Chapter 8
Memory Model
1. CUDA Memory Model
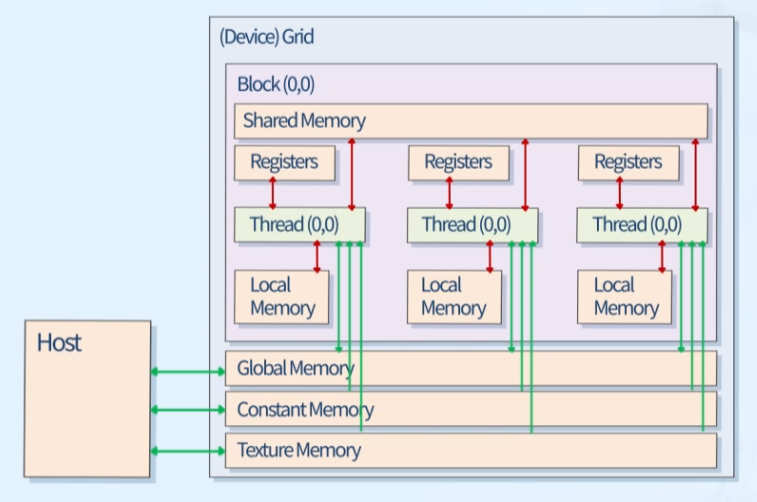
Local Memory & Register
- 스레드 개별 소유
- Data lifetime = Thread lifetime
Shared Memory
- 블록 당 소유
- Data lifetime = Block lifetime
Global Memory
- 모든 블록 내의 스레드 접근 가능
- Data lifetime = from Allocation to Deallocation
Constant Memory & Texture Memory
- 모든 블록 내의 스레드 접근 가능
- 읽기 전용
속도
- Registers > Shared > Local~Global
2. Details
Qualifier
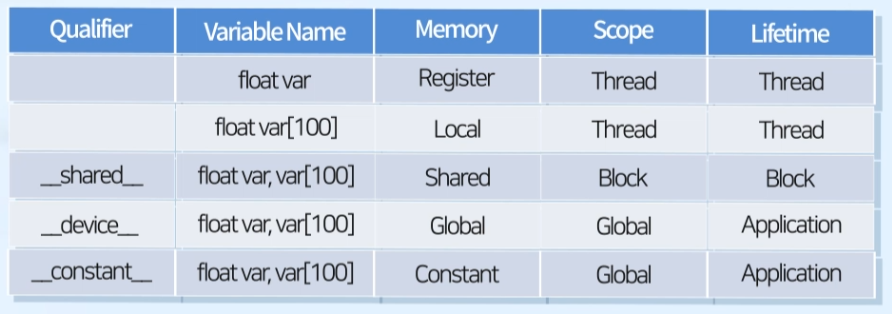
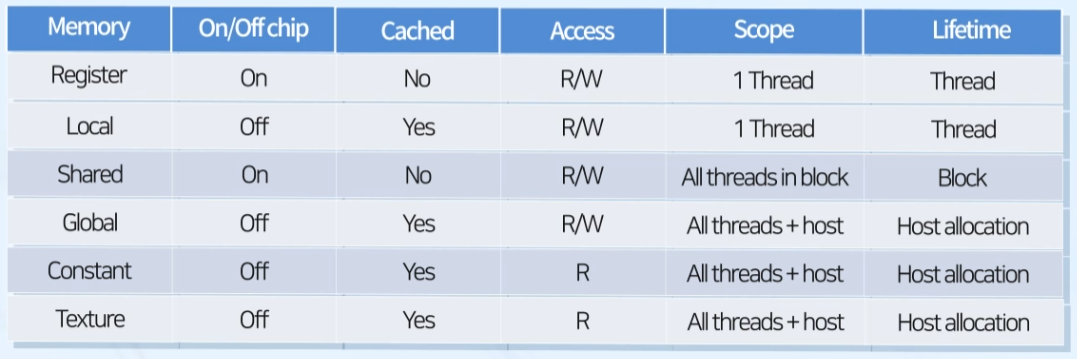
Memory별 특징 요약
3. GPU Caches
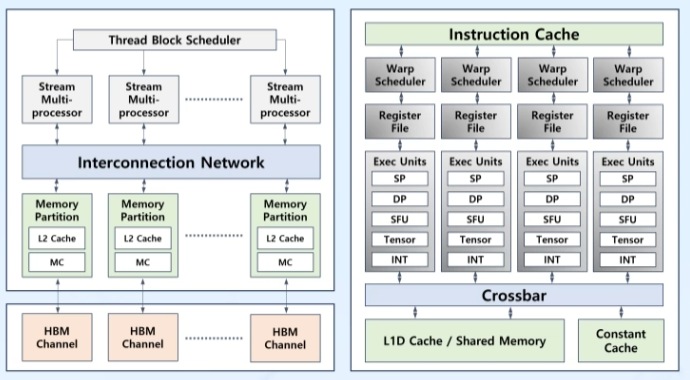
Caches
- DRAM의 느린 성능을 보완
- CPU: L1, L2, L3... caches
- GPU: Only L1, L2 caches
L1
- SM별로 각각 존재하는 캐시
- 빠른 접근, 적은 용량
L2
- 모든 SM이 공유하는 캐시
- 큰 용량
Memory Features
1. Register
가장 빠른 메모리
- 직접적으로 코어에 근접하여 데이터 접근 가능
레지스터 사용 변수
- 커널 함수에서 타입 qualifier 없이 선언된 스칼라 자동 변수
- 인덱스가 상수이고 컴파일 단계에서 결정되어 있는 배열 변수
과도한 레지스터 사용
- Occupancy 감소
SM에 올릴 수 있는 스레드 블록 수 감소하기 때문 - Limit을 넘어가면 Local 메모리 사용
스레드 메모리 크기 출력
--ptxas-options=-v (-Xptxas-v)- 컴파일 옵션 (per kernel)
- 각 스레드의 레지스터, 공유 메모리, constant 메모리 크기 출력
레지스터 사용 제어
-maxrregcount=size- 컴파일 옵션 (per thread for all kernels)
- 레지스터 사용 제어로 Occupancy 감소 문제 해소
2. Local Memory
Global Memory와 같은 HW 공간 사용
