Transformer
Transformer는 2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델로 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현한 모델이다.
RNN 계열의 모델은 sequential하게 학습하는 구조로 hidden state를 순차적으로 넘기는 방식으로 인해 병렬처리가 불가능했으며 문장의 길이가 길어짐에 따라 attention 계산량이 많아졌다.
이러한 문제점을 해결하기 위해서 RNN을 사용하지 않고 encoder-decoder 구조로 설계하여 기존 순차적인 연산에서 벗어나 병렬처리를 가능하게 했으며 우수한 성능을 보인다는 특징이 있다.

Transformer Architecture
Transformer의 Architecture는 다음과 같다.
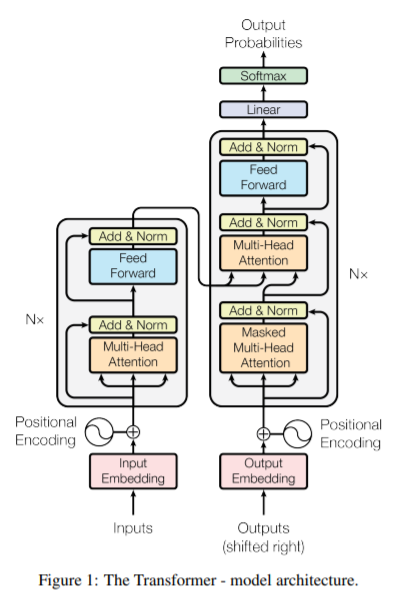
왼쪽은 encoder, 오른쪽은 decoder에 해당된다.
encoder-decoder 구조로 동일한 encoder layer와 decoder layer가 반복되어 쌓인 형태이다.
Encoder
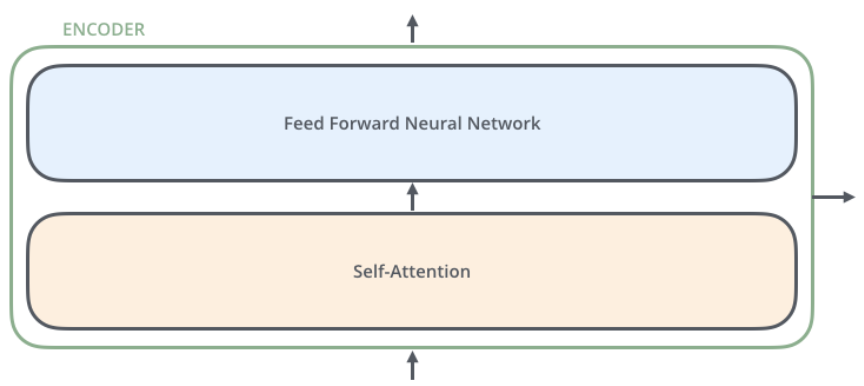

encoder는 Self-Attention과 Feed Forward로 구성되어 있다.
encoder 안에는 multi-head attention과 feed forward가 있고 add&norm을 활용하고 있다.
Attention
Attention은 Query, Key, Value의 개념이 사용되어 decoder의 매 시점에서 hidden state와 모든 encoder 간의 유사도를 score 계산을 기반으로 진행되었다.
Transformer에서는 self-attention 개념을 적용하여 특정 feature가 같은 context 내에서 어떤 features를 참조하고 있는지 attention 계산을 통해 입력 문장의 단어들 간 유사도를 얻는다.
Scaled Dot-Product Attention
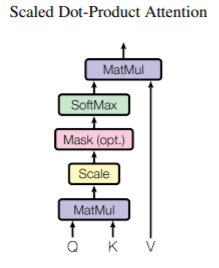
Scaled Dot-Product Attention의 구조는 위와 같다.
위 구조를 식으로 정리하면 다음과 같다.

input vector로부터 Query, Key, Value vector를 생성한다.
Query · Key (matrix product)하여 계산하여 특정 위치의 단어가 다른 단어와 얼마나 연관되어있는지 점수를 구한다.
Score를 Key vector 차원의 제곱근으로 나눈다.
Softmax 계산을 하고 Value vector에 softmax score를 곱하여 최종적으로 attention 결과를 만든다.
Multi-Head Attention

Multi-Head Attention의 구조는 위와 같다.
위 구조를 식으로 정리하면 다음과 같다.

