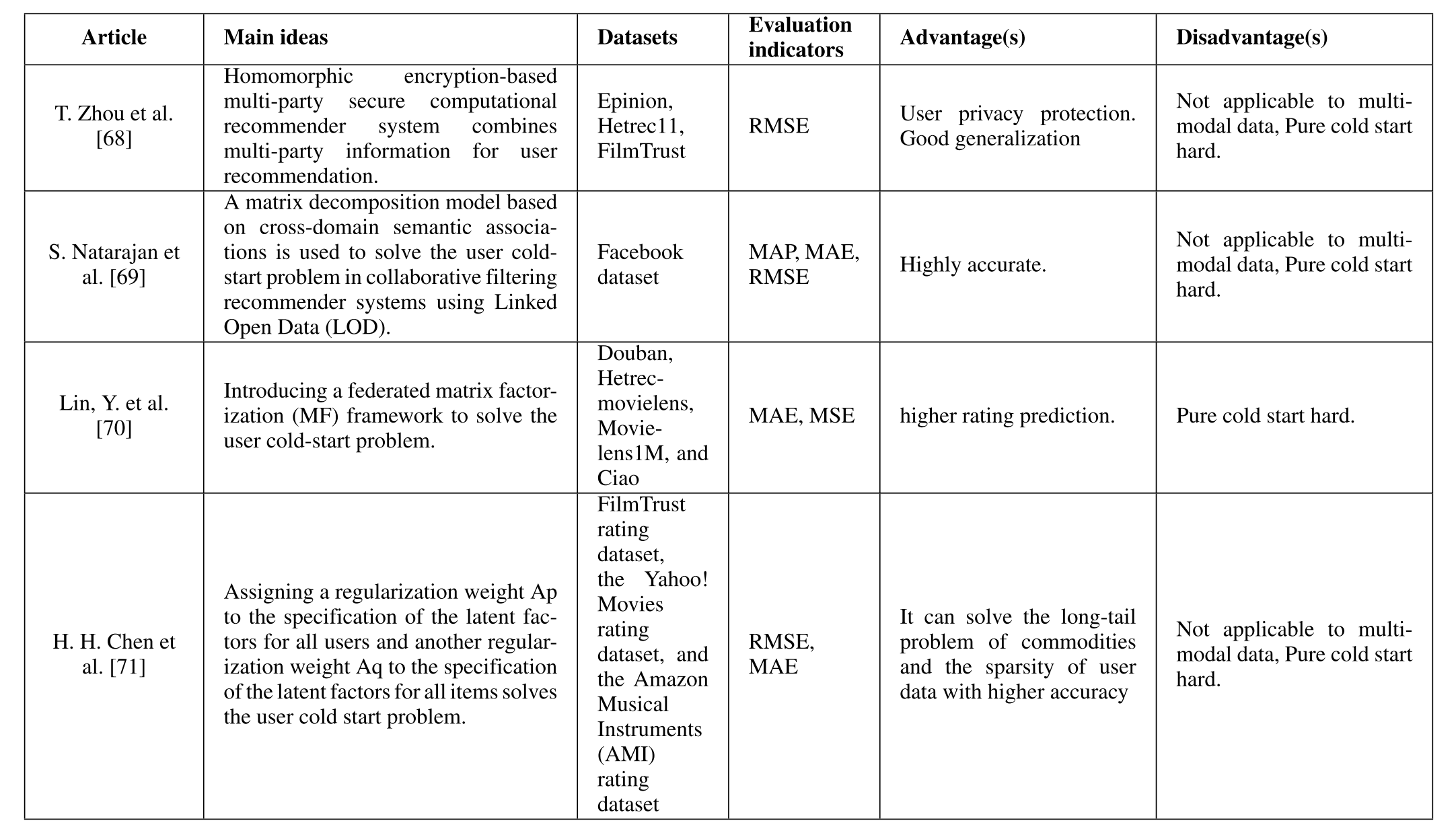
| 논문 (Article) | 주요 아이디어 (Main ideas) | 데이터셋 (Datasets) | 평가지표 (Evaluation indicators) | 장점 (Advantages) | 단점 (Disadvantages) |
|---|---|---|---|---|---|
| T. Zhou et al. [68] | 동형 암호화 기반의 다자간 보안 계산을 통해 다자간 정보를 결합하여 사용자 추천을 수행하는 추천 시스템 제안. | Epinion, Hetrec11, FilmTrust | RMSE | 사용자 프라이버시 보호 및 좋은 일반화 성능 제공. | 다중 모달 데이터에 적용되지 않음, 순수 콜드 스타트 문제 해결 어려움. |
| S. Natarajan et al. [69] | 크로스 도메인 의미 연관성을 기반으로 한 행렬 분해 모델을 사용하여 협업 필터링 추천 시스템에서 사용자 콜드 스타트 문제를 해결. | Facebook 데이터셋 | MAP, MAE, RMSE | 높은 정확도 제공. | 다중 모달 데이터에 적용되지 않음, 순수 콜드 스타트 문제 해결 어려움. |
| Lin, Y. et al. [70] | 사용자 콜드 스타트 문제를 해결하기 위해 연합 행렬 분해(Federated Matrix Factorization) 프레임워크를 제안. | Douban, Hetrec-movielens, MovieLens1M, Ciao | MAE, MSE | 평점 예측 정확도 향상. | 순수 콜드 스타트 문제 해결 어려움. |
| H. H. Chen et al. [71] | 사용자 및 아이템에 대한 잠재 요인(라틴 팩터)의 정규화 가중치를 할당하여 사용자 콜드 스타트 문제를 해결. | FilmTrust, Yahoo! Movies, Amazon Musical Instruments (AMI) | RMSE, MAE | 롱테일 문제와 사용자 데이터 희소성 문제를 더 높은 정확도로 해결 가능. | 다중 모달 데이터에 적용되지 않음, 순수 콜드 스타트 문제 해결 어려움. |