- High Bandwidth Memory (HBM Channel)
- GPU 사용설명서의 'GDDR5'
- 같은 공간을 사용하지만 용도는 다름
로컬 메모리 사용 변수
- 크기 문제로 레지스터에 저장할 수 없는 레지스터 변수
- 컴파일 타임에 결정되지 않는 인덱스를 가지는 로컬 배열 (동적 할당)
- 레지스터 공간을 너무 많이 사용하는 로컬 자료 구조나 배열 (강제적)
캐시(L1, L2) 이용
- Global Memory와 위치 같음 -> 속도 느림
- 보완 위해 Cache 사용
3. Shared Memory
On-Chip
- L1 캐시와 같은 메모리 사용 (SM별로 존재)
- 크기 설정 가능
공유 메모리 사용 변수
__shared__qualifier로 선언되는 변수- CUDA kernel의 로컬 범위, 혹은 글로벌로 선언 가능
크기 제한
- L1 캐시 사용 -> 크기 제한
- cc 7.0: 최대 96 KB (device별로 상이)
- 지정된 크기를 초과하면 compile error 발생
동기화: Barrier
__syncthreads() // 공유 메모리 접근- 같은 블록 내의 모든 스레드 도착까지 대기
- barrier 이전에 개별 스레드가 갱신한 메모리 일관성 보장
- 블록 내 모든 스레드는 같은 동기화 포인트(
__syncthreads()) 도착 필요 - 블록과 블록 사이 동기화 X -> 실행 순서 제한 X
필요한 경우, 블록을 kernel(same stream)으로 분류
동기화: Memory Fence
| 함수 | 기능 |
|---|---|
__threadfence_block() | 스레드 블록 수준 |
__threadfence() | 그리드 수준 |
__threadfence_system() | 시스템(호스트+디바이스) 수준 |
- fence 이전에 쓰기 한 값에 대해 fence 이후 모든 스레드에 갱신된 값 제공 보장 (정합성)
- 스레드 동기화 X -> 블록 내 모든 스레드 실행 불필요
성능
- 글로벌 메모리보다 매우 높은 bandwidth
- 낮은 latency
- 공유 메모리 사용이 많으면 활성 워프 감소
정적 할당
__shared__ float var[n][m];- 1D, 2D, 3D array 모두 가능
동적 할당
extern __shared__ float var[];- 1차원만 가능
- 컴파일 타임에 공유 메모리 크기가 알려지지 않으면 'extern' 키워드 사용
- 크기는 커널 호출 인수로 지정
4. Constant Memory
