서울시 CCTV 현황 데이터 분석하며 pandas를 사용해보자!
1. 데이터 읽기
!conda install -y pandas #pands 설치
import pandas as pd
CCTV_Seoul = pd.read_csv('../data/01. Seoul_CCTV.csv', encoding = 'utf-8')
#..은 terminal에서 폴더를 이용할 때 쓰는 명령어로, 현재 폴더에서 하나 상위 폴더로 이동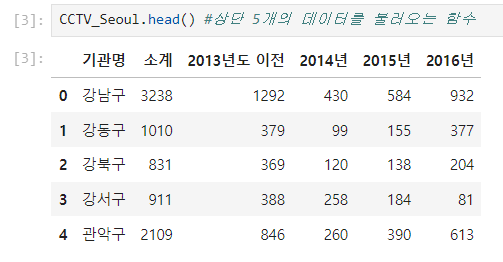
1. read_csvd의 parameters
- sep: str, default ',', 구분자
- index_col: Hashable, Sequence of Hashable or False
2. read_excel 의 parameters
pop_Seoul = pd.read_excel( '../data/01. Seoul_Population.xls', header=2, usecols= 'B, D, G, J, N' )
- head: int, list of int 불러올 행 지정 (원본 파일에서 n+1 행부터 불러옴)
- usecols: str, list-like, collable 불러올 열 지정
- rename(): column 이름 변경
CCTV_Seoul.reaname(columns = {CCTV_Seoul.columns[0] : '구별'}, inplace = True)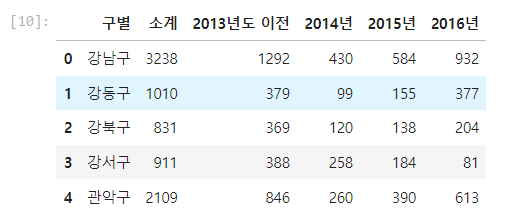
2. Pandas 기초
pandas.Series
1차원 배열과 유사한 데이터 구조로,데이터 값과인덱스(레이블)을 가짐동일한 데이터 타입만 가질 수 있음- 구성요소: index, value
pd.Series([1, 2, 3, 4], dtype=str) #데이터, 데이터 타입 설정
# index 지정하는 방법
pd.Series({"key":"value"})
pd.Series('value', index = 'key')
#동일한 데이터 타입만 가질 수 있음
data = pd.Series([1, 2, 3, 4, '5']) 
pandas.DataFrame
2차원 배열과 유사한 데이터구조로, 여러 개의Series로 구성됨- 각 열은
서로 다른 데이터 타입을 가질 수 있음 - 구성요소: index, value, column
dates = pd.date_range('20210101', periods = 6) #날짜 데이터 생성
import numpy as np
data = np.random.randn(6, 4) #표준정규분포에서 난수 생성, datatype: array
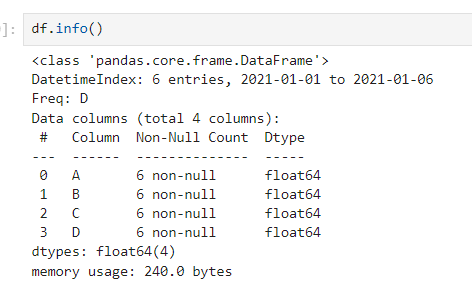
df = pd.DataFrame(data, index = dates, columns = ['A', 'B', 'C', 'D'])
#기본구조: pd.DataFrame(data, index, columns)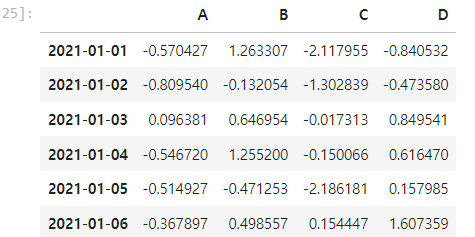
pd.DataFrame()
1) dic 안의 list 형으로 df 만들기left = pd.DataFrame({ 'key' : ['K0', 'K4', 'K2','K3'], 'A' : ['A0', 'A1', 'A2', 'A4'], 'B' : ['B0', 'B1', 'B2', 'B3'] })2) list 안의 dic 형으로 df 만들기
right = pd.DataFrame([ {'key':'K0', 'A':'A0', 'B':'B0'}, {'key':'K4', 'A':'A1', 'B':'B1'}, {'key':'K2', 'A':'A2', 'B':'B2'}, {'key':'K3', 'A':'A4', 'B':'B3'} ])
데이터 정렬: sort_values()
df.sort_values(by = 'B', ascending = False, inplace = True)데이터 선택
df['A']
df.A # 알파벳은 바로 입력 가능, 숫자/기타 문자열은 안됨!
