TIL
1.Redis 자료구조

레디스의 기본 자료구조는 key-value지만 여러가지 자료구조를 제공한다.기본 자료구조로 key와 value가 1대1 매핑되어있다.데이터를 순차적으로 저장하고 처리한다.쉽게 말해 자바의 Queue와 같으며, 데이터 중복이 가능하다.자바의 Set과 같으며 데이터 중복을
2.레디스의 분산락은 무엇인가!?
서론 오늘은 레디스는 무엇이고 왜 사용하는가를 다뤄보려고 한다. 특징 레디스는 몇가지 특징이 있는데 key-value 형식의 데이터 저장소이다. 단일 스레드 실행을 하기 때문에 Atomic 하다. 디스크가 아닌 인메모리에 저장한다. 레디스에 대한 기본적인 설명과 사
3.EC2 메모리 부족 해결(swap file)
EC2 프리티어를 사용중 CD/CD를 위해 deploy-agent와 docker를 사용하는데 메모리가 부족한 현상이 일어났다.swap file이란 메모리가 부족할 때 디스크 일부분을 메모리에서 사용하는 방법이다.더 많은 메모리를 사용할 수 있다는 장점이 있지만, 디스크
4.선착순 쿠폰 이벤트 개발기2 (feat.Redis)
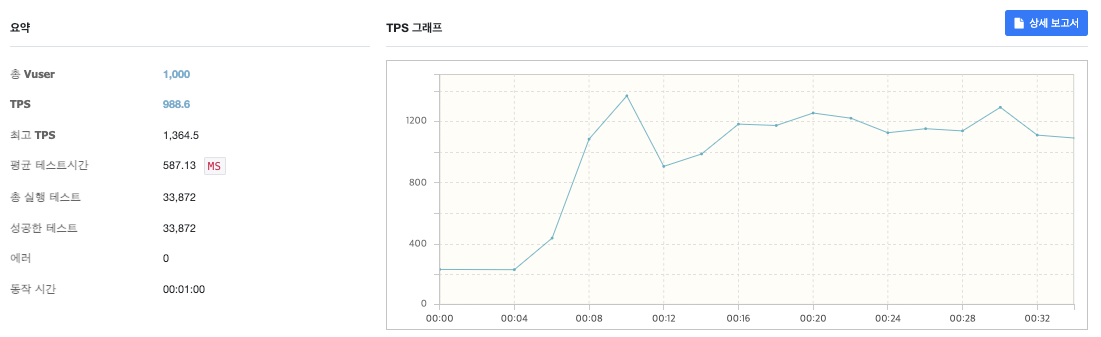
선착순 쿠폰 이벤트 개발기를 진행한 뒤 분산락에 대해서 알게 되어 스핀락보다 분산락이 더 효율적이라는 생각에 redis 클라이언트를 변경해보았다.implementation 'org.redisson:redisson-spring-boot-starter:3.16.8'lett
5.프로젝트 회고 - Shoe Kream
