데이터 분석
1.데이터 분석 - SQL

데이터 분석(SQL) 1일차 - mysql 사용 1. SQL 데이터 조회 - SQl의 가장 기본구조인 SELECT 와 FROM > select 컬럼1, 컬럼2 from 테이블 > select * from food_orders select에 *를 넣으면 f
2.데이터 분석 - SQL

데이터 분석(SQL) 2일차 - mysql 사용replace(바꿀 컬럼, 현재 값, 바꿀 값)식당 명에 'blue'를 'Pink'로 바꾸기 select restaurant_name "원래 상점명", replace(restaurant_name,
3.데이터 분석 - SQL

데이터 분석(SQL) 3일차 - mysql 사용💡 Subquery를 활용하여 복잡한 연산을 수행할 수 있다. ☝ Subquery가 필요한 경우 여러번의 연산을 수행해야 할때조건문에 연산 결과를 사용해야 할때 조건에 Query결과를 사용하고 싶을때select colum
4.데이터 분석 - SQL

데이터 분석(SQL) 4일차 - mysql 사용 1. 조회한 데이터에 아무 값이 없을 경우 1) 없는 값을 제외해주기 📌 MySQL에서는 사용할 수 없는 값(null이 아님)을 연산에서 0으로 간주함 📌 데이터 값이 null이여야 계산식에서 제외 시켜줌!
5.데이터 분석 - SQL 반올림

데이터 분석(SQL) 5일차 - mysql 사용 1. 반올림 함수 1) round - ROUND('수치값', '반올림 자릿수') ✔️ round 소숫점 반올림 ✔️ round 정수 반올림 반올림 자릿수를 지정할 때 마이너스(-) 기호를 붙여서 지정 2) CEI
6.파이썬 기초

파이썬 1일차 - 파이썬 기초1) 변수 선언 변수이름 = 값✔️ 특정 문자를 다른 문자로 바꾸기전화번호의 지역번호 출력📌 순서가 있는, 다른 자료형들의 모임📌 \[] 사이에 요소 넣기!✔️ 리스트의 길이도 len() 함수를 사용
7.데이터 분석 - 한주 정리(SQL, python)

1주차 내용 정리 - SQL, python 1. SQL 기초 1) SQL 기본 구조 작성 순서 select -> from -> where -> group by -> having -> order by 작동 순서 from -> on -> join -> where -
8.파이썬 - 조건문, 반복문, 함수

데이터 분석 6일차 (파이썬 2일) 조건을 만족했을 때 특정 코드를 실행하도록 하는 문법else - 위의 모든 if와 elif 조건이 모두 거짓일 때 실행elif - 앞선 if 또는 elif 조건들이 모두 거짓(False)일 경우, 추가적인 조건을 검사하여 참이면 실행
9.파이썬 - 튜플, 집합, f-string

📌 리스트와 비슷하지만 불변하는 자료형튜플은 대신 ( )으로 쓴다아래와 같은 내용 수정 작업 불가 📌 언제 주로 사용하냐면요, 아래와 같이, 딕셔너리 대신 리스트와 튜플로 딕셔너리 '비 슷하게' 만들어 사용해야 할 때 많이 쓰인다! 📌 중복이 제거됨! 변수로
10.파이썬 - Colab 단축키

코드 실행: Shift + Enter 새 코드 셀 추가: 코드 셀을 추가하려면 코드 셀 위에서 Ctrl + M + A 코드 셀 삭제: 코드 셀을 삭제하려면 코드 셀 위에서 Ctrl + M + D 코드 셀 복원: 마지막으로 삭제한 셀을 복원 Ctrl + M + Z 코드
11.파이썬 - 기초(다시한번 정리)

데이터 분석 9일차 (파이썬 5일) 파이썬 종합반 1주차📌 파이썬에서 가장 많이 사용하는 출려문 print 함수📌 화면에 값을 출력하는데 사용 📌 괄호 안에 출력하고자 하는 값을 넣어주고 여러 값을 출력할 때는 쉼표(,)로 구분함변수와 문자열 함께 출력 📌 무언
12.파이썬 - 튜플, 딕셔너리

변경 불가능(Immutable) 한 자료형으로, 리스트와 유사하지만 요소를 변경할 수 없다.소괄호 ()를 사용하여 정의하며, 요소를 쉼표 ,로 구분함count(): 지정된 요소의 개수를 반환index(): 지정된 요소의 인덱스를 반환수정은 불가 하지만 합치거나 반복은
13.파이썬 - 조건문, 반복문(for문, while문)

데이터 분석 12일차 (파이썬 8일) 파이썬 종합반 3주차 이전에 정리한 조건문과 반복문 1. 조건문(if, elif, else) 특정 조건이 참(True)인 경우에만 특정 코드가 실행됨 - if문 구조 💡들여쓰기 및 띄어쓰기 매우 중요!! 비교 연산자 파이
14.파이썬 - 함수 사용법

\- 함수는 특정 기능을 수행하는 코드로, 필요할 때 여러 번 호출할 수 있는 구조!✔ 코드 재사용 가능하게 함✔ 코드 논리적으로 나누어 가독성을 높임✔ 입력(매개변수)을 받아 결과(출력)를 반환할 수 있음\- 함수를 정의할 때는 def 키워드를 사용!여러 개의 인수를
15.SQL - WITH RECURSIVE

데이터 분석 14일차 WITH RECURSIVE는 자기 자신을 반복 호출하여 재귀적으로 데이터를 생성하는 SQL 문법✔️ UNION ALL을 사용해서 계속 새로운 데이터를 추가함.✔️ 종료 조건 (WHERE)이 없으면 무한 루프가 되므로 꼭 필요!✅ 실행 과정1️⃣ S
16.파이썬 - 유용한 문법 (포맷팅, 리스트 캄프리헨션, 람다, glob, os)

