레디스의 기본 자료구조는 key-value지만 여러가지 자료구조를 제공한다.
자료형
Strings
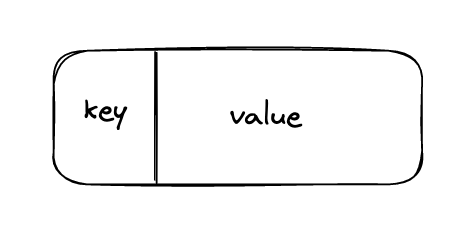
기본 자료구조로 key와 value가 1대1 매핑되어있다.
Lists
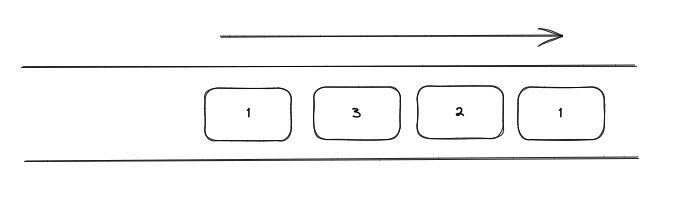
데이터를 순차적으로 저장하고 처리한다.
쉽게 말해 자바의 Queue와 같으며, 데이터 중복이 가능하다.
Sets
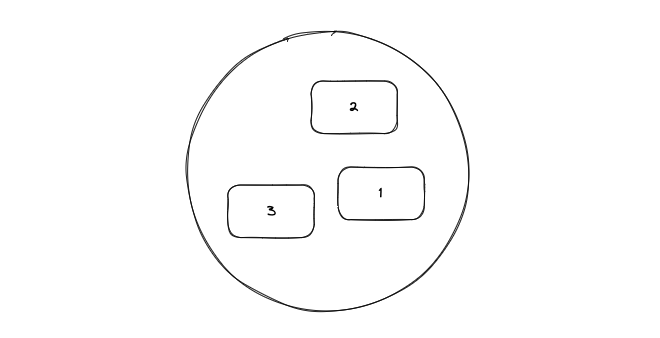
자바의 Set과 같으며 데이터 중복을 허용하지 않는다.
Sorted Sets
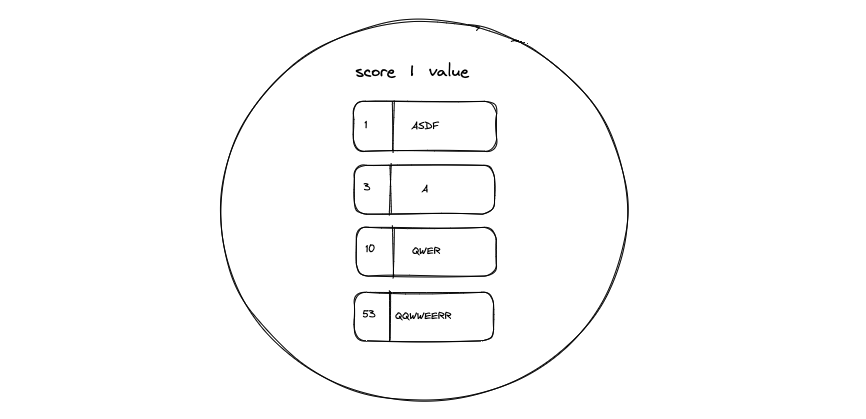
Sets과 비슷하지만, score로 정렬한다.
Hashes
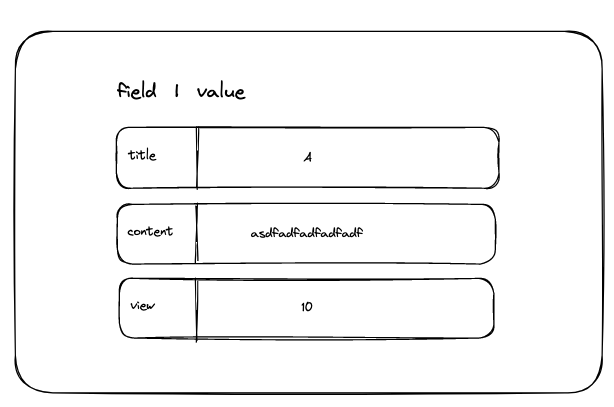
value를 구분할 수 있는 field가 주어진다. RDB의 테이블과 비슷하다고 이해하면 좋다.
Streams
로그 데이터를 처리하기 위해 생긴 자료구조로 데이터 추가는 가능하나, 수정이 불가능하다.
추가로 다른 자료구조보다 시간복잡도에서 우월한 성능을 가지고 있으며, 다른 자료구조와 다르게
id, 데이터 영속화, 오래된 데이터 삭제 등 여러가지 기능을 제공하고 있어 kafka와 같이 메세지 브로커로 사용할 수 있다.
내부 구조
SKIP List
SKIP List는 Sorted Set 자료형의 두가지 내부구조중 하나다.
Sorted Set에 멤버의 수가 128개를 초과하거나 Value의 크기가 64Byte를 초과하면 SKIP List로 마이그레이션 한다. 물론 redis.conf 에서 수치를 조정할 수 있다.

Sorted Set에서 linked list를 사용하게 되면 n번째 score를 가지는 노드를 찾기위해 n번의 O(n)연산을 해야한다.
레디스는 싱글 스레드 연산을 하기 때문에 한가지 요청이 오래걸리면 병목이 일어나기 때문에 실행시간을 최대한 줄여야 한다.
레디스의 전체적인 성능일 높이려면 비교시간을 줄여야 한다.
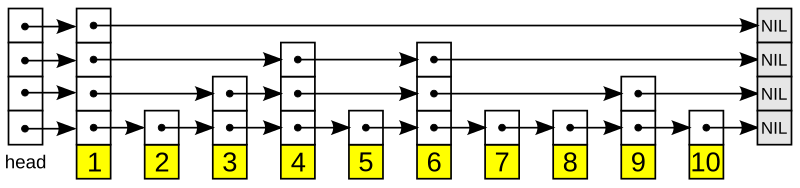
linked list와 다르게 포인터의 수(level)를 늘려서 비교하는 횟수를 O(log n)으로 줄인다.
그렇다면 포인터 level은 어떻게 정해질까?
매번 1/4 확률로 level을 결정하고, 최대 32 level까지 간다.
Sorted Set은 level을 통해 비교하기 때문에 메모리가 가능한 무한히 저장할 수 있다
처음에 level 1 을 가지고, 1/4 확률로 2.. 또 1/4 확률로 3.. 로 계속 이어진다.
확률적으로 보면
level 1 = 1/4
level 2 = 1/4^2
level n = 1/4^n
으로 노드당 평균 포인터는 골고루 분포된다.
참고
https://en.wikipedia.org
http://redisgate.kr/redisgate/ent/ent_intro.php
