
2023.01.17 (화)
출근한지 나흘째. 지금까진 괜찮다. 오전에 일찍 일어나는 것도 좋고, 한 시간 반 정도 걸려서 오는 것도 나쁘진 않다. 어제는 코 진료를 받으러 세브란스 병원에 1시 20분까지 가야 했기에 점심까지만 일하고 일찍 퇴근했다. 달았다. ㅋㅎㅎ 오늘은 풀 타임으로 일할 예정이다. 다만 오늘은 점심에 안과를 다녀올 예정이다. 어제도 오른쪽 눈이 흐릿하고 초점이 안 맞아 안과도 다녀왔는데 내 난시가 엄청 심하다는 것이다. 다시 확인 받으러 다녀올 예정이다.
오늘은 파이토치를 이용해서 MNIST 학습 모델을 만들어보고 공부해보려고 한다. 오전까지는 PyTorch 환경 세팅하고 간단한 텐서 연산과 모델을 만드는데 필요한 모듈들을 공부해 보았다. 이 중 다층 신경망에 대해 공부해보려고 한다.
MLP Multi Layer Perceptrons 정의하기
PyTorch를 사용하여 신경망을 빌드하려면 torch.nn 패키지를 사용해야 한다. 이렇게만 보면 거부감이 없는데, 막상 사용하면서 코드로 보게 되면 거부감이 생긴다. 그래서 난 그냥 cook kit처럼 생각하기로 했다. ㅋㅋㅋ 그냥 이제 끓인 물만 넣고~ 전자레인지만 돌리면 되는 느낌으로. 쨌든, 2-1 MNIST MLP 코드를 살펴보겠다. 참, 모든 코드는 DeepLearning101의 깃허브에서 가져왔다. 이 레포지터리로 파이토치를 공부하는 중이다.
1. Module Import
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms, datasets2. 딥러닝 모델을 설계할 때 활용하는 장비 확인
이후로는 기본적인 세팅을 완료한다. CUDA가 있으면 cuda를 쓰고 없으면 cpu를 쓰도록 하는 것과 batch와 epoch 크기를 정해주었다.
if torch.cuda.is_available():
DEVICE = torch.device('cuda')
else:
DEVICE = torch.device('cpu')
print("Using PyTorch version:", torch.__version__,' Device:', DEVICE)
BATCH_SIZE = 32
EPOCHS = 103. MNIST 데이터 다운로드 (Train set, Test set 분리하기)
위에서 import한 모듈 중 torchvision 라이브러리에서 MNIST dataset을 가져와준다. 이때 train과 test dataset을 분리한 후, 가져온 데이터셋을 torch.utils.data.DataLoader()에서 BATCH_SIZE에 맞추어 잘 나눠준다.
train_dataset = datasets.MNIST(root = "../data/MNIST",
train = True,
download = True,
transform = transforms.ToTensor())
test_dataset = datasets.MNIST(root = "../data/MNIST",
train = False,
transform = transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = BATCH_SIZE,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = BATCH_SIZE,
shuffle = False)4. 데이터 확인하기
이렇게 가져온 데이터를 확인해보면 다음과 같다.
for (X_train, y_train) in train_loader:
print('X_train:', X_train.size(), 'type:', X_train.type())
print('y_train:', y_train.size(), 'type:', y_train.type())
break결과:
X_train: torch.Size([32, 1, 28, 28]) type: torch.FloatTensor
y_train: torch.Size([32]) type: torch.LongTensor
데이터셋은 BATCH_SIZE에 맞추어서 32개로 나눴기 때문에 32개가 있는거다. train_loader의 길이를 구해보았더니 다음과 같았다. train_dataset은 총 1875 * 32 = 60000장의 사진이 있는 것이다.
