데이터 분석 32일
1. 피어슨 상관계수 (Pearson Correlation Coefficient)
✅ 두 숫자형(연속형) 변수 간의 선형 관계를 측정할 때 사용
⭐️ 특징
- -1 ~ +1 사이 값
- +1: 강한 양의 선형 관계
- -1: 강한 음의 선형 관계
- 0: 선형 관계 없음
- 예시
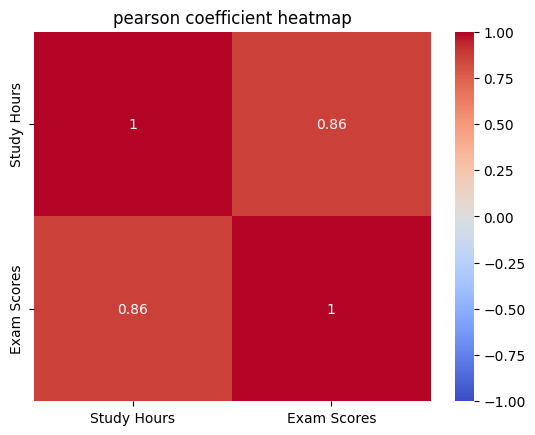
- 공부 시간과 시험 점수 → 공부할수록 점수가 높아지면 +1에 가까움
🖥️ 코드
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from scipy.stats import pearsonr # # 예시 데이터 생성 np.random.seed(0) study_hours = np.random.rand(100) * 10 exam_scores = 3 * study_hours + np.random.randn(100) * 5 # # 데이터프레임 생성 df = pd.DataFrame({'Study Hours': study_hours, 'Exam Scores': exam_scores}) # # 피어슨 상관계수 계산 pearson_corr, _ = pearsonr(df['Study Hours'], df['Exam Scores']) print(f"피어슨 상관계수: {pearson_corr}") # # 상관관계 히트맵 시각화 sns.heatmap(df.corr(), annot=True, cmap='coolwarm', vmin=-1, vmax=1) plt.title('pearson coefficient heatmap') plt.show()
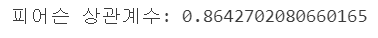
2. 비모수 상관계수 (Non-parametric Correlation)
✅ 정규성 가정 없이도 사용할 수 있으며, 특히 순위(rank) 중심으로 관계를 파악함
- 예시:
- 영화에 대한 평점을 사용자별로 매기고, 이 평점 순위를 비교할 때
→ 사용자 A와 B의 영화 순위가 비슷하다면 높은 상관을 가집니다.
🔹 (1) 스피어만 상관계수 (Spearman's Rank Correlation)
📁 방식
- 데이터를 순위로 변환한 뒤, 피어슨 상관계수를 계산
❓ 언제 사용?
- 비선형 관계지만 순서가 있을 때
- 이상치에 민감하지 않은 분석이 필요할 때
- 예시
- 키 순위와 농구 실력 순위 비교 → 순위가 비슷하면 +1에 가까움
🔹 (2) 켄달의 타우 (Kendall’s Tau)
📁 방식
- 데이터 쌍을 모두 비교해서 순서가 일치하는 쌍(일치)과 일치하지 않는 쌍(불일치)의 비율로 계산
❓ 언제 사용?
- 데이터 수가 적을 때
- 순위 간 미세한 차이도 반영하고 싶을 때
- 예시
- A학생과 B학생이 각각 친구들을 순위 매겼을 때 얼마나 비슷한지 확인
🖥️ 코드
from scipy.stats import spearmanr, kendalltau # # 예시 데이터 생성 np.random.seed(0) customer_satisfaction = np.random.rand(100) repurchase_intent = 3 * customer_satisfaction + np.random.randn(100) * 0.5 # # 데이터프레임 생성 df = pd.DataFrame({'Customer Satisfaction': customer_satisfaction, 'Repurchase Intent': repurchase_intent}) # # 스피어만 상관계수 계산 spearman_corr, _ = spearmanr(df['Customer Satisfaction'], df['Repurchase Intent']) print(f"스피어만 상관계수: {spearman_corr}") # # 켄달의 타우 상관계수 계산 , # _ 부분에 p-value 넣으면 p-value도 구해짐 kendall_corr, _ = kendalltau(df['Customer Satisfaction'], df['Repurchase Intent']) print(f"켄달의 타우 상관계수: {kendall_corr}") # # # 상관관계 히트맵 시각화 sns.heatmap(df.corr(method='spearman'), annot=True, cmap='coolwarm', vmin=-1, vmax=1) plt.title('spearman coefficient heatmap') plt.show()

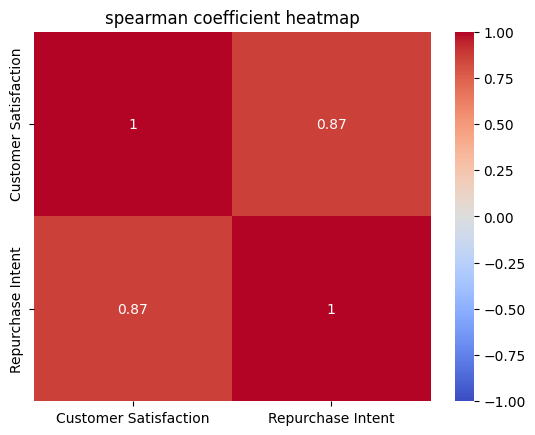
🔸 스피어만 vs 켄달의 타우
| 비교 항목 | 스피어만 | 켄달의 타우 |
|---|---|---|
| 계산 방법 | 순위 → 피어슨 계산 | 쌍 비교 (일치/불일치) |
| 해석 | 직관적이고 빠름 | 좀 더 정밀하고 보수적 |
| 데이터 수 | 많아도 OK | 적을수록 더 안정적 |
| 민감도 | 이상치에 강함 | 순위 간 관계에 더 민감 |
3. 상호정보 상관계수 (Mutual Information)
✅ 변수 간의 비선형 관계나 모든 형태의 의존 관계를 측정할 때 사용
→ 수치형, 범주형 모두 사용 가능
🔎 특징
- 값이 0이면 완전히 독립
- 값이 클수록 의존도 높음
- 예시
- 방문 시간대(오전/오후)와 구매 여부 → 특정 시간대에 구매가 많다면 상호정보 높음
🖥️ 코드
import numpy as np from sklearn.metrics import mutual_info_score # # 범주형 예제 데이터 X = np.array(['cat', 'dog', 'cat', 'cat', 'dog', 'dog', 'cat', 'dog', 'dog', 'cat']) Y = np.array(['high', 'low', 'high', 'high', 'low', 'low', 'high', 'low', 'low', 'high']) # # 상호 정보량 계산 mi = mutual_info_score(X, Y) print(f"Mutual Information (categorical): {mi}")

📑 정리표
| 종류 | 사용 시점 | 특징 | 예시 |
|---|---|---|---|
| 피어슨 | 연속형 변수 간 선형 관계 | 빠르고 일반적 | 공부 시간 vs 시험 점수 |
| 스피어만 | 순위 기반, 이상치 많을 때 | 순위 → 피어슨 계산 | 키 순위 vs 농구 실력 |
| 켄달 타우 | 순위 정밀 비교, 데이터 적을 때 | 일치 쌍 비율 | 친구 순위 비교 |
| 상호정보 | 비선형, 범주형 포함 | 정보량 기반 관계 | 방문 시간대 vs 구매 여부 |