Multi-Head Attention은 h개의 각각 다르게 초기화된 parameter matrix를 곱하여 h개의 attention 결과를 얻고 이를 concat하여 결과를 얻는다.
Multi-Head Attention 구현
class MultiHeadAttention(nn.Module):
def __init__(self, hid_dim, n_heads):
super().__init__()
assert hid_dim % n_heads == 0
self.hid_dim = hid_dim
self.n_heads = n_heads
self.head_dim = hid_dim // n_heads
self.query = nn.Linear(hid_dim, hid_dim)
self.key = nn.Linear(hid_dim, hid_dim)
self.value = nn.Linear(hid_dim, hid_dim)
self.dropout = nn.Dropout(0.1)
def forward(self, hidden_states, attention_mask=None):
print('Hidden States: ', hidden_states.shape) # ADDED
Q = self.query(hidden_states) #Q : [2,9,768]
K = self.key(hidden_states) #K : [2,9,768]
V = self.value(hidden_states) #V : [2,9,768]
batch_size = hidden_states.shape[0]
Q = Q.view(batch_size, -1, self.n_heads, self.head_dim).permute(0,2,1,3) #Q : [2,12,9,64]
K = K.view(batch_size, -1, self.n_heads, self.head_dim).permute(0,2,1,3) #K : [2,12,9,64]
V = V.view(batch_size, -1, self.n_heads, self.head_dim).permute(0,2,1,3) #V : [2,12,9,64]
d_k = self.head_dim # d_k : 64
#print('transpose k', K.transpose(-2,-1).size()) #transpose k: [2,12,64,9]
attention_score = torch.matmul(Q, K.transpose(-1,-2)) # Q x K^T
attention_score = attention_score / math.sqrt(d_k) #[2,12,9,9]
if attention_mask is not None:
attention_score = attention_score + attention_mask
attention = nn.functional.softmax(attention_score, dim=-1) #softmax attention score: [2,12,9,9]
attention = self.dropout(attention)
output = torch.matmul(attention,V) #score*v: [2,12,9,64]
output = output.permute(0, 2, 1, 3) #permute output: [2,9,12,64]
output = output.reshape(2,9,768) #reshape output: [2,9,768]
return output
input vector로부터 Query, Key, Value vector를 생성한다. [2,9,768] 차원의 Q, K, V를 [2,12,9,64]로 바꿔주기 위해 view(batch_size, -1, self.n_heads, self.head_dim)로 차원을 추가해주고 permute(0,2,1,3)로 바꿔준다.
Query · Key (matrix product)하여 계산하고 Score를 Key vector 차원의 제곱근으로 나눈다. attention_score: [2,12,9,9]
Softmax 계산을 하고 Value vector에 softmax score를 곱한다. softmax attention score: [2,12,9,9] score * V: [2,12,9,64][2,9,12,64]로 만들어주기 위해 permute(0, 2, 1, 3)를 해주고 [2,9,768]로 만들어주기 위해 reshape을 해준다.
Decoder
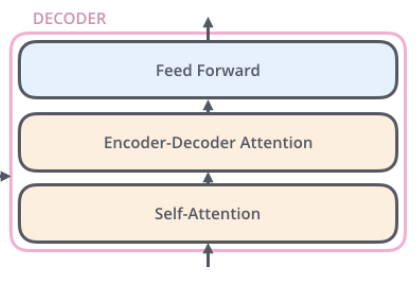

decoder는 self-attention, encoder-decoder attention, feedforward로 구성되어 있다. 으로 구성되어 있다.
decoder 안에는 Feed Forward, multi-head attention, masked multi-head attention가 있고 add&norm을 활용하고 있다.
구현코드 github
https://github.com/KimHyeYeon41/AISoftware/blob/main/%5BAI_05%5DMulti_Head_Attention.ipynb
Encoder와 Decoder의 구현은 다음 포스트에서 이어집니다.
https://velog.io/@gpdus41/Transformer-EncoderDecoder-%EA%B5%AC%ED%98%84
reference
https://arxiv.org/pdf/1706.03762.pdf
http://jalammar.github.io/illustrated-transformer/