가져온 데이터셋의 모양도 살펴보면 다음과 같다.
pltsize = 1
plt.figure(figsize=(10 * pltsize, pltsize)) #10개 plot하기 위한 figure 크기 설정
for i in range(10):
plt.subplot(1, 10, i + 1) # plot.subplot(rows, columns, index)
plt.axis('off')
plt.imshow(X_train[i, :, :, :].numpy().reshape(28, 28), cmap = "gray_r")
plt.title('Class: ' + str(y_train[i].item()))
5. Multi Layer Perceptron (MLP) 모델 설계하기
데이터셋이 잘 불러와줬음을 확인했으니 이제 모델을 설계해보자.
class Net(nn.Module): # nn.Module은 모든 neural network의 base class라고 한다.
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28*28, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 10)
def forward(self,x):
x = x.view(-1, 28*28)
x = self.fc1(x)
x = F.sigmoid(x)
x = self.fc2(x)
x = F.sigmoid(x)
x = self.fc3(x)
x = F.log_softmax(x, dim=1)
return xPyTorch를 사용했을 때 좋은 점은 위와 같이 신경망을 만들 때 정방향 방향의 함수만 정의해도 되는 것이다. 역방향 함수는 자동으로 정의가 된다. 그러기 위해서는 당연히 torch.nn.functional에서 제공해주는 함수들을 사용해야 할 것이다. 위와 같은 네트워크에서 학습 프로세스를 돌리게 되면 모든 계층에서 입력값을 순차적으로 처리하게 되고, 마지막의 층에서 예측 레이블과 올바른 레이블 간의 다른 정도를 파악하게 된다. 이 다른 정도를 그라데이션, 즉 기울기로 나타내고 이 그라데이션 값을 네트워크에 다시 전파해서 계층 가중치를 업데이트하는 방식으로 모델은 가중치를 설정하는 방법을 학습하게 된다.
6. Optimizer, Objective Function 설정하기
이 부분은 나도 정확히 잘은 모르는데 Optimzier는 Loss를 갱신하는 방법에 대해 다루는거고 Objective Function은 Loss function을 의미한다. Optimizer의 매개변수를 보면 lr=0.01과 momentum=0.5가 있다. lr은 learning rate로 그라디언트를 얼마만큼 강하게 적용 시킬지를 결정하고 momentum은 gradient값이 0에 도달하는 경우가 있다고 하더라도 빠져나올 수 있도록 관성력을 주는 계수라고 한다. 옵티마이저의 종류로는 SGD, AdaGrad, Adam 등이 있으며 learning rate를 epoch가 증가함에 따라 수정해주는 Scheduler가 있다고 한다.
model = Net().to(DEVICE)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
criterion = nn.CrossEntropyLoss()
print(model)결과
Net(
(fc1): Linear(in_features=784, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=256, bias=True)
(fc3): Linear(in_features=256, out_features=10, bias=True)
)7. MLP 모델 학습을 진행하며 학습 데이터에 대한 모델 성능을 확인하는 함수 정의
def train(model, train_loader, optimizer, log_interval):
model.train()
for batch_idx, (image, label) in enumerate(train_loader):
image = image.to(DEVICE)
label = label.to(DEVICE)
optimizer.zero_grad()
output = model(image)
loss = criterion(output, label)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print("Train epoch: {} [{}/{} ({:.0f}%)]\tTrain Loss: {:.6f}".format(
epoch, batch_idx * len(image),
len(train_loader.dataset), 100. * batch_idx / len(train_loader),
loss.item()))제목 그대로 모델 성능을 확인하는 함수이다. 모델 성능과 더불어 학습을 시켜주는 함수이다. 함수를 하나하나 살펴보면,
model.train()을 설정해준다. 모델은 학습할 때와 추론할 때 다르게 동작하는 layer들이 있는데, 학습을 할 것이라고 명시해준다. 이 기능은 PyTorch에서 자주 사용되는 코드라고 한다.model.eval()도 있다고 한다.- train_loader 안에 들어있는 batch_idx 별로 각각의 image와 label을 image, label 로컬 변수에 저장을 해준다.
