
1 INTRODUCTION
추천 시스템은 검색 랭킹 시스템(search ranking system)으로 볼 수 있음. 입력 쿼리는 사용자와 맥락 정보(contextual information), 출력은 순위가 매겨진 항목 목록(ranked list of items). 주어진 쿼리에 대해 추천 작업은 데이터베이스에서 관련 있는 항목(relevant items)을 찾아내고, 클릭(clicks)이나 구매(purchases)와 같은 특정 목표에 따라 항목들을 순위화(ranking)하는 것임.
추천시스템에서의 과제는 memorization과 generalization 측면에서 동시에 좋은 성능을 내는 것이다.
- memorization : 자주 함께 등장하는 아이템 쌍 혹은 feature 조합을 학습하는 것
- generalization : 과거에 자주 관찰되지 않은 조합이라도, 특징 간의 간접적인 상관 관계를 통해 새로운 조합을 학습하는것
- 사용자가 비디오 앱(Netflix)을 설치하고, 다른 사용자는 음악 앱(Spotify)을 설치했다는 데이터를 학습했다고 가정합니다.
- 만약 "비디오"와 "음악"이라는 카테고리 간에 상관 관계가 있다면, 특정 사용자가 비디오 앱을 설치했을 때, 음악 앱(예: Pandora)을 추천할 수 있습니다. 이는 과거에 "Netflix -> Pandora" 조합이 직접적으로 나타나지 않았더라도 가능해집니다.
각 추천 방식의 특징은 아래와 같음
- memorization에 기반한 추천
- 해당 방식의 추천은 보통 더 주제 관련되어서 추천되거나 사용자가 이미 액션을 취한 항목과 직접적으로 관련됨
- "주제별"이란 사용자가 관심을 가진 특정 카테고리나 주제에 초점을 맞춘 추천을 의미. 예를 들어 사용자가 스포츠 관련 앱을 설치한 기록이 있다면, 다른 스포츠 앱을 추천할 가능성이 높음
- generalization에 기반한 추천은 추천된 아이템의 다양성을 높이는데 목적이 있다.
대규모 온라인 추천 및 랭킹 시스템을 위해 로지스틱 회귀와 같은 generalized linear model 이 널리 사용된다. 이는 단순하고 확장 가능하며 해석 가능하기 때문이다.
- 원-핫 인코딩된 이진 희소 특징(binarized sparse features)으로 학습된다.
- 희소 특징에 대한 교차 변환(cross-product transformations)을 사용하여서 feature interaction을 학습하기도 함.
- 그러나 이러한 경우 training data에 없는 feature 조합에 대해서는 일반화시킬 수 없다는 한계가 존재한다.
factorization machine이나 DNN과 같은 embedding-based 모델은 관찰되지 않은 feature 조합에 대해서도 generalization 성능이 높다.
-
쿼리와 항목 Feature에 대해 저차원 밀집 임베딩 벡터 (low-dimensional dense embedding vector)를 학습하여 이전에 보지 못한 쿼리-항목 특징 쌍에 일반화할 수 있으며, 또한 Feature 엔지니어링의 부담이 적음
-
그러나 쿼리-항목 행렬 (query-item matrix)이 희소 (sparse)하고 고차원 (high-rank)일 경우, 효과적인 저차원 표현 (low-dimensional representations)을 학습하기 어렵다.
-
즉 예시를 들면 다음과 같은 사용자에 대해서는 학습이 어렵다는 것이다.
- 특정한 선호를 가진 사용자 (users with specific preferences):
- 예를 들어, 한 사용자가 특정한 장르의 영화만 좋아하거나, 특정 취미(예: 희귀 수집품)를 가진 경우, 이 사용자는 보통 대중적인 아이템보다 특화된 아이템을 선호합니다.
- 좁은 관심사를 사용자 (niche items with a narrow appeal):
- 예를 들어, 대중적으로 인기가 없는 희소한 물품이나 서비스(예: 특정 지역 전통 음악 앱)는 관심을 가진 사용자 자체가 적음
- 특정한 선호를 가진 사용자 (users with specific preferences):
-
이때 밀집 임베딩은 모든 쿼리-항목 쌍(query-item pairs)에 대해 0이 아닌 예측값(nonzero predictions)을 생성함. 이로 인해 과도하게 일반화 (over-generalize)되어 덜 관련성 있는 추천 (less relevant recommendations)을 할 가능성이 있음.