4.4 Improved New Approach Based on Collaborative Filtering
Collaborative Filtering vs Content-based Filtering
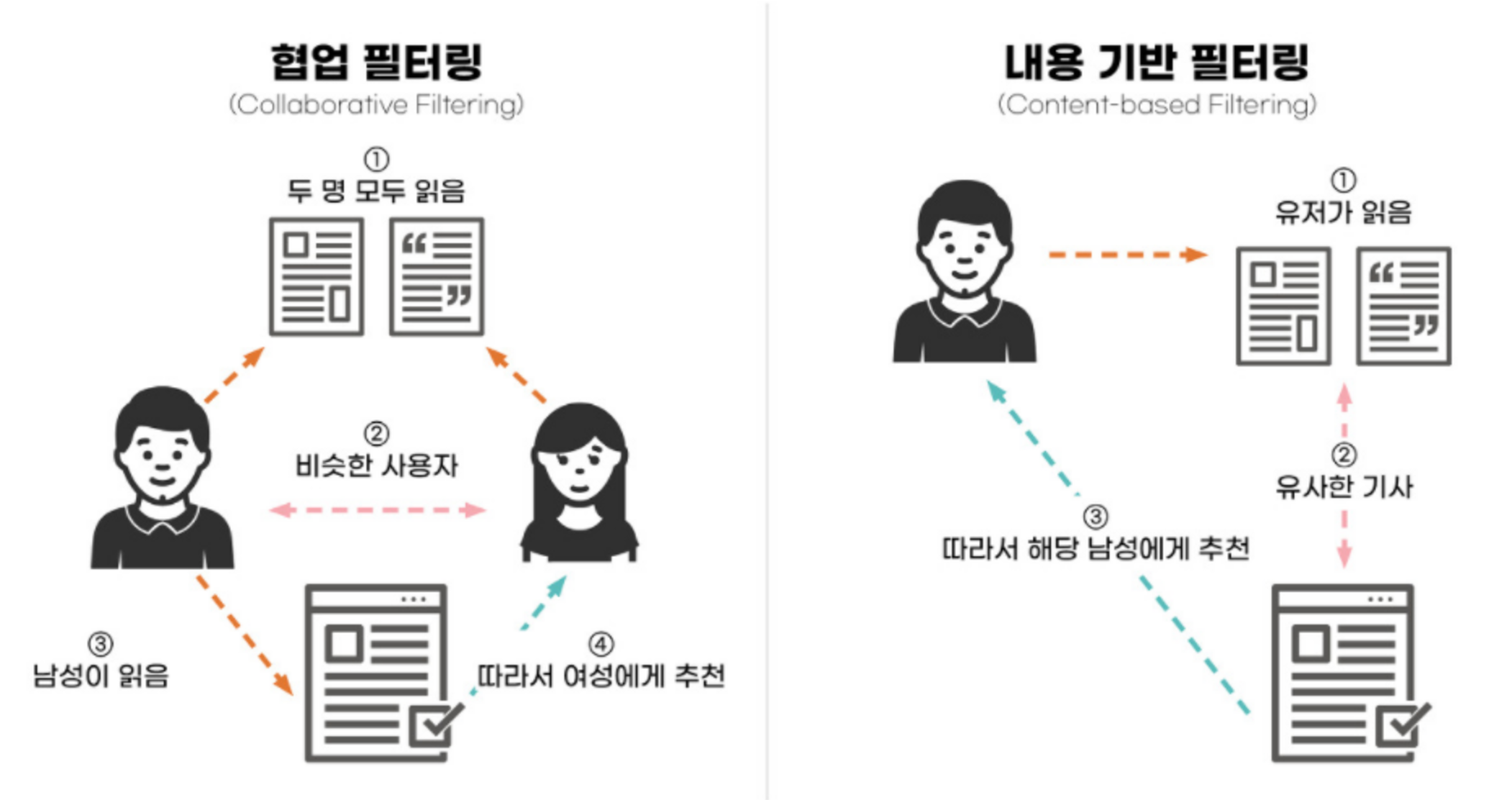
- 협업 필터링 모델(Collaborative Filtering, CF)인데요, 이것은 다른 사용자들로부터 취향 정보들을 모아 사용자의 관심사를 예측하는 방법입니다. CF 모델은 비슷한 취향을 가진 사용자들은 어떠한 아이템에 대해 비슷한 선호도를 가질 것이라는 가정 하에 사용자와 아이템 간 상호 작용 데이터를 활용. 만약 캐롤을 좋아하는 사람들이 공통적으로 판타지 영화에 대해 높은 선호도를 보인다면 사용자에게 “해리포터”를 추천해줄 수도 있음
- 콘텐츠 기반 필터링 모델(Content-based Filtering)은 콘텐츠만을 활용하여 추천해주는 알고리즘. 사용자가 좋아하는 콘텐츠를 분석하여 그와 유사한 콘텐츠를 추천해주는 기술입니다.
Collaborative Filtering
- 즉 협업 필터링(Collaborative Filtering, CF)은 추천 시스템에서 사용자의 과거 행동과 다른 사용자들의 데이터를 활용해 추천을 수행하는 알고리즘입니다. 이 알고리즘의 핵심 아이디어는 유사한 선호도를 가진 사용자들이 유사한 항목을 좋아할 가능성이 높다는 점을 기반으로 함. 그래서 사용자나 아이템의 세부적인 콘텐츠 정보가 없어도 추천을 수행할 수 있음.
| 논문 (Article) | 주요 아이디어 (Main ideas) | 데이터셋 (Datasets) | 평가지표 (Evaluation indicators) | 장점 (Advantages) | 단점 (Disadvantages) |
|---|---|---|---|---|---|
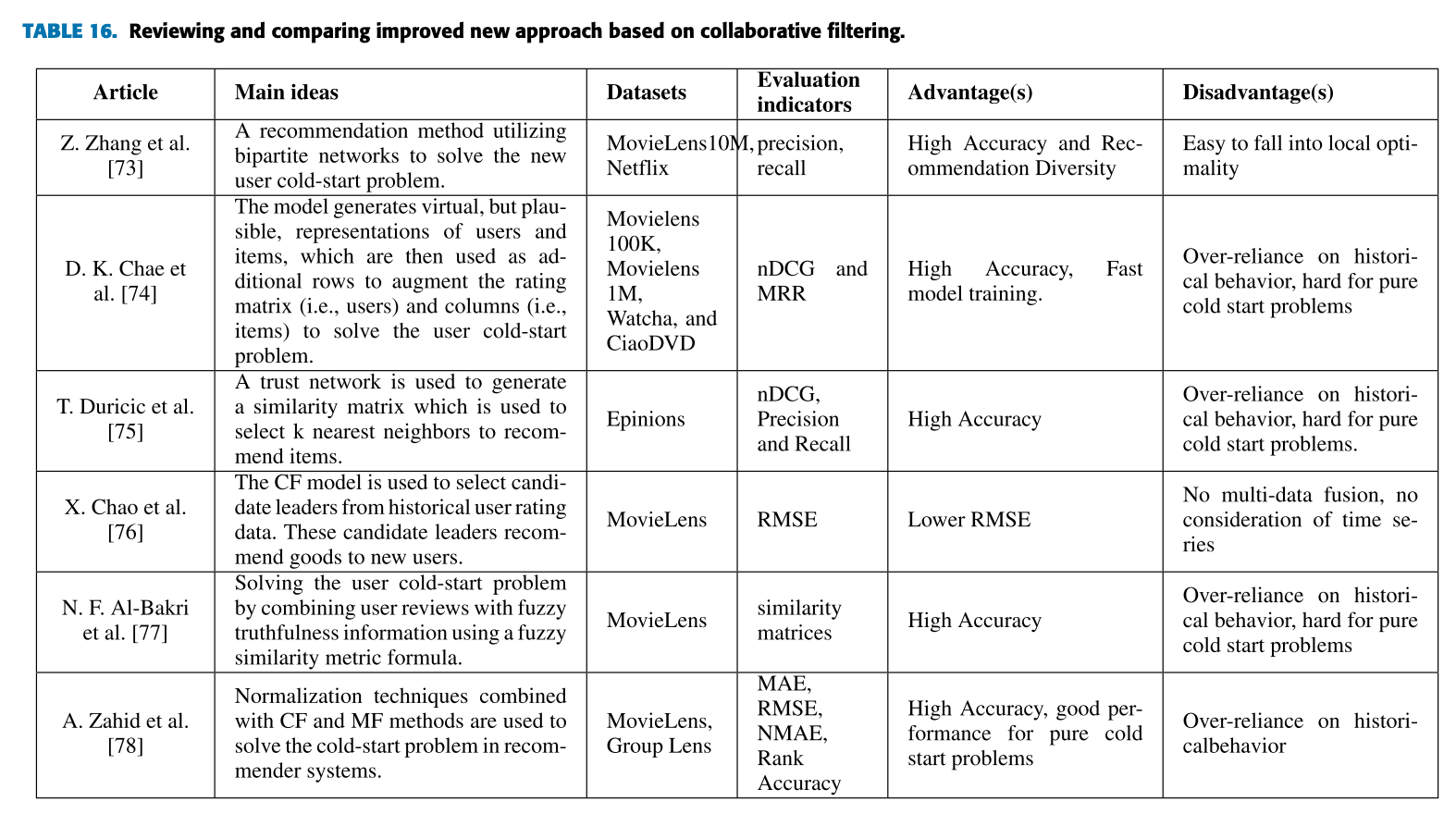
