
Table
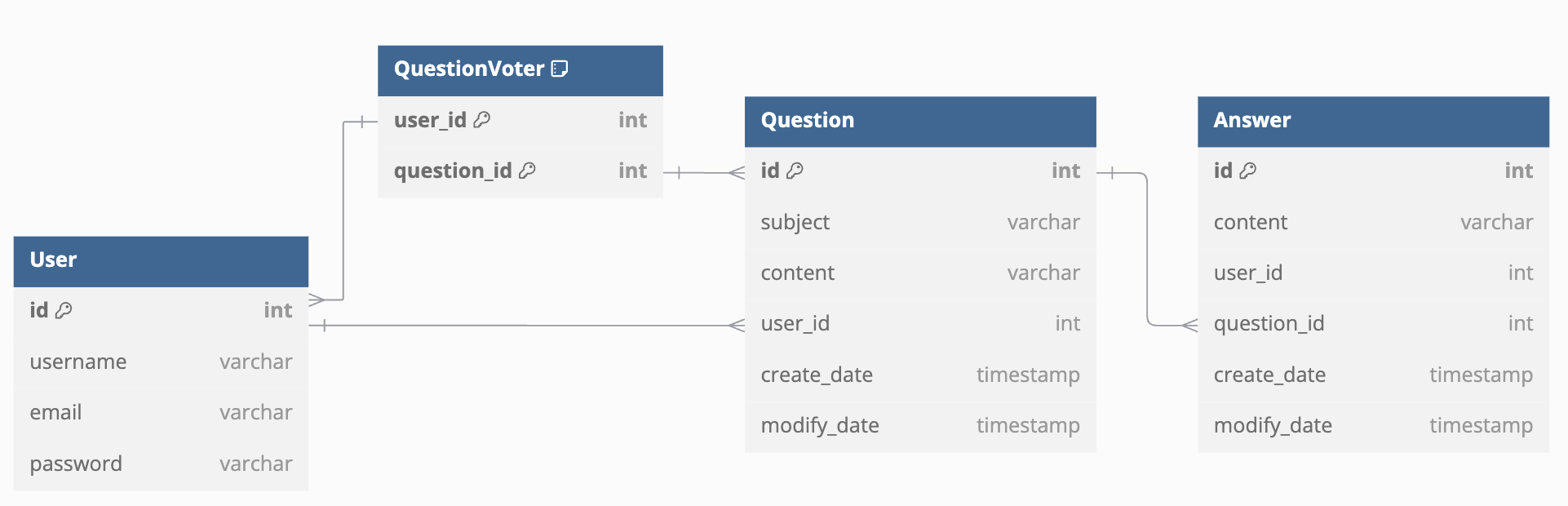
question = Table(
'question', Base.metadata,
Column('id', Integer, primary_key=True),
Column('subject', String, nullable=False),
Column('content', Text, nullable=False),
Column('create_date', DateTime, nullable=False),
Column('user_id', Integer, ForeignKey('user.id'), nullable=True),
Column('modify_date', DateTime, nullable=True),
)
answer = Table(
'answer', Base.metadata,
Column('id', Integer, primary_key=True),
Column('content', Text, nullable=False),
Column('create_date', DateTime, nullable=False),
Column('question_id', Integer, ForeignKey('question.id')),
Column('user_id', Integer, ForeignKey('user.id'), nullable=True),
Column('modify_date', DateTime, nullable=True),
)
user = Table(
'user', Base.metadata,
Column('id', Integer, primary_key=True),
Column('username', String, unique=True, nullable=False),
Column('password', String, nullable=True),
Column('email', String, unique=True, nullable=True),
)
question_voter = Table(
'question_voter',
Base.metadata,
Column('user_id', Integer, ForeignKey('user.id'), primary_key=True),
Column('question_id', Integer, ForeignKey('question.id'), primary_key=True)
)기초
select
데이터를 조회하기 위한 기본 쿼리.
-
예시 코드
from sqlalchemy import select stmt = select(question) results = session.execute(stmt).fetchall() print("results: ", results) -
결과
results: [ (1, 'user', 'user-첫번째 질문입니다.', datetime.datetime(2024, 12, 1, 0, 0), 1, datetime.datetime(2024, 12, 12, 13, 57, 17, 109273)), (2, 'user', 'user-두번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), None, datetime.datetime(2024, 12, 2, 0, 0)), (3, 'user', 'user-세번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), 2, datetime.datetime(2024, 12, 2, 0, 0)), ... ]
insert
데이터를 삽입하는 함수.