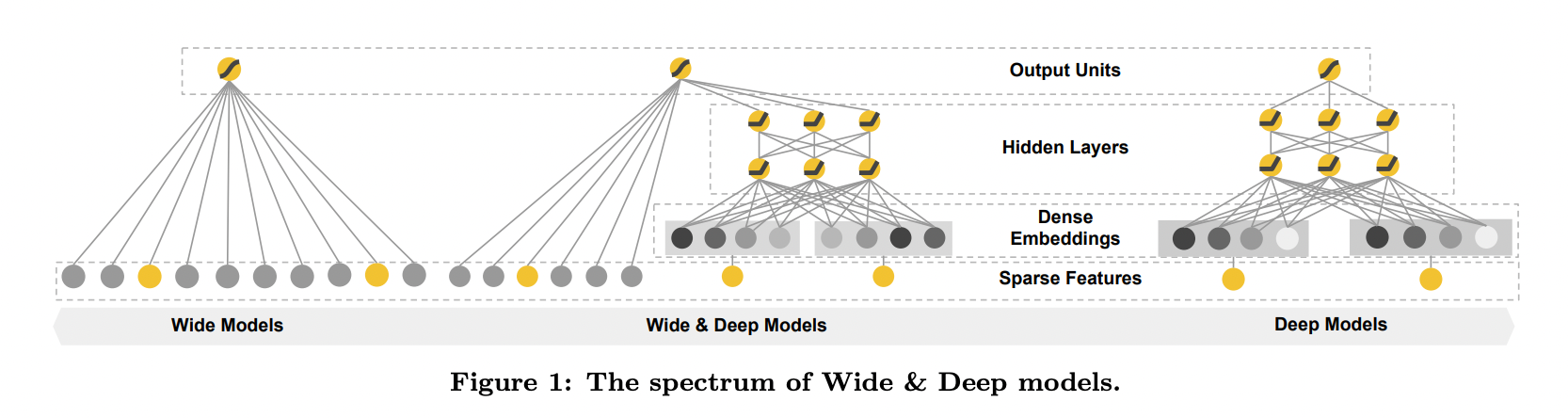
-
메모리제이션(memorization)과 일반화(generalization)를 하나의 모델에서 동시에 달성하기 위해, 선형 모델 구성 요소(linear model component)와 신경망 구성 요소(neural network component)를 함께 학습(jointly training)하는 Wide & Deep 학습 프레임워크(Wide & Deep learning framework)를 소개합니다.
2 RECOMMENDER SYSTEM OVERVIEW
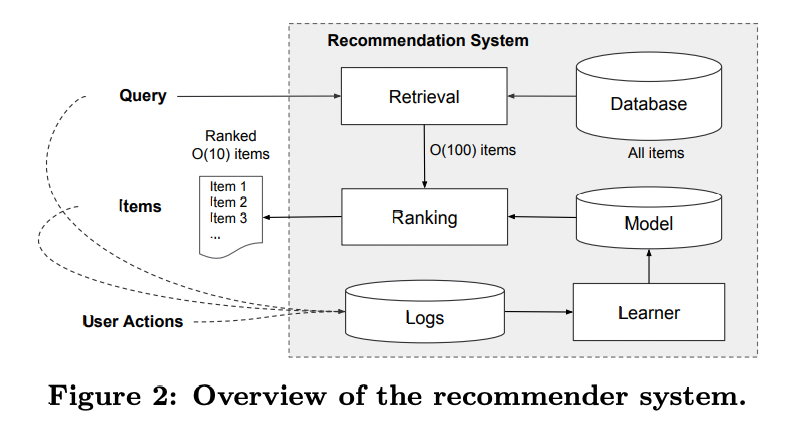
- 앱 추천 시스템의 개요는 위 그림 2에 나와 있음. 사용자가 앱 스토어를 방문하면, 사용자 및 맥락 정보(contextual features)로 구성된 쿼리(query)가 생성됩니다.
- 쿼리(Query)
- 사용자가 앱 스토어를 방문하면 시스템은 사용자와 맥락 정보를 바탕으로 쿼리를 생성.
- Ex : 사용자 특징: 거주 국가, 언어, 나이 등
- Ex : 맥락 특징: 디바이스 종류, 시간대 등
- 사용자가 앱 스토어를 방문하면 시스템은 사용자와 맥락 정보를 바탕으로 쿼리를 생성.
- 검색(Retrieval)
- 데이터베이스(Database)에 있는 전체 아이템(앱)을 대상으로, 주어진 쿼리에 가장 적합한 O(100)개의 후보군을 추출해서, 후보군을 축소해서 그 뒤 ranking 시스템의 부담을 줄여줌
- 이 단계는 빠르게 동작해야 하므로 머신러닝 모델과 사람이 정의한 규칙을 조합해 사용.
- 데이터베이스(Database)에 있는 전체 아이템(앱)을 대상으로, 주어진 쿼리에 가장 적합한 O(100)개의 후보군을 추출해서, 후보군을 축소해서 그 뒤 ranking 시스템의 부담을 줄여줌
- 랭킹(Ranking)
- 검색 단계에서 추출된 후보군(O(100))을 대상으로 점수를 매겨 최종 순위를 결정.
- 점수는 , 즉 사용자가 행동(클릭, 구매 등)을 할 확률로 계산.
- 최종적으로 O(10)개의 아이템을 추천.
- 로그(Logs) 및 학습자(Learner)
- 사용자 행동(클릭, 구매 등)을 기록해 로그로 저장.
- 이 로그 데이터를 학습자(Learner)가 사용해 모델을 지속적으로 개선.
- 쿼리(Query)
- 데이터베이스에 100만 개 이상의 앱이 있어, 모든 쿼리에 대해 모든 앱을 평가하는 건 현실적으로 불가능한데 이는 서비스 Latency 요구 조건(보통 O(10) 밀리초) 때문.
- 쿼리 수신 시 첫 단계는 검색(retrieval). 검색 시스템은 머신러닝 모델과 사람이 정의한 규칙(human-defined rules) 조합으로 쿼리와 가장 잘 맞는 항목의 짧은 목록 반환. 후보군 축소 후 랭킹 시스템(ranking system)이 항목을 점수에 따라 순위 매김.