| Z. Zhang et al. [73] | 바이파티트 네트워크(bipartite network)를 활용하여 새로운 사용자 콜드 스타트 문제를 해결하는 추천 방법 제안. | MovieLens10M, Netflix | Precision, Recall | 높은 정확도와 추천 다양성 제공. | 지역 최적화(local optimality)에 빠질 가능성이 있음. |
| D. K. Chae et al. [74] | 가상 사용자와 아이템의 표현을 생성하여 평점 행렬에 추가 행과 열로 사용하고, 이를 통해 사용자 콜드 스타트 문제 해결. | Movielens100K, Movielens1M, Watcha, CiaoDVD | nDCG, MRR | 높은 정확도, 빠른 모델 학습. | 과거 행동에 과도하게 의존하며, 순수 콜드 스타트 문제 해결이 어려움. |
| T. Duricic et al. [75] | 신뢰 네트워크를 사용해 유사도 행렬을 생성하고, 이를 기반으로 k개의 가장 가까운 이웃을 선택하여 아이템 추천. | Epinions | nDCG, Precision, Recall | 높은 정확도. | 과거 행동에 과도하게 의존하며, 순수 콜드 스타트 문제 해결이 어려움. |
| X. Chao et al. [76] | 협업 필터링(CF) 모델을 사용해 과거 사용자 평점 데이터를 기반으로 리더 후보를 선택하고, 이 리더들이 신규 사용자에게 상품을 추천. | MovieLens | RMSE | RMSE 값 감소. | 다중 데이터 융합 미고려, 시간 시퀀스(time series) 미고려. |
| N. F. Al-Bakri et al. [77] | 사용자 리뷰와 퍼지 진위(fuzzy truthfulness) 정보를 결합하여 사용자 콜드 스타트 문제 해결을 위한 퍼지 유사도 메트릭 공식을 제안. | MovieLens | Similarity Matrices | 높은 정확도. | 과거 행동에 과도하게 의존하며, 순수 콜드 스타트 문제 해결이 어려움. |
