2023.01.13(금)
오늘 두 번째 논문을 리뷰해보려고 한다. 오늘 오전에 YOLO에 대한 논문을 리뷰하고 이제 2시 정도에 주간보고 하는거 지켜보고 끝낸 후 박사 과정에 계신 분과 학부 인턴 학우랑 셋이서 세미나도 진행했는데, 이 시간을 통해 내가 이번 겨울방학동안 해야 할 일에 대한 방향성을 좀 구체적으로 알 수 있게 되어서 의미 있었던 시간이었다. 이틀차지만 막연히 논문만 읽고 구현은 1도 안하고 이게 재미가 없어서 좀 힘이 빠졌었는데, 주간보고에서 다른 학우와 같이 협업하게 될 박사님이 하신 내용들을 보았을 때, 내가 읽은 논문에서 등장하는 데이터셋과 모델들을 사용하고 또 데이터셋을 정제하고 또 평가를 하면서 시각화를 하니까 나도 어서 논문 읽기를 끝내고 실질적으로 프로젝트에 참여하고픈 의지가 좀 생긴거 같았다. 또 더 재밌었던 건, 내가 그 전날에 읽은 내용 중 zero-shot splitting에 관한 내용이나 occlusion에 대한 내용을 실제로 따지고 고려하면서 회의를 했다는 것이다. 내가 논문에서 읽고 습득한 내용이 실제로 쓰임이 있구나 하는 생각이 들어 재미를 붙일 수 있는 계기가 된거 같았다. 내용을 어서 따라 잡아 초특급 아가에서 특급 아가 정도로 거듭나고 싶다,, 가보자고!!
1. Introduction
이 논문은 YOLO의 object detection 능력을 사람의 자세(pose)를 검출하는데 사용하고자 한다. 그 이유는 최근 object detection 기술의 향상이 많이 이뤄지고 있기 때문이다. 이 제안된 방법 이전에는 크게 두 가지 방식이 SOTA (state-of-the-art)라고 한다. Top-down과 bottom-up이다.
Top-down은 heavy person detector를 수행한 후, 각각의 검출마다 사람의 pose estimation을 수행한다. 그렇게 하게된다면 복잡도는 사람의 수에 비례하여 증가하게 되고 이는 real-time 검출에 적합하지 않은 high complexity와 variable runtime을 야기한다.
Bottom-up은 반대로 일관적인 run-time을 가진다. 한 번의 연산으로 image의 heatmap을 계산하고 heatmap의 local maxima를 keypoint로 검출해내기 때문이다. 하지만, heatmap으로 변환 후, 복잡하고 미분이 불가능한 post-processing 절차가 남아있어 end-to-end로 학습이 불가능하며, post-processing을 했음에도 불구하고 두 인접한 keypoint간 heatmap이 분별할 수 없을 수 있기에 부정확한 결과를 도출할 수 있다. 또, 이런 post-processing 과정(NMS, Non-Maximum Suppression, to find local maxima, line integral, refinement, etc)은 계산의 가속이 대개 어렵다고 한다.
YOLO-Pose는 두 방식의 장점만을 가져와 Pose Estimation을 수행한다. 우선, 사람을 잘 검출해낼 수 있는 YOLOv5 framework을 base로 삼는다. 이를 사용한다면 공간적으로 가까운 위치의 사람이더라도 다른 anchor box를 지니고 있기 때문에 분별이 가능하고, 이는 결국 사람의 keypoint들 간의 분별을 가능케 한다. 이는 bottom-up 방식에서 keypoint는 잘 검출하되, 다른 사람의 것으로 엮는 문제를 해결해준다. 그리고 postprocessing도 비교적 간단하고 end-to-end로 구현되게 된다. 또한 top-down 방식과 달리, 사람의 수와 무관한 run-time을 지니게 된다. 동시에 사람들과 각각의 keypoint를 검출해낼 수 있게 되기 때문이다. (YOLO 모델의 특성상)
해당 논문은 해당 내용에 대해 다룰 것이라고 한다.
