Chapter 6
MPI_Isend, MPI_Irecv, MPI_Waitall
1. C code
#include <stdio.h>
#include "mpi.h"
int main()
{
int rank,size,count,i;
float data[100], value[100];
MPI_Request ireq[100];
MPI_Init(NULL, NU**텍스트**LL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank==0){
for (i=0;i<100;i++){
data[i]=1.0*(i+1);
MPI_Isend(&data[i],1,MPI_FLOAT,1,i,MPI_COMM_WORLD, &ireq[i]);
}
} else if(rank==1){
for (i=0;i<100;i++)
MPI_Irecv(&value[i],1,MPI_FLOAT,0,i,MPI_COMM_WORLD, &ireq[i]);
}
MPI_Waitall(100, ireq, MPI_STATUSES_IGNORE);
if (rank==1) printf("value[99]:%f\n",value[99]);
MPI_Finalize();
return 0;
}2. Result

-np 2
- 노드를 2개 쓰는 것을 전제로 작성한 코드
- 만약
-np 3을 했다면, rank 2의 ireq가 지정되지 않았기 때문에MPI_Waitall(100, ireq, MPI_STATUSES_IGNORE);에서 오류 발생
단방향/양방향 통신
1. Undirectional Communication
Blocking Send, Blocking Recv
if (myrank==0){
MPI_Send(sendbuf,icount,MPI_FLOAT,1,itag, MPI_COMM_WORLD);
} else if (myrank==1) {
MPI_Recv(recvbuf,icount,MPI_FLOAT,0,itag, MPI_COMM_WORLD);
}Non-blocking Send, Blocking Recv
if (myrank==0){
MPI_Isend(sendbuf,icount,MPI_FLOAT,1,itag, MPI_COMM_WORLD, ireq);
MPI_Wait(ireq, istatus);
} else if (myrank==1) {
MPI_Recv(recvbuf,icount,MPI_FLOAT,0,itag, MPI_COMM_WORLD,istatus);
}MPI_Isend+MPI_Wait=MPI_Send
Blocking Send, Non-blocking Recv
if (myrank==0){
MPI_Send(sendbuf,icount,MPI_FLOAT,1,itag, MPI_COMM_WORLD);
} else if (myrank==1) {
MPI_Irecv(recvbuf,icount,MPI_FLOAT,0,itag, MPI_COMM_WORLD, ireq);
MPI_Wait(ireq, istatus);
}MPI_Irecv+MPI_Wait=MPI_Recv
Non-blocking Send, Non-blocking Recv
if (myrank==0){
MPI_Isend(sendbuf,icount,MPI_FLOAT,1,itag, MPI_COMM_WORLD, ireq);
} else if (myrank==1) {
MPI_Irecv(recvbuf,icount,MPI_FLOAT,0,itag, MPI_COMM_WORLD, ireq);
}
MPI_Wait(ireq, istatus);MPI_Isend,MPI_Irecv뒤에MPI_Wait를 각각 쓴 것과 동일한 효과MPI_Wait를 if문 바깥에 한 번만 쓰는 것이 코드 효율성 면에서 유리
2. Bidirectional Communication
선 송신, 후 수신 (교착 O)
if(myrank==0){
MPI_Send(sendbuf, …);
MPI_Recv(recvbuf, …);
} else if(myrank==1){
MPI_Send(sendbuf, …);
MPI_Recv(recvbuf, …);
}if(myrank==0){
MPI_Isend(sendbuf, …, ireq, …);
MPI_Wait(ireq, …);
MPI_recv(recvbuf, …);
} else if(myrank==1)
MPI_Isend(sendbuf, …, ireq,…);
MPI_Wait(ireq, …);
MPI_Recv(recvbuf, …);
}MPI_Send()는 blocking communication 함수로, 상황에 따라 전송 방법을 다르게 설정함- message 크기가 작을 때에는 system buffer에
