서론
리팩토링을 하며 사용자가 많아질때 서버에 부담을 줄일 방법에 대해 생각해보았다.
- TPS 개선(캐시, 쿼리튜닝)
- 서버 증설
- DB 커넥션 시간 줄이기
3가지 정도 생각이 났는데, 오늘은 DB 커넥션 타임을 줄여볼 생각이다.
현재 성능 개선이 필요할 정도로 많은 트래픽이 있거나, 트랜잭션 타임이 길지 않다.
DB 커넥션을 짧게 한만큼 어플리케이션에서 정제하면 걸리는 시간은 그대로 아닌가요?
트레이드오프가 있다. 하나의 쿼리로 한 번에 조회를 하는 경우 네트워크를 한 번만 타고 DB엔진이 제공하는 실행계획을 사용하는 장점이 있지만, 쿼리의 복잡성이 증가해 유연성과 가독성이 떨어지고, 무엇보다 DB커넥션 타임이 증가해 최악의 경우 다른 클라이언트가 사용하지 못하는 상황까지 생긴다.
DB 커넥션은 보통 일정 시간 동안 유지되는데, 이는 DB 서버에 부하를 일으키기도 한다. 또한, DB 서버가 많은 수의 동시 연결을 처리할 때는 성능에 영향을 미칠 수 있다.
이렇게 하면 DB 쿼리가 더 단순해지고, 결과 데이터가 더 작아지므로 DB 커넥션을 더 빠르게 반환할 수 있습니다. 이는 DB 서버의 부하를 줄이고 전체적인 성능을 향상시키는 데 도움을 줄 수 있다.
현재 db와 어플리케이션 서버 모두 한개씩 사용하고 있지만, 사용자가 많아지면 서버를 늘릴텐데 보통 db는 sharding, replication 하는 경우를 제외하곤 늘리지 않는다.
따라서 분산환경을 고려한다면 db 리소스 사용을 줄이는 것도 좋은 방법이다.
리팩토링
현 코드
public List<MyOrderResponse> findAllByMemberIdOrderByVisitDateAsc(
Long memberId,
OrderStatus option,
LocalDateTime cursorDate,
int pageSize) {
Map<Long, MyOrderResponse> distinctMyOrders = jpaQueryFactory
.select(
qOrder.id,
qOrder.title,
qOrder.orderStatus,
qOrder.region,
qOrder.visitDate,
qOrder.createdAt,
qOrder.cakeInfo,
qOrder.hopePrice,
qImage.imageUrl,
qOrder.offers
)
.from(qOrder)
.leftJoin(qImage)
.on(
qOrder.id.eq(qImage.referenceId),
qImage.imageType.eq(ORDER)
)
.where(
gtVisitDate(cursorDate),
eqOrderStatus(option),
qOrder.memberId.eq(memberId)
).orderBy(qOrder.visitDate.asc(), qImage.id.asc())
.limit(pageSize * MAX_PHOTOS_NUM_PER_ORDER)
.transform(
groupBy(qOrder.id)
.as(
Projections.constructor(
MyOrderResponse.class,
qOrder.id,
qOrder.title,
qOrder.orderStatus,
qOrder.region,
qOrder.visitDate,
qOrder.createdAt,
qOrder.cakeInfo,
qOrder.hopePrice,
qImage.imageUrl,
qOrder.offers.size()
)
)
);
if (distinctMyOrders.size() > pageSize) {
return new ArrayList<>(distinctMyOrders.values()).subList(0, pageSize);
}
return new ArrayList<>(distinctMyOrders.values());