- pose estimation과 object detection은 scale variation과 occlusion 같은 도전적인 상황이 동일하게 존재한다고 한다. 제안하고자하는 방식(YOLO-Pose)는 object detection을 사용함으로써 object detection 기술의 향상으로부터 직접적인 이득을 받을 수 있을 것이라고 주장한다.
- YOLO-Pose는 heatmap-free이고 end-to-end training이 가능한 standard OD postprocessing을 사용할 것이라고 한다.
- IoU 개념을 확장하여 Object Keypoint Similarity(OKS)를 제안한다. 이는 evaluation뿐만 아니라 training을 위한 loss 값으로도 쓰인다. OKS Loss는 scale-invariant(크기에 영향 X)이고 keypoint마다 다른 weighting을 배분한다.
- AP50을 SOTA에 비해 4배 덜 적은 연산으로 도달한다.
- joint detection과 pose estimation을 동시에 하는 framework을 제안한다.
- 낮은 복잡도로 개량한 모델들은 실시간에 치중한 모델들을 outperform한다.
2. Related Work
Multi-person 2D pose estimation은 크게 top-down과 bottom-up으로 나뉜다고 한다.
2.1 Top-down Methods
Top-down, 혹은 two-stage approaches들은 Faster RCNN 같은 사람 검출 모델을 먼저 돌린 후에 각 사람의 pose를 예측하는 식으로 진행된다. 따라서, 이미지 안의 사람들 수에 비례해 컴퓨터 연산의 복잡도 (computational complexity)가 증가하게 된다. 사람의 keypoint들을 segmentation mask로 검출해낸다고 한다. 이러한 모델의 예시로는 Mask-RCNN이 있다고 한다.
여기서 난 잘 모르겠는 표현이 나온다. 심플한 모델의 예시로는 단순한 아키텍쳐에 deep한 backbone과 several deconvolutional layers to enlarge the resolution of the output features라는 표현이 나오는데, deep한 backbone이 뭔지 모르겠고, deconvolutional layers가 뭔지도 잘 모르겠다.
이러한 모델은 사진의 scale에 영향을 안 받는다는 장점이 있는데, 대신에 occlusion, 가림,에 영향을 약하다고 하다.
2.2 Bottom-up Methods
Bottom-up approach는 어느 사람의 관절인지와 무관하게 이미지의 모든 keypoints들을 검출해내고 각각의 사람과 연결짓는다. Keypoints를 검출하기 위해 heatmap을 사용한다. NMS 같은 방식으로 찾은 heatmap의 pixel 중 local maxima에 특정 keypoint가 있다고 예측하는 것인데, 이러한 방식은 top-down 방식에 비해 연산 복잡도가 낮고 running time도 적은 대신에 정확도가 떨어진다.
3. YOLO-Pose
해당 논문에서 제안하는 YOLO-Pose는 bottom-up 방식과 같은 single-shot approach이지만, heatmap을 안 쓰는 대신 anchor를 사용해 사람들의 keypoints들을 묶는다.
3.1 Overview
사람 검출에 강한 YOLOv5를 base로 선택했고 그 위에 얹히는 방식으로 모델 구성을 했다고 한다. YOLOv5는 검출한 오브젝트를 80개의 class를 분별할 수 있고 anchor당 85개의 element들을 예측한다. 그리고 각각의 grid의 location 당 3개의 서로 다른 모양의 anchor가 존재한다고 한다. 난 anchor가 정확히 뭔지 잘 모르겠다.
사람의 pose estimation을 하기 위해 사람당 17개의 keypoints를 검출해야 하는데 각각의 keypoints는 좌표와 confidence에 의해 구별된다. 각각의 anchor의 prediction vector은 다음과 같이 정의된다.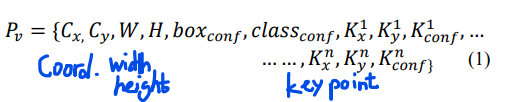
각 keypoint의 confidence는 keypoint의 visibility에 근거한다고 한다. 보이면 1, 보이지 않으면 0으로 설정했다고 한다. 또 만약 keypoint가 사진 밖에 존재한다면, 검출할 때 보이지 않는 keypoint도 그리면 안되니까, 지워냈다고 한다.