sendbuf를 복사 후 return -> 교착 상태 발생 X - But, message 크기가 클 때에는
sendbuf에서 직접 전송 -> rank 0, rank 1이 모두 send만 함 ->MPI_Recv()로 넘어가지 못하고 교착 - message 크기에 따라 교착 여부 달라짐 = Debugging이 어려움
선 송신, 후 수신 (교착 X)
if(myrank==0){
MPI_Isend(sendbuf, …, ireq, …);
MPI_Recv(recvbuf, …);
MPI_Wait(ireq, …);
} else if(myrank==1){
MPI_Isend(sendbuf, …, ireq, …);
MPI_Recv(recvbuf, …);
MPI_Wait(ireq,…);
}MPI_Isend()는 non-blocking communiation 함수로, 호출 즉시 return- 전송 함수 return 후 바로 data receiving 준비
- message 크기와 관계없이 교착 발생 X
선 수신, 후 송신 (교착 O)
if(myrank==0){
MPI_Recv(recvbuf, …);
MPI_Send(sendbuf, …);
} else if(myrank==1){
MPI_Recv(recvbuf, …);
MPI_Send(sendbuf, …);
}MPI_Recv()는 blocking communication 함수 -> message를 받을 때 까지 다음 단계로 넘어가지 못함- message 크기와 무관하게 교착 발생 O
선 수신, 후 송신 (교착 X)
if (myrank == 0) {
MPI_Irecv(recvbuf, …,ireq, …);
MPI_Send(sendbuf, …);
MPI_Wait(ireq,…);
}
else if(myrank == 1){
MPI_Irecv(recvbuf, …,ireq, …);
MPI_Send(sendbuf, …);
MPI_Wait(ireq, …);
}MPI_Irecv()는 non-blocking communication 함수 -> 호출 후 바로 return되어MPI_Send()로 넘어감- message 크기와 무관하게 교착 발생 X
한쪽은 송신부터, 다른 쪽은 수신부터
if (myrank == 0){
MPI_Send(sendbuf, …);
MPI_Recv(recvbuf, …);
}
else if(myrank == 1){
MPI_Recv(recvbuf, …);
MPI_Send(sendbuf, …);
}- blocking, non-blocking routine 사용과 무관하게 교착 발생 X
권장 코드
if(myrank == 0){
MPI_Isend(sendbuf, …, ireq1, …);
MPI_Irecv(recvbuf, …, ireq2, …);
else if(myrank == 1){
MPI_Isend(sendbuf, …, ireq1, …);
MPI_Irecv(recvbuf, …, ireq2, …);
}
MPI_Wait(ireq1, …);
MPI_Wait(ireq2, …);- 송신, 수신 모두 non-blocking communication 함수 사용
- if문 바깥의
MPI_Wait()으로 수신 확인
3. Deadlock_blocking
C code
#include <stdio.h>
#include "mpi.h"
#define BUF_SIZE (1024)
int main()
{
int nrank,i;
double a[BUF_SIZE],b[BUF_SIZE];
MPI_Init(NULL,NULL);
MPI_Comm_rank(MPI_COMM_WORLD,&nrank);
if(nrank==0) {
MPI_Send(a,BUF_SIZE,MPI_DOUBLE, 1,17,MPI_COMM_WORLD);
MPI_Recv(b,BUF_SIZE,MPI_DOUBLE, 1,19,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
}
else if(nrank==1){
MPI_Send(a,BUF_SIZE,MPI_DOUBLE, 0,19,MPI_COMM_WORLD);
MPI_Recv(b,BUF_SIZE,MPI_DOUBLE, 0,17,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
}
MPI_Finalize();
return 0;
}BUF_SIZE (256),BUF_SIZE (1024)로 message 크기를 다르게 설정 후 각각 실행
Result
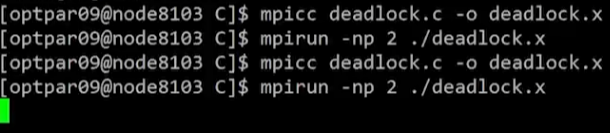
