Chapter 10
다중 루프 병렬화: collapse
1. Collapse
개요
#pragma omp for collapse(loop 개수)로 정의 후 사용- 중첩 loop문을 이용하기 위해 사용
- 병렬화 효율성 향상 기대
중첩 loop문
- Nested Parallel: fork-join의 발생으로 인한 부하 -> 성능 저하
- 루프 각각에
#pragma omp for사용: syntax error - collapse 보조 지시어 사용: recommended!
2. Example
C code
#include <stdio.h>
#include <omp.h>
#define N 10000
int main()
{
int a[N][N], i, j;
omp_set_num_threads(4);
#pragma omp parallel for private(i,j) collapse(2)
for (i=0; i<N; i++)
for (j=0; j<N; j++)
a[i][j] *= 2;
}사용
- 중첩 루프문 영역에
#pragma omp parallel for collapse()선언 - 바깥 루프의 작업량이 적고, 안쪽 루프의 작업량이 많은 경우에 collapse를 쓰면 성능 향상이 더 확실하게 보임
Flush, False Sharing
1. Example (Flush)
C code
#include <stdio.h>
#include <omp.h>
#include <unistd.h>
int main()
{
int x=0;tid;
omp_set_num_threads(4);
#pragma omp parallel private(tid)
{
tid=omp_get_thread_num();
if (tid==0) {
sleep(3);
x=1;
sleep(3);
}
while (x==0) {
}
printf("x=%d in %d-th thread\n",x,tid);
}
}Result
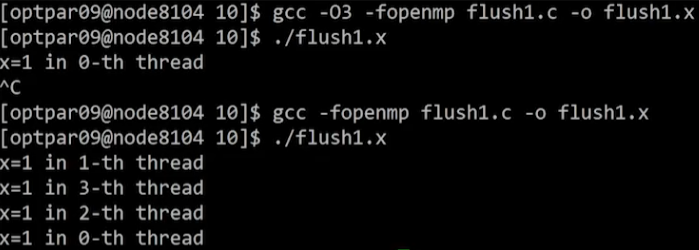
- 최적화 옵션에 따라 결과가 달라짐
- 컴파일 시
-O3최적화 옵션을 넣은 경우, while문을 스레드 1~3이 빠져나오지 못함
해석

- 최적화 옵션이 없는 경우, 메모리의 x값을 매 반복마다 읽어옴
-O3옵션은 성능 향상을 위해 x를 캐시에 저장해두고 읽기 때문에 메모리에서의 x 변화를 인지하지 못함
2. Flush
FLUSH Directive
- 메모리 펜스의 역할을 수행
- 컴파일러는 R/W 순서를 reordering 하지 않음