YOLO-Pose는 CSP-darknet53을 backbone으로 사용하고 PANet을 backbone으로부터 검출된 features들을 fusing하도록 했다고 한다. 그리고 이러한 특징들을 다양한 scales에 적용되는 4개의 detection heads로 들어가게 되고 마지막으로 2개의 decouple heads가 boxes와 keypoints들을 예측하게 된다.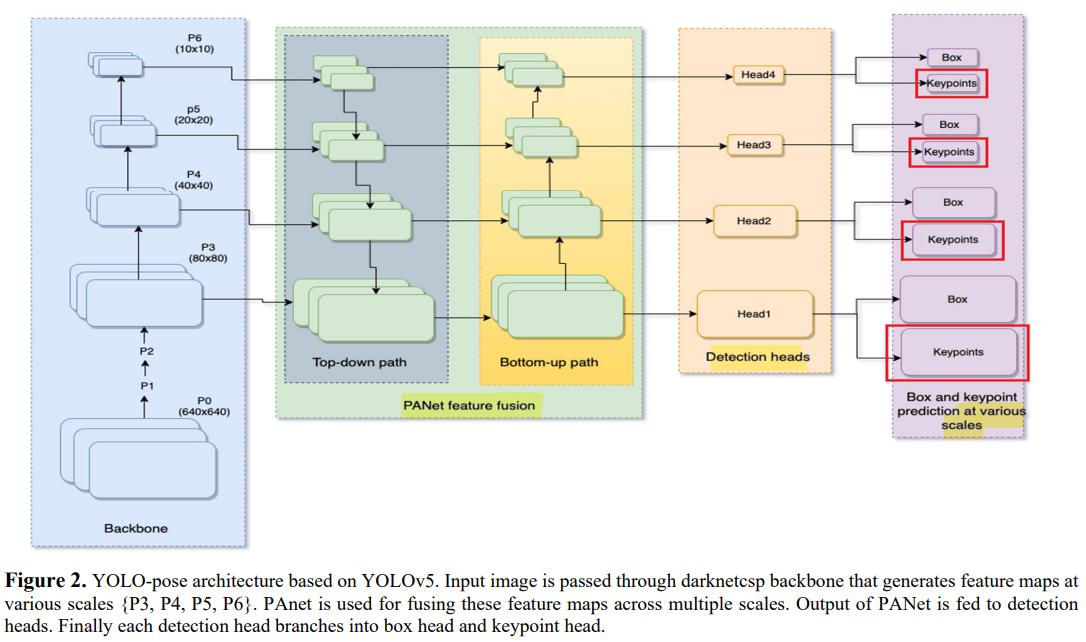
3.2 Anchor based multi-person pose formulation
검출된 사람과 match되어진 anchor에 bounding box에 대한 정보가 담기게 되고 각각의 keypoint와 box는 anchor 중심에 대해서 예측된다고 한다. (With respect to the center of the anchor)
3.3 IoU Based Bounding-box Loss Function
이 모델은 CIoU Loss를 사용해다. 
3.4 Human Pose Loss Function Formulation
OKS, Object Keypoint Similarity는 keypoints들을 평가하는데 있어 가장 인기가 많고 keypoint location을 회귀하는데 사용되는 loss function이다. 또 크기 scale에 무관하고 사람의 머리(eyes, nose, ears)를 사람의 다른 부위 (shoulders, knees, hips)보다 더 중요시여긴다. OKS loss는 절대 plateu하지 않는다고 하며 각각의 keypoint의 loss가 따로 구해지고 마지막에 한번에 더해진다.
그리고 각각의 keypoint의 confidence에 대한 loss도 계산을 한다.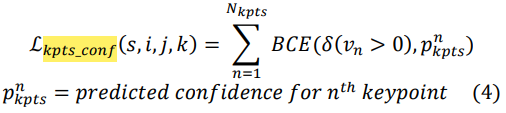
이후 location (i,j)에 해당하는 scale이 s인 K_th anchor에 대해 ground truth bounding box를 비교해서 total loss를 구하면, 다음과 같다.