optimizer.zero_grad()를 호출하여 모델 매개변수의 변화도를 재설정한다. 기본적으로 변화도는 더해지기(add up) 때문에 중복 계산을 막기 위해 반복할 때마다 명시적으로 0으로 설정한다.- model에 image 값을 넣어준 것의 값을 output 변수에 저장해준다. 이후
criterion()에 넣어줌으로써 loss 값을 구한다. loss.backward()를 통해 역전파도 해준다. 이때 PyTorch는 각 매개변수에 대한 손실의 변화도를 저장한다.optimizer.step()을 호출해서 역전파 단계에서 수집된 변화도로 매개변수로 조정한다.- 마지막으로 log_interval 크기마다 Train epoch와 Train Loss를 출력하도록 해서 성능 확인을 가능케 한다.
8. 학습되는 과정 속에서 검증 데이터에 대한 모델 성능을 확인하는 함수 정의
def evaluate(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for image, label in test_loader:
image = image.to(DEVICE)
label = label.to(DEVICE)
output = model(image)
test_loss += criterion(output, label).item()
prediction = output.max(1, keepdim=True)[1]
correct += prediction.eq(label.view_as(prediction)).sum().item()
test_loss /= (len(test_loader.dataset)/ BATCH_SIZE)
test_accuracy = 100. * correct/len(test_loader.dataset)
return test_loss, test_accuracy이제 학습 과정 속에서 검증 데이터에 대한 모델 성능을 확인하는 함수에 대한 설정에 대한 함수이다. 난 여태껏 잘 이해 못했었는데 아마 내가 이해한 것이 맞다면, 각 epoch 별로 전체 데이터셋, 즉 train_loader 안에 들어있는 데이터들을 배치 크기에 맞게 나누어서 학습을 진행하는 것으로 이해를 했다. 검증을 다 한 후에는 다시 optimzer의 gradients를 모두 0으로 세팅하고 다시 epoch 1회를 또 하는 식으로 학습을 진행하는 것 같다. 어쨌든, evaluate()은 1 epoch동안 train()을 다 한 후, 검증해보는 함수인 것이다.
- 위에서 말했던 것처럼 이제 평가를 하는 것이기 때문에
model.eval()이 사용된다. 학습할 때와 추론할 때 다르게 동작하는 Layer들을 Evaulation mode로 바꿔준다. torch.no_grad()에서는 PyTorch의 Autograd Engine을 비활성화해서 Gradient를 계산하지 않도록 한다. Gradient를 계산하지 않기 때문에 메모리 사용량을 줄이고 계산 속도를 빠르게 만들 수 있다. 참고로 학습할 때와 평가할 때 다음과 같이 두 가지의 경우로 나뉘어서 함수를 작성하면 될 것 같다.

- test_loss는 각 BATCH_SIZE 별로 loss 값이 더해지고 그 다음에
(len(test_loader.dataset)/ BATCH_SIZE)크기만큼 나뉘게 된다. 이게 왜 그런가에 대해 생각을 많이 했다. 그냥test_loss /= len(test_loader.dataset)이어야 하는거 아닌가? 싶었다.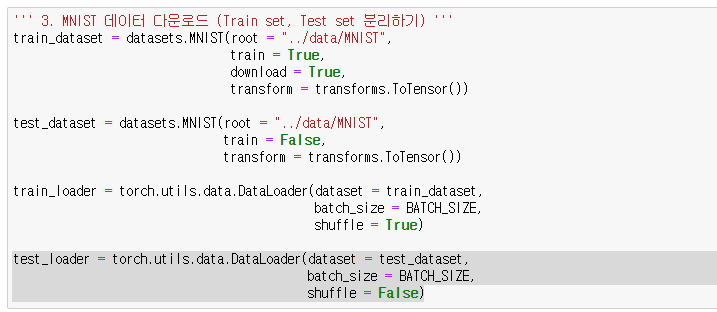
하지만 여기를 보면 이렇게 test_loader도 BATCH_SIZE만큼 나뉘어서 들어가게 된다. 그래서 위의 코드와 같이 나뉘게 되는 것이다.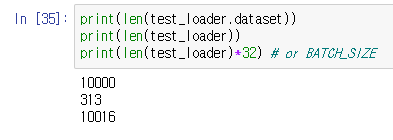
9. MLP 학습 실행하며 Train, Test set의 Loss 및 Test set Accuracy 확인하기
모든 준비가 끝났으니, 학습을 시켜주면 된다.