df.[['A', 'B']] # 두 개 이상의 컬럼 선택시 list안에 담아서 선택 가능 df.loc
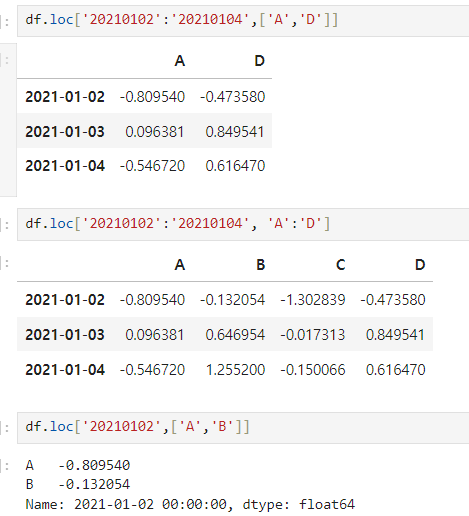
- 기본 구조: df.loc[index, colum]
df.loc['20210102':'20210104',['A','D']] df.loc['20210102':'20210104', 'A':'D'] df.loc['20210102',['A','B']] # series 반환
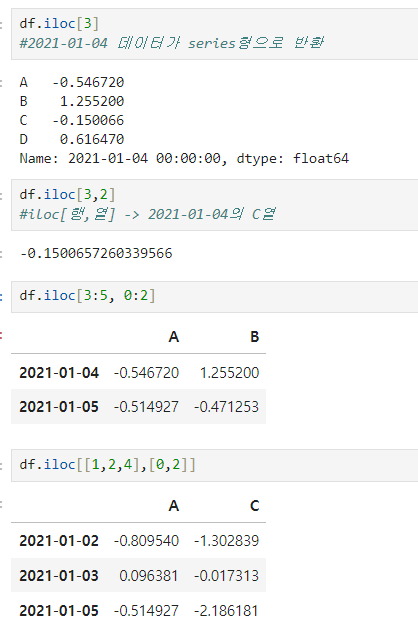
df.iloc
- inter location, 컴퓨터가 인식하는 인덱스값으로 선택
- 기본구조: df.iloc[행, 열]
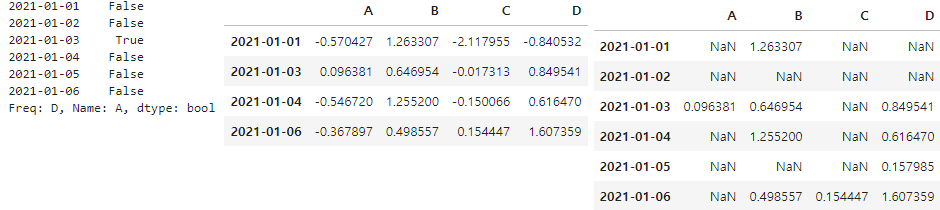
condition
- 특정 조건을 주는 값을 선택함
df['A'] > 0 #A컬럼에서 A보다 큰 숫자만 선택 후, boolean으로 반환 df[df['B'] > 0] #전체 데이터에서 B열이 0보다 큰 값만 선택하여 반환 df[df > 0] #0보다 크지 않은 값은 NaN으로 반환됨
컬럼 추가/제거
#추가: 열 이름과 행 갯수에 맞춰서 각각의 데이터 값을 줌
df['E'] = ['one', 'one', 'two', 'tree', 'four', 'six']
# isin(): 특정 요소가 있는지 확인하여 series를 반환
df['E'].isin(['two'])
#제거: del, drop
del df['E']
df.drop(['D'], axis = 1, inplace = True) #axis = 0: 행 방향, axis = 1: 열 방향
df.drop(['20210104'])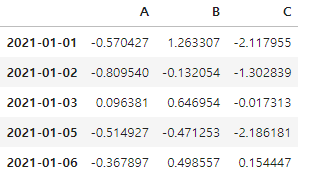

비전공자의 Data Analyst 도전기 🥹✨