Transformer -Encoder 구현
이전 Transformer의 이론 및 구성요소와 이어집니다.
https://velog.io/@gpdus41/Transformer-%EC%9D%B4%EB%A1%A0-%EB%B0%8F-%EA%B5%AC%EC%84%B1Attention-is-all-you-need
Encoder
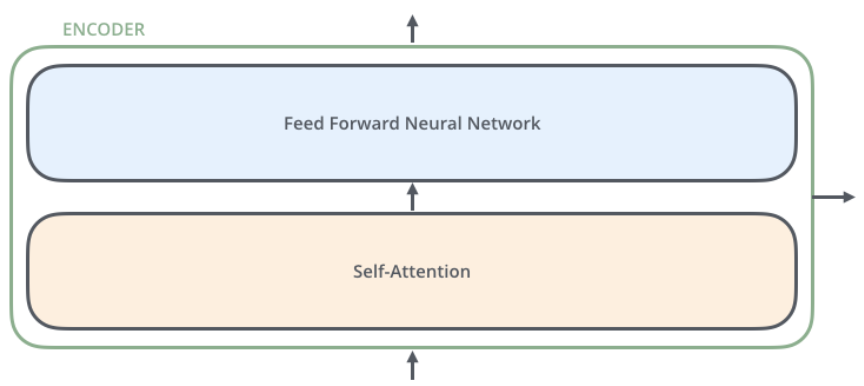

encoder는 Self-Attention과 Feed Forward로 구성되어 있다.
encoder 안에는 multi-head attention과 feed forward가 있고 add&norm을 활용하고 있다.
FeedForward 구현
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.linear = nn.Linear(config.hidden_size, config.intermediate_size) # 768 -> 3072
self.conv1 = nn.Conv1d(config.hidden_size,config.intermediate_size,1)
self.conv2 = nn.Conv2d(config.intermediate_size,config.hidden_size,1)
self.activate = nn.functional.gelu
self.dropout = nn.Dropout(0.1)
def forward(self, hidden_states):
# hidden_states = [batch size, seq len, hid dim]
# linear -> gelu
output = self.linear(hidden_states)
output = self.activate(output)
output = self.dropout(output)
return outputfeedforward 선형 결합과 gelu 함수를 활성화 함수로 적용한다.
EncoderLayer 구현
class EncoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.self_attention = MultiHeadAttention(config)
self.feedforward = FeedForward(config)
self.linear_1 = nn.Linear(config.hidden_size, config.hidden_size)
self.linear_2= nn.Linear(config.intermediate_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states, attention_mask=None):
# hidden_states = [batch_size, seq_len, hidden_size]
# 1. multi-head attention
attention_output = self.self_attention(hidden_states, attention_mask)
# 2. add & norm : linear -> dropout -> residual connection and layer norm
attention_output = self.linear_1(attention_output)
attention_output = self.dropout(attention_output)
attention_output = self.layer_norm(hidden_states + attention_output)
# 3. feedforward
feedforward_output = self.feedforward(attention_output)
# 4. add & norm
feedforward_output = self.linear_2(feedforward_output)
feedforward_output = self.dropout(feedforward_output)
feedforward_output = self.layer_norm(feedforward_output + attention_output)
return feedforward_outputEncoder의 layer를 쌓는 과정이다.
multi-head attention - add&norm - feedforward - add&norm 순으로 layer를 쌓는다.