BUF_SIZE (256): 정상적으로 프로그램 종료BUF_SIZE (1024): Deadlock에 걸려 프로그램이 종료되지 못함- Deadlock의 기준이 되는 message 크기는 system에 따라 상이
MPI_Sendrecv, MPI_Sendrecv_replace
1. MPI_Sendrecv
MPI_Sendrecv()
MPI_Sendrecv(sendbuf, sendcount, sendtype, dest, sendtag, recvbuf, recvcount, recvtype, source, recvtag, comm, status);- sending과 receiving이 결합된 형태
- 프로세스들 사이의 shift operation 실행에 유리
ex. rank0->rank1, rank1->rank2, rank2->rank3... - argument는
MPI_Send()와MPI_Recv()의 것들과 동일함
Example: C code
#include <stdio.h>
#include "mpi.h"
int main()
{
int myrank, A[4]={0,},B[4]={0,},inext,iprev, i;
MPI_Init(NULL,NULL);
MPI_Comm_rank(MPI_COMM_WORLD,&myrank);
A[myrank]=myrank+1;
inext=myrank+1, iprev=myrank-1;
if(myrank==0) iprev=3;
if(myrank==3) inext=0;
if(myrank==0) printf("Before\n");
for(i=0;i<4;i++)
if(myrank==i) printf("Myrank: %d, A=%d %d %d %d\n",myrank,A[0],A[1],A[2],A[3]);
MPI_Sendrecv(&A[myrank],1,MPI_INT,inext,0,&B[myrank],1,MPI_INT,iprev,0, \
MPI_COMM_WORLD,MPI_STATUS_IGNORE);
if(myrank==0) printf("After\n");
for(i=0;i<4;i++)
if(myrank==i) printf("Myrank: %d, B=%d %d %d %d\n",myrank,B[0],B[1],B[2],B[3]);
MPI_Finalize();
return 0;
}- circular하게 인자를 전달하는 코드
- rank0, rank3은
if(myrank==0) iprev=3;,if(myrank==3) inext=0;으로 설정
Example: Result
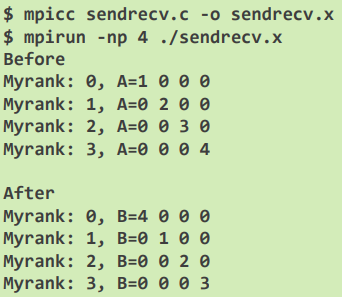
- sendbuf
A[], recvbufB[]각각 출력
2. MPI_Sendrecv_replace
MPI_Sendrecv_replace()
MPI_Sendrecv_replace(buf, count, datatype, dest, sendtag, source, recvtag, comm, status);- sending과 receiving이 결합된 형태
- 송/수신에서 동일한 버퍼 사용
- 메모리 관리 차원에서, 버퍼를 하나 덜 쓰기 때문에 메모리 절약을 할 수 있음
Example: C code
#include <stdio.h>
#include <mpi.h>
int main()
{
int myrank, a,inext,iprev,i;
MPI_Init(NULL,NULL);
MPI_Comm_rank(MPI_COMM_WORLD,&myrank);
a=myrank+1;
inext=myrank+1, iprev=myrank-1;
if(myrank==0) iprev=3;
if(myrank==3) inext=0;
for(i=0;i<4;i++)
if(myrank==i) printf("Before myrank: %d, a=%d\n",myrank,a);
MPI_Sendrecv_replace(&a,1,MPI_INT, inext, 0, iprev, 0, MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
for(i=0;i<4;i++)
if(myrank==i) printf("After myrank: %d, a=%d\n",myrank,a);
MPI_Finalize();
return 0;
}MPI_Sendrecv()예시의 송수신 함수만MPI_Sendrecv_replace()으로 변경
Example:Result

MPI_Sendrecv_replace()를 사용하여 Before와 After의 출력 배열이a[]로 동일함

올해는 진짜 갓생 산다