데이터 분석 40일
📌 1. Z-score (표준점수)
-
개념: 평균에서 얼마나 떨어져 있는지를 ‘표준편차’ 기준으로 계산
-
공식: 𝑧 = (𝑥-𝜇)/σ
(x: 값, μ: 평균, σ: 표준편차) -
기준: |z| > 3이면 이상치로 간주하는 게 일반적
-
장점: 계산이 빠르고 간단
-
단점: 정규분포 가정이 필요 (데이터가 비대칭이면 부적합)
📌 2. IQR (Interquartile Range)
-
개념: 데이터의 중앙 50% 범위를 기준으로 벗어난 값을 이상치로 판단
-
공식:
- IQR = Q3 - Q1
- 하한 = Q1 - 1.5×IQR
- 상한 = Q3 + 1.5×IQR
- 하한보다 작거나 상한보다 크면 이상치 -
장점: 분포 가정 없이 사용할 수 있고, 극단값에 덜 민감
-
단점: 다변량 데이터에는 적용이 어려움 (변수 하나씩만 가능)
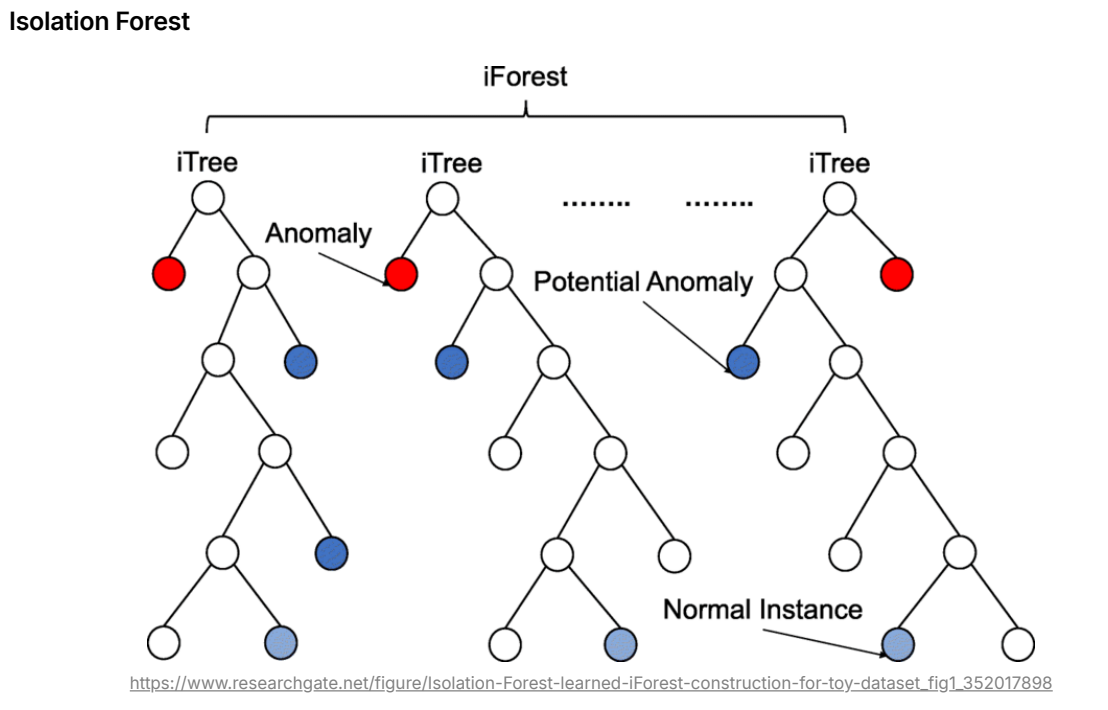
📌 3. Isolation Forest
- 개념: 데이터를 무작위로 분할하면서 빠르게 격리되는 점을 이상치로 간주
- 특징: 랜덤 트리 기반, 대규모 데이터에 빠름
- 장점: 직관적이고 고차원에도 비교적 강함
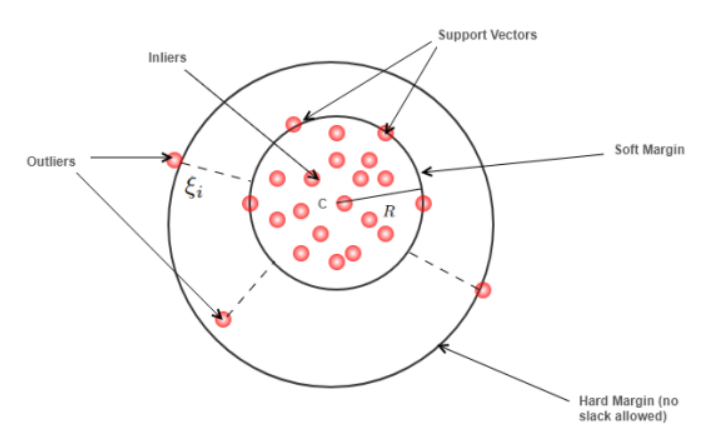
📌 4. One-Class SVM
- 개념: 정상 데이터를 둘러싼 경계를 형성하고, 그 바깥의 점들을 이상치로 간주
- 특징: 커널 기반으로 고차원에 강함, 세밀한 경계 설정 가능
📌 5. LOF (Local Outlier Factor)
- 개념: 주변 이웃들과 비교했을 때 밀도가 상대적으로 낮은 포인트를 이상치로 판단
- 아이디어: 데이터가 밀집된 지역에 비해 혼자 떠 있는 점은 이상치 가능성이 큼
- 장점: 군집 내에서도 이상치를 잘 잡아냄 (비정상 밀도 감지)
- 단점: 거리 기반이라 고차원에서는 성능 저하
❓ 그럼 머신러닝에서는 어떤 방법을 써?
✅ 정답: 데이터와 목적에 따라 달라!
| 상황 | 추천 방법 |
|---|---|
| 단순 수치형, 정규분포 가정 가능 | Z-score |
| 범용적으로 간단하게 확인할 때 | IQR |
| 복잡한 분포, 이상치 패턴이 지역적일 때 | LOF |
| 고차원, 대용량 데이터 | Isolation Forest |
| 비선형 경계가 필요할 때 | One-Class SVM |
✔️ 비지도 학습 기반 방법(LOF, Isolation Forest, One-Class SVM)은 머신러닝 프로젝트에서 자주 쓰임