-
예시 코드
from sqlalchemy import insert from datetime import datetime stmt = insert(question).values( subject="service", content="insert test", create_date=datetime.now(), user_id=None ) session.execute(stmt) session.commit()
update
데이터를 업데이트.
-
예시 코드
from sqlalchemy import update from datetime import datetime stmt = update(question).where(question.c.id == 1)\ .values( content="update test", modify_date=datetime.now() ) session.execute(stmt) session.commit()
delete
데이터를 삭제.
-
예시 코드
from sqlalchemy import delete stmt = delete(question).where(question.c.id == 1) session.execute(stmt)
현재 question의 id가 1인 데이터를 외래키로 가진 answer 데이터때문에 에러발생
해결 방법1
question_id가 1인 데이터를 가진 answer 데이터 삭제 후, question삭제answer_stmt = delete(answer).where(answer.c.question_id == 1) question_stmt = delete(question).where(question.c.id == 1) session.execute(answer_stmt) session.execute(question_stmt) session.commit()
해결 방법2
자식 Table 객체에 옵션from sqlalchemy import Column, Integer, Table, ForeignKey answer = Table( ..., Column('question_id', Integer, ForeignKey('question.id', ondelete="CASCADE") )stmt = delete(question).where(question.c.id == 1) session.execute(stmt) session.commit()
where
조건문을 추가.
-
예시 코드
from sqlalchemy import select stmt = select(question).where(question.c.subject == "user") results = session.execute(stmt).fetchall() print("results: ", results) -
결과
results: [ (1, 'user', 'update test', datetime.datetime(2024, 12, 1, 0, 0), 1, datetime.datetime(2024, 12, 12, 13, 57, 17, 109273)), (2, 'user', 'user-두번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), None, datetime.datetime(2024, 12, 2, 0, 0)), (3, 'user', 'user-세번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), 2, datetime.datetime(2024, 12, 2, 0, 0)), ... ]
and / or / not
논리 연산자를 사용한 조건 결합.
- and_
여러 조건을 논리적으로 AND로 연결- 예시 코드
question의 id가 8이하이면서, subject가 service인 데이터 조회from sqlalchemy import select, and_ stmt = select(question).where( and_( question.c.id <= 8, question.c.subject == "service" ) ) results = session.execute(stmt).fetchall() print("results: ", results) - 결과
results: [ (6, 'service', 'service-첫번째 질문입니다.', datetime.datetime(2024, 12, 1, 0, 0), 1, datetime.datetime(2024, 12, 12, 13, 57, 17, 109000)), (7, 'service', 'service-두번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), 2, datetime.datetime(2024, 12, 2, 0, 0)), (8, 'service', 'service-세번째 질문입니다.', datetime.datetime(2024, 12, 3, 0, 0), 1, datetime.datetime(2024, 12, 12, 13, 57, 17, 109000)) ]
- 예시 코드
- or_
여러 조건을 논리적으로 OR로 연결- 예시 코드
question의 subject가 user이거나 service인 데이터 조회from sqlalchemy import select, or_ stmt = select(question).where( or_( question.c.subject == "user", question.c.subject == "service" ) ) results = session.execute(stmt).fetchall() print("results: ", results) - 결과
results: [ (1, 'user', 'update test', datetime.datetime(2024, 12, 1, 0, 0), 1, datetime.datetime(2024, 12, 12, 13, 57, 17, 109273)), (2, 'user', 'user-두번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), None, datetime.datetime(2024, 12, 2, 0, 0)), (3, 'user', 'user-세번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), 2, datetime.datetime(2024, 12, 12, 13, 57, 17, 109000)), ... (9, 'service', 'service-네번째 질문입니다.', datetime.datetime(2024, 12, 4, 0, 0), 2, datetime.datetime(2024, 12, 4, 0, 0)), (10, 'service', 'service-다섯번째 질문입니다.', datetime.datetime(2024, 12, 5, 0, 0), 1, datetime.datetime(2024, 12, 5, 0, 0)), ... ]
- 예시 코드
- not_
조건을 부정하는 데 사용- 예시 코드
question의 subject가 user가 아닌 데이터 조회from sqlalchemy import select, not_ stmt = select(question).where( not_( question.c.subject == "user" ) ) results = session.execute(stmt).fetchall() print("results: ", results) - 결과
results: [ (6, 'service', 'service-첫번째 질문입니다.', datetime.datetime(2024, 12, 1, 0, 0), 1, datetime.datetime(2024, 12, 12, 13, 57, 17, 109000)), (7, 'service', 'service-두번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), 2, datetime.datetime(2024, 12, 2, 0, 0)), (8, 'service', 'service-세번째 질문입니다.', datetime.datetime(2024, 12, 3, 0, 0), 1, datetime.datetime(2024, 12, 12, 13, 57, 17, 109000)), ... ]
- 예시 코드
text
순수 SQL 쿼리를 실행.
