Chapter 9
Scheduling
1. Scheduling clauses
개요
- 루프 실행의 분배 방식을 지정
- 기본적인 schedule 정책: 실행 회수 균등 분배
- 작업의 schedule를 지정하기 위해 schedule clause를 사용
Static [, chunk_size]
- 반복 실행이 각 스레드에 균일하게 할당
chunk_size가 주어진 경우, 총 반복 실행 회수를 chunk_size로 나누어 chunk 생성- 이후, chunk들을 스레드에 라운드-로빈 방식으로 정적 할당
- 연산 횟수가 스레드 수로 나누어 떨어지지 않으면, 처리를 먼저 끝낸 스레드가 추가 실행
Dynamic [, chunk_size]
- 총 반복 실행 회수를
chunk_size로 나누어 chunk 생성 - chunk들은 스레드에 동적 할당(먼저 작업이 끝나는 스레드 우선)
chunk_size가 없으면 디폴트 chunk_size=1- load balancing 면에서 유리
- 계산량이 달라지는 경우, dynamic scheduling이 유리
Guided [, chunk_size]
- Dynamic scheduling
- 반복을 진행하면서, chunk 크기가 변함 (default = 1)
Runtime
$ export OMP_SCHEDULE="static,1000"
$ export OMP_SCHEDULE="dynamic"- 프로그램 실행 중 환경 변수 OMP_SCHEDULE 값을 참조
- 재 컴파일 없이 다양한 스케줄링 방식 시도 가능
Auto
- OpenMP 3.0 이상 지원
- 컴파일러, 실시간 시스템이 가장 적합하다고 판단하는 스케줄링 설정
- gcc 컴파일러는 Auto 사용 시 보통 static으로 지정
2. 비교
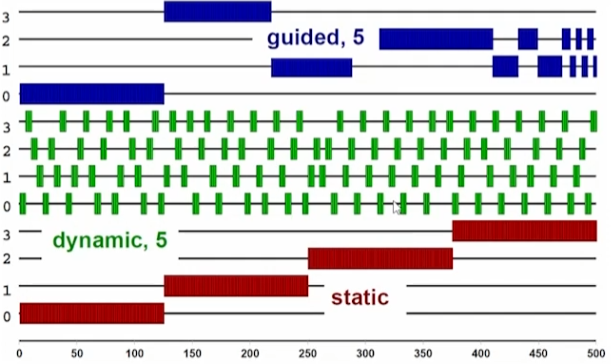
- static: 작업을 스레드 개수만큼 나누어 할당
- dynamic: chunk_size=5인 chunk를 먼저 작업이 끝나는 스레드 우선으로 동적 할당
- guided: dynamic과 비슷하나, chunk_size가 점차 줄어듦
Task, Taskwait
1. 명시적 task
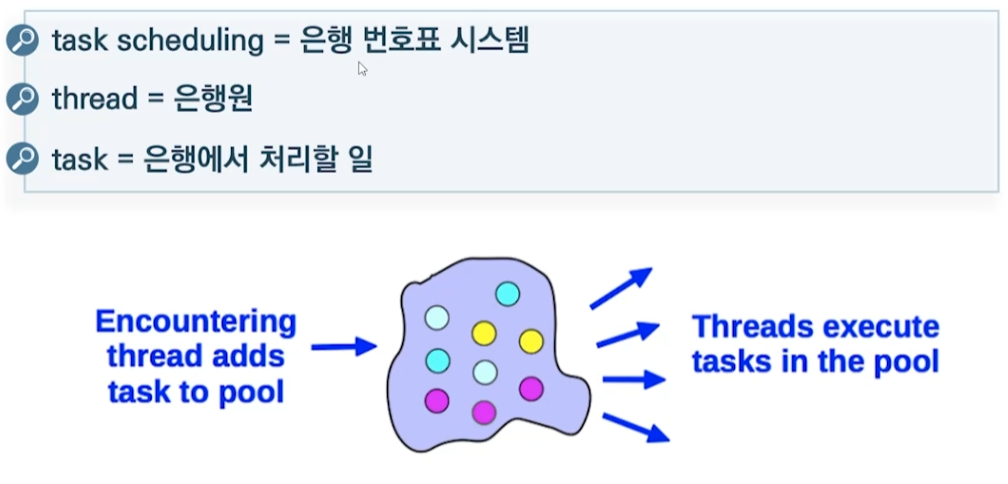
(암시적) task
- 스레드 팀 발생
- 팀 내의 각 스레드에 task 하나씩 할당
- 모든 task 종료될 때 까지 마스터 스레드 대기
개요
- OpenMP 3.0부터 제공
- 병렬화가 힘들었던 while루프, C++ iterator, recursion 병렬화 가능
- task 지시어는 수행해야 할 코드를 작업 큐에 넣는 동작 수행
사용
