데이터 분석 31일
📘 회귀 분석 쉽게 배우기
- 단순선형, 다중선형, 범주형, 다항 및 스플라인 회귀까지!
1. 단순선형회귀 (Simple Linear Regression)
✅ 한 가지 원인(X)이 결과(Y)에 영향을 줄 때 사용.
예: 공부 시간(📚)이 점수(📝)에 영향을 줄까?
결과: 직선 하나로 설명함.
- 지표
MSE: 4.03 (오차가 낮을수록 좋음)
R²: 0.89 (1에 가까울수록 설명 잘함)
🟦 그래프:
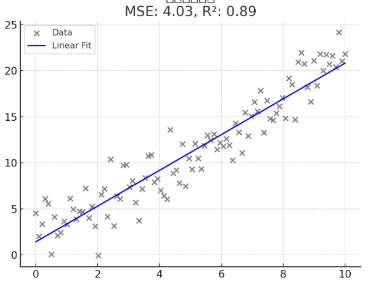
- 회색 점: 실제 데이터
- 파란 선: 예측 직선
→ 데이터가 선에 가까우면 좋은 모델!
🖥️ 코드
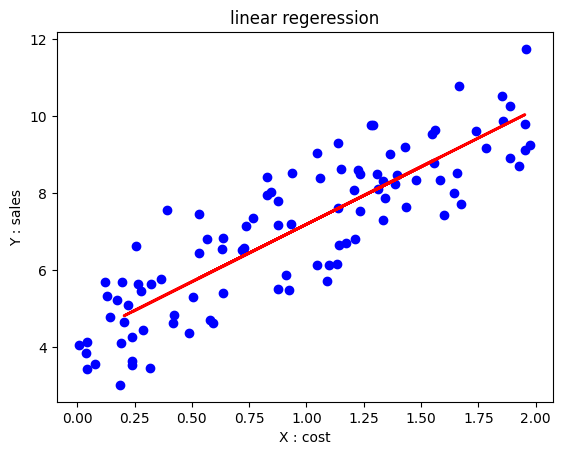
#### ☑️ 하나의 독립변수와 종속변수와의 관계를 분석 및 예측 # #- 광고비(X)와 매출(Y) 간의 관계 분석. #- 현재의 광고비를 바탕으로 예상되는 매출을 예측 가능. # import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error, r2_score # # 예시 데이터 생성 np.random.seed(0) X = 2 * np.random.rand(100, 1) y = 4 + 3 * X + np.random.randn(100, 1) # # 데이터 분할 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # # 단순선형회귀 모델 생성 및 훈련 model = LinearRegression() model.fit(X_train, y_train) # # 예측 y_pred = model.predict(X_test) # # 회귀 계수 및 절편 출력 print("회귀 계수:", model.coef_) print("절편:", model.intercept_) # # 모델 평가 mse = mean_squared_error(y_test, y_pred) r2 = r2_score(y_test, y_pred) print("평균 제곱 오차(MSE):", mse) print("결정 계수(R2):", r2) # # 시각화 plt.scatter(X, y, color='blue') plt.plot(X_test, y_pred, color='red', linewidth=2) plt.title('linear regeression') plt.xlabel('X : cost') plt.ylabel('Y : sales') plt.show()

2. 다중선형회귀 (Multiple Linear Regression)
✅ 여러 원인이 결과에 영향을 줄 때 사용.
예: 공부 시간 + 수면 시간 + 식사량 → 점수에 영향을?
결과: 변수 여러 개로 만든 예측 공식
시각화: 3D 이상이라 그래프는 복잡해서 주로 숫자로 평가
🖥️ 코드
### ☑️ 두 개 이상의 독립 변수와 종속변수와의 관계를 분석 및 예측 # #- 다양한 광고비(TV, Radio, Newspaper)과 매출 간의 관계 분석. #- 현재의 광고비(TV, Radio, Newspaper)를 바탕으로 예상되는 매출을 예측 가능. # # 예시 데이터 생성 data = {'TV': np.random.rand(100) * 100, 'Radio': np.random.rand(100) * 50, 'Newspaper': np.random.rand(100) * 30, 'Sales': np.random.rand(100) * 100} df = pd.DataFrame(data) # # 독립 변수(X)와 종속 변수(Y) 설정 X = df[['TV', 'Radio', 'Newspaper']] y = df['Sales'] # # 데이터 분할 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # # 다중선형회귀 모델 생성 및 훈련 model = LinearRegression() model.fit(X_train, y_train) # # 예측 y_pred = model.predict(X_test) # # 회귀 계수 및 절편 출력 print("회귀 계수:", model.coef_) print("절편:", model.intercept_) # # 모델 평가 mse = mean_squared_error(y_test, y_pred) r2 = r2_score(y_test, y_pred) print("평균 제곱 오차(MSE):", mse) print("결정 계수(R2):", r2)

3. 범주형 변수 (Categorical Variables)
✅ 남/여, 지역, 등급 같은 글자형 변수도 회귀분석에 쓸 수 있음
❗️하지만 숫자로 바꿔야 함 → 더미 변수(dummy variable) 사용
🎯 예시: 성별
성별 더미 값 남 0 여 1
🎯 예시: 지역 (서울/부산/대구)
지역 서울_더미 부산_더미 서울 1 0 부산 0 1 대구 0 0
☝️ 이렇게 바꾸면 회귀 모델에 넣을 수 있다!