-
예시 코드
stmt = text("SELECT * FROM question WHERE id <= 3") results = session.execute(stmt).fetchall() print("results: ", results) -
결과
results: [ (1, 'user', 'update test', datetime.datetime(2024, 12, 1, 0, 0), 1, datetime.datetime(2024, 12, 12, 13, 57, 17, 109273)), (2, 'user', 'user-두번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), None, datetime.datetime(2024, 12, 2, 0, 0)), (3, 'user', 'user-세번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), 2, datetime.datetime(2024, 12, 2, 0, 0)) ]
중급
join
두 테이블을 조인.(INNER JOIN이 기본으로 적용됨)
-
예시 코드
from sqlalchemy import select stmt = select(question, user).join(user, question.c.user_id == user.c.id) results = session.execute(stmt).fetchall() print("results: ", results) -
결과
results: [ (1, 'user', 'update test', datetime.datetime(2024, 12, 1, 0, 0), 1, datetime.datetime(2024, 12, 12, 13, 57, 17, 109273), 1, 'test1', '$2b$12$OGngduoyV4uyulaxjlL/4urIzGlk0VFSndkY6jBD.BHeKPcofigGC', 'test1@test.com'), (3, 'user', 'user-세번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), 2, datetime.datetime(2024, 12, 2, 0, 0), 2, 'test2', '$2b$12$3..HbiNBXxe414aD1n2hnObYYTl9uHdW5hFcK4PtatIb6NHjwZYhi', 'test2@test.com'), ...LEFT OUTER JOIN
from sqlalchemy import select stmt = select(question, user).outerjoin(user, question.c.user_id == user.c.id) results = session.execute(stmt).fetchall() print("results: ", results)results: [ (1, 'user', 'update test', datetime.datetime(2024, 12, 1, 0, 0), 1, datetime.datetime(2024, 12, 12, 13, 57, 17, 109273), 1, 'test1', '$2b$12$OGngduoyV4uyulaxjlL/4urIzGlk0VFSndkY6jBD.BHeKPcofigGC', 'test1@test.com'), (2, 'user', 'user-두번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), None, datetime.datetime(2024, 12, 2, 0, 0), None, None, None, None), (3, 'user', 'user-세번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), 2, datetime.datetime(2024, 12, 2, 0, 0), 2, 'test2', '$2b$12$3..HbiNBXxe414aD1n2hnObYYTl9uHdW5hFcK4PtatIb6NHjwZYhi', 'test2@test.com'), ...
group_by
데이터를 그룹화.
-
예시 코드
from sqlalchemy select, func stmt = select(question.c.subject, func.count(question.c.id)).group_by(question.c.subject) results = session.execute(stmt).fetchall() print("results: ", results) -
결과
results: [('service', 5), ('project', 5), ('user', 6), ('share', 5)]
having
그룹화된 데이터에 조건 추가.
-
예시 코드
from sqlalchemy select, func stmt = select(question.c.subject, func.count(question.c.id))\ .group_by(question.c.subject)\ .having(func.count(question.c.id) <= 5) results = session.execute(stmt).fetchall() print("results: ", results) -
결과
results: [('service', 5), ('project', 5), ('share', 5)]
distinct
중복을 제거한 결과 반환.