상수 메모리 사용 변수
__constant__qualifier로 선언된 변수- 글로벌 범위의 상수변수
디바이스에서 읽기 전용
- 호스트에서의 초기화 (읽기+쓰기), 디바이스에서의 읽기만 가능
- 워프의 모든 스레드가 똑같은 값을 읽어야 할 때 유용
전용 캐시 존재
- 워프 내의 모든 스레드가 같은위치를 읽기만 하는 경우 L1 캐시를 이용한 글로벌 메모리 접근보다 성능 우수
Function
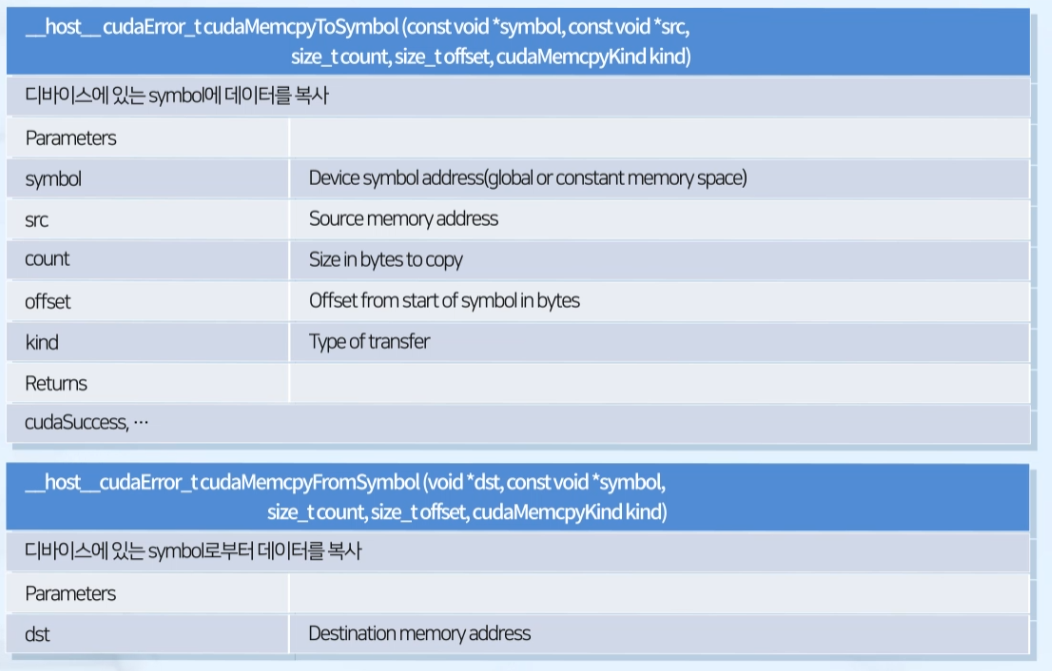
- symbol: global/constant 메모리의 변수
cudaMemcpyToSymbol(),cudaMemcpyFromSymbol()
device의 symbol에 / symbol로부터 데이터 복사- static 변수용
cudaMemcpyToSymbol()이 아닌cudaMemcpy()사용 시 오류 발생

cudaGetSymbolAddress()
CUDA symbol과 연관된 디바이스 포인터 return
5. Global Memory
가장 큰 메모리
- 용량은 GPU 스펙이 따라 상이
- 최대 latency
글로벌 메모리 사용 변수
- 동적 할당되는 변수(
cudaMalloc()) __device__qualifier로 선언되는 정적 변수
캐시(L1, L2) 이용
- 시스템에서 자동적으로 사용
ex. warp 단위로 cache에 데이터를 옮겨두는 식으로 사용하면 속도를 높일 수 있음
Other Memory
1. Pinned Memory
Pageable vs Pinned
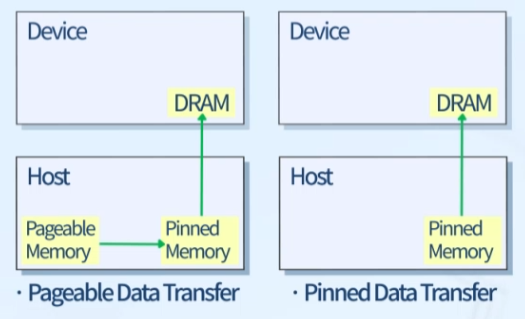
- Pageable Data Transfer (Default)
일반적인cudaMemcpy()시 수행됨
Pageable Memory가 별도로 마련된 Pinned Memory 공간에 임시 저장된 후 GPU 쪽으로 copy
안정성 확보 but 성능 저하
Function

cudaMallocHost(),cudaFreeHost()- 임시 page-locked(pinned) host memory 할당 -> 소스 host data를 pinned memory에 복사 -> pinned memory에서 device memory로 복사
Features
- 장점: 디바이스가 pinned memory에 직접 접근 가능
pageable 메모리보다 더 높은 bandwidth로 R/W - 단점: OS 성능 저하
과도한 pinned memory 할당은 OS에 부하를 줌