프로그래머스 백엔드 데브코스의 첫번째 팀 프로젝트가 끝난지 한 달이 지났다. 회고는 미리 작성했지만, 포스팅은 지금 한다.깃허브노션프로젝트의 주목적은 "스프린트 진행하기", "도전적인 기술 사용하기"이었다. 회의를 통해 각자 하고싶은 것, 도전하고 싶은 기술을 나열한
6.CI/CD 시간을 줄여보자(Github Actions)
새로운 pr을 생성하고, 머지할때 두근대는 마음으로 성공 여부를 기다린다.프로젝트 배포 자동화를 Git Actions을 이용하고 있는데, 5분 가까운 시간이 소요된다는건 오래걸린다 생각이 들어 ci/cd 스크립트를 수정해서 시간을 줄여보도록 한다.기존의 ci 방식을 살
7.DB 커넥션 시간을 줄여보자
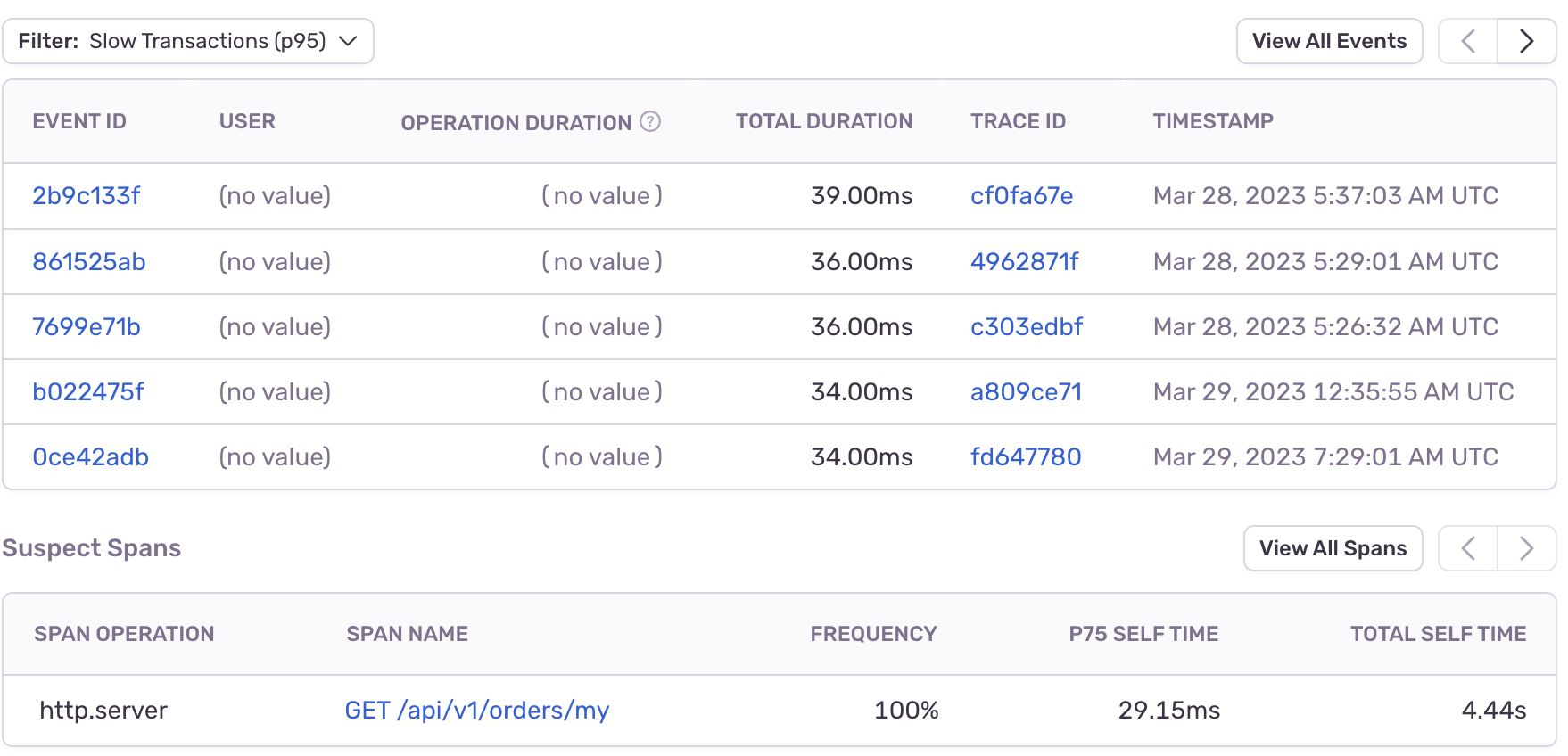
리팩토링을 하며 사용자가 많아질때 서버에 부담을 줄일 방법에 대해 생각해보았다.TPS 개선(캐시, 쿼리튜닝)서버 증설DB 커넥션 시간 줄이기3가지 정도 생각이 났는데, 오늘은 DB 커넥션 타임을 줄여볼 생각이다.현재 성능 개선이 필요할 정도로 많은 트래픽이 있거나, 트
8.Gradle life cycle
그래들은 종속성을 정의하고 순서대로 실행되도록 보장한다.빌드는 세 가지 단계로 진행된다.설정 파일을 감지한다. gradle파일을 찾고(멀티), 찾지 못하면(싱글) setting.gradle을 빌드한다.gradle 파일은 init, setting, build 세가지가 있
9.B-Tree, B+Tree
B-Tree와 B+Tree는 데이터베이스에서 사용되는 자료구조로, 대량의 데이터를 저장하고 탐색하는 데에 효율적이다.Balance Tree라는 뜻의 B-Tree는 Node들이 균형을 잡히도록 설계되었다. 검색,삽입,삭제 모두 O(log N)각 노드는 하나 이상의 자식