데이터 분석 14일차문자열을 포맷하는 가장 간결하고 직관적인 방법중괄호 {} 안에 변수명을 직접 넣어 사용print()보다 편함 🎯 수식도 가능🎯 f-string에서 정렬 가능리스트를 쉽고 간결하게 생성하는 문법기존의 for문을 한 줄로 줄여서 더 빠르고, 가독성이
17.SQL- Join on절에 세부 조건

데이터 분석 15일차✅ JOIN을 사용할 때 ON 절에서 추가적인 조건을 넣을 수 있다.✅ 조인을 수행할 때 특정한 조건을 적용하여 원하는 데이터를 필터링할 수 있다.✅ LEFT JOIN, INNER JOIN 등에서 ON과 WHERE의 차이가 있음.✔️ ON 절에서 A
18.파이썬 - Pandas를 활용한 데이터 필터링(1)

데이터 분석 16일차기본으로pandas와 numpy import 하는걸로 시작하기time 활용법(%%time)✔️출력: 1부터 1000만까지 합: 49999995000000 CPU times: user 1.19 s, sys: 786 µs, total: 1.19 s Wa
19.파이썬 - Pandas를 활용한 조인

데이터 분석 17일차🔹 merge()는 SQL의 JOIN과 유사하게 동작하며, 공통 컬럼을 기준으로 DataFrame을 결합할 때 사용한다.✅ 기본 문법✅ 조인 방식 (how 옵션)inner (기본값): 공통 컬럼 값이 있는 데이터만 반환 (교집합)left: 왼쪽(d
20.파이썬 - Pivot Table, index

데이터 분석 18일차Pivot Table은 데이터의 특정 열을 기준으로 그룹화하고, 원하는 방식으로 집계하여 재구성할 수 있는 도구이다. pandas 라이브러리의 pivot_table() 함수를 사용하여 데이터 분석을 쉽게 수행할 수 있다.🔹Pivot Table의 주
21.SQL - 날짜 더하기 & 빼기 정리

데이터 분석 19일차💡 + INTERVAL을 사용한 간단한 표현💡 - INTERVAL을 사용한 간단한 표현📍 JOIN에서 DATE_ADD()와 DATE_SUB()를 사용할 때 주의할 점🔹 (1) 하루 더한 값으로 JOINb.recorddate + 1일이 a.re
22.SQL - cross join, 다중 join

데이터 분석 20일차Cross Join은 두 개의 테이블을 조인할 때 모든 행을 조합하여 결과를 생성하는 방식💡 A 테이블에 5개의 행이 있고 B 테이블에 3개의 행이 있으면, 5 × 3 = 15개의 결과가 생성된다! <기본 구조> 또는 INNER JOIN의
23.SQL - 문제 풀이

데이터 분석 21일차https://leetcode.com/problems/not-boring-movies/description/홀수(odd) 라는것에 나머지가 1인 숫자를 구하면 되겠지라 생각하고 그럼 1은? 하고 짠 코드가... where id = 1 or
24.SQL - 문제 풀이, 기초 프로젝트 시작
데이터 분석 21일차https://leetcode.com/problems/project-employees-i/submissions/1580093171/project_id로 group by 하고 구하기정답코드첫날 한일주제 선정: H&M 고객/매출 데이터결측치와
25.SQL - 문제 풀이, 기초 프로젝트 시작(2)
데이터 분석 22일차https://leetcode.com/problems/percentage-of-users-attended-a-contest/register의 contest_id별 user_id 수를 구하고 Users에서 user_id 수를 구해서 나눠서 백
26.기초 프로젝트 - 인사이트 내기
데이터 분석 23일차H&M 데이터 분석고객 경험과 브랜드의 연결성 \- 고객 분류(충성고객, 잠재 충성 고객,잠재 이탈 고객, 탈퇴 고객 ) \- 충성고객 : FN=1 AND ACTIVE=1(휴면 \- 충성고객 : FN=1 AND ACTIVE=1 \- 잠
27.프로젝트 - 정리 및 ppt 작성 계획
데이터 분석 24일차H&M 회사에 대해 간략한 소개 글로벌 회사, 패스트 패션 업계 선두 주자 데이터 테이블 컬럼 소개 결측치 이상치
28.기초 프로젝트 - 최종 취합
데이터 분석 25일차
29.기초 프로젝트 - 최종 완성
데이터 분석 26일차
30.기초 프로젝트 - 최종
데이터 분석 27일차
31.sql 문제 풀이