-
예시 코드
from sqlalchemy import select stmt = select(question.c.subject.distinct()) # stmt = select(question.c.subject).distinct(question.c.subject) results = session.execute(stmt).fetchall() print("results: ", results) -
결과
results: [('project',), ('service',), ('share',), ('user',)]
union / union_all
두 개 이상의 SELECT 문을 합칠 때 사용되며, union과 union_all의 차이점은 중복 처리 여부이다.
- union
중복된 결과를 제거-
예시 코드
from sqlalchemy import select stmt1 = select(question.c.id, question.c.subject, question.c.content)\ .where(question.c.id < 3) stmt2 = select(question.c.id, question.c.subject, question.c.content)\ .where(question.c.subject == "user") union_stmt = stmt1.union(stmt2) results = session.execute(union_stmt).fetchall() print("results: ", results) -
결과
results: [ (1, 'user', 'update test'), (2, 'user', 'user-두번째 질문입니다.'), (3, 'user', 'user-세번째 질문입니다.'), (4, 'user', 'user-네번째 질문입니다.'), (5, 'user', 'user-다섯번째 질문입니다.'), (309, 'user', 'insert test') ]
-
- union_all
중복된 결과를 포함-
예시 코드
from sqlalchemy import select stmt1 = select(question.c.id, question.c.subject, question.c.content)\ .where(question.c.id < 3) stmt2 = select(question.c.id, question.c.subject, question.c.content)\ .where(question.c.subject == "user") union_all_stmt = stmt1.union_all(stmt2) results = session.execute(union_all_stmt).fetchall() print("results: ", results) -
결과
results: [ (1, 'user', 'update test'), (1, 'user', 'update test'), (2, 'user', 'user-두번째 질문입니다.'), (2, 'user', 'user-두번째 질문입니다.'), (3, 'user', 'user-세번째 질문입니다.'), (4, 'user', 'user-네번째 질문입니다.'), (5, 'user', 'user-다섯번째 질문입니다.'), (309, 'user', 'insert test') ]
-
bindparam
쿼리에 바인딩된 파라미터 사용.
-
예시 코드
from sqlalchemy import select, bindparam stmt = select(question).where(question.c.id == bindparam("question_id")) result = session.execute(stmt, {"question_id": 1}).fetchone() print("result :", result) -
결과
result : (1, 'user', 'update test', datetime.datetime(2024, 12, 1, 0, 0), 1, datetime.datetime(2024, 12, 12, 13, 57, 17, 109273))
bindparam 사용 이유
- case1. bindparam을 사용한 경우
stmt = select(question).where(question.c.id == bindparam("question_id")) result = session.execute(stmt, {"question_id": 1}).fetchall()# 실제 SQL 쿼리 SELECT * FROM question WHERE id = :question_id- case2. bindparam을 사용하지 않은 경우
question_id = 1 stmt = select(question).where(question.c.id == question_id) result = session.execute(stmt).fetchall()# 실제 SQL 쿼리 SELECT * FROM question WHERE id = :id_1
-> case1은 bindparam을 사용해 동일한 쿼리 객체에 여러 파라미터를 효율적으로 바인딩할 수 있어, 반복 실행이 필요한 상황에서 재사용성이 뛰어나다. 반면, case2는 매번 새로운 조건으로 처리되기 때문에 재사용성이 낮고 효율적이지 않다.
bindparam은 Core에서 세부적인 제어나 쿼리 재사용을 명시적으로 구현할 때 필요하며, 쿼리를 재컴파일하지 않고 바인딩 값만 바꿔 실행할 수 있다.
literal_column
순수 SQL 표현을 포함하는 컬럼.
-
예시 코드
from sqlalchemy import select, literal_column stmt = select(literal_column("'test'").label("test_column"), question.c.content)\ .where(question.c.id <= 3) results = session.execute(stmt).fetchall() print("results: ", results) -
결과
results: [ ('test', 'update test'), ('test', 'user-두번째 질문입니다.'), ('test', 'user-세번째 질문입니다.') ].label()
SQLAlchemy에서 컬럼이나 표현식에 별칭(Alias)을 부여하기 위해 사용
즉, SQL 쿼리에서 결과 집합의 컬럼 이름을 변경하거나 새 이름을 지정할 때 사용
심화
case
SQL의 CASE 표현식 작성.