10.직렬화와 역직렬화

객체를 바이트 스트림으로 바꾸는 과정직렬화의 기준으로 포맷으로 Java 포맷, XML, JSON등이 있다.자바 포맷이 더 빠르지만, 가독성과, 플랫폼의 다향성때문에 사실상 JSON이 표준바이트 스트림 : 8비트의 연속된 데이터 흐름, 컴퓨터에서 데이터를 바이트 단위로
11.JVM 메모리 구조
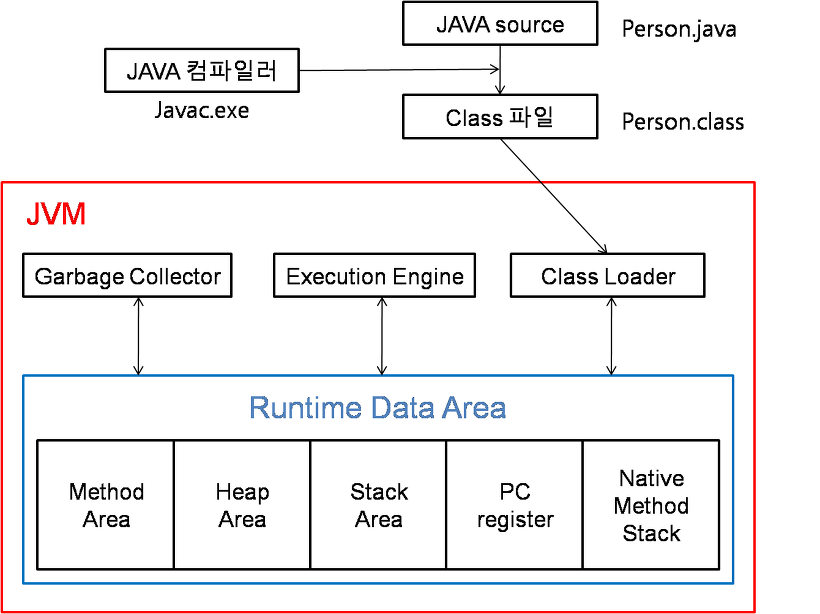
출처(https://steady-coding.tistory.com/305)JVM의 구조는 사진과 같이 이루어져 있으며, 그 중 데이터 영역은 5가지로 나누어져 있다.JVM(Java Virtual Machine)은 Java 애플리케이션을 실행하는 데 필요한 가상
12.스프링 프록시
객체 지향 디자인 패턴 중 하나로, 객체에 대한 접근을 제어하기 위해 중간에 대리자(proxy) 객체를 두는 것. 프록시는 실제 객체와 동일한 인터페이스를 구현하지만, 실제 객체에 대한 요청을 중간에 가로채서 필요한 작업을 수행하고, 그 결과를 반환한다. 이를 통해 실
13.헥사고날 아키텍처
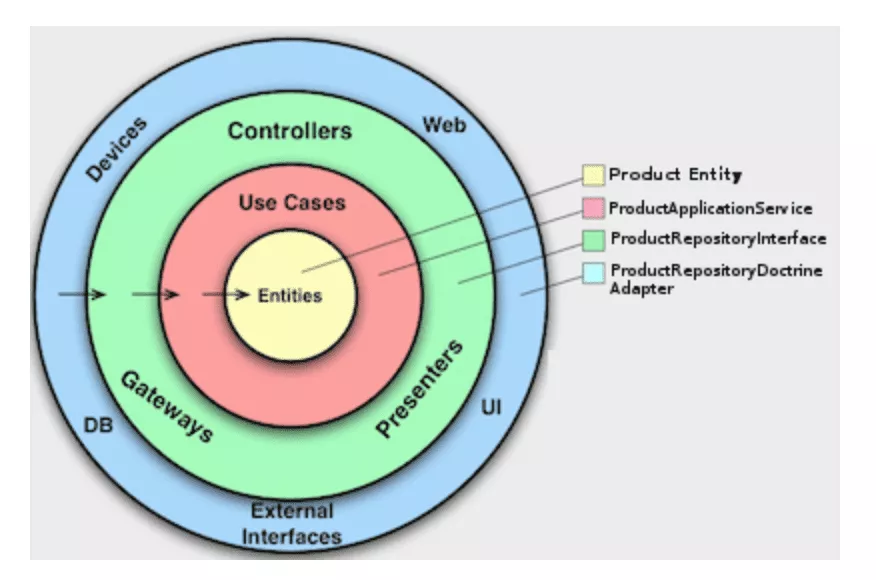
서론 반년 전 만들면서 배우는 클린 아키텍처 책을 읽으면서 헥사고날 아키텍처에 대해 접하게 되었다. 당시 도움을 주시던 멘토님은 굉장히 부작용이 크다고 도입했다가 후회하는 회사들이 많다고 하셨는데, 내 눈엔 굉장히 매력적으로 다가왔다. 똥은 찍어봐야 알기 때문에 사
