데이터 분석 71일
📌 A/B 테스트 사이트
1. A/B 테스트의 핵심 요소
- 대조군(Control Group): 아무 변화도 주지 않은 그룹
- 실험군(Treatment Group): 새로운 조건을 적용한 그룹
- 평가지표(Metrics): 실험효과를 측정할 수 있는 지준
- ex) 전환율, 클릭률, 평균 구매 금액 등
2. Randomization (무작위 배정)
- 편향(Bias) 제거
- 특정 집단이 과도하게 실험에 포함되거나 제외될 위험을 줄임
예: 온라인 수업 실험에서 자기주도적인 학생들만 참여하면 결과가 왜곡될 수 있음
→ 무작위 배정을 통해 이 문제를 방지
- 두 그룹 간 비교 가능성 확보
- 실험군과 대조군이 기본적으로 유사한 특성을 갖게 되어 처치로 인한 진짜 효과만을 비교할 수 있음
- 외부 요인 제거 (Confounding Variables 통제)
예: 온라인 수업을 듣는 학생들이 사실은 시간 여유가 더 없거나 성적이 낮을 수 있음
→ 이런 요인이 결과에 영향을 미치지 않도록 설계된 것이 무작위 배정
🔹 실생활 예시
-
온라인 수업의 효과를 알아보는 실험에서, 온라인 수업을 듣는 학생들이 대면 수업을 들을 여유가 없는 낮은 수준의 학생일 수 있다는 걱정은 하지 않아도 됨
-
랜덤 실험 설계 자체가 이러한 차이를 없애기 위해 만들어졌기 때문이다.
-
그 결과, 실험군과 대조군 학생들은 기본적으로 비슷한 특성을 가진 집단이 되었고,
점수 차이는 학습 방식(온라인 vs 대면)의 효과로 설명할 수 있게 된다.
🔹 통계적 해석: 평균의 차이 + 표준 오차
-
실험에서는 보통 처치 효과를 추정하기 위해 두 그룹의 평균 차이를 계산한다.
-
하지만 이 평균 차이가 우연인지 실제 효과인지 판단하려면, 결과의 불확실성을 이해하는 것이 중요합니다.
⭐ 바로 여기서 표준 오차(Standard Error)가 등장!!
표준 오차는 우리가 계산한 평균 차이가 얼마나 신뢰할 수 있는지를 보여주는 지표이다.
3. Standard Error (표준 오차)
🔹 표준 오차란?
- 표준 오차(SE)는 샘플 평균이 모집단 평균에서 얼마나 벗어날 수 있는지를 나타내는 값
- 실험 결과의 신뢰도를 보여주는 지표!
- SE가 작을수록, 샘플 평균은 모집단 평균에 가깝다고 판단할 수 있다.
🔹 수식: Moivre's Equation
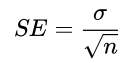
- SE: 표준 오차 (Standard Error)
- σ: 모집단의 표준편차 (모르거나 샘플에서 추정 가능)
- n: 샘플 크기
🔹 왜 표준 오차가 중요한가?
1) 샘플 크기가 클수록 결과가 더 신뢰 가능
- 샘플이 작을수록 평균의 변동성(흔들림)이 커서, 극단적인 결과가 나올 수 있음
- 샘플이 클수록 평균이 모집단 평균에 가까워지며, 표준 오차는 작아짐
2) 샘플 간의 차이를 비교할 때 사용
- 예: 실험군과 대조군의 평균 점수 차이가 우연인지, 실제로 유의미한 차이인지 파악할 때
→ 표준 오차가 작을수록, 평균 차이의 신뢰도는 높아짐
✅ 실습 예시 (Python 코드)
import pandas as pd
import numpy as np
data = pd.read_csv("online_classroom.csv")
online = data.query("format_ol==1")["falsexam"]
face_to_face = data.query("format_ol==0 & format_blended==0")["falsexam"]
def se(y: pd.Series):
return y.std() / np.sqrt(len(y))
print("대면 학습 그룹의 SE:", se(face_to_face)) # 0.8724
print("온라인 학습 그룹의 SE:", se(online)) # 1.537결과: 
⭐ 다음 개념으로 연결: 신뢰 구간 (Confidence Interval)
표준 오차는 신뢰 구간을 계산하는 핵심 요소
예: 평균 ± 1.96 × SE → 95% 신뢰 구간
4. Confidence Interval (신뢰 구간)
🔸 신뢰 구간이란?
- 실험에서 평균을 구했다면, 그 평균이 실제로 얼마나 믿을 수 있는지 궁금하겠지?
- 신뢰 구간은 그 평균이 어느 범위 안에 있을 가능성이 높은지를 알려주는 범위!
ex) “이 그룹의 평균 점수는 73.6점이고, 진짜 평균은 95% 확률로 70.6점에서 76.6점 사이에 있을 거예거다" 라고 말할 수 있는 게 바로 신뢰 구간이다.
🔸 왜 중요한가?
✅ 결과의 불확실성을 숫자로 보여준다
- 실험이나 조사는 항상 약간의 오차가 있음
- 신뢰 구간은 "얼마나 흔들릴 수 있는지" 그 오차 범위를 보여주는 것
✅ 단순한 평균보다 더 신뢰할 수 있음
- 그냥 "평균이 73.6점입니다"보다
→ "70.6점에서 76.6점 사이에 있을 가능성이 높습니다"가 더 정확한 느낌이다
🔸 어떻게 계산하나?
신뢰 구간=평균±1.96×표준 오차(SE)
(1.96은 95% 신뢰 수준일 때 쓰는 숫자)
- 표준 오차(SE)는 "이 평균이 얼마나 흔들릴 수 있나?"를 나타내는 값
📌 정리
| 항목 | 설명 |
|---|---|
| A/B 테스트 | - 대조군 vs 실험군을 비교하여 변화의 영향을 측정하는 실험 - 랜덤화를 통해 외부 요인의 영향 제거 및 공정한 비교 가능성 확보 |
| 표준 오차 (SE) | - 실험 데이터의 신뢰도를 나타내는 지표 - 샘플 크기가 클수록 SE는 작아지고 평균 추정치의 정확도는 높아짐 |
| 신뢰 구간 (CI) | - 실험 결과의 불확실성을 수치로 표현한 범위 - 95% 신뢰 구간: 동일 실험을 반복할 경우, 모집단 평균이 그 구간에 포함될 확률이 95% - 예: 대면 학습 CI (76.83, 80.25), 온라인 학습 CI (70.63, 76.65) → 구간이 겹치지 않으므로 대면 학습 점수가 유의미하게 높다고 판단 |
| 결론 | - 랜덤화와 통계적 지표(SE, CI)를 통해 실험 결과의 신뢰성과 인과 관계를 명확히 평가할 수 있음 |
최종 프로젝트 Day2
- 오늘 ebay에서 토큰받는 법과 open API 하는 법을 알게 되었다!
- 나름 사용할 데이터 테이블을 골라봤고 컬럼들을 봤다.
- 어떻게 컬럼들을 연결할지 ERD로 보긴 했지만 좀 더 시간이 필요하다...
끝!!