데이터 분석 28일차 - sql 문제
32.통계(1) - 분포 정리
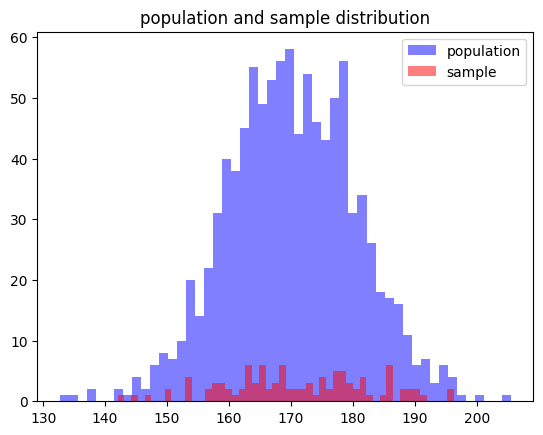
데이터 분석 29일차 - 통계 분포
33.통계(2) - 가설 검정과 주요 검정 기법
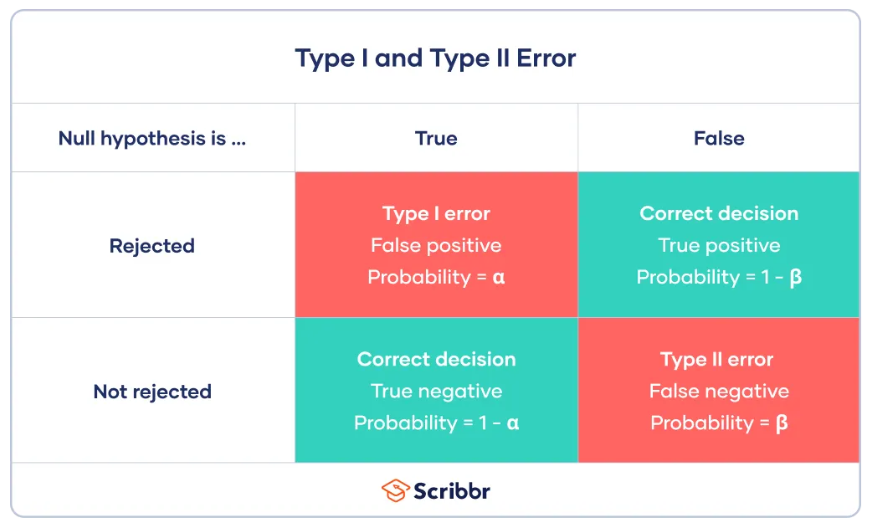
데이터 분석 30일 - 통계(2) : 가설 검정과 주요 검정 기법
34.통계(3) - 회귀 분석: 단순, 다중, 다항, 스플라인
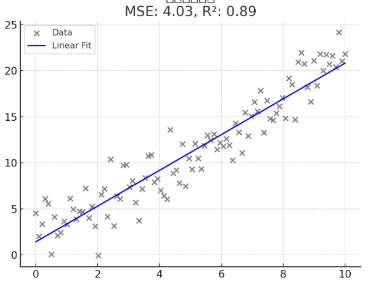
데이터 분석 31일📘 회귀 분석 쉽게 배우기단순선형, 다중선형, 범주형, 다항 및 스플라인 회귀까지!✅ 한 가지 원인(X)이 결과(Y)에 영향을 줄 때 사용.예: 공부 시간(📚)이 점수(📝)에 영향을 줄까?결과: 직선 하나로 설명함.지표MSE: 4.03 (오차가
35.python - melt 함수
python - melt 함수
36.통계(4) - 상관계수 종류
데이터 분석 32일 ✅ 상관계수 - 피어슨, 스피어만, 켄달 타우, 상호정보
37.머신러닝- 3가지 주요 종류
데이터 분석 33일데이터 - 머신러닝 3가지 주요 종류
38.데이터 크기 맞추기! 표준화, 정규화, 로그변환
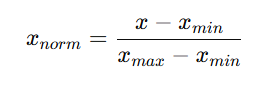
데이터 분석 34일 - 표준화, 정규화, 로그
39.머신러닝 기초 정리(1)
데이터 분석 35일핵심 포인트 요약머신러닝이란?→ 컴퓨터가 데이터로부터 스스로 패턴을 학습해 예측/분류를 수행하는 기술머신러닝 3요소→ 데이터, 알고리즘, 컴퓨팅 파워AI, 머신러닝, 딥러닝의 관계→ 딥러닝은 머신러닝의 하위, 머신러닝은 AI의 하위머신러닝의 주요 분류
40.통계(5) - 분포&상관계수... 헷갈려서 다시 정리
데이터 분석 36일📁 데이터고객 나이이용 시간사용 금액성별자주 오는지 여부 (yes/no)→ 컬럼별 히스토그램 또는 정규성 검정나이 : 종모양 아니고 편향 좀 있음이용시간 : 한쪽으로 치우침사용금액 : 뾰족하거나 치우침→ 결론 : 딱 정규분포는 아님 (많이 왜곡됨)"
41.머신러닝 정리(2) - 앙상블 기법
데이터 분석 37일 \- 💪 여러 모델을 합치면 더 똑똑해진다!✔️ 쉽게 말하면?친구 한 명보다 여러 명이 모여 문제를 풀면 더 정확할 수 있잖아?머신러닝도 같은 원리 → 여러 모델을 모아서 성능을 높이는 방법예시) 🌳 랜덤포레스트(Random Forest) \-
42.머신러닝 정리(3) - 클러스터링
데이터 분석 38일\- 클러스터링 = 비지도학습 대표 선수→ "군집화"라고도 불러.→ 특징 비슷한 애들끼리 자동으로 묶어주는 기술!고객의 나이, 구매 금액, 구매 주기 같은 정보가 쭉~ 들어 있는 데이터가 있다. 그런데 문제는... "누가 VIP인지, 누가 잠재고객인지
43.머신러닝(4) - 차원축소 간단 정리
데이터 분석 39일"너무 어려운 차원축소 간단하게 포인트만 정리해 본다"→ 데이터에 변수가 너무 많으면 이런 문제가 생김처리 오래 걸림노이즈(쓸데없는 변수) 많음그래프로 보기 힘듦→ 그래서 핵심정보만 뽑고 변수 수를 줄여서:깔끔하게 정리빠르게 처리그래프로 보기 쉽게
44.이상치 탐지 방법!
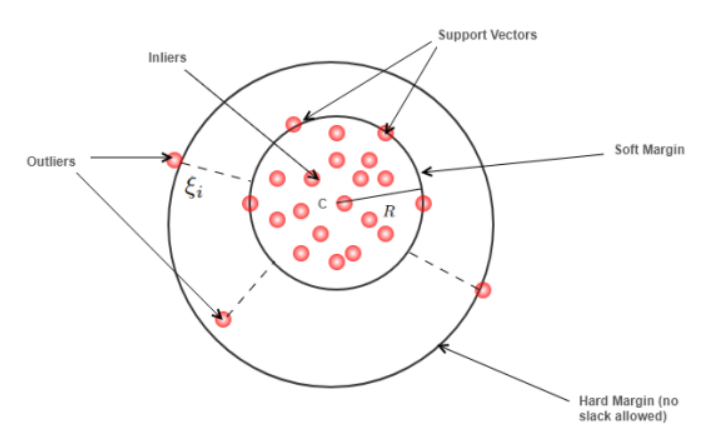
데이터 분석 40일개념: 평균에서 얼마나 떨어져 있는지를 ‘표준편차’ 기준으로 계산공식: 𝑧 = (𝑥-𝜇)/σ(x: 값, μ: 평균, σ: 표준편차)기준: |z| > 3이면 이상치로 간주하는 게 일반적장점: 계산이 빠르고 간단단점: 정규분포 가정이 필요 (데이터가
45.클러스터링(군집) 순서 정리
데이터 분석 41일데이터를 불러오고 확인합니다.결측치(누락된 값)가 있는지 확인하고, 필요에 따라 제거하거나 채워넣기(imputation).중복값 제거와 같은 전처리를 진행.불필요한 변수(컬럼)는 제거.특성 선택: 분석에 필요한 주요 특성(변수)을 선택.정규화/표준화:
46.심화 프로젝트 시작 Day1
데이터 분석 42일
47.심화 프로젝트 시작 Day 2
데이터 분석 43일
48.심화 프로젝트 시작 Day3
데이터 분석 44일
49.심화 프로젝트 시작 Day4
데이터 분석 45일
50.심화 프로젝트 시작 Day5
데이터 분석 46일
51.H&M 데이터 분석 프로젝트: EDA를 통한 인사이트 도출