- 이 점수는 보통 , 즉 사용자 행동 레이블 가 특징 (사용자 특징, 맥락 특 징, 인상 특징을 포함)에 따라 발생할 확률을 나타냄
- 사용자 특징(user features): 국가, 언어, 인구통계 정보 등
- 맥락 특징(contextual features): 디바이스, 시간대, 요일 등
- 인상 특징(impression features): 앱 출시 시점, 앱의 과거 통계 등
- 이 논문에서는 Wide \& Deep 학습 프레임워크를 활용한 랭킹 모델에 초점을 맞춤
3 Wide & Deep learning
3.1 The Wide Component
와이드 컴포넌트(Wide Component)는 다음 형태의 일반화 선형 모델 (generalized linear model)로 구성됨:
- : 예측값(prediction)
- 개의 특징(feature)로 이루어진 벡터
- : 모델 파라미터(parameters)
- : 바이어스(bias)
특징 집합(feature set)은 아래와 같음
- 원시 입력 특징(raw input features)와 변환된 특징(transformed features)를 포함.
- 이 중에서 가장 중요한 변환 중 하나는 교차 변환(cross-product transformation)으로 정의됨.
여기서:
- : 부울 값(0 또는 1).
- -번째 특징이 -번째 교차 변환 에 포함될 경우.
- : 포함되지 않을 경우.
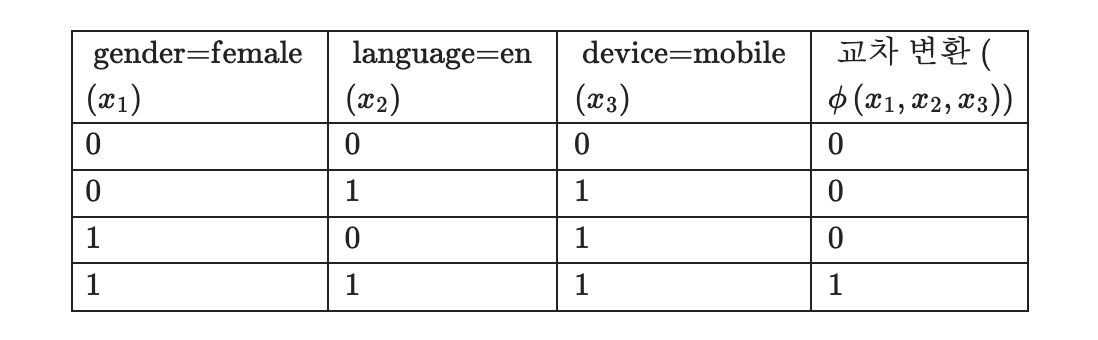
위를 이해하기 위해서, 아래 세 가지 이진 특징이 있다고 가정해봅시다.
- "gender=female"
- "language=en"
- "device=mobile"
이 특징들의 교차 변환은 다음과 같이 계산이 가능합니다.
아래는 이 세 가지 특징에 대한 교차 변환 결과를 표로 나타낸 것입니다.
- 이 방식은 이진 특징 간의 상호작용(interactions)을 캡처하고, 일반화 선형 모델에 비선형성(nonlinearity)을 추가
3.2 The deep component
- 전방향 신경망(feed-forward neural network)으로 구성됨.
- 범주형 특징(categorical features): 입력값은 특징 문자열(feature strings)로 표현됨.
예: "language=en" - 이러한 희소(sparse)하고 고차원(high-dimensional)인 범주형 특징은 먼저 저차원(low-dimensional)이고 밀집(dense)된 실수값 벡터(real-valued vector)로 변환됨. 이를 흔히 임베딩 벡터(embedding vector)라고 부름.
임베딩 벡터의 특성
- 임베딩의 차원(dimensions)은 보통 에서 수준.
- 임베딩 벡터는 처음에는 무작위 값으로 초기화(randomly initialized)되고, 모델 학습 중 최종 손실 함수(loss function)를 최소화하도록 학습됨.
임베딩 벡터의 학습 과정
- 데이터:
- 범주형 특징: "language=en", "language=es", "language=fr".
- 학습 전 임베딩 행렬 (3개의 범주, 2 차원 임베딩):
- 학습 과정:
- "language=en"의 임베딩 벡터 사용.
- 모델 출력과 실제값 비교 손실 계산.
- 그래디언트 계산 후 업데이트.
- 반복 학습 후 최종적으로 임베딩 벡터가 데이터에 맞게 최적화됨:
임베딩 벡터와 신경망
- 변환된 저차원 밀집 임베딩 벡터는 신경망의 은닉층(hidden layers)으로 전달됨.
- 은닉층에서는 각 층이 다음 계산을 수행:
여기서:
- : 현재 층 번호(layer number).
- : 활성화 함수(activation function). 주로 ReLU(Rectified Linear Unit) 사용.
- 번째 층의 활성화값(activations).
- 번째 층의 바이어스(bias).
- 번째 층의 모델 가중치(weights).
여기서 는 activation function, 는 weight matrix, 는 bias를 의미한다. 위 그림에 따르면 총 3 개의 layer를 쌓았으며, 로 ReLU를 사용했다.
https://github.com/jrzaurin/Wide-and-Deep-Keras/blob/master/wide_and_deep_keras.py
위 블로그의 코드를 보면 좀 이해가 빠름
3.3 Joint training of wide & deep model
Wide 컴포넌트와 Deep 컴포넌트는 출력 로그 오즈(log odds)의 가중 합(weighted sum)을 예측값(prediction)으로 결합하며, 이 예측값은 하나의 공통 로지스틱 손실 함수(logistic loss function)에 전달되어 공동 학습(joint training)이 이루어짐.
Joint Training vs. Ensemble
- Joint Training (공동 학습)
- Wide와 Deep 컴포넌트를 동시에 최적화함.
- Wide와 Deep의 출력과 가중치를 함께 고려하며 학습.
- 예측 성능을 개선하기 위해 두 컴포넌트가 서로를 보완.