| A. Zahid et al. [78] | 협업 필터링(CF)과 행렬 분해(MF) 기법을 결합하여 정규화 기법을 사용, 추천 시스템의 사용자 콜드 스타트 문제 해결. | MovieLens, GroupLens | MAE, RMSE, NMAE, Rank Accuracy | 높은 정확도와 순수 콜드 스타트 문제에서의 좋은 성능 제공. | 과거 행동에 과도하게 의존. |
4.5 New Improved Content-based Approach
- 콘텐츠 기반 추천 알고리즘(content-based recommendation algorithm)은 사용자의 과거 행동 기록과 아이템 속성(attribute)을 기반으로 비슷한 아이템을 추천하는 알고리즘입니다. 이 알고리즘의 핵심 아이디어는 사용자의 행동 데이터를 이용하는 대신, 아이템 자체의 특성을 활용해 추천을 수행한다는 점입니다. 그래서 사용자의 개인 정보나 행동 데이터를 필요로 하지 않음. 하지만 사용자의 변화하는 관심사나 선호도를 반영하지 못할 수 있어, 특정 상황에서 추천이 부정확해질 가능성이 있습니다. 특히 사용자 콜드 스타트 문제(user cold-start problem)에 취약
| 연구자 | 접근법/모델 | 주요 아이디어 | 특징 및 성과 |
|---|---|---|---|
| Kannout et al. [40] | FPRS (Frequent Pattern Mining Framework) | 신규 사용자와 아이템의 콜드 스타트 문제를 해결하기 위해 빈번하게 발생하는 아이템 집합과 콘텐츠 기반 전략을 결합한 추천 시스템 프레임워크를 제안하며 실증 연구를 통해 방법의 효능을 확인. | 빈번한 패턴 탐지와 콘텐츠 기반 전략 결합으로 추천 성능 개선. |
| Chia et al. [41] | TF-IDF 텍스트 마이닝 기법 | 데이터 필터링과 정보 검색을 위해 TF-IDF 기반 텍스트 마이닝 기술을 활용하여 콘텐츠 기반 추천의 효율성을 증대. | 텍스트 마이닝으로 콘텐츠 필터링 정확도 향상. |