사용
while (x==0) {
#pragma omp flush(x)
}- x를 캐시에서 읽지 않고 메모리에서 직접 읽어오라는 지시어
#pragma omp flush(x)사용 후 컴파일 시, 스레드 1~3이 정상적으로 while문 탈출
3. False Sharing
원인
- 멀티 코어 CPU에서 캐시 일관성을 유지해야 함 -> 성능 저하 발생
- RAM에 있는 데이터를 Cache로 가져올 때, 그 변수의 크기만큼 가져오는 것이 아니라 캐시라인 크기인 연속된 64바이트의 크기를 한꺼번에 캐시에 올림
- 병렬 처리에서 False Sharing에 의한 부하 -> 함수 수준에서 6~7배, 어플리케이션 수준에서는 2배 정도의 성능 저하 발생
해결
- False Sharing이 발생할 변수를 private 선언
4. Example 1 (False Sharing)
C code
#include <stdio.h>
#include <omp.h>
#define N 10000000
int main()
{
long sum=0; a[4]={0}, i, tid;
omp_set_num_threads(4);
#pragma omp parallel private(tid)
{
tid=omp_get_thread_num();
#pragma omp for
for (i=1; i<=N; i++)
a[tid]+=i;
#pragma omp atomic
sum += a[tid];
}
printf("sum = %ld\n",sum);
}Result
- Serial Code보다 Parallel Code가 7배 정도 느림
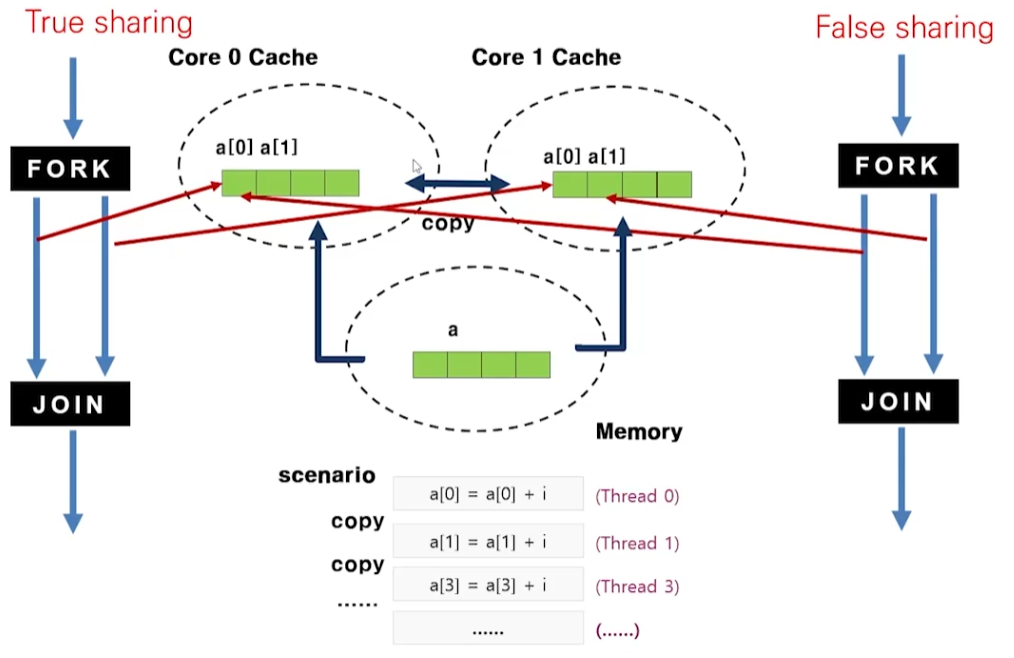
- False Sharing: 각 스레드에서 지정된 원소 a[tid]만 접근
(각 스레드가 모두 a[i]에 접근하는 형태라면 True Shring) - 시스템은 캐시 일관성을 위해 멀티 코어의 Cache를 copy를 통해 지속적으로 동기화시킴 -> 성능 저하
- 각 스레드가 각기 다른 부분을 접근하는 상황에서는 캐시 일관성이 필요 없기 때문에 조치 필요
4. Example 2 (False Sharing Avoidance)
C code
#include <stdio.h>
#include <omp.h>
#define N 10000000
int main()
{
long sum=0; a[4*8]={0}, i, tid;
omp_set_num_threads(4);
#pragma omp parallel private(tid)