1. 데이터 소개 1) ERD 2. 분석 방법 ⇨ 결측치 및 이상치 확인 후 제거 ⇨ 전체 고객 및 매출 현황 분석 1) 컬럼 식별화 ✅ transaction_hm 테이블에 price 컬럼 식별화: 원화로 변경 > : 광고 예산 (만원 단위)종속 변수 (Y): 일일 매출 (만원 단위)데이터를 바탕으로 광고 예산이 매출에 미치는 영향을 분석하고, 예측 모델을 만듭니다.✅ 0. import ✅ 1. 데이터 입력 📌 reshape(-1, 1)은 X를
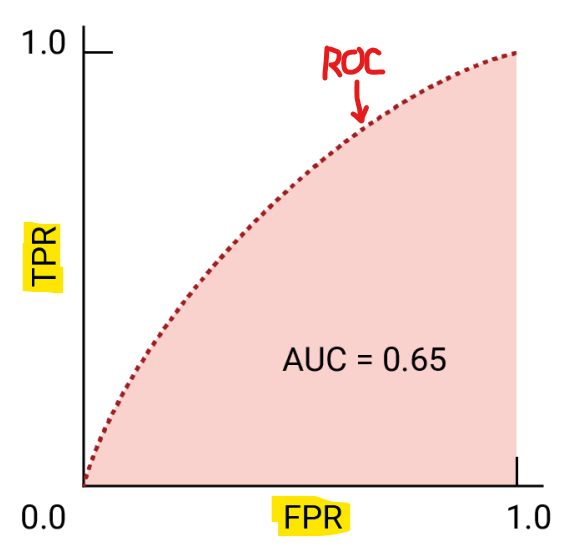
58.머신러닝 - 분류(랜덤 포레스트) 코드
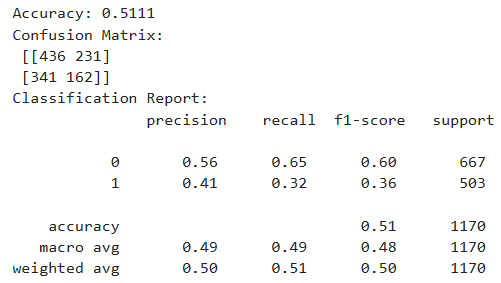
데이터 분석 54일목적: 고객에게 할인이 적용됐는지 여부를 예측하는 분류 문제모델: RandomForestClassifier 사용특징(독립변수): Review Rating, Age, Previous Purchases예측 대상(종속변수): Discount Applied
59.실전 프로젝트 시작 Day1
데이터 분석 55일
60.실전 프로젝트 시작 Day2
데이터 분석 56일
61.실전 프로젝트 시작 Day3
데이터 분석 57일
62.실전 프로젝트 시작 Day4
데이터 분석 58일
63.실전 프로젝트 시작 Day5
데이터 분석 59일
64.실전 프로젝트 시작 Day6
데이터 분석 60일
65.실전 프로젝트 시작 Day7
데이터 분석 61일
66.실전 프로젝트 시작 Day7
데이터 분석 62일
67.실전 프로젝트 시작 Day8
데이터 분석 63일
68.실전 프로젝트 시작 Day9
데이터 분석 64일
69.API와 웹 크롤링의 종류
데이터 분석 65일정의: \- 프로그램 간에 데이터를 주고받기 위한 정식 통로 \- 웹사이트가 서버에서 정보를 꺼내오도록 공식적으로 제공하는 방식예시: \- 날씨 정보를 제공하는 기상청 API에 요청하면, 현재 날씨 데이터를 JSON 형식으로 받을 수 있다.장점:
70.스파크(Spark)