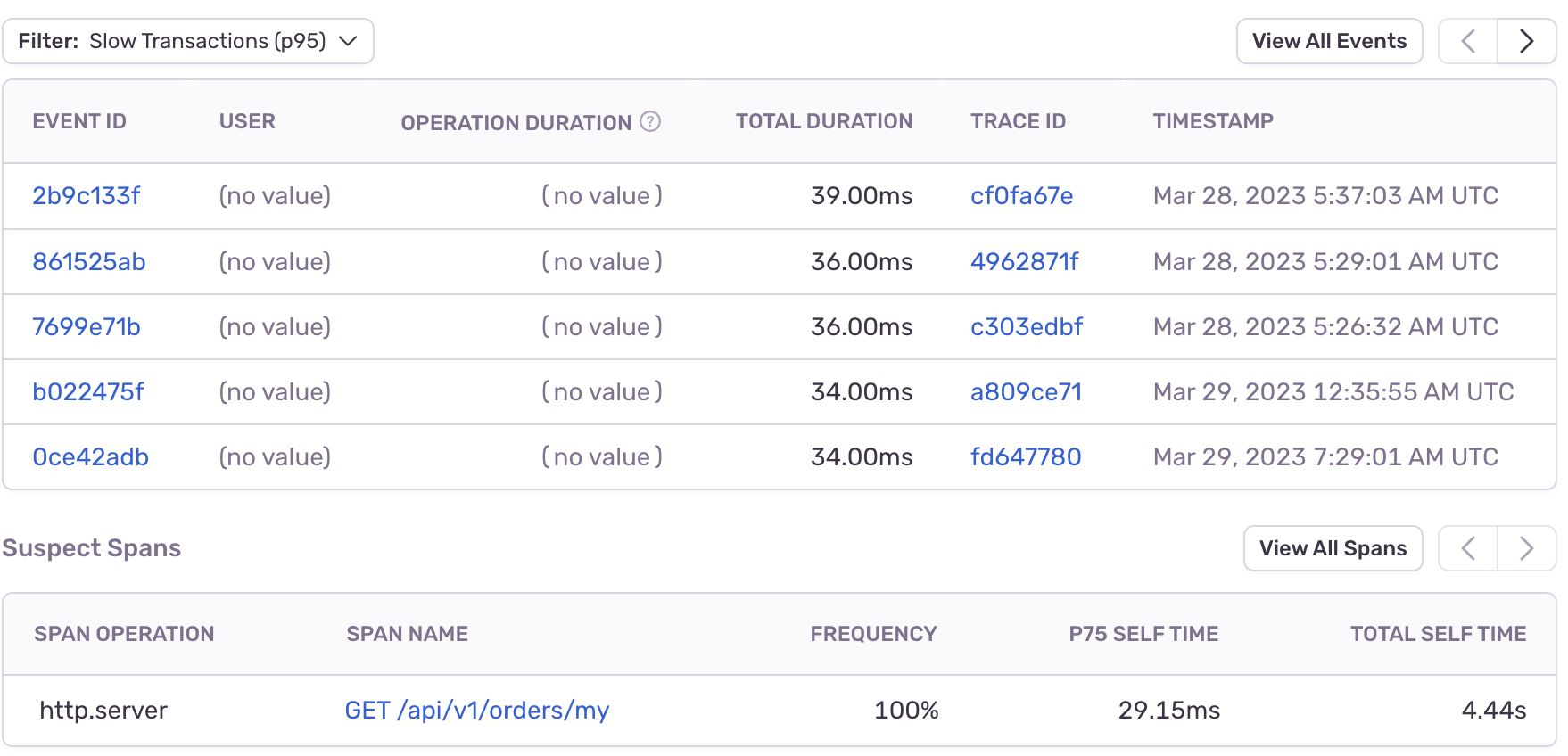
}커넥션 시간 측정
쿼리 전 후로 currentTimeMills() 를 빼주는 방식으로 측정했다.
평균 24.5 ms
코드 개선
어플리케이션에서 조합하도록 바꾼점은 세가지이다.
- Map으로 변경하는 부분
- 적절한 Image를 가져와 MyOrderResponse로 만드는 부분
- order by
public List<Order> findAllByMemberIdOrderByVisitDateAsc(
Long memberId,
OrderStatus option,
LocalDateTime cursorDate,
int pageSize) {
List<Order> myOrders = new java.util.ArrayList<>(jpaQueryFactory
.select(
qOrder
)
.from(qOrder)
.where(
gtVisitDate(cursorDate),
eqOrderStatus(option),
qOrder.memberId.eq(memberId)
).limit(pageSize)
.fetchAll()
.stream()
.toList());
myOrders.sort(Comparator.comparing(Order::getVisitDate));
return myOrders;
}쿼리가 굉장히 가벼워졌다.
myOrders.sort를 사용해 OrderBy가 없어도 visitDate 대로 정렬했다.
추가
db에서 order by로 정렬 후 limit로 개수 제한을 두는 것과 limit로 제한을 두고 order by 하는 것의 결과는 다른 결과값을 반환한다. 만약 limit이 없었다면 같은 결과를 가질 수 있는데, 옳지 않은 변경이었다.
Map으로 변경한 이유는 1:N 조인에서 첫 번째 값만 조인하기 위함이었는데, 이는 상위 레이어에서 값을 조합한다.
같은 의미로 MyOrderResponse를 레포지토리가 아닌 상위 레이어에서 만들도록 했다.
List<Order> myOrders = orderService.getMyOrders(getOrderRequest, memberId);
Long lastId = myOrders.isEmpty() ? 0L : myOrders.get(myOrders.size() - 1).getId();
return new MyOrdersResponse(
myOrders.stream()
.map(myOrder -> new MyOrderResponse(
myOrder.getId(),
myOrder.getTitle(),
myOrder.getOrderStatus(),
myOrder.getRegion(),
myOrder.getVisitDate(),
myOrder.getCreatedAt(),
myOrder.getCakeInfo(),
myOrder.getHopePrice(),
imageService.getImageUrl(myOrder.getId(), ORDER),
orderService.offerCount(myOrder.getId()))
).toList(),
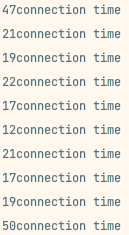
lastId);결과
평균 16.4 ms로 30% 이상의 시간이 줄었다. 물론 전체적인 시간과 네트워크 비용을 생각하면 무조건 좋은 것은 없다고 생각한다.
마무리
제일 처음에 쿼리 메서드를 작성했을때, 한번에 엔티티가 아닌 모든 값을 가져와 조합하고 리턴하려 했다. 그러다 보니 쿼리도 복잡해지고, 그에 따라 db 커넥션을 물고있는 시간도 늘어났다. 분산환경을 고려한다면 db 커넥션을 쪼개는 것도 좋은 방법이라 생각했고, 쿼리의 가독성이 훨씬 좋아졌다.
그리고 디스크보다 메모리에서 데이터를 정제하는게 속도적으로 유리하다. (서버에 부하가 될 수 있음)