| Li et al. [42] | Cold-Transformer | 특징 분포의 변화를 고려하기 위해 문맥 기반 적응 임베딩(Context-based Adaptive Embedding)을 생성하며, 신규 사용자의 임베딩을 기존 사용자와 유사한 "핫 상태"로 변환해 관련 사용자 선호도를 반영. | 문맥 적응 임베딩으로 신규 사용자와 기존 사용자 간의 격차 완화. |
5 METRICS TO ASSESS USER COLD START
- 사용자 UUU와 테스트 세트 SSS를 기반으로, 해당 사용자를 위한 모든 추천 결과를 순위로 계산한 값입니다.
- 추천 시스템의 Top-K 정확도가 높을수록, 사용자가 관심을 가질 가능성이 높은 아이템을 더 잘 예측하고 정렬할 수 있음을 나타냅니다.
- 주로 사용되는 지표는 NDCG@K, Hit@K 등입니다.
6 Conclusion
데이터 기반 접근 방식
- 데이터 기반 접근 방식은 주로 다양한 사용자 정보를 활용하여 New - User 문제를 해결하는 데 사용됩니다. 예를 들어, 사용자 소셜 네트워크 데이터나 인구통계학적 데이터를 활용합니다. 이러한 방식의 장점은 사용자 관련 데이터(예: 소셜 네트워크 데이터)를 활용해 과거 행동 데이터가 없는 신규 사용자 문제를 보다 효과적으로 해결할 수 있다는 점입니다. 이를 통해 사용자 콜드 스타트 문제를 완화할 수 있습니다.
- 하지만, 이 방법에는 다중 도메인에서 활동하는 사용자의 Feature 융합의 어려움, 사용자 데이터의 프라이버시 문제, 그리고 사용자 데이터 수집의 어려움과 같은 몇 가지 문제가 존재합니다.
방법론 기반 접근 방식
- 방법론 기반 접근 방식은 다양한 알고리즘이나 모델을 적용하여 문제를 해결합니다. 이 논문에서는 방법론 기반 접근 방식을 다섯 가지로 세분화했습니다:
- 메타러닝 기법
- 딥러닝 기법
- 행렬 분해 기법
- 협업 필터링을 기반으로 한 새로운 기법
- 콘텐츠 기반 추천 시스템의 새로운 기법
- 이 방법의 장점은 일부 규칙을 활용해 사용자 콜드 스타트 문제를 해결할 수 있다는 것입니다. 예를 들어, 기계 학습 관련 기법은 빠른 학습을 통해 신규 사용자에게 추천을 제공할 수 있으며, 다중 특징 융합 문제를 보다 효과적으로 해결할 수 있습니다.