14.도메인과 엔티티의 차이점
도메인과 엔티티의 차이점을 묻는다면 답변할 수 있는가? 나는 없었다. 같다고 생각한다고 틀린 답은 아니지만, 맞는 답도 아니니 차이점을 알아보자.애플리케이션의 비즈니스에 관련된 모든 개념 모델을 뜻한다. 유스케이스의 경우는 도메인의 동적 측면을 나타낸다면 도메인은 정적
15.간단한 쿼리가 굉장히 느린 현상
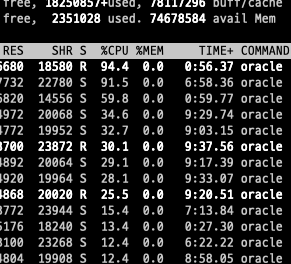
이렇게 간단한 쿼리가 10분이 지나도 완료되지 않는다.ORDERCD는 PK여서 원래 수십 ms면 끝나는 쿼리인데 말이다.DataGrip과 컴퓨터를 재시작해도 변함없었다.데드락인가 해서 찾아봐도 데드락이 감지되지 않았다.처음 의심한 것은 DB 서버가 많은 트래픽을 받아서
16.IT 엔지니어를 위한 네트워크 입문이 읽기 싫을때 - 1

이 글은 IT 엔지니어를 위한 네트워크 입문 스터디를 마치고 정리한 글이다.이전에 정리했던 RealMySQL 정리와는 조금 다르게 양이 너무 많아 설명을 모두 적으면, 책을 다시 읽는게 더 좋을 것 같아 키워드 위주로 정리했다.네트워크는 단말간 물리적인 연결이 필요하다
17.IT 엔지니어를 위한 네트워크 입문이 읽기 싫을때 - 2
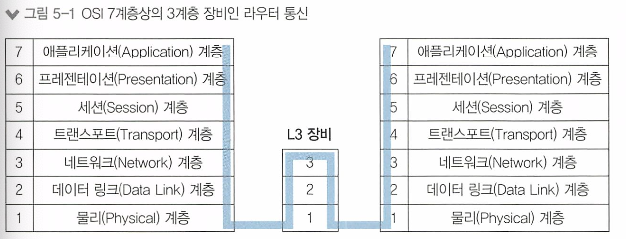
이 글은 IT 엔지니어를 위한 네트워크 입문 스터디를 마치고 정리한 글이다.라우터 : 3계층에서 동작하는 여러 네트워크 장비의 대표격으로 경로를 지정해주는 장비라우터에 들어오는 패킷의 목적지 IP 주소를 확인하고 자신이 가진 경로 정보를 이용해 최적의 경로로 포워딩 한