Chapter 6
Reduction
1. Inner Product 개선
기존 코드
#pragma omp parallel private(local_sum)
{
local_sum=0;
#pragma omp for
for(i=0; i<N; i++)
local_sum+=a[i]*b[i];
#pragma omp atomic
sum+=local_sum;
} - 루프 병렬화 & atomic 동기화 사용
Reduction 활용 코드
#pragma omp parallel for reduction (+:sum)
for(i=0; i<N; i++)
sum+=a[i]*b[i];- Reduction 연산 활용
- 병렬적으로
a[i]*b[i]을 계산하여sum으로 취합
2. 내부 구조
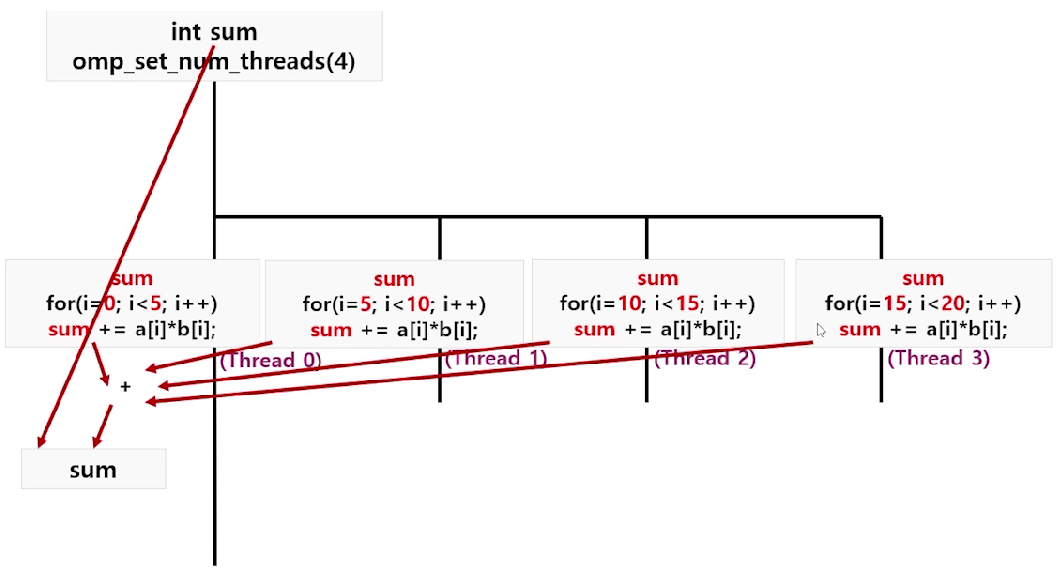
스레드 내부
- 루브 병렬화(for문)에 의해 N이 자동적으로 4개의 스레드에 분할됨
- 각 스레드에서 sum을 각각 계산
스레드 외부
- 각 스레드의 계산값을 취합 -> Reduction
reduction (+:sum)-> 취합 연산 == '+'
Reduction 연산자 (C)

- 주로 +, *를 사용하며, 비트 연산도 가능
- 여러 병렬 프로그램에 많이 쓰임
Inner Product 성능 비교
1. 성능 비교 함수
omp_get_wtime
#include <omp.h>
...
double stime, etime;
...
stime=omp_get_wtime();
//Computing..
etime=omp_get_wtime()-stime;
printf("Elapsed Time: %lf sec.\n", etime);- 특정 지점에서 경과된 wall clock time을 초 단위로 변환
2. Case 목록
Case 1: serial code
#define N 10000000
...
stime=omp_get_wtime();
for(i=0; i<N; i++)
sum+=a[i]*b[i];
etime=omp_get_wtime() - stime;Case 2: critical
stime=omp_get_wtime();
#pragma omp parallel
{
#pragma omp for
for(i=0; i<N; i++)
#pragma omp critical
sum+=a[i]*b[i];
}
etime=omp_get_wtime() - stime;Case 3: atomic(루프 내부)
stime=omp_get_wtime();
#pragma omp parallel
{
#pragma omp for
for(i=0; i<N; i++)
#pragma omp atomic
sum+=a[i]*b[i];
}
etime=omp_get_wtime() - stime;Case 4: atomic(루프 외부)
stime=omp_get_wtime();
#pragma omp parallel private(local_sum)
{
local_sum=0;
#pragma omp for
for(i=0; i<N; i++)
local_sum+=a[i]*b[i];
#pragma omp atomic
sum += local_sum;
}
etime=omp_get_wtime() - stime;Case 5: reduction
stime=omp_get_wtime();
#pragma omp parallel for reduction (+:sum)
for(i=0; i<N; i++)
sum+=a[i]*b[i];3. Result
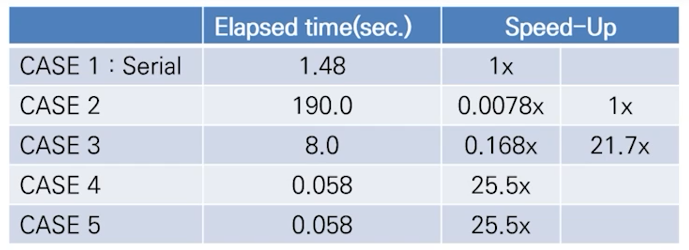
최고 성능
- reduction을 사용한 케이스가 가장 성능이 좋음
- case 4 == case 5를 풀어서 코드화 해둔 것
- Reduction을 사용했을 때, 최소한의 코드 수정으로 최대의 성능 확보
최저 성능
- critical 변수를 for문 내부에 쓰면 for문 수행마다 syncronization이 이루어져 매우 느림
- atomic이 critical보다 성능이 좋음, but 이것마저 serial code보다 훨씬 느림 -> for문 내부에 쓰지마라
주의 사항
- 스레드를 무조건 많이 쓴다고 성능 향상? X
- 하드웨어마다 최적화된 스레드 수 사용할 것

올해는 진짜 갓생 산다