- Ensemble
- 각 모델이 독립적으로 학습됨(별도로 학습).
- 학습 시 서로의 존재를 알지 못하고, 예측 시점(inference time)에만 결합.
- 일반적으로 개별 모델의 크기가 더 커야 함(더 많은 특징과 변환 필요).
Joint Training의 이점
- 모델 크기 감소:
- Joint Training에서는 Wide 컴포넌트가 Deep 컴포넌트의 약점을 보완하는 데 집중.
- Wide 컴포넌트가 전체적으로 큰 모델일 필요 없이 소수의 교차 변환(cross-product feature transformations)만 포함해도 충분.
- 반면, 앙상블 방식은 개별 모델이 독립적으로 학습되기 때문에 각 모델이 더 크고 복잡해야 함.
학습 과정
- 역전파(Backpropagation):
- 출력값으로부터 Wide와 Deep 컴포넌트로 동시에 그래디언트(gradients)를 전달.
- 두 컴포넌트를 모두 최적화.
- 최적화 알고리즘:
- Wide 부분:
- Follow-the-regularized-leader (FTRL) 알고리즘 사용.
- 정규화를 적용해 희소성(sparsity)을 강화.
- Deep 부분:
- AdaGrad 알고리즘 사용.
- 학습률 조정을 통해 효율적 학습.
- Wide 부분:
모델의 예측값은 다음과 같이 계산됨:
식의 각 구성 요소
- :
- 이진 클래스 레이블 Y 가 1일 확률.
- : 이진 레이블(예: 1 은 클릭, 0 은 클릭하지 않음).
- :
- 시그모이드 함수(sigmoid function).
- 출력값을 0 과 1 사이의 확률로 변환:
- :
- 원본 특징 와 교차 변환(cross-product transformation) 를 결합 한 벡터.
- : 원본 입력 특징.
- : 원본 특징 의 교차 변환. 이는 두 개 이상의 특징 간의 상호작용을 포착함
- 예: "gender=female", "language=en" 교차 변환 "AND(gender=female, language=en)".
- 원본 특징 와 교차 변환(cross-product transformation) 를 결합 한 벡터.
- :
- Wide 컴포넌트의 가중치 벡터(weights).
- 와 내적(dot product)을 계산하여 Wide 컴포넌트의 출력을 생성.
- :
- Deep 컴포넌트의 최종 활성화값(final activations)에 적용되는 가중치.
- Deep 컴포넌트의 최종 출력 와 내적 계산.
- :
- Deep 컴포넌트의 마지막 은닉층(final hidden layer)의 활성화값.
- 이 값은 Deep 컴포넌트에서 학습된 비선형적 패턴을 나타냄.
- :
- 바이어스 항(bias term). 모델 출력값에 추가적으로 조정값을 더함.
4 SYSTEM IMPLEMENTATION
- 앱 추천 파이프라인은 데이터 생성(data generation), 모델 학습(model training), 모델 서빙(model serving)의 세 단계로 구성됨.
4.1 데이터 생성 단계 (Data Generation)
-
데이터 생성 방식:
- 일정 기간 동안의 사용자 데이터(user data)와 앱 데이터(app impression data)를 활용해 학습 데이터를 생성.
- 각 데이터 샘플(example)은 하나의 인상(impression)에 해당.
-
레이블(label):
- 1: 사용자가 해당 앱을 설치한 경우.
- 0: 그렇지 않은 경우.
-
범주형 특징(categorical features) 처리:
- 범주형 문자열을 정수 ID(integer ID)로 매핑하는 어휘 테이블(vocabularies) 생성.
- 시스템은 최소 발생 횟수를 초과한 문자열 특징들에 대해 ID 공간을 계산.
- 예:
"language=en" → ID: 1,"language=es" → ID: 2.
- 예:
-
연속형 특징(continuous real-valued features) 처리:
-
실수 값 특징을 범위로 정규화(normalize).
-
특정 값 를 해당 누적 분포 함수(cumulative distribution function, CDF) 로 변환.
-
데이터를 개의 분위(quantiles)로 나눔.
-
-번째 분위에 속한 값의 정규화 결과는:
- 예: 일 경우, 값이 3번째 분위에 속하면 결과는 .
-
-
-
분위 경계(Quantile Boundaries):
- 각 분위의 경계값도 함께 계산되어 데이터를 분할하는 데 사용.