3.5 Test Time Augmentations
논문 기준 SOTA, State Of The Art pose estimation은 TTA, Test Time Augmentation에 성능향상을 위해 의존한다고 한다. Flip Test와 Multi-scale testing이 대개 쓰인다. 다만, 이러한 방식은 연산 복잡도와 시간을 잡아먹기 때문에 해당 논문에서는 사용하지 않았다고 한다.
3.6 Keypoint Outside Bounding Box
YOLO-Pose는 bounding box 밖에 keypoint가 있으면 안된다는 제약 조건이 없기 때문에, occlusion이 발생하더라도 사람의 keypoint를 잘 예측할 수 있다. 
4. Experiments
4.1 COCO Keypoint Detection
Dataset COCO Dataset을 사용했다고 한다. 200,000 이상의 이미지와 250,000 사람 instances와 17개의 keypoint로 구성되어 있다고 한다. train2017 set은 57,000개의 이미지와 val2017, test-dev2017은 5000, 20,000개의 이미지로 구성되어 있다. train2017로 훈련을 시키고 나머지 val2017과 test-dev2017에 대해 결과 보고서를 작성했다고 한다.
Evaluation Metric standard evaluation metric과 OKS-based metric을 사용했다고 한다. Average precision, average recall scores들을 다양한 thresholds와 다양한 오브젝트 크기에 대해 계산했다고 한다. AP, AP50, AP75, APL, AR
Training data augmentation을 수행했다 (random scale ([0.5, 1.5]), random translation [-10, 10], random flip with probability 0.5, mosaic augmentation with probability 1, and various color augmentations).
SGD optimzer를 cosine scheduler와 함께 사용했고 learning rate은 1e-2로 설정하고 300 epoch만큼 수행했다.