for epoch in range(1, EPOCHS + 1):
train(model, train_loader, optimizer, log_interval = 200)
test_loss, test_accuracy = evaluate(model, test_loader)
print("\n[EPOCH: {}], \tTest Loss: {:.4f}, \tTest Accuracy: {:.2f} %\n".format(
epoch, test_loss, test_accuracy))CPU로 돌려도 MNIST는 크기가 크지 않아 금방 됐다. 1 Epoch와 10 Epoch의 결과만을 올려보겠다.
Train epoch: 1 [0/60000 (0%)] Train Loss: 2.230744
Train epoch: 1 [6400/60000 (11%)] Train Loss: 2.185731
Train epoch: 1 [12800/60000 (21%)] Train Loss: 2.191620
Train epoch: 1 [19200/60000 (32%)] Train Loss: 2.109231
Train epoch: 1 [25600/60000 (43%)] Train Loss: 1.875135
Train epoch: 1 [32000/60000 (53%)] Train Loss: 1.922193
Train epoch: 1 [38400/60000 (64%)] Train Loss: 1.834045
Train epoch: 1 [44800/60000 (75%)] Train Loss: 1.428548
Train epoch: 1 [51200/60000 (85%)] Train Loss: 1.562168
Train epoch: 1 [57600/60000 (96%)] Train Loss: 1.233367
[EPOCH: 1], Test Loss: 1.2468, Test Accuracy: 60.78 %
...
Train epoch: 10 [0/60000 (0%)] Train Loss: 0.405347
Train epoch: 10 [6400/60000 (11%)] Train Loss: 0.484223
Train epoch: 10 [12800/60000 (21%)] Train Loss: 0.188986
Train epoch: 10 [19200/60000 (32%)] Train Loss: 0.250357
Train epoch: 10 [25600/60000 (43%)] Train Loss: 0.470695
Train epoch: 10 [32000/60000 (53%)] Train Loss: 0.328740
Train epoch: 10 [38400/60000 (64%)] Train Loss: 0.461421
Train epoch: 10 [44800/60000 (75%)] Train Loss: 0.345035
Train epoch: 10 [51200/60000 (85%)] Train Loss: 0.236559
Train epoch: 10 [57600/60000 (96%)] Train Loss: 0.121124
[EPOCH: 10], Test Loss: 0.3244, Test Accuracy: 90.62 %60.78%에서 90.62%으로 Test Accuracy가 증가했음을 알 수 있다.
후기
PyTorch를 사용하면 정말 편리하구나를 느낄 수 있었다. 그냥 PyTorch가 다 해주네 싶다. 예전에 밑시딥3권을 진행하면서 실제로 forward랑 backward propagation이 되도록 직접 라이브러리를 구현해본적이 있는데, 그냥 파이토치를 쓰면 되겠다 싶다. 다만, 이런 강력한 툴을 사용하려면 이론에 대해 빠삭해야겠다 싶었다. 아무리 툴이 강력해도 어떻게 쓸지 모르면 의미없기 때문이다. 내 상태를 보면 정말 허술하게 이것저것 아는 듯한 느낌인데, 이 코드를 백지에서부터 쓸 수 있을지는 모르겠다. 아직 이론적 개념이 부족한게 느껴진다. 계속해서 공부하면서 채워나가보겠다.
출처
https://learn.microsoft.com/ko-kr/windows/ai/windows-ml/tutorials/pytorch-train-model
https://github.com/Justin-A/DeepLearning101
https://tigris-data-science.tistory.com/entry/PyTorch-modeltrain-vs-modeleval-vs-torchnograd
https://tutorials.pytorch.kr/beginner/basics/optimization_tutorial.html
마크다운 문법 참고