4.2 Model Training
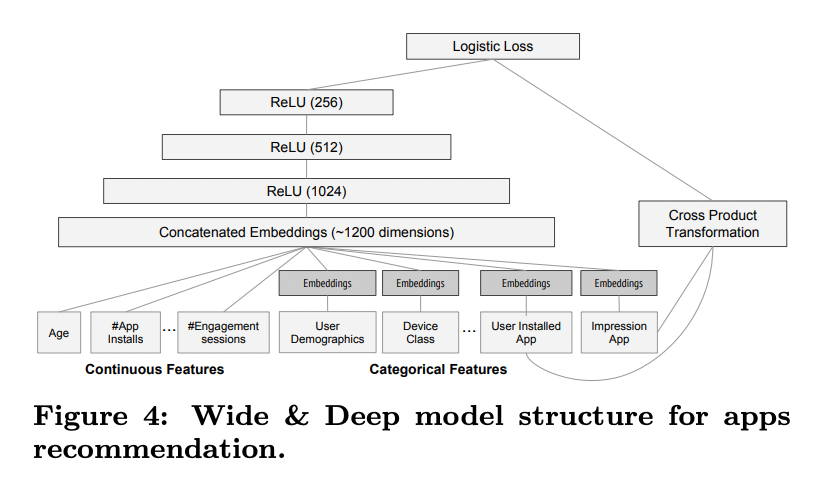
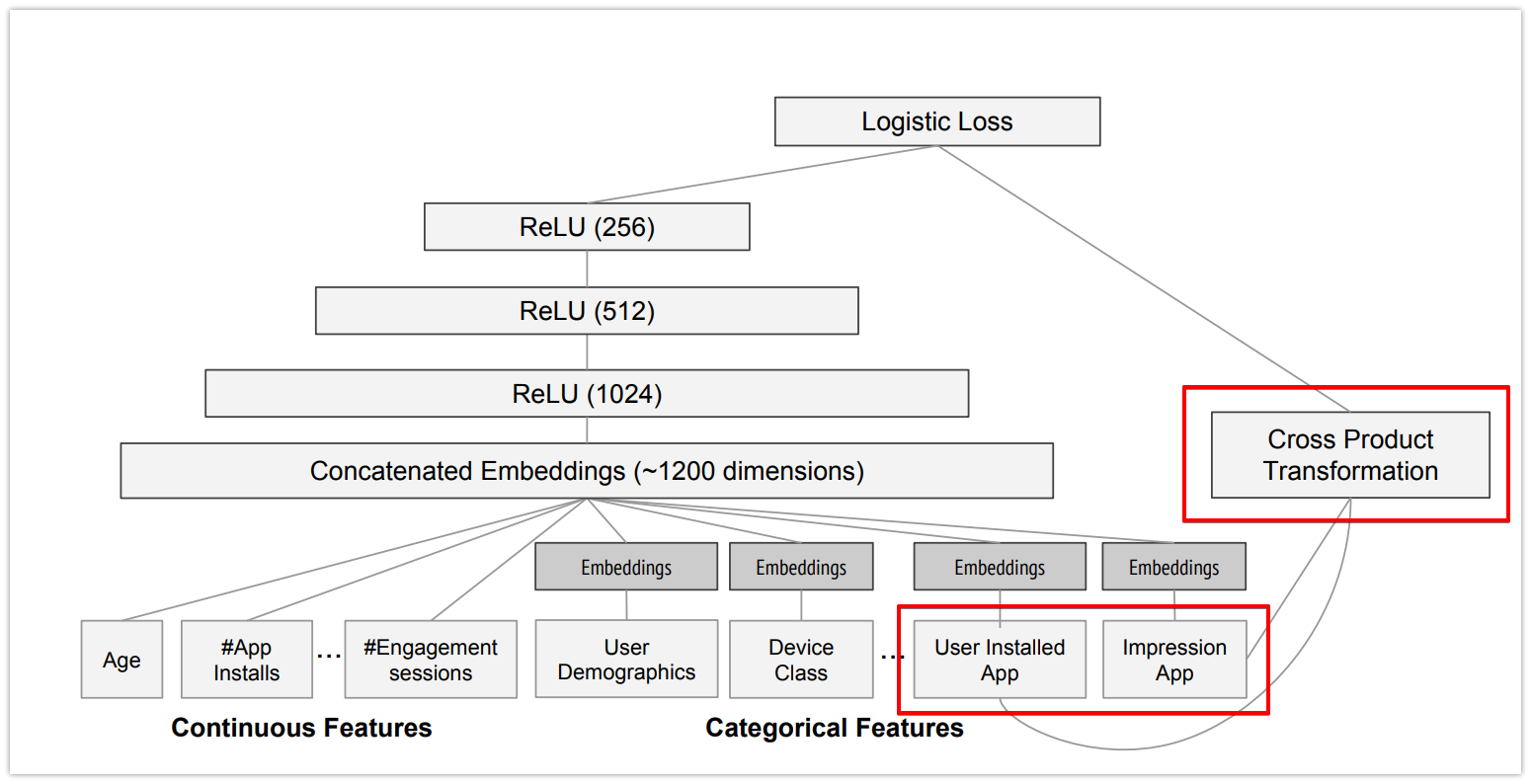
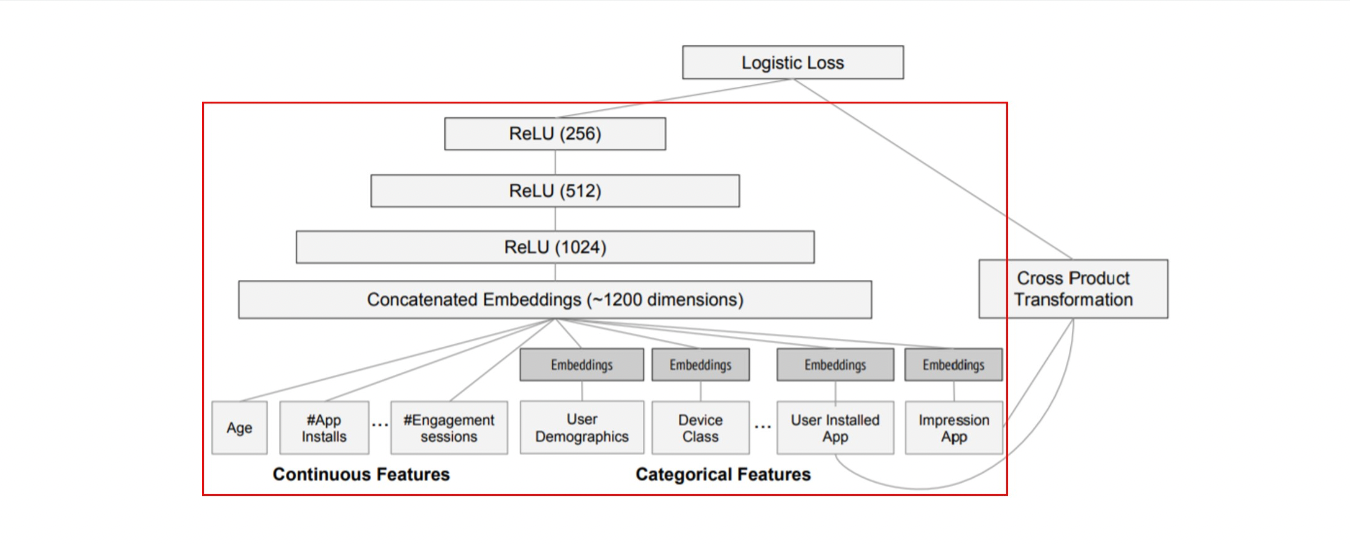
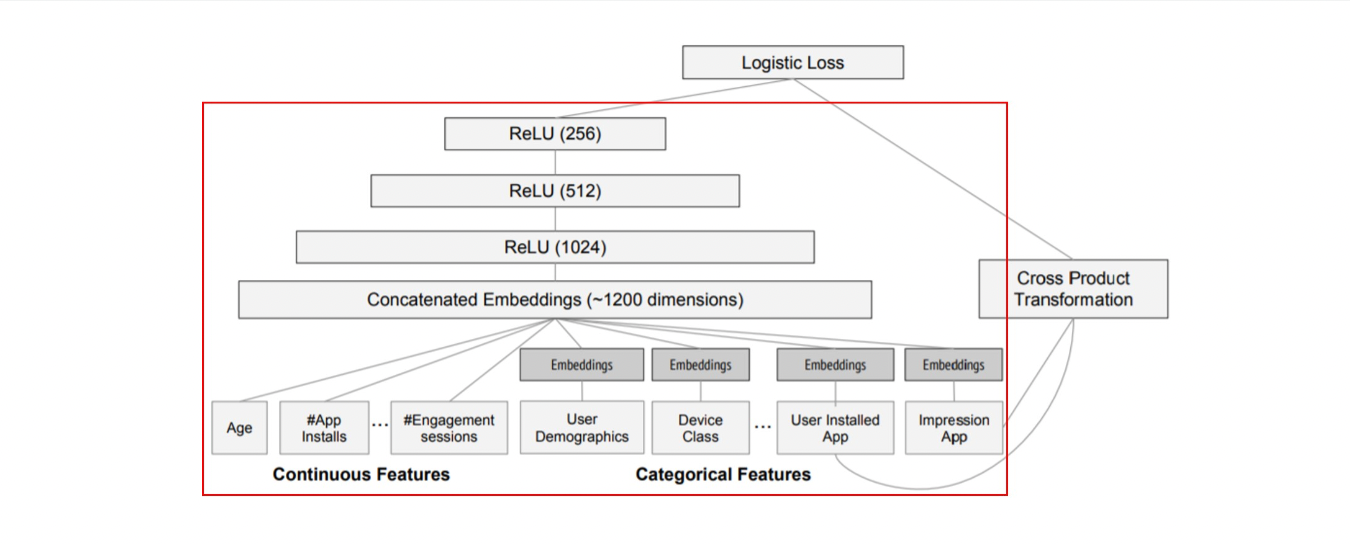
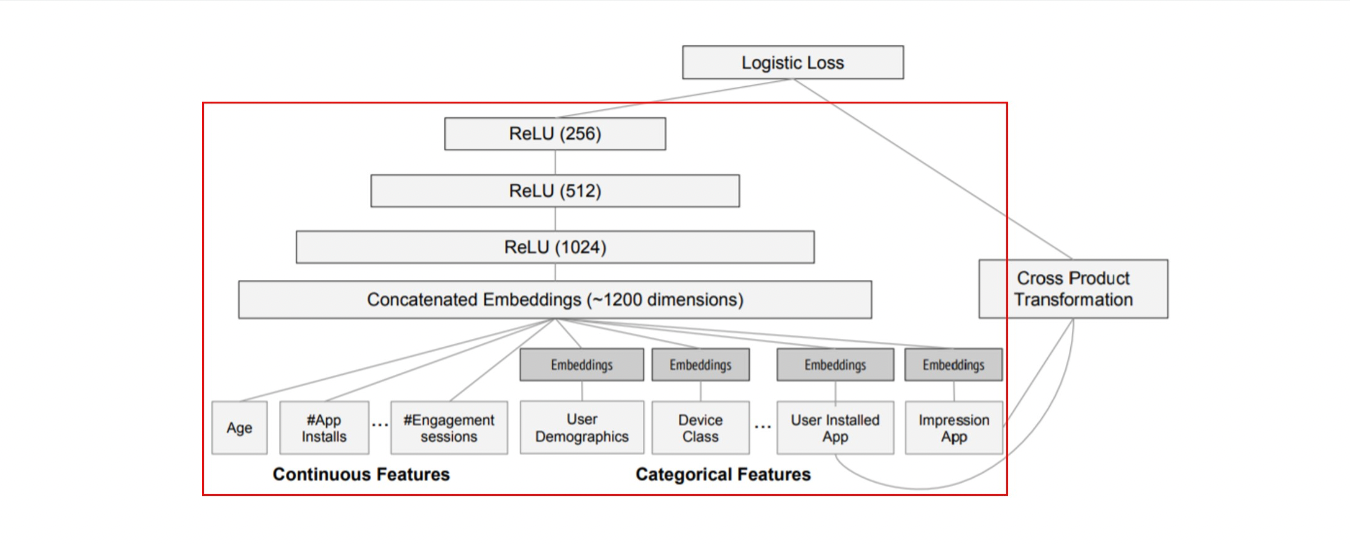
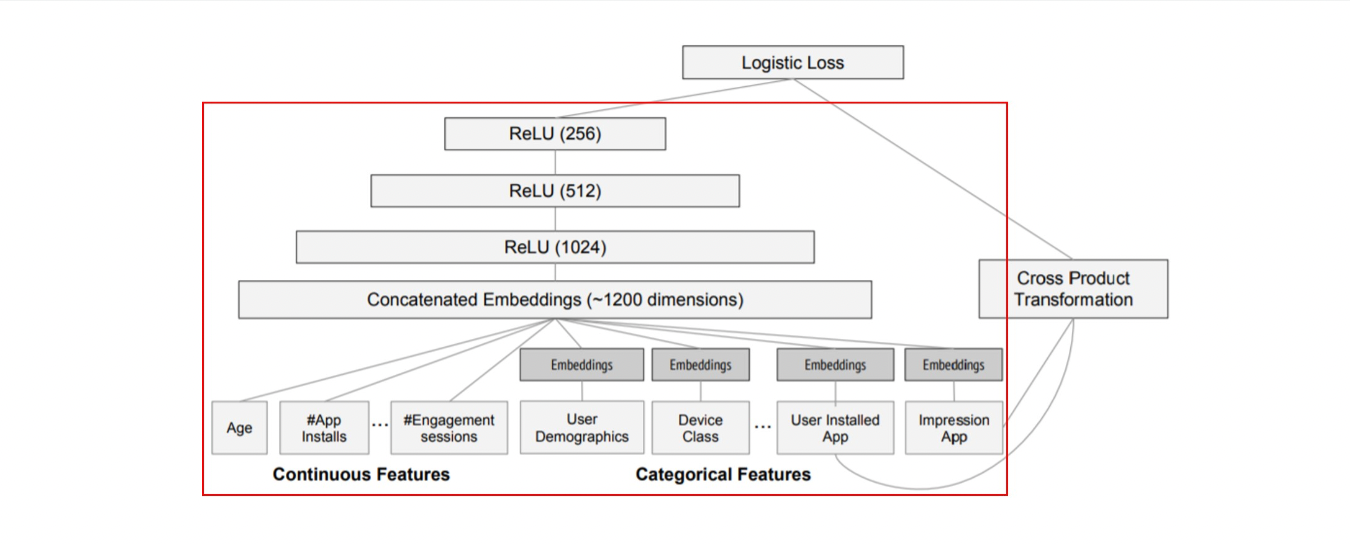
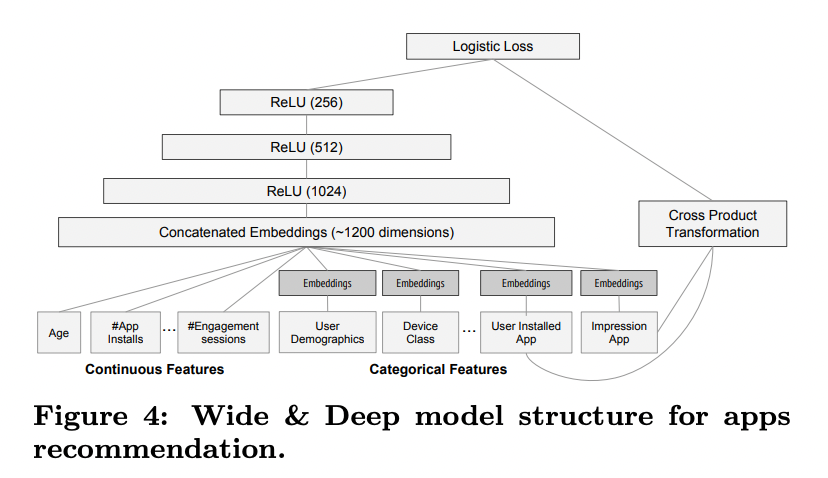