- 하지만 이러한 방법은 모델이 복잡하고 순수 콜드 스타트 문제에서는 결과가 저조하다는 단점이 있습니다.
- 기계 학습 및 딥러닝 기술이 다양한 학문 분야에서 점점 더 많이 사용되고 있으며, DNN, GNN 등의 기법이 신규 사용자 문제를 완화하는 데 더 많이 활용되고 있습니다.
콜드 스타트 vs 데이터 희소성 문제
- 콜드 스타트 문제와 데이터 희소성 문제는 추천 시스템에서 충분한 정보가 부족한 상황과 관련이 있지만, 발생 시점, 범위, 해결 방식이 다릅니다.
- 콜드 스타트 문제는 사용자 등록 정보나 아이템 메타데이터와 같은 추가 정보를 확보하는 데 초점을 맞추는 반면, 데이터 희소성 문제는 기존 데이터를 활용해 누락된 정보를 보완하는 데 초점을 맞춥니다. 기계 학습, 메타러닝, 일부 하이브리드 접근 방식은 두 문제를 동시에 해결할 수 있습니다.
콜드 스타트 모델 평가
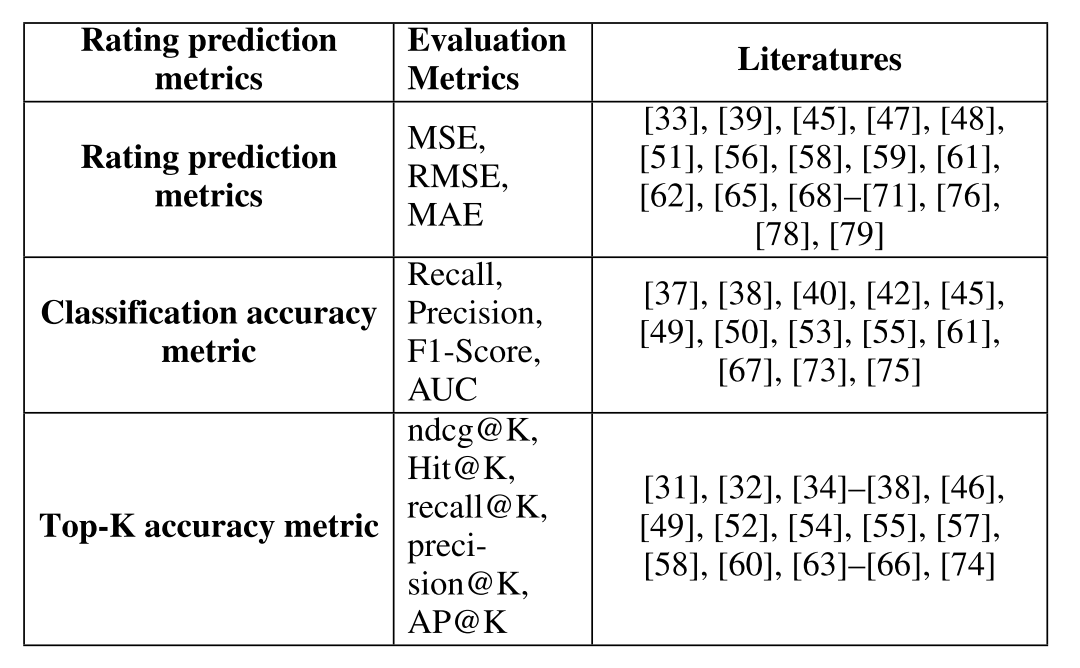
- 사용자 콜드 스타트 모델 평가에는 세 가지 주요 평가 지표가 사용됩니다:
- . 평점 예측 지표 (Rating Prediction Metrics)
- 분류 정확도 지표 (Classification Accuracy Metrics)
- 순위 지표 (Ranking Metrics)
- 대부분의 연구는 모델을 종합적으로 평가하기 위해 다양한 평가 지표를 선택합니다. 일부 논문은 단일 지표만 사용하여 평가를 진행하기도 합니다. 하지만 대부분의 연구는 순위 지표를 평가 지표로 채택합니다.
- 최근 NDCG가 사용자 콜드 스타트 추천 시스템의 성능을 분석하는 데 점점 더 많이 사용되고 있음을 확인할 수 있습니다.