데이터 분석 66일대용량 데이터 처리에 특화된 도구여러 컴퓨터로 나눠서 동시에 처리 가능 (분산처리)파이썬 기반인 Pyspark 사용 → 배우기 쉬움보통 100GB 이상의 데이터 다룰 때한 대의 컴퓨터로 안 돌아갈 때특히 분할이 어려운 데이터 (예: 그래프 데이터)는
71.프로덕트 데이터 사이언스 - 프로덕트 센스
데이터 분석 67일정의: 고객의 니즈를 이해하고, 비즈니스 목표 달성을 위한 제품 전략을 수립하는 능력중요한 이유: \- 사용자 중심 접근: 사용자 불편·니즈 파악 → 제품 개선 아이디어 도출 \- 데이터 기반 의사결정: 제품팀과 협업 → 데이터로 우선순위 설정 및
72.프로덕트 데이터 사이언스 - Metric Diagnosis
데이터 분석 68일정의: 주요 비즈니스 지표(Metric)에 예상치 못한 변동이 발생했을 때, 그 원인을 체계적으로 분석하고 해결 방안을 도출하는 과정목적: 데이터 기반으로 문제를 진단하고, 의사결정 및 액션 플랜을 수립하는 것중요성: 전환율 감소, 사용자 이탈 증가
73.SQLD 자격증 공부
데이터 분석 69일
74.최종 프로젝트 시작
데이터 분석 70일
75.A/B 테스트(설계와 통계적 신뢰) & 최종 프로젝트 Day2
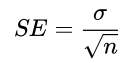
데이터 분석 71일대조군(Control Group): 아무 변화도 주지 않은 그룹실험군(Treatment Group): 새로운 조건을 적용한 그룹평가지표(Metrics): 실험효과를 측정할 수 있는 지준 \- ex) 전환율, 클릭률, 평균 구매 금액 등특정 집단이 과
76.A/B 테스트(p-value및 test 정리) & 최종 프로젝트 Day3
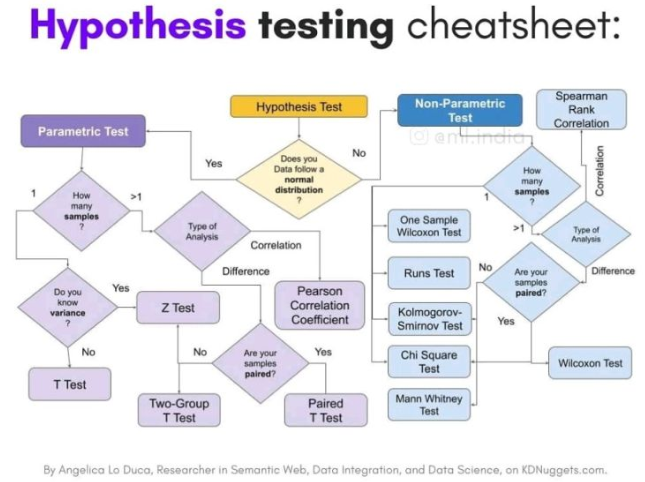
데이터 분석 72일p-value(유의확률)는 "귀무가설(null hypothesis)이 맞다고 가정했을 때, 지금처럼 극단적인 결과가 나올 확률"을 의미.ex) 남녀 평균 급여가 같다는 가설(귀무가설) 하에, 표본에서 150유로 차이가 났다면, p-value는 이런 차
77.최종 프로젝트 Day4
데이터 분석 73일