{
tid=omp_get_thread_num();
#pragma omp for
for (i=1; i<=N; i++)
a[tid*8]+=i;
#pragma omp atomic
sum += a[tid*8];
}
printf("sum = %ld\n",sum);
}Result
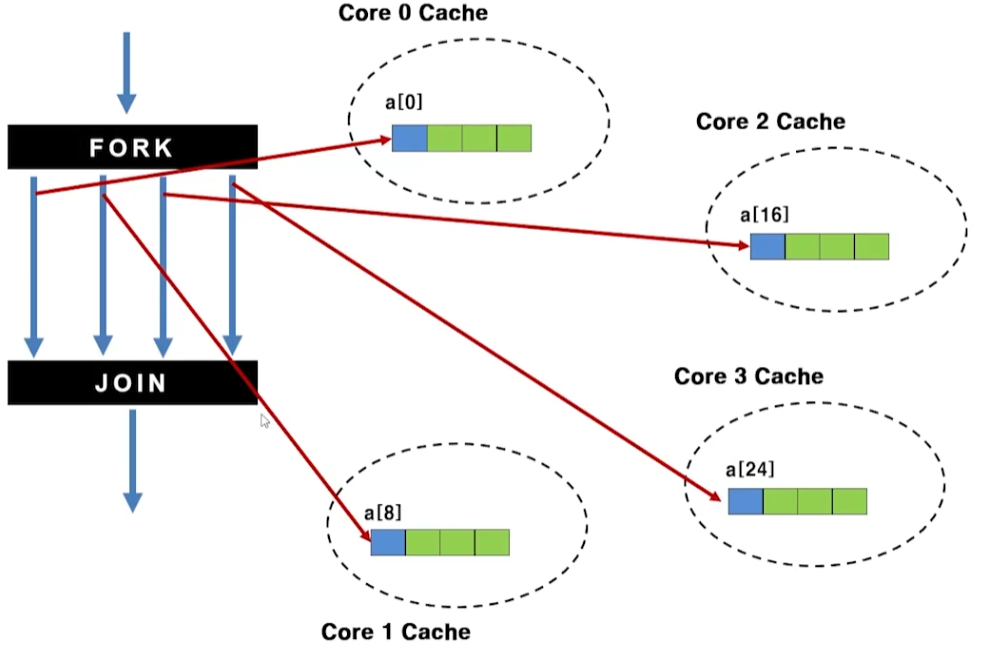
- a[]의 길이가 길어져 각 코어의 Cache에 나누어 저장됨
- False Sharing이 일어나지 않아 Serial Code보다 약 3배 빨라짐
- 사실 해당 예제에서는 그냥 reduction을 사용하면 됨
Data Dependency
1. 데이터 의존성
개요
- 서로 다른 문장이 동일한 메모리 위치에 접근(racing)할 때 발생
- Loop-carried 데이터 의존성
대상
- shared 변수에서만 발생
- 루프에서 read만 되는 변수에는 의존성 문제 없음
- 한 번의 반복에서만 접근되는 변수에는 의존성이 없음
- 여러 반복에서 Read, Write 되는 shared 변수에서 발생
2. Loop-carried 의존성
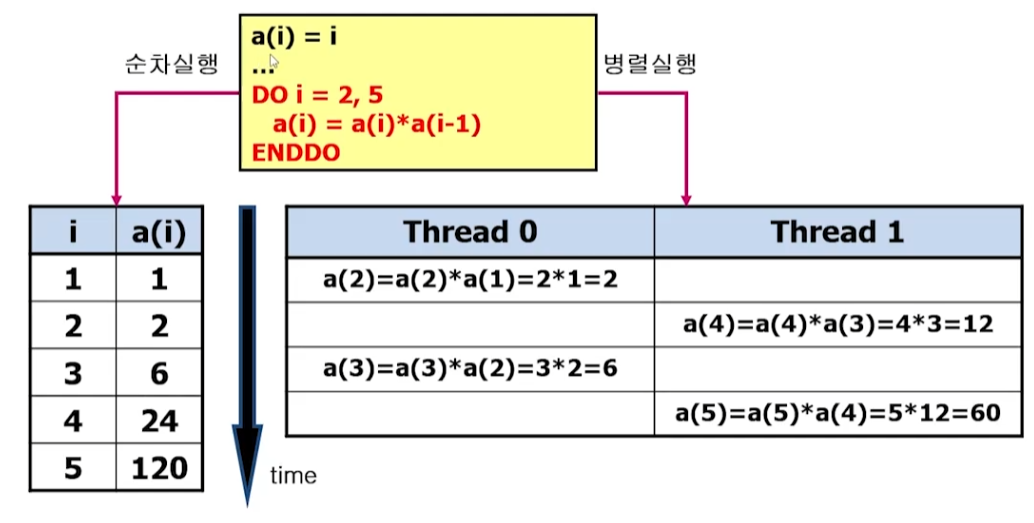
flow 의존성(true dependence or RAW)
- 순차 실행에서 S1 -> S2의 순서로 실행될 때
- S1: a(2) = a(1) + b(2) (write)
- S2: a(3) = a(2) + b(3) (read)
- S1이 write, S2가 read (RAW)
anti 의존성
- S1이 read, S2가 write(WAR)
output 의존성
- S1, S2 모두가 write (WAW)
3. Example (Loop Carried 의존성)
C code
for (i=0; i<N; i++)
x = d[i] + 1
a[i] = a[i+1] + x
b[i] = b[i] + b[i-1] + d[i-1]
c[2] = 2*i해석
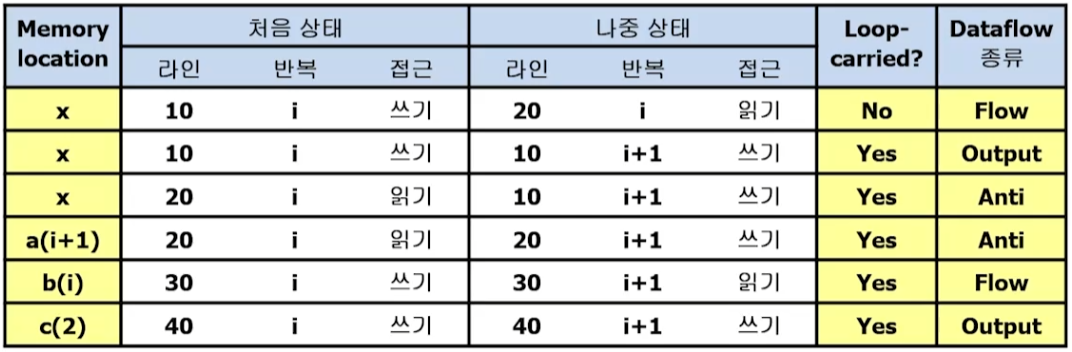
4. 데이터 의존성의 제거
의존성 제거
- 데이터 유효 범위 변경
- 간단한 소스코드의 변경
- anti, output 의존성은 항상 제거 가능
- flow 의존성은 제거 가능할 수도 불가능할 수도 있으며, 근본적인 알고리즘 변경이 요구될 수도 있음
주의
- 의존성 제거 과정에서 가급적 다른 의존성에 영향 주지 말 것
- flow 의존성이 제거 불가능한 경우, 병렬처리도 불가능함

올해는 진짜 갓생 산다