실험에서 사용된 모델 구조는 그림 4에 나타남. 학습 시, 입력층(input layer)은 학습 데이터와 어휘 테이블(vocabularies)을 받아 희소(sparse) 특징과 밀집(dense) 특징을 함께 생성하고 레이블(label)을 생성.
- Wide 컴포넌트:
- 사용자가 설치한 앱(user installed apps)과 인상 앱(impression apps)의 교차 변환(cross-product transformation)으로 구성.
- Deep 컴포넌트:
- 각 범주형 특징(categorical feature)에 대해 32차원의 임베딩 벡터(embedding vector) 학습.
- 모든 임베딩 벡터와 밀집 특징(dense features)을 결합(concatenate)하여 약 1200차원의 밀집 벡터 생성.
- 결합된 벡터는 3개의 ReLU 층을 거친 뒤 최종적으로 로지스틱 출력 유닛(logistic output unit)에 전달
학습 데이터
- Wide & Deep 모델은 5000억 개 이상의 데이터 샘플로 학습됨.
- 새로운 학습 데이터가 도착할 때마다 모델을 재학습(retrain)해야 함.
- 그러나 매번 모델을 처음부터 학습하면 계산 비용이 매우 크고, 데이터 도착 후 최신 모델을 서비스에 적용하는 데 지연이 발생하므로 아래 Warm Starting 시스템을 적용함.