2. Zero-Copy Memory
Intro
- 호스트, 디바이스 변수는 상호 직접 접근이 불가능
- Zero-Copy Memory는 예외적으로 가능
Zero-Copy Memory
- 디바이스 메모리 공간에 맵핑된 pinned memory
- 호스트와 디바이스는 zero-copy memory에 접근 가능
- GPU 스레드는 직접 접근 가능
- 디바이스 메모리가 부족할 때 호스트 메모리 이용
- 명시적 데이터 전송 불필요
-PCIe 전송율 개선
성능 문제
- 데이터 동기화 필요
kernel 함수는 비동기 실행 -> Zero-Copy Memory 변수의 변화를 host가 모를 경우 오류 발생 - 동시 접근 시 데이터 레이싱 발생 가능성
- 과도한 사용 시 OS에 부하
용례
- 사용 빈도가 높은 작은 데이터 처리
Function


cudaHostAlloc(): 호스트에 디바이스에서 접근 가능한 pinned memory 할당cudaFreeHost(): 메모리 해제cudaHostGetDevicePointer():cudaHostAlloc()에 의해 할당된 mapped host memory의 디바이스 포인터 return
3. Unified Memory
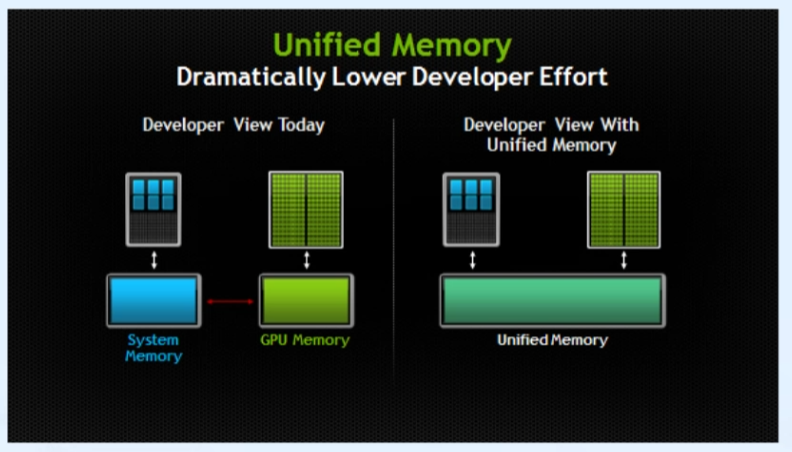
가상 메모리 공간
- Zero-Copy의 동기화, 성능 저하 문제 해소
- Host, Device 모두 접속 가능한 메모리 공간(a pool of managed memory) 생성
- 서로 다른 물리적 메모리 공간을 같은 메모리 주소를 이용하여 접근
호스트와 디바이스 메모리 사이 데이터 자동 이동
managed memory
- 시스템에 의해 자동으로 관리되는 Unified Memory allocation
- Device memory에서 유효한 모든 CUDA 연산은 managed memory에서도 유효함
- un-managed memory: 명시적 할당, application에 의해 전달
- 단, 최선의 알고리즘으로 구현되는 것을 보장하진 못함
정적 할당
__device__ __managed__ int x;__managed__annotation 사용- File-scope와 global-scope에서만 사용 가능
동적 할당

cudaMallocManaged(): Unified Memory System에 의해 자동으로 관리되는 메모리 할당cudaFree(): 메모리 해제

올해는 진짜 갓생 산다