Encoder 전체
import torch
from torch import nn
from transformers.activations import gelu
import math
"""
BERT base config
hidden_size = 768
num_attention_heads = 12
num_hidden_layers = 12
hidden_dropout_prob = 0.1
hidden_act = gelu
"""
class MultiHeadAttention(nn.Module):
def __init__(self, config):
super().__init__()
assert config.hidden_size % config.num_attention_heads == 0
self.hidden_size = config.hidden_size # 768
self.num_attention_heads = config.num_attention_heads # 12
self.head_dim = config.hidden_size // config.num_attention_heads
self.query = nn.Linear(self.hidden_size, self.hidden_size)
self.key = nn.Linear(self.hidden_size, self.hidden_size)
self.value = nn.Linear(self.hidden_size, self.hidden_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def forward(self, hidden_states, attention_mask=None):
print('Hidden States: ', hidden_states.shape) # ADDED
Q = self.query(hidden_states)
K = self.key(hidden_states)
V = self.value(hidden_states)
print('Q.size',Q.size())
print('K.size',K.size())
print('V.size',V.size())
batch_size = hidden_states.shape[0]
Q = Q.view(batch_size, -1, self.num_attention_heads, self.head_dim).permute(0,2,1,3)
K = K.view(batch_size, -1, self.num_attention_heads, self.head_dim).permute(0,2,1,3)
V = V.view(batch_size, -1, self.num_attention_heads, self.head_dim).permute(0,2,1,3)
print('Q.size',Q.size())
print('K.size',K.size())
print('V.size',V.size())
d_k = self.head_dim # d_k
print('dk',d_k)
print('transpose k', K.transpose(-2,-1).size())
attention_score = torch.matmul(Q, K.transpose(-1,-2)) # Q x K^T
attention_score = attention_score / math.sqrt(d_k)
print('attention score: ', attention_score.size())
if attention_mask is not None:
attention_score = attention_score + attention_mask
attention = nn.functional.softmax(attention_score, dim=-1)
print('softmax attention score: ', attention.size())
attention = self.dropout(attention)
output = torch.matmul(attention,V)
print('score*v',output.size())
output = output.permute(0, 2, 1, 3)
print('permute output',output.size())
output = output.reshape(2,9,768)
print('reshape output: ', output.size())
return output
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.linear = nn.Linear(config.hidden_size, config.intermediate_size) # 768 -> 3072
self.conv1 = nn.Conv1d(config.hidden_size,config.intermediate_size,1)
self.conv2 = nn.Conv2d(config.intermediate_size,config.hidden_size,1)
self.activate = nn.functional.gelu
self.dropout = nn.Dropout(0.1)
def forward(self, hidden_states):
# hidden_states = [batch size, seq len, hid dim]
# linear -> gelu
### Custom Code 작성 ###
print('hidden_states(input)',hidden_states.size())
#output = self.conv1(hidden_states.transpose(1,2))
output = self.linear(hidden_states)
print('linear output',output.size())
output = self.activate(output)
print('activate output',output.size())
#output = self.conv2(output).transpse(1,2)
output = self.dropout(output)
print('dropout output',output.size())
return output
class EncoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.self_attention = MultiHeadAttention(config)
self.feedforward = FeedForward(config)
self.linear_1 = nn.Linear(config.hidden_size, config.hidden_size)
self.linear_2= nn.Linear(config.intermediate_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states, attention_mask=None):
# hidden_states = [batch_size, seq_len, hidden_size]
# 1. multi-head attention
attention_output = self.self_attention(hidden_states, attention_mask)
# 2. add & norm : linear -> dropout -> residual connection and layer norm
### Custom Code 작성 ###
attention_output = self.linear_1(attention_output)
attention_output = self.dropout(attention_output)
attention_output = self.layer_norm(hidden_states + attention_output)
print('attention_output',attention_output.size())
# 3. feedforward
feedforward_output = self.feedforward(attention_output)
# 4. add & norm
### Custom Code 작성 ###
feedforward_output = self.linear_2(feedforward_output)
feedforward_output = self.dropout(feedforward_output)
feedforward_output = self.layer_norm(feedforward_output + attention_output)
print('feedforward_output',feedforward_output.size())
return feedforward_output
class Encoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.layer = nn.ModuleList([EncoderLayer(config) for _ in range(config.num_hidden_layers)]) # layer 만큼 반복하여 생성
def forward(self, hidden_states, attention_mask=None):
for layer in self.layer:
hidden_states = layer(hidden_states, attention_mask)
return hidden_states
구현코드 github link
https://github.com/KimHyeYeon41/AISoftware/blob/main/%5BAI_06%5DTransformer_Encoder.ipynb
reference
https://arxiv.org/pdf/1706.03762.pdf
http://jalammar.github.io/illustrated-transformer/