- 스레드 팀과 작업 큐(queue) 연결(binding)
- 작업 큐에 있는 코드들을 스레드 팀이 순서대로 실행
- task를 작업 큐에 넣는 동작을 할 때는 병렬 영역에서 다수의 스레드 동작, 동기화 문제 발생 가능 ->
#pragma omp single로 해결
Task Construct
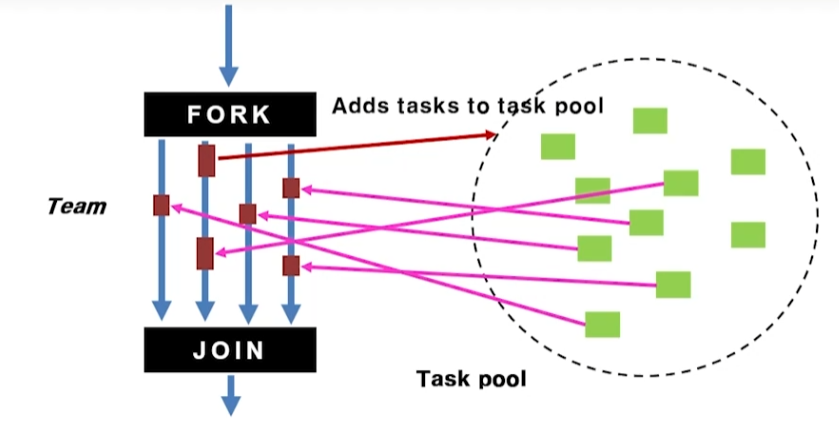
- Task는 수행할 코드를 작업 큐에 넣는 동작을 함
- 작업 큐에 있는 작업들은 수행 가능한 스레드에 의해 순서대로 실행
2. Task Example
C code
#include <stdio.h>
#include <omp.h>
int main()
#pragma omp parallel num_threads(32)
{
#pragma omp single
{
printf("A tid=%d\n", omp_get_thread_num());
#pragma omp task
{
printf("B tid=%d\n", omp_get_thread_num());
}
#pragma omp task
{
printf("C tid=%d\n", omp_get_thread_num());
}
printf("D tid=%d\n", omp_get_thread_num());
}
}
}Result
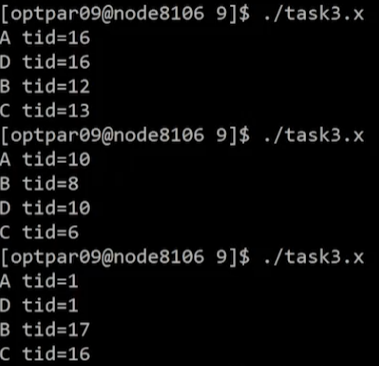
#pragma omp single내의 작업인 A,D는 항상 똑같은 스레드가 출력#pragma omp task로 queue에 넘긴 작업인 B,C는 실행마다 각기 다른 스레드에서 출력
Taskwait
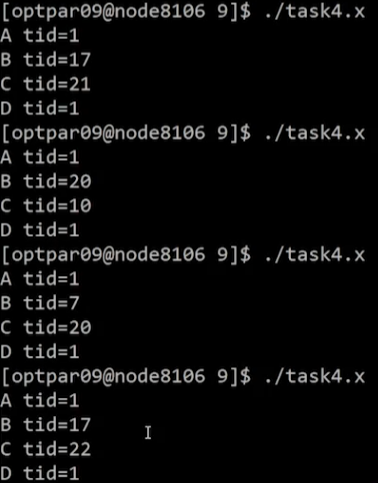
#pragma omp taskwait영역 내부 작업은 위의 작업들이 모두 완료된 후에 수행됨- Example의 D print 작업에
taskwait추가 -> D는 위의 A,B,C print 작업이 모두 완료된 후에 수행 -> A,B,C,D 순서대로 출력
3. 데이터 유효 범위
C code
int foo()
{
int a,b,c,d,e;
#pragma omp parallel private(b,d,e)
{
#pragma omp task private(e)
{
/*
a: shared
b: firstprivate
c: shared
d: firstprivate
e: private
*/
}
}
}해석
- 따로 지정되지 않은 변수들은 모두 shared
- 병렬 구문, task 구문에서 private로 지정된 변수 -> private
- 병렬 구문에서만 private로 지정된 변수 -> firstprivate

올해는 진짜 갓생 산다