🖥️ 코드
### ☑️ 범주형 변수를 찾고 더미 변수로 변환한 후 회귀 분석 수행 # #- 성별, 근무 경력과 연봉 간의 관계. #- 성별과 근무 경력이라는 요인변수 중 성별이 범주형 요인변수에 해당 #- 해당 변수를 더미 변수로 변환 #- 회귀 수행 # # 예시 데이터 생성 data = {'Gender': ['Male', 'Female', 'Female', 'Male', 'Male'], 'Experience': [5, 7, 10, 3, 8], 'Salary': [50, 60, 65, 40, 55]} df = pd.DataFrame(data) # # 범주형 변수 더미 변수로 변환 df = pd.get_dummies(df, drop_first=True) # # 독립 변수(X)와 종속 변수(Y) 설정 X = df[['Experience', 'Gender_Male']] y = df['Salary'] # # 단순선형회귀 모델 생성 및 훈련 model = LinearRegression() model.fit(X, y) # # 예측 y_pred = model.predict(X) # # 회귀 계수 및 절편 출력 print("회귀 계수:", model.coef_) print("절편:", model.intercept_) # # 모델 평가 mse = mean_squared_error(y, y_pred) r2 = r2_score(y, y_pred) print("평균 제곱 오차(MSE):", mse) print("결정 계수(R2):", r2)
4. 다항회귀 & 스플라인 회귀
🔹 다항회귀 (Polynomial Regression)
✅ 관계가 곡선일 때 사용.
- 단순선형회귀는 직선으로 데이터를 설명하지만, 현실 데이터는 직선으로 설명 안 되는 경우가 많음!
- 예: 공부 시간이 너무 많으면 피곤해서 점수가 떨어질 수도 있어 → "U자 곡선"
- 예: 광고를 너무 많이 보면 오히려 거부감 생겨서 효과가 떨어짐 → "역U자 곡선"
- 예: 너무 많이 운동하면 오히려 건강 나빠질 수 있어 → 곡선 필요!
지표
- MSE: 3.41
- R²: 0.91 → 단순선형보다 더 잘 설명함!
🟩 그래프:
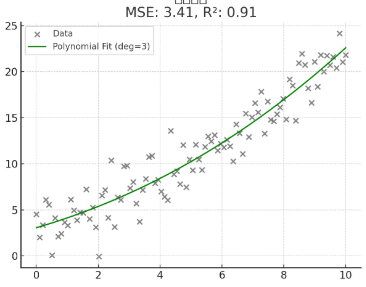
- 회색 점: 실제 데이터
- 녹색 선: 곡선 형태의 예측 결과
🔹 스플라인 회귀 (Spline Regression)
✅ 데이터를 여러 구간으로 나눠서 각 구간마다 곡선을 만들고 부드럽게 연결함.
- 너무 복잡한 데이터를 설명할 때 유용.
✅ 정리용 지표
- 지표 뜻 해석
- MSE 평균제곱오차 낮을수록 좋음 (오차 작음)
- R² 결정계수 1에 가까울수록 좋음 (잘 설명함)
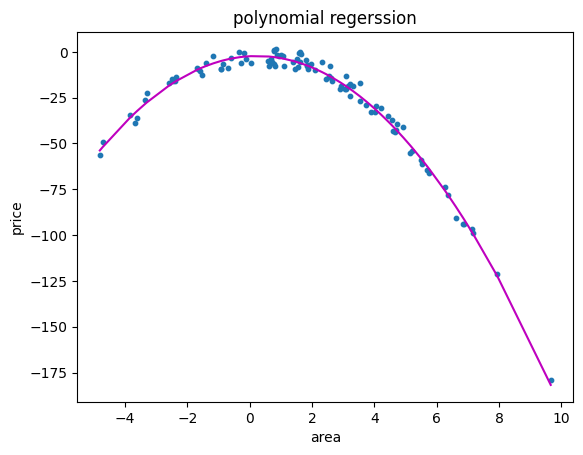
🖥️ 다항회귀 코드
### ☑️ 독립변수와 종속변수의 관계가 비선형 관계일 때 사용 #- 주택 가격 예측(면적과 가격 간의 비선형 관계) # from sklearn.preprocessing import PolynomialFeatures # # 예시 데이터 생성 np.random.seed(0) X = 2 - 3 * np.random.normal(0, 1, 100) y = X - 2 * (X ** 2) + np.random.normal(-3, 3, 100) X = X[:, np.newaxis] # # 다항 회귀 (2차) polynomial_features = PolynomialFeatures(degree=2) X_poly = polynomial_features.fit_transform(X) # model = LinearRegression() model.fit(X_poly, y) y_poly_pred = model.predict(X_poly) # # 모델 평가 mse = mean_squared_error(y, y_poly_pred) r2 = r2_score(y, y_poly_pred) print("평균 제곱 오차(MSE):", mse) print("결정 계수(R2):", r2) # # 시각화 plt.scatter(X, y, s=10) # 정렬된 X 값에 따른 y 값 예측 sorted_zip = sorted(zip(X, y_poly_pred)) X, y_poly_pred = zip(*sorted_zip) plt.plot(X, y_poly_pred, color='m') plt.title('polynomial regerssion') plt.xlabel('area') plt.ylabel('price') plt.show()