- 예시 코드
question의 modify_date가 2024-12-11 이후라면, 최근에 업데이트된 질문이므로 True, 아니라면 Falsefrom datetime import datetime from sqlalchemy import select, case stmt = select( question.c.id, question.c.content, question.c.modify_date, case((question.c.modify_date >= datetime(2024, 12, 11), True), else_=False) .label("is_recently_update") ) results = session.execute(stmt).fetchall() for result in results: print({ "question_id": result.id, "question_content": result.content, "question_modify_date": result.modify_date, "is_recently_update": result.is_recently_update }) - 결과
{'question_id': 1, 'question_content': 'update test', 'question_modify_date': datetime.datetime(2024, 12, 12, 13, 57, 17, 109273), 'is_recently_update': True} {'question_id': 2, 'question_content': 'user-두번째 질문입니다.', 'question_modify_date': datetime.datetime(2024, 12, 2, 0, 0), 'is_recently_update': False} {'question_id': 3, 'question_content': 'user-세번째 질문입니다.', 'question_modify_date': datetime.datetime(2024, 12, 12, 13, 57, 17, 109000), 'is_recently_update': True} {'question_id': 4, 'question_content': 'user-네번째 질문입니다.', 'question_modify_date': datetime.datetime(2024, 12, 2, 0, 0), 'is_recently_update': False} ...
func
SQL 함수 호출 (예: COUNT, MAX).
-
예시 코드
from sqlalchemy import select, func stmt1 = select(func.count(question.c.id)) question_count = session.execute(stmt1).fetchone() print("question_count: ", question_count) stmt2 = select(func.max(question.c.id)) question_max_id = session.execute(stmt2).fetchone() print("question_max_id: ", question_max_id) -
결과
question_count: (21,) question_max_id: (309,)
alias
테이블이나 서브쿼리에 별칭 부여.
-
예시 코드
from sqlalchemy import select question_alias = question.alias("question") stmt = select(question_alias).where(question_alias.c.subject == "service") results = session.execute(stmt).fetchall() print("results: ", results) -
결과
results: [ (6, 'service', 'service-첫번째 질문입니다.', datetime.datetime(2024, 12, 1, 0, 0), 1, datetime.datetime(2024, 12, 12, 13, 57, 17, 109000)), (7, 'service', 'service-두번째 질문입니다.', datetime.datetime(2024, 12, 2, 0, 0), 2, datetime.datetime(2024, 12, 2, 0, 0)), (8, 'service', 'service-세번째 질문입니다.', datetime.datetime(2024, 12, 3, 0, 0), 1, datetime.datetime(2024, 12, 12, 13, 57, 17, 109000)), (9, 'service', 'service-네번째 질문입니다.', datetime.datetime(2024, 12, 4, 0, 0), 2, datetime.datetime(2024, 12, 4, 0, 0)), (10, 'service', 'service-다섯번째 질문입니다.', datetime.datetime(2024, 12, 5, 0, 0), 1, datetime.datetime(2024, 12, 5, 0, 0)) ]
result.scalar_one / result.scalars
Core에서 단일 값 또는 스칼라 데이터를 반환.
-
예시 코드
from sqlalchemy import select stmt = select(questsion.c.id, question.c.content) scalar_result = session.execute(stmt).scalar() scalars_result = session.execute(stmt).scalars().all() stmt2 = select(question.c.id, question.c.content).where(question.c.id ==1) scalar_one_result = session.execute(stmt2).scalar_one() print("scalar_result: ", scalar_result) print("scalars_result: ", scalars_result) print("scalar_one_result: ", scalar_one_result) -
결과
scalar_result: 1 scalars_result: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 309] scalar_one_result: 1question을 첫번째 열로 작성한다면?
from sqlalchemy import select stmt = select(questsion) scalar_result = session.execute(stmt).scalar() print("scalar_result: ", scalar_result)scalar_result: 1- ORM 방식 (select(Question))
- ORM은 Question 클래스와 데이터베이스 테이블 간의 매핑을 사용
- 쿼리 결과는 ORM이 매핑된 Python 객체로 반환
- Core 방식 (select(question))
- Core 방식은 테이블 객체를 직접 사용하며, 데이터베이스 행(row)을 있는 그대로 반환
- scalar()는 첫 번째 컬럼 값을 반환
- ORM 방식 (select(Question))