Testing 각 input image를 특정한 크기의 정사각형 이미지로 설정하고 학습시켰다고 한다.
4.2 Results on COCO val2017
Higer HRNet, EfficientHRNet같은 SOTA approach들과 비교를 진행했다. AP50 metric에 대하여 YOLO-Pose는 4배 더 복잡한 DEKR 모델보다 더 나은 AP50과 APL 점수를 얻었다고 한다.
4.3 Ablation Study: OKS Loss vs L1 Loss
OKS가 L1 Loss에 비해 더 나은 성능을 가져왔다.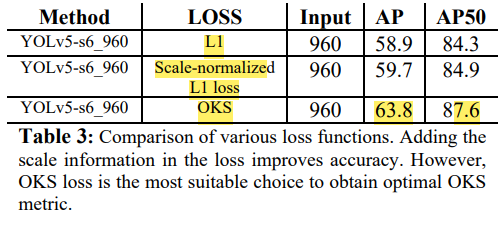
4.4 Ablation Study: Across Resolution
낮은 해상도에 대해서도 YOLO-Pose가 더 나은 성능을 자랑했다.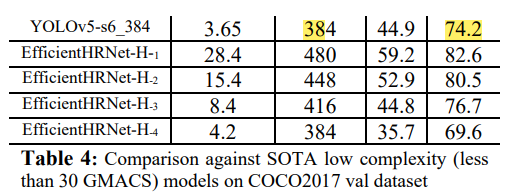
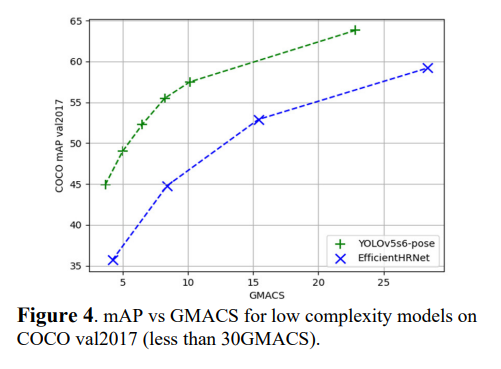
4.5 Ablation Study: Quantization
기존의 YOLOv5 모델은 activation function으로 sigmoid-weighted linear unit (SiLU)를 사용했는데, 이는 quantization에 약하므로 이에 상대적으로 강한 ReLU 모델을 사용했다고 한다. 다양한 quantization에 대한 AP 값은 다음 테이블과 같다.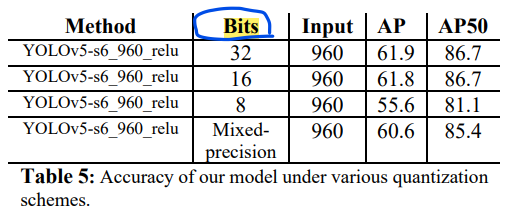
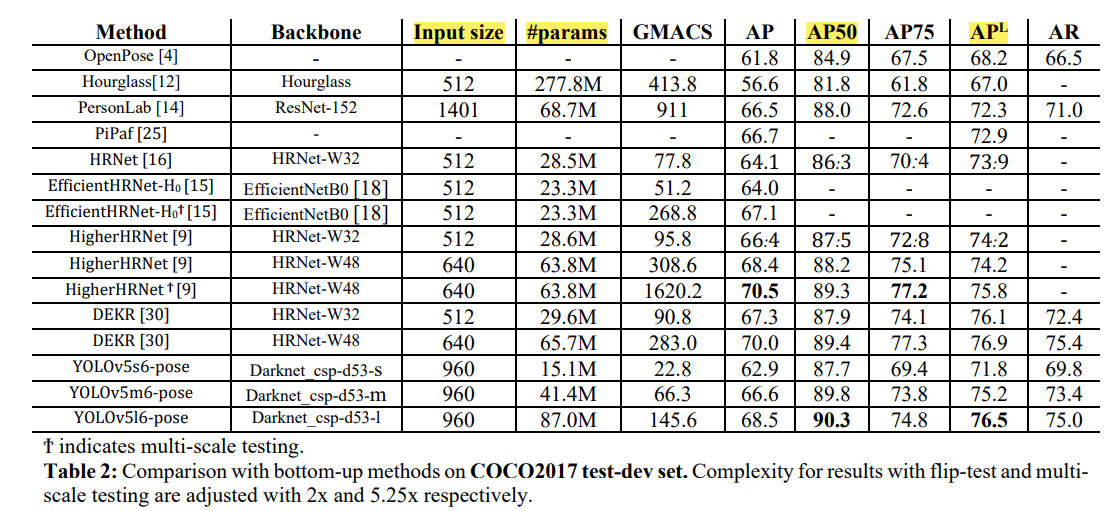
4.6. Results on COCO test-dev2017
Bottom-up 방식이면서 keypoint를 localize 시키기 때문에 성능이 뛰어나다.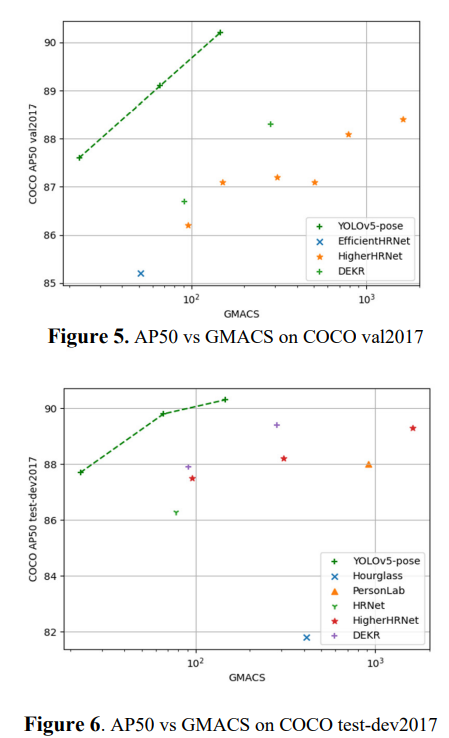
5. Conclusion
이 논문의 목표는 object detection과 human pose estimation을 융합하는 것이라고 한다. Object detection의 benefits을 human pose estimation으로 전달하도록 하는 것이 목표라고 한다.
출처
Maji, Debapriya, et al. "YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