78.최종 프로젝트 Day5
데이터 분석 74일
79.최종 프로젝트 Day6
데이터 분석 75일
80.최종 프로젝트 Day7 - Category 늪
데이터 분석 76일
81.최종 프로젝트 Day8
데이터 분석 77일
82.최종 프로젝트 Day9
데이터 분석 78일 - 이상치 처리 및 지역 분류
83.최종 프로젝트 Day10
데이터 분석 79일 - 지역 분류
84.최종 프로젝트 Day11
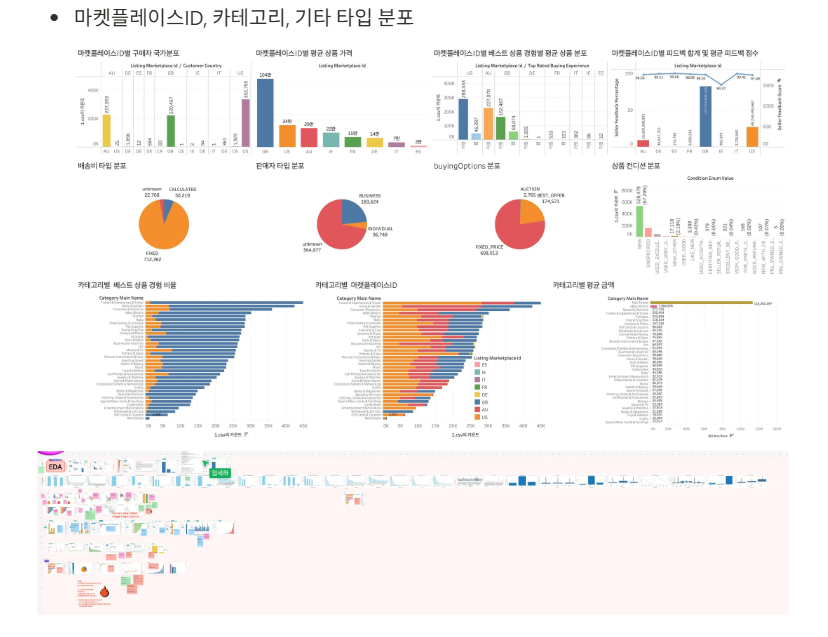
데이터 분석 80일
85.최종 프로젝트 Day12
데이터 분석 81일 크롤링
86.최종 프로젝트 Day13
데이터 분석 82일 오늘도 크롤링 available(제품 재고)와 sold(판매된 제품) 둘다 null 값인...
87.최종 프로젝트 Day14
데이터 분석 83일 - 오늘도 역시 크롤링! & 자료조사
88.최종 프로젝트 Day15
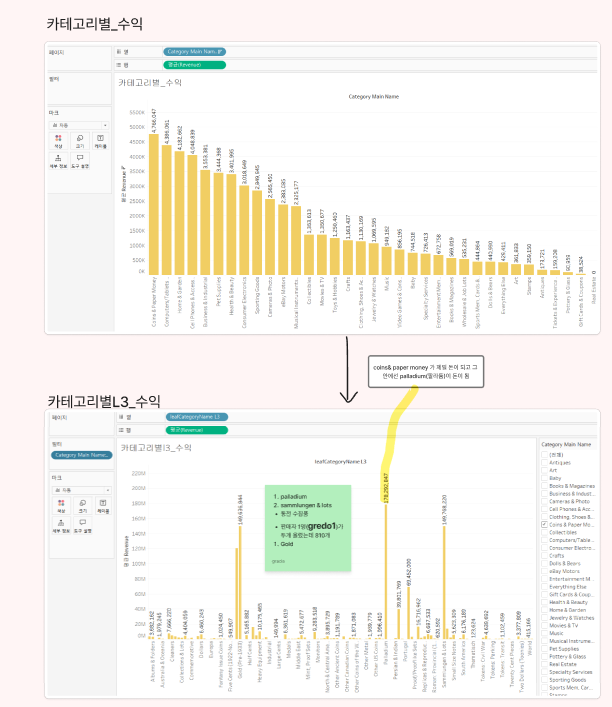
데이터 분석 84일 78만개 크롤링을 완료했는데... eda를 하다보니 이사한 점을 발견함. 데이터에서 확인했을때는 sold_quantity가 1개 인데 URL을 확인해 보니 1,345개가 나옴왜 이런가 코드를 다시 확인해 봤더니 콤마(,)가 있을 경우 콤마 앞 숫자만
89.최종 프로젝트 Day16
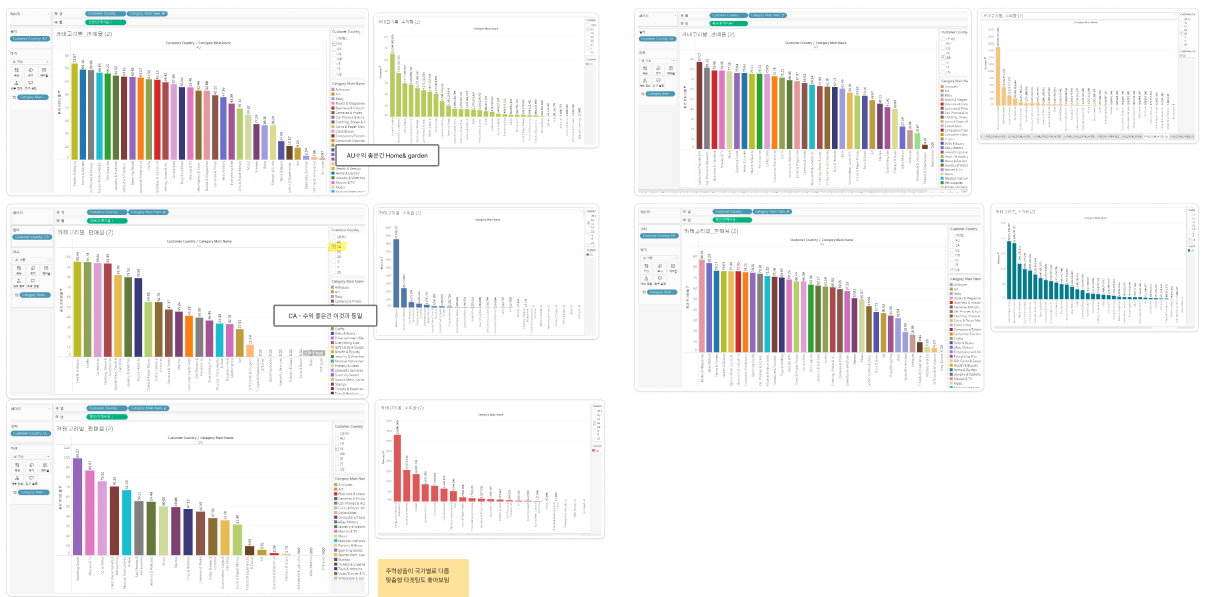
데이터 분석 85일 - 진짜 최종 드디어 최종 데이터셋이 완성되었다. 총 3개의 데이터 비교 분석할 데이터 2개와 원본데이터 1개 오늘은 marketing 데이터가 들어 있지 않고 원본데이터에서 샘플링헤서 약 7만6천개를 뽑아온 데이터로 분석 함. 확실히 avalia
90.최종 프로젝트 Day17
데이터 분석 85일 - EDA 정리 시작
91.최종 프로젝트 Day18
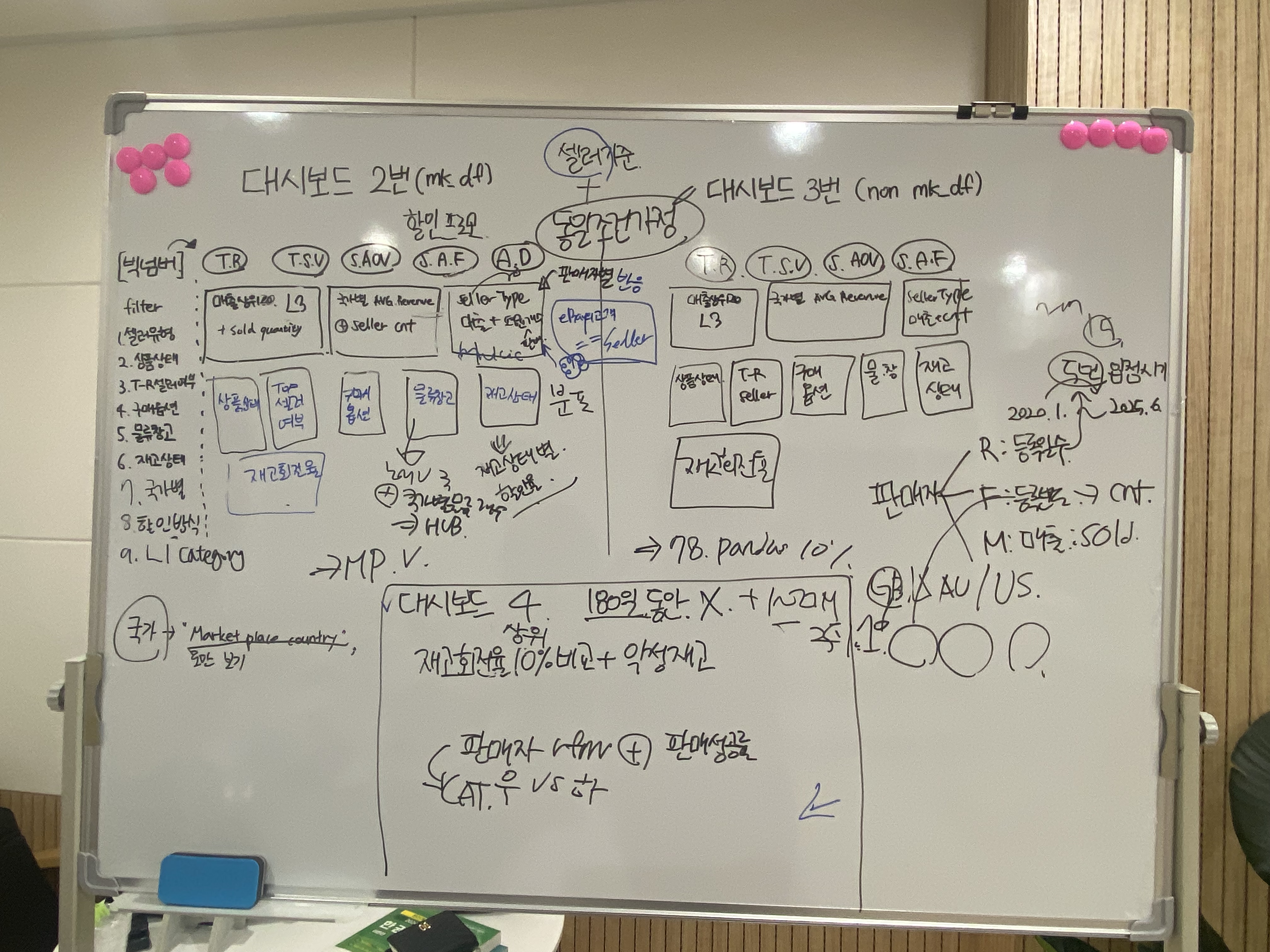
데이터 분석 86일 - 대시보드 구상 시작
92.최종 프로젝트 Day19
데이터 분석 87일 - 대시보드 드로잉 시작
93.최종 프로젝트 Day20