Warm-Starting 시스템
- 새로운 모델 학습 시, 이전 모델의 임베딩(embeddings)과 선형 모델 가중치(linear model weights)를 초기값으로 사용해 학습 시작.
- 이를 통해 학습 시간을 줄이고, 모델 업데이트를 더 빠르게 서비스 가능.
모델 배포 전 검증 작업
- 모델 서버에 모델을 로드하기 전에 시험 실행(dry run)을 수행:
- 실시간 트래픽(live traffic) 처리에 문제가 없는지 확인.
- 이전 모델과 새로운 모델을 비교하여 모델 품질(empirical validation) 검증:
- 새로운 모델이 정상적으로 작동하는지 확인하는 일관성 검사(sanity check) 수행.
4.3 Model Serving
- 모델 배포:
- 모델 학습과 검증이 완료되면, 이를 모델 서버(model servers)에 로드.
- 모델 서버는 앱 추천 요청(request)을 처리하는 역할을 수행.
- 요청 처리 과정:
- 앱 검색 시스템(App Retrieval System)에서 앱 후보군(app candidates)과 사용자 특징(user features)을 서버로 전달.
- Wide & Deep 모델을 사용해 각 앱의 점수(score) 계산:
- 계산은 모델의 Forward Inference Pass(전방 추론 단계)를 통해 수행.
- 계산된 점수를 기반으로 앱을 내림차순 정렬하여 사용자에게 순서대로 보여줌.
- 성능 최적화:
- 각 요청에 대해 10ms 수준으로 응답 시간을 맞추기 위해 성능 최적화 수행.
- 멀티스레딩 병렬 처리(multithreading parallelism)를 활용:
- 앱 후보군 전체를 한 번에 처리하지 않고, 작은 배치(small batches)로 나눠 병렬로 처리.
- 이를 통해 모델 추론의 응답 속도 향상.
5 EXPERIMENT RESULTS
Wide & Deep 학습의 효과를 실제 추천 시스템에서 평가하기 위해 실시간 실험(live experiments)을 실행. 이 시스템은 다음 두 가지 측면에서 평가됨:
- 앱 설치율 (App Acquisitions):
- Wide & Deep 모델이 사용자의 앱 설치 행동에 미치는 영향을 평가.
- 추천된 앱이 얼마나 자주 설치되는지 확인하여 모델의 성능 측정.
- 서빙 성능 (Serving Performance):
- 모델이 실시간으로 요청을 처리하는 속도와 효율성 평가.
- 실시간 추천 시스템에서 성능이 요구사항(예: 10ms 이내 응답)을 충족하는지 확인.
5.1 실험 결과 - A/B 테스트
- 실험 설정:
- 기간: 3주 동안 실시간 A/B 테스트 진행.
- 대조군(Control Group):
- 사용자 1%를 무작위로 선택.
- 이전 버전의 랭킹 모델(Highly-optimized wide-only logistic regression model)을 사용해 추천 제공.
- 이 모델은 풍부한 교차 변환(cross-product feature transformations)을 활용한 로지스틱 회귀 기반.
- 실험군(Experiment Group):
- 또 다른 사용자 1%에게 Wide & Deep 모델을 사용해 추천 제공.
- 동일한 특징(feature) 세트를 사용해 학습된 모델.
- 결과:
- Wide & Deep 모델은 앱 스토어 메인 페이지에서 앱 설치율을 대조군 대비 +3.9% 상승(통계적으로 유의미).
- 또한, 동일한 특징과 신경망 구조를 사용한 Deep-only 모델과도 비교:
- Wide & Deep 모델은 Deep-only 모델 대비 +1% 추가 상승(통계적으로 유의미).
5.2 Serving Performance

- 상황:
- 상용 모바일 앱 스토어에서 발생하는 높은 수준의 트래픽으로 인해 고처리량(high throughput)과 낮은 지연(low latency)을 유지하며 서비스를 제공하는 것이 도전 과제.
- 최대 트래픽(peak traffic) 시, 추천 서버는 초당 1000만 개 이상의 앱에 대한 점수를 계산.
- 싱글 스레드(single threading):
- 모든 후보 앱을 단일 배치(single batch)로 점수화하는 데 31ms 소요.
- 멀티스레드(multithreading):
- 배치를 더 작은 크기(small batches)로 분할하여 병렬 처리.
- 이 구현으로 클라이언트 측 지연(client-side latency)을 크게 줄임.
- 결과: 서빙 오버헤드(serving overhead)를 포함해 지연 시간이 14ms로 감소
6 Conclusion
- 메모리제이션(Memorization)과 일반화(Generalization)는 추천 시스템에서 모두 중요한 역할을 함.
- Wide 선형 모델:
- 교차 변환(cross-product feature transformations)을 통해 희소한 특징 간의 상호작용을 효과적으로 기억.
- Deep 신경망:
- 저차원 임베딩(low-dimensional embeddings)을 활용하여 이전에 본 적 없는 특징 상호작용을 일반화.
- Wide 선형 모델:
- 본 논문에서는 두 모델의 장점을 결합한 Wide & Deep 학습 프레임워크를 제안.
- Wide 모델의 메모리제이션 능력과 Deep 모델의 일반화 능력을 통합.
- 이 프레임워크를 Google Play, 대규모 상용 앱 스토어의 추천 시스템에 적용하고 평가.
- Wide-only 모델과 Deep-only 모델 대비 앱 설치율(App acquisitions)에서 유의미한 향상을 보임.
