GPT1&GPT2
GPT1

자연어에는 label이 지정되어있지 않은 Unlabeled data가 많다.
Unlabeled data를 활용하기 어려운 이유는 어떤 Optimization objective가 효과적인지 알 수 없고 모델에서 학습된 표현을 다양한 NLP task로 전환하는데 효율적인 방법이 정해지지 않았다.
GPT1은 Unsupervised pre-training과 supervised fine-tunning을 결합한 semi-supervised를 제안한다.
- 신경망 초기의 parameter를 pre-trained 하기 위해 unlabeled data에 language modeling objective를 사용
- 위에서 얻은 parameter를 supervised objective를 사용하여 fine-tunning한 후 특정 task에 적용
GPT1 구조
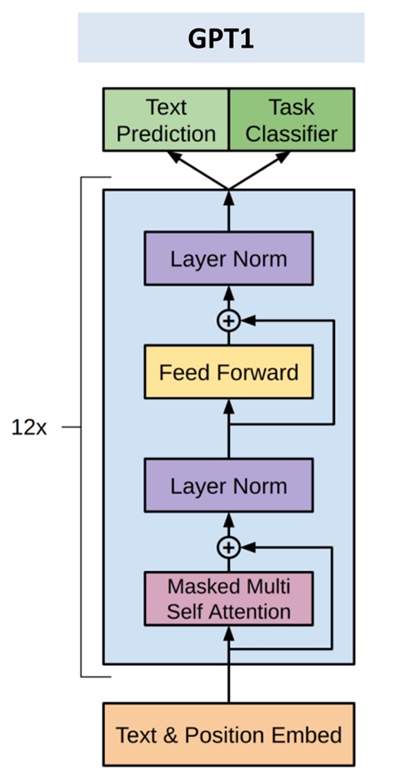
Unsupervised pre-training, Supervised fine-tunning
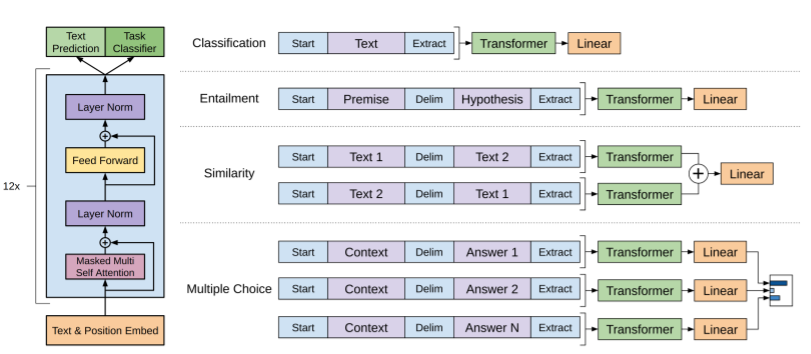
NLP task들을 처리하기 위해 여러개의 문장이 필요한 경우 각 문장을 구분하여 하나로 연결하는 방식을 사용한다.
GPT2

대규모의 dataset과 large model, supervised learning은 학습한 작업에서 좋은 성능을 내지만 민감하고 망가지기 쉽다.
training dataset을 생성하고 label할 필요가 없는 일반적인 시스템을 제안한다.
GPT2 구조
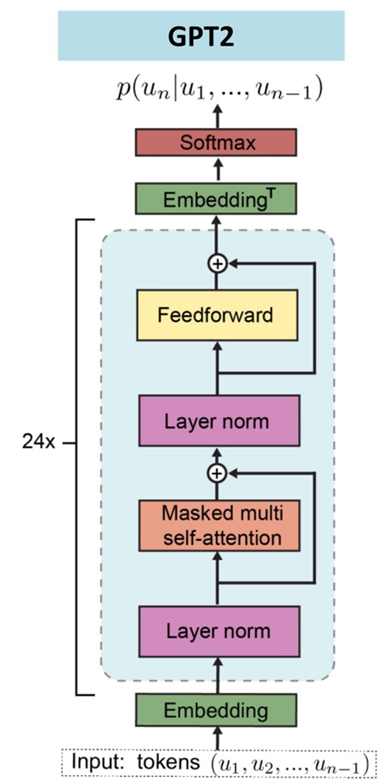
GPT1에서 이후에 실행하던 Layer Norm을 input part로 옮겨졌다.
마지막 self-attention block 이후 추가적인 layer normalization이 존재한다. residual layer의 누적에 따른 initialization의 변화로 residual layer의 깊이 N에 따라 1/√N * weights 를 사용하여 residual layer의 가중치를 설정한다.
- Position of Layer Normalization
- Additional Layer Normalization
- Initialization method
reference
https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
수업자료(이론)