데이터 분석 88일 - 대시보드 무한 수정
94.최종 프로젝트 Day21
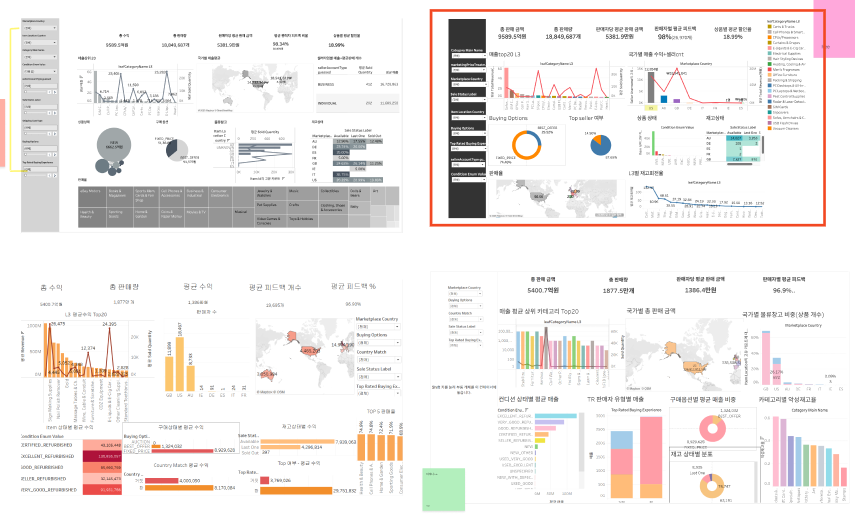
데이터 분석 89일 - 오늘도 대시보드 수정: 그래프도 다양하게 만들봄
95.최종 프로젝트 Day22
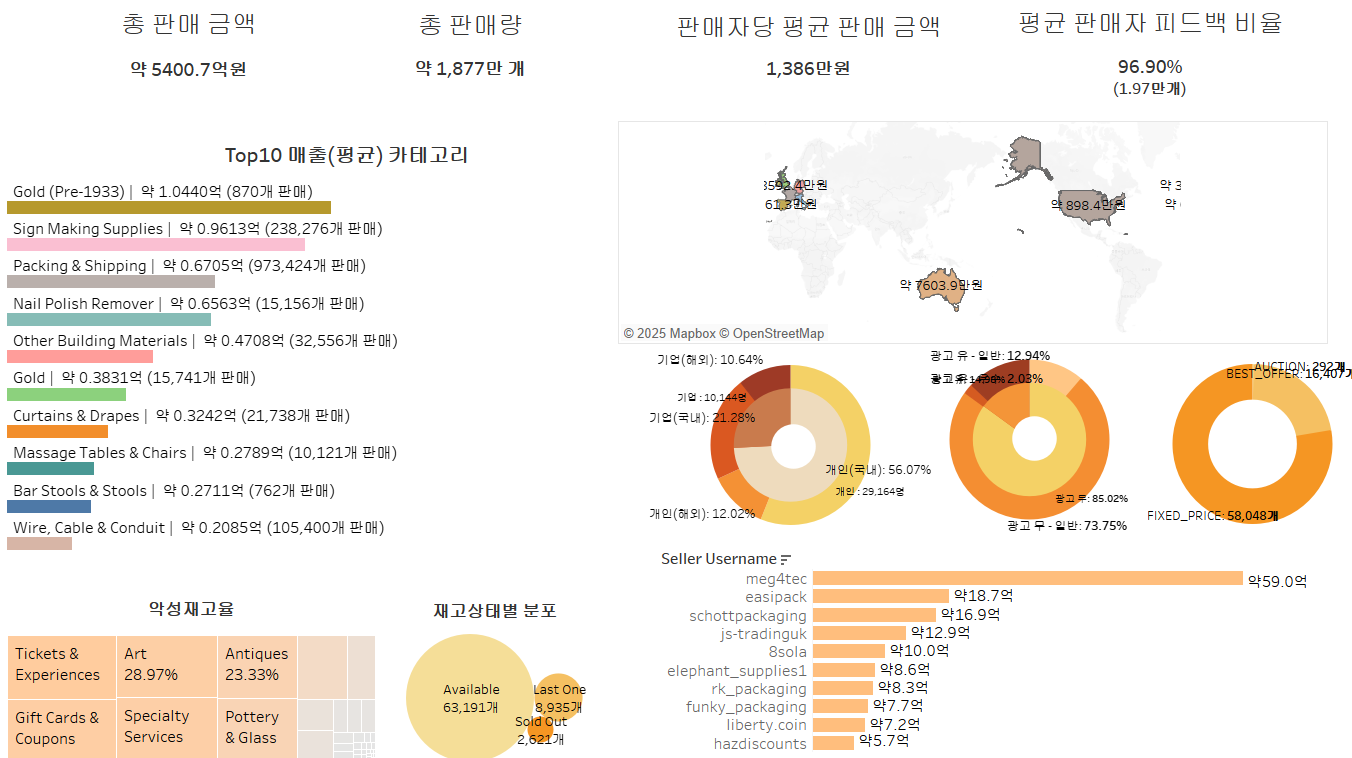
데이터 분석 90일거의 - 최종 대시보드 레이아웃
96.최종 프로젝트 Day23
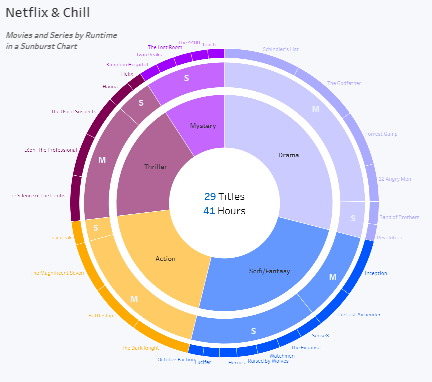
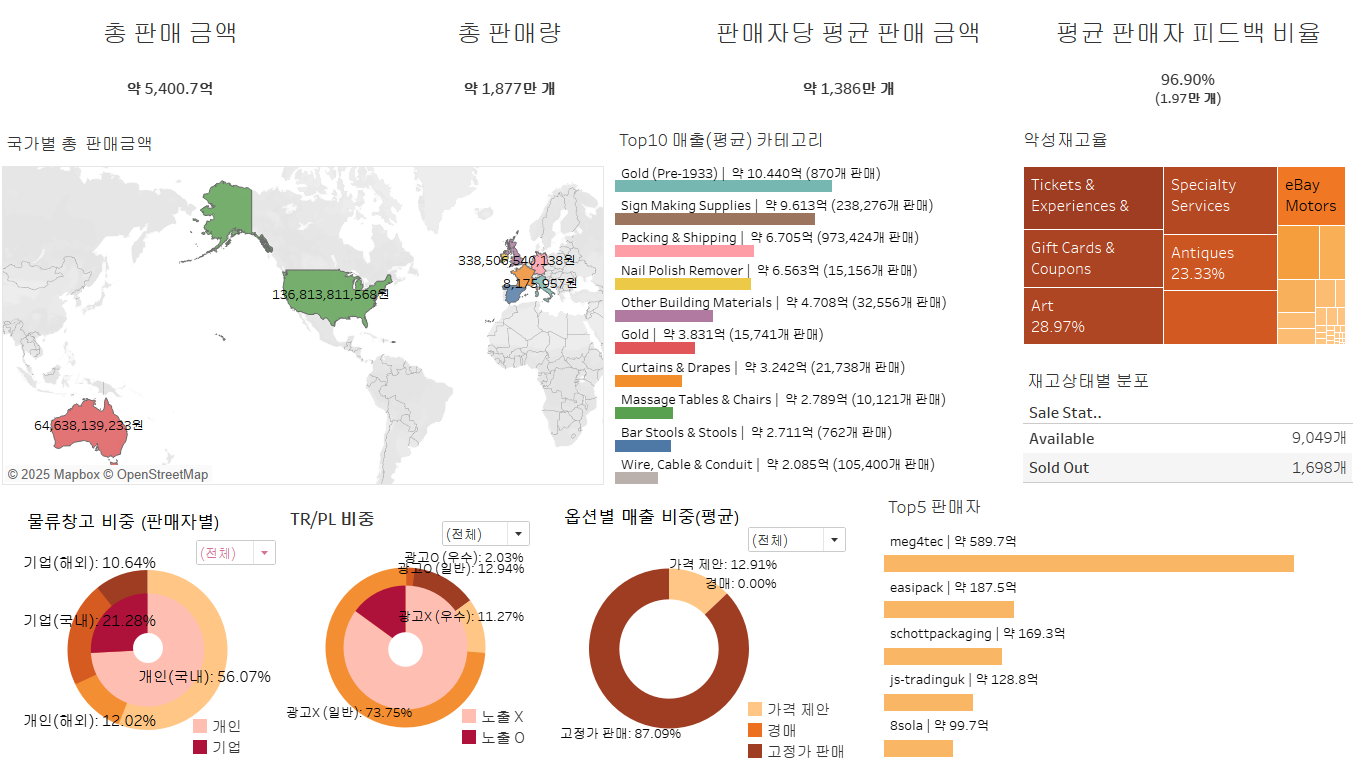
데이터 분석 91일 - 대시보드 레이아웃 및 동작(필터) 완료~!!
97.최종 프로젝트 Day24
데이터 분석 92일 대시보드 정리 어제 끝난줄 알았는데...
98.최종 프로젝트 Day25
데이터 분석 93일 - PPT 작업
99.최종 프로젝트 Day26
데이터 분석 94일 - 드디어 끝~!
100.최종 프로젝트 끝!
데이터 분석 95일 - 최종 프로젝트